A Comparison of Fusion Techniques for Multi-Modal Human Activity Recognition on the HARMES Dataset
Pith reviewed 2026-06-29 04:29 UTC · model grok-4.3
The pith
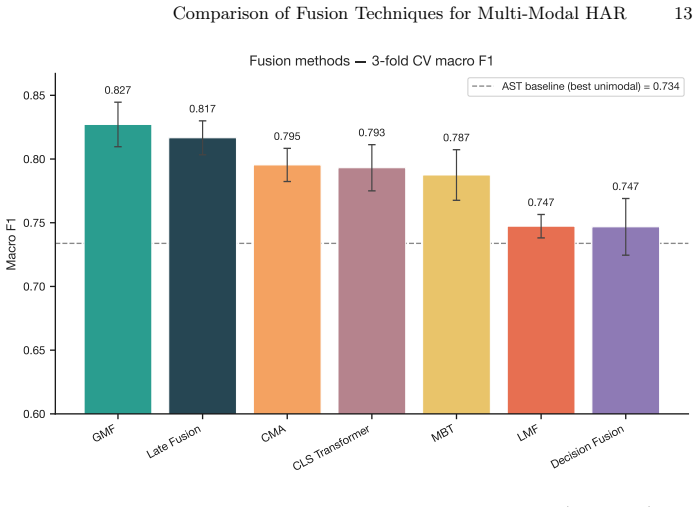
Gated Multi-modal Fusion reaches 0.82 macro F1 on the HARMES dataset, six points above late-fusion concatenation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying the seven different fusion techniques to a state-of-the-art multi-modal model architecture on the HARMES dataset, which comprises 61 hours of fully labeled IMU, audio, and ambient humidity data for 15 household and personal hygiene activities, we show that Gated Multi-modal Fusion achieves the highest macro F1-score (0.82), surpassing the concatenation-based late fusion HARMES paper baseline of 0.76 by +6pp under leave-one-participant-out evaluation.
What carries the argument
Gated Multi-modal Fusion, a mechanism that uses learned gates to dynamically control the contribution of each modality (IMU, audio, humidity) before or during combination in the shared model.
Load-bearing premise
The seven fusion techniques were applied to an identical state-of-the-art multi-modal model architecture with no architecture changes that inadvertently favor one fusion method over others.
What would settle it
Re-training the identical seven fusion variants after swapping the underlying feature extractor or adding modality-specific branches and observing whether the 0.82 score gap disappears.
Figures

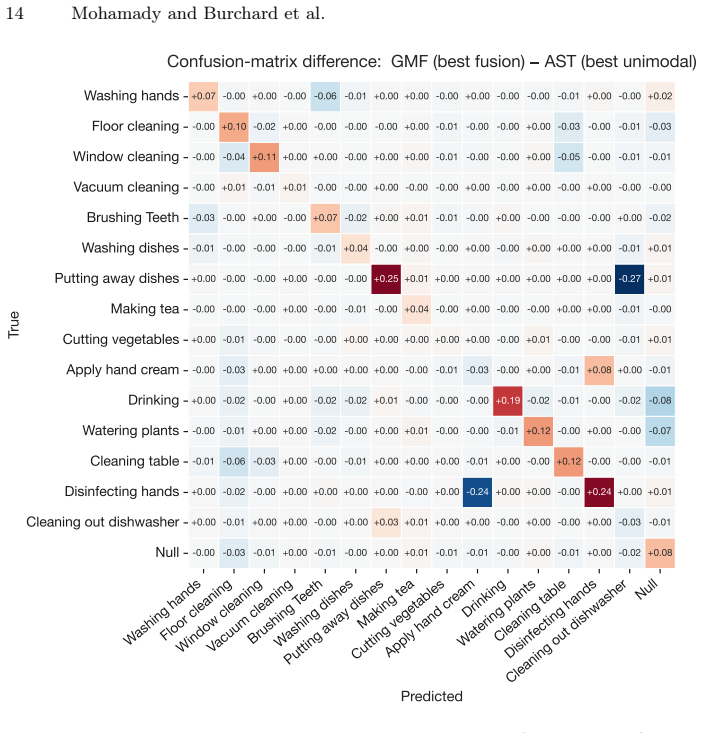



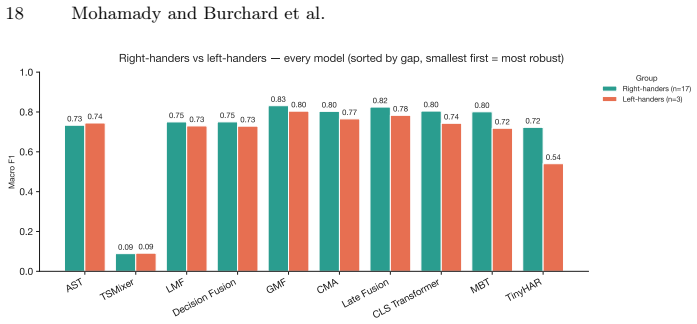







read the original abstract
Recent advances in Human Activity Recognition (HAR) from wearable sensors have shown that multi-modal deep learning models consistently outperform their uni-modal counterparts. Modalities can include IMUs, RGB cameras, audio signals, and others. One important aspect of multi-modal deep learning is the sensor fusion approach we apply. Over recent years, multiple fusion paradigms have been proposed for multi-modal HAR. However, to the best of our knowledge, no head-to-head comparison of these paradigms exists on a common multi-modal HAR benchmark dataset. To address this research gap, we systematically compare seven state-of-the-art sensor fusion methods on the recently released HARMES dataset, which comprises 61 hours of fully labeled IMU, audio, and ambient humidity data. The chosen dataset focuses on 15 household and personal hygiene activities of daily living (ADLs). By applying the seven different fusion techniques to a state-of-the-art multi-modal model architecture, we show that Gated Multi-modal Fusion achieves the highest macro F1-score (0.82), surpassing the concatenation-based late fusion HARMES paper baseline of 0.76 by +6pp under leave-one-participant-out evaluation. All code used in our experiments is made publicly available on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript performs a head-to-head empirical comparison of seven sensor fusion techniques (including gated multi-modal fusion and concatenation-based late fusion) applied to a multi-modal HAR model on the HARMES dataset (IMU + audio + humidity, 15 ADLs). Under leave-one-participant-out evaluation it reports that gated multi-modal fusion attains the highest macro F1 of 0.82, outperforming the HARMES baseline of 0.76 by 6 percentage points. All code is released publicly.
Significance. If the experimental controls are sound, the work supplies a useful, reproducible benchmark for choosing fusion operators in multi-modal wearable HAR. The public GitHub release is a clear strength that enables direct verification of the reported ranking.
major comments (2)
- [Abstract] Abstract: the central claim that Gated Multi-modal Fusion outperforms the other six techniques by 6 pp rests on the assertion that all seven methods were applied to “a state-of-the-art multi-modal model architecture” with “no architecture changes.” No explicit confirmation is given that the unimodal feature extractors, their output dimensionalities, the downstream classifier, optimizer schedule, learning-rate scaling, and regularization were held strictly fixed while only the fusion operator was exchanged. If any variant required even modest hyper-parameter adjustments for training stability, the observed ranking could be an artifact rather than an intrinsic property of the fusion method.
- [Results] Results (implied by the reported F1 scores): the macro F1 values are presented as single point estimates with neither error bars, standard deviations across random seeds, nor statistical significance tests comparing the seven methods. Without these, it is impossible to determine whether the +6 pp margin is reliable or could be explained by training stochasticity.
minor comments (1)
- [§2] The abstract states that the dataset comprises “61 hours of fully labeled” data; a brief table or sentence in §2 confirming the exact number of participants, recording duration per participant, and class distribution would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below. Where the points identify gaps in explicit documentation or statistical reporting, we agree that revisions are warranted and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Gated Multi-modal Fusion outperforms the other six techniques by 6 pp rests on the assertion that all seven methods were applied to “a state-of-the-art multi-modal model architecture” with “no architecture changes.” No explicit confirmation is given that the unimodal feature extractors, their output dimensionalities, the downstream classifier, optimizer schedule, learning-rate scaling, and regularization were held strictly fixed while only the fusion operator was exchanged. If any variant required even modest hyper-parameter adjustments for training stability, the observed ranking could be an artifact rather than an intrinsic property of the fusion method.
Authors: The manuscript states that the seven fusion techniques were applied to the same state-of-the-art multi-modal model architecture with no architecture changes. In practice, the unimodal feature extractors, their output dimensionalities, the downstream classifier, optimizer, learning-rate schedule, and regularization were held identical across all variants; only the fusion operator itself was exchanged. We will add an explicit paragraph in the Methods section of the revised manuscript confirming these controls in detail to remove any ambiguity. revision: yes
-
Referee: [Results] Results (implied by the reported F1 scores): the macro F1 values are presented as single point estimates with neither error bars, standard deviations across random seeds, nor statistical significance tests comparing the seven methods. Without these, it is impossible to determine whether the +6 pp margin is reliable or could be explained by training stochasticity.
Authors: We agree that single-run point estimates limit the ability to assess variability due to training stochasticity. Leave-one-participant-out evaluation on this dataset is computationally expensive, which is why we initially reported single runs. In the revision we will either (a) rerun all seven methods with three random seeds and report means and standard deviations or (b) add a clear limitations statement explaining the single-run protocol and the rationale. We will also include pairwise statistical significance tests (e.g., McNemar or paired t-tests on per-participant scores) where multiple runs become available. revision: yes
Circularity Check
No circularity: purely empirical comparison of fusion methods with measured outcomes
full rationale
The manuscript performs a head-to-head experimental comparison of seven fusion techniques on the HARMES dataset under leave-one-participant-out evaluation. Reported macro F1 scores (e.g., 0.82 for gated fusion vs. 0.76 baseline) are direct measurements on held-out participants, not quantities derived from equations or fitted parameters that reduce to the inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain, which is absent because the central claim is observational rather than deductive. The skeptic concern about architecture identity is a validity issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- model hyperparameters and training settings
axioms (1)
- domain assumption HARMES dataset and leave-one-participant-out protocol constitute a valid and unbiased benchmark for comparing fusion methods
Reference graph
Works this paper leans on
-
[1]
Sensors19(17), 3808 (Jan 2019).https://doi.org/10.3390/s19173808
Aguileta, A.A., Brena, R.F., Mayora, O., Molino-Minero-Re, E., Trejo, L.A.: Multi- Sensor Fusion for Activity Recognition—A Survey. Sensors19(17), 3808 (Jan 2019).https://doi.org/10.3390/s19173808
-
[2]
Neural Computing and Applications32(14), 10209–10228 (Jul 2020)
Arevalo, J., Solorio, T., Montes-y-Gómez, M., González, F.A.: Gated multimodal networks. Neural Computing and Applications32(14), 10209–10228 (Jul 2020). https://doi.org/10.1007/s00521-019-04559-1
-
[3]
Multimedia Systems16(6), 345–379 (Nov 2010)
Atrey, P.K., Hossain, M.A., El Saddik, A., Kankanhalli, M.S.: Multimodal fusion for multimedia analysis: A survey. Multimedia Systems16(6), 345–379 (Nov 2010). https://doi.org/10.1007/s00530-010-0182-0
-
[4]
In: Proceedings of the 2025 ACM International Sympo- sium on Wearable Computers
Bian, S., Liu, M., Rey, V.F., Geißler, D., Lukowicz, P.: TinierHAR: Towards Ultra-Lightweight Deep Learning Models for Efficient Human Activity Recogni- tion on Edge Devices. In: Proceedings of the 2025 ACM International Sympo- sium on Wearable Computers. pp. 163–169. ACM, Espoo Finland (Oct 2025). https://doi.org/10.1145/3715071.3750410
-
[5]
Expert Systems with Applications312, 131487 (May 2026).https://doi.org/10.1016/j.eswa.2026.131487
Bralina, S., Yazici, A., Guan, C., Lee, M.H.: Adaptive bottleneck transformer for multimodal EEG, audio, and vision fusion. Expert Systems with Applications312, 131487 (May 2026).https://doi.org/10.1016/j.eswa.2026.131487
-
[6]
Bulling, A., Blanke, U., Schiele, B.: A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv.46(3), 33:1–33:33 (Jan 2014). https://doi.org/10.1145/2499621
-
[7]
In: Durmaz Incel, Ö., Qin, J., Bieber, G., Kuijper, A
Burchard, R., Ali, H., Van Laerhoven, K.: Improved Strategies for Multi-modal Atmospheric Sensing to Augment Wearable IMU-Based Hand Washing Detection. In: Durmaz Incel, Ö., Qin, J., Bieber, G., Kuijper, A. (eds.) Sensor-Based Activity Recognition and Artificial Intelligence, vol. 16292, pp. 308–323. Springer Nature Switzerland, Cham (2026).https://doi.or...
-
[9]
Burchard, R., Brückner, P.A., Bock, M., Van Laerhoven, K.: HARMES: A Multi- Modal Dataset for Wearable Human Activity Recognition with Motion, Envi- ronmental Sensing and Sound (Apr 2026).https://doi.org/10.5281/zenodo. 19425719
-
[10]
In: Konak, O., Arnrich, B., Bieber, G., Kuijper, A., Fudickar, S
Burchard, R., Van Laerhoven, K.: Multi-modal Atmospheric Sensing to Aug- ment Wearable IMU-Based Hand Washing Detection. In: Konak, O., Arnrich, B., Bieber, G., Kuijper, A., Fudickar, S. (eds.) Sensor-Based Activity Recognition and Artificial Intelligence. pp. 55–68. Springer Nature Switzerland, Cham (2025). https://doi.org/10.1007/978-3-031-80856-2_4
-
[11]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin,J.,Chang,M.W.,Lee,K.,Toutanova,K.:BERT:Pre-trainingofDeepBidi- rectional Transformers for Language Understanding (May 2019).https://doi. org/10.48550/arXiv.1810.04805 22 Mohamady and Burchard et al
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.04805 2019
-
[12]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Jun 2021).https://doi.org/10.48550/arXiv.2010.11929
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.11929 2021
-
[13]
In: Pro- ceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Ekambaram, V., Jati, A., Nguyen, N., Sinthong, P., Kalagnanam, J.: TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting. In: Pro- ceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. pp. 459–469 (Aug 2023).https://doi.org/10.1145/3580305.3599533
-
[14]
Gao, Z., wang, Y., Chen, J., Xing, J., Patel, S., Liu, X., Shi, Y.: MMTSA: Multi- Modal Temporal Segment Attention Network for Efficient Human Activity Recog- nition. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies7(3), 96:1–96:26 (Sep 2023).https://doi.org/10.1145/3610872
-
[15]
Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala, K.V., Joulin, A., Misra, I.: ImageBind One Embedding Space to Bind Them All. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15180– 15190 (Jun 2023).https://doi.org/10.1109/CVPR52729.2023.01457
-
[16]
In: Interspeech 2021
Gong, Y., Chung, Y.A., Glass, J.: AST: Audio Spectrogram Transformer. In: Interspeech 2021. pp. 571–575. ISCA (Aug 2021).https://doi.org/10.21437/ Interspeech.2021-698
2021
-
[17]
In: 2016 International Joint Conference on Neural Networks (IJCNN)
Ha, S., Choi, S.: Convolutional neural networks for human activity recognition using multiple accelerometer and gyroscope sensors. In: 2016 International Joint Conference on Neural Networks (IJCNN). pp. 381–388. IEEE, Vancouver, BC, Canada (Jul 2016).https://doi.org/10.1109/IJCNN.2016.7727224
-
[18]
In: Proceedings of the 38th International Conference on Machine Learning
Jaegle, A., Gimeno, F., Brock, A., Vinyals, O., Zisserman, A., Carreira, J.: Per- ceiver: General Perception with Iterative Attention. In: Proceedings of the 38th International Conference on Machine Learning. pp. 4651–4664. PMLR (Jul 2021)
2021
-
[19]
Koutoupis, S., Zervou, M.A., Kontras, K., Vos, M.D., Tsakalides, P., Tsagkatakis, G.: The More, the Merrier: Contrastive Fusion for Higher-Order Multimodal Align- ment (Apr 2026).https://doi.org/10.48550/arXiv.2511.21331
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21331 2026
-
[20]
Journal of Computer Science and Cybernetics pp
Le, T.H., Nguyen, T.K., Le, T.A., Delalandre, M., Trung, K.T., Tran, T.H., Pham, C.: Mamba-MHAR: An efficient multimodal framework for human action recog- nition. Journal of Computer Science and Cybernetics pp. 245–264 (Sep 2025). https://doi.org/10.15625/1813-9663/22770
-
[21]
Information Fusion 104, 102153 (Apr 2024).https://doi.org/10.1016/j.inffus.2023.102153
Lee, S., Lim, Y., Lim, K.: Multimodal sensor fusion models for real-time exercise repetition counting with IMU sensors and respiration data. Information Fusion 104, 102153 (Apr 2024).https://doi.org/10.1016/j.inffus.2023.102153
-
[22]
IEEE Internet of Things Journal12(3), 2373–2384 (Feb 2025).https://doi.org/10.1109/JIOT.2024.3463405
Li, S., Zhu, T., Duan, F., Chen, L., Ning, H., Nugent, C., Wan, Y.: HARMamba: Efficient and Lightweight Wearable Sensor Human Activity Recognition Based on Bidirectional Mamba. IEEE Internet of Things Journal12(3), 2373–2384 (Feb 2025).https://doi.org/10.1109/JIOT.2024.3463405
-
[23]
Efficient Low-rank Multimodal Fusion with Modality-Specific Factors
Liu, Z., Shen, Y., Lakshminarasimhan, V.B., Liang, P.P., Zadeh, A., Morency, L.P.: Efficient Low-rank Multimodal Fusion with Modality-Specific Factors (May 2018). https://doi.org/10.48550/arXiv.1806.00064
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1806.00064 2018
-
[24]
Lu, J., Batra, D., Parikh, D., Lee, S.: ViLBERT: Pretraining Task-Agnostic Vi- siolinguistic Representations for Vision-and-Language Tasks (Aug 2019).https: //doi.org/10.48550/arXiv.1908.02265
-
[25]
3109–3115 (2019)
Ma, H., Li, W., Zhang, X., Gao, S., Lu, S.: AttnSense: Multi-level Attention Mech- anism For Multimodal Human Activity Recognition pp. 3109–3115 (2019)
2019
-
[26]
Mollyn, V., Ahuja, K., Verma, D., Harrison, C., Goel, M.: SAMoSA: Sensing Activities with Motion and Subsampled Audio. Proceedings of the ACM on In- Comparison of Fusion Techniques for Multi-Modal HAR 23 teractive, Mobile, Wearable and Ubiquitous Technologies6(3), 1–19 (Sep 2022). https://doi.org/10.1145/3550284
-
[27]
In: Bouamor, H., Pino, J., Bali, K
Moon, S., Madotto, A., Lin, Z., Saraf, A., Bearman, A., Damavandi, B.: IMU2CLIP: Language-grounded Motion Sensor Translation with Multimodal Con- trastive Learning. In: Bouamor, H., Pino, J., Bali, K. (eds.) Findings of the As- sociation for Computational Linguistics: EMNLP 2023. pp. 13246–13253. Associa- tion for Computational Linguistics, Singapore (Dec...
2023
-
[28]
In: Proceedings of the 2017 ACM International Symposium on Wearable Computers
Münzner, S., Schmidt, P., Reiss, A., Hanselmann, M., Stiefelhagen, R., Dürichen, R.: CNN-based sensor fusion techniques for multimodal human activity recogni- tion. In: Proceedings of the 2017 ACM International Symposium on Wearable Computers. pp. 158–165. ACM, Maui Hawaii (Sep 2017).https://doi.org/10. 1145/3123021.3123046
arXiv 2017
-
[29]
Nagrani, A., Yang, S., Arnab, A., Jansen, A., Schmid, C., Sun, C.: Attention Bot- tlenecks for Multimodal Fusion (Nov 2022).https://doi.org/10.48550/arXiv. 2107.00135
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[30]
Sensors16(1), 115 (Jan 2016).https://doi.org/10.3390/s16010115
Ordóñez, F., Roggen, D.: Deep Convolutional and LSTM Recurrent Neural Net- works for Multimodal Wearable Activity Recognition. Sensors16(1), 115 (Jan 2016).https://doi.org/10.3390/s16010115
-
[31]
In: Proceedings of the 28th Annual International Conference on Mobile Computing And Networking
Ouyang, X., Shuai, X., Zhou, J., Shi, I.W., Xie, Z., Xing, G., Huang, J.: Cosmo: Contrastive fusion learning with small data for multimodal human activity recog- nition. In: Proceedings of the 28th Annual International Conference on Mobile Computing And Networking. pp. 324–337. MobiCom ’22, Association for Com- puting Machinery, New York, NY, USA (Oct 202...
arXiv 2022
-
[32]
Perez, E., Strub, F., De Vries, H., Dumoulin, V., Courville, A.: FiLM: Visual Rea- soning with a General Conditioning Layer. Proceedings of the AAAI Conference on Artificial Intelligence32(1) (Apr 2018).https://doi.org/10.1609/aaai.v32i1. 11671
-
[33]
Information Fusion80, 241–265 (Apr 2022).https://doi.org/10.1016/ j.inffus.2021.11.006
Qiu, S., Zhao, H., Jiang, N., Wang, Z., Liu, L., An, Y., Zhao, H., Miao, X., Liu, R., Fortino, G.: Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research chal- lenges. Information Fusion80, 241–265 (Apr 2022).https://doi.org/10.1016/ j.inffus.2021.11.006
2022
-
[34]
In: Proceedings of the 38th International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning Transferable Visual Models From Natural Language Supervision. In: Proceedings of the 38th International Conference on Machine Learning. pp. 8748–8763. PMLR (Jul 2021)
2021
-
[35]
In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J
Rahman, W., Hasan, M.K., Lee, S., Bagher Zadeh, A., Mao, C., Morency, L.P., Hoque, E.: Integrating Multimodal Information in Large Pretrained Transformers. In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 2359–2369. Association for Computational Ling...
-
[36]
IEEE Signal Processing Magazine34(6), 96–108 (Nov 2017)
Ramachandram,D.,Taylor,G.W.:DeepMultimodalLearning:ASurveyonRecent Advances and Trends. IEEE Signal Processing Magazine34(6), 96–108 (Nov 2017). https://doi.org/10.1109/MSP.2017.2738401
-
[37]
In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M
Tian, Y., Krishnan, D., Isola, P.: Contrastive Multiview Coding. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M. (eds.) Computer Vision – ECCV 2020. pp. 776–
2020
-
[38]
Springer International Publishing, Cham (2020).https://doi.org/10.1007/ 978-3-030-58621-8_45 24 Mohamady and Burchard et al
2020
-
[39]
Tsai, Y.H.H., Bai, S., Liang, P.P., Kolter, J.Z., Morency, L.P., Salakhutdinov, R.: Multimodal Transformer for Unaligned Multimodal Language Sequences (Jun 2019).https://doi.org/10.48550/arXiv.1906.00295
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.00295 2019
-
[40]
Tailornet: Predict- ing clothing in 3d as a function of human pose, shape and garment style
Vaezi Joze, H.R., Shaban, A., Iuzzolino, M.L., Koishida, K.: MMTM: Multimodal Transfer Module for CNN Fusion. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13286–13296. IEEE, Seattle, WA, USA (Jun 2020).https://doi.org/10.1109/CVPR42600.2020.01330
-
[41]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., ukasz Kaiser, Ł., Polosukhin, I.: Attention is All you Need. In: Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc. (2017). https://doi.org/10.48550/arXiv.1706.03762
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2017
-
[42]
Wang, J., Chen, Y., Hao, S., Peng, X., Hu, L.: Deep learning for sensor-based activity recognition: A survey. Pattern Recogn. Lett.119(C), 3–11 (Mar 2019). https://doi.org/10.1016/j.patrec.2018.02.010
-
[43]
The Visual Computer41(7), 5135–5151 (May 2025).https://doi.org/10.1007/s00371-024-03712-9
Wang, K., Liu, C., Zhang, R.: CMA-SOD: Cross-modal attention fusion network for RGB-D salient object detection. The Visual Computer41(7), 5135–5151 (May 2025).https://doi.org/10.1007/s00371-024-03712-9
-
[44]
Knowledge-Based Systems223, 106970 (Jul 2021).https: //doi.org/10.1016/j.knosys.2021.106970
Yadav,S.K.,Tiwari,K.,Pandey,H.M.,Akbar,S.A.:Areviewofmultimodalhuman activity recognition with special emphasis on classification, applications, challenges and future directions. Knowledge-Based Systems223, 106970 (Jul 2021).https: //doi.org/10.1016/j.knosys.2021.106970
-
[45]
Scientific Re- ports16(1), 382 (Dec 2025).https://doi.org/10.1038/s41598-025-29801-w
Yılmaz,T.A.,Yatbaz,H.Y.,Ever,E.,Yazici,A.:Hierarchicalhumanactivityrecog- nition with fusion of audio and multiple inertial sensor modalities. Scientific Re- ports16(1), 382 (Dec 2025).https://doi.org/10.1038/s41598-025-29801-w
-
[46]
In: Palmer, M., Hwa, R., Riedel, S
Zadeh, A., Chen, M., Poria, S., Cambria, E., Morency, L.P.: Tensor Fusion Network for Multimodal Sentiment Analysis. In: Palmer, M., Hwa, R., Riedel, S. (eds.) Pro- ceedings of the 2017 Conference on Empirical Methods in Natural Language Pro- cessing. pp. 1103–1114. Association for Computational Linguistics, Copenhagen, Denmark (Sep 2017).https://doi.org/...
-
[47]
Zhou, Y., Zhao, H., Huang, Y., Riedel, T., Hefenbrock, M., Beigl, M.: TinyHAR: A Lightweight Deep Learning Model Designed for Human Activity Recognition. In: Proceedings of the 2022 ACM International Symposium on Wearable Computers. pp. 89–93. ACM, Cambridge United Kingdom (Sep 2022).https://doi.org/10. 1145/3544794.3558467 A Fusion Strategy Visualization...
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.