VASAE: Naming SAE Dictionary Directions with Vocabulary-Aligned Anchoring
Pith reviewed 2026-06-29 04:42 UTC · model grok-4.3
The pith
VASAE trains sparse autoencoders to assign each feature the name of its nearest vocabulary token while matching standard reconstruction quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VASAE trains SAE features under vocabulary-aligned anchoring and assigns each feature an intrinsic token name: the token string whose embedding is nearest to that feature. Without reducing reconstruction quality compared with a standard SAE, VASAE produces dictionaries with vocabulary-aligned features, achieving about 90 percent alignment in layers 0-10 of GPT-2-small at a 0.8 cutoff on the nearest-token alignment score, high alignment in representative shallow and middle layers of Llama-3.1-8B, and limited alignment in the final layer.
What carries the argument
Vocabulary-aligned anchoring, which constrains SAE feature directions during training so each is named by its nearest token embedding.
If this is right
- Dictionaries gain intrinsic token names usable directly from training rather than post-hoc labeling.
- Alignment reaches 92.8 percent in a representative shallow layer of Llama-3.1-8B.
- After subtracting sentence-level mean sparse codes, many intrinsic names remain relevant to nearby input tokens.
- The approach works across GPT-2-small and Llama-3.1-8B but shows layer-dependent variation in final layers.
Where Pith is reading between the lines
- The anchoring may reduce the need for manual feature inspection in larger models by providing built-in labels.
- Testing whether these names predict feature behavior on held-out inputs could quantify their stability beyond the reported cutoffs.
- The method might extend to other activation sites such as attention outputs or MLP layers to check consistency of alignment.
Load-bearing premise
The token whose embedding is nearest to a learned SAE feature direction provides a semantically meaningful and stable name for the feature's activation behavior across inputs.
What would settle it
A dataset of inputs where the activation pattern of a feature consistently fails to match the semantics of its assigned nearest token would falsify the claim that the name is meaningful.
Figures






read the original abstract
Sparse autoencoders (SAEs) provide useful decompositions of Transformer residual streams, but their learned features are usually named post hoc rather than directly connected to the Transformer's token vocabulary. We introduce Vocabulary-Aligned Sparse Autoencoder (VASAE), a method that trains SAE features under vocabulary-aligned anchoring and assigns each feature an intrinsic token name: the token string whose embedding is nearest to that feature. Without reducing reconstruction quality compared with a standard SAE, VASAE produces dictionaries with vocabulary-aligned features. Using a 0.8 cutoff on the nearest-token alignment score, dictionaries trained on GPT-2-small post-residual streams align about 90% of features in layers 0--10. In Llama-3.1-8B, representative shallow and middle-layer dictionaries contain strongly aligned features, including 92.8% in the shallow layer, while the representative final-layer dictionary shows limited alignment. After subtracting the sentence-level mean sparse code, case studies show that many remaining intrinsic token names are relevant to nearby input tokens. These results suggest that vocabulary-aligned anchoring can connect learned features to intrinsic token names during training, complementing post hoc interpretation of learned dictionaries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Vocabulary-Aligned Sparse Autoencoder (VASAE), a modified SAE training procedure that incorporates vocabulary-aligned anchoring so that each decoder direction can be named by its nearest token embedding. The central claims are that this produces dictionaries with high vocabulary alignment (approximately 90% of features above 0.8 alignment score in GPT-2-small layers 0-10 and 92.8% in a shallow Llama-3.1-8B layer) without reducing reconstruction quality relative to standard SAEs, with qualitative support from case studies after sentence-level mean subtraction of sparse codes.
Significance. If the alignment scores correspond to stable semantic matches between names and activation patterns, the method would provide a training-time solution to the post-hoc naming problem in SAE interpretability, potentially yielding more reproducible and vocabulary-grounded feature dictionaries. The reported layer-wise differences (strong alignment in shallow/middle layers, weaker in final layers) and the mean-subtraction case studies are potentially useful observations for the field.
major comments (3)
- [Abstract] Abstract: the claim that VASAE produces dictionaries 'without reducing reconstruction quality compared with a standard SAE' is load-bearing for the central contribution but is stated without any quantitative comparison (no MSE values, no tables, no error bars, no ablation on the anchoring term).
- [Abstract] Abstract: the utility of the intrinsic names rests on the untested premise that nearest-token embedding proximity yields a name whose semantics match the feature's activation behavior; no quantitative test (e.g., activation precision/recall on the named token, or stability under direction perturbation) is reported to support the ~90% alignment figures.
- [Abstract] Abstract and results: the alignment percentages (90% for GPT-2 layers 0-10, 92.8% for Llama shallow layer) are presented without accompanying tables, per-layer breakdowns, or controls for the effect of the anchoring hyperparameter, making it impossible to assess whether the result is robust or an artifact of the chosen 0.8 cutoff.
minor comments (1)
- [Abstract] The abstract refers to 'case studies' showing relevance after mean subtraction but does not specify the criteria used to judge relevance or the number of examples examined.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the abstract and results sections would benefit from additional quantitative details, tables, and robustness checks. We will revise the manuscript accordingly to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that VASAE produces dictionaries 'without reducing reconstruction quality compared with a standard SAE' is load-bearing for the central contribution but is stated without any quantitative comparison (no MSE values, no tables, no error bars, no ablation on the anchoring term).
Authors: We agree that the abstract would be strengthened by including specific quantitative evidence. The full manuscript reports MSE values demonstrating comparable reconstruction quality to standard SAEs, but we will add explicit MSE figures with error bars from multiple random seeds, a summary table, and an ablation on the anchoring term strength to the abstract and main results. revision: yes
-
Referee: [Abstract] Abstract: the utility of the intrinsic names rests on the untested premise that nearest-token embedding proximity yields a name whose semantics match the feature's activation behavior; no quantitative test (e.g., activation precision/recall on the named token, or stability under direction perturbation) is reported to support the ~90% alignment figures.
Authors: The alignment score is defined directly as the cosine similarity between the decoder direction and the nearest token embedding, providing an intrinsic measure of vocabulary alignment by construction. We acknowledge that this does not automatically guarantee semantic match with activation patterns on inputs. We will add quantitative validation including activation precision/recall for the named tokens and stability analysis under small perturbations to the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract and results: the alignment percentages (90% for GPT-2 layers 0-10, 92.8% for Llama shallow layer) are presented without accompanying tables, per-layer breakdowns, or controls for the effect of the anchoring hyperparameter, making it impossible to assess whether the result is robust or an artifact of the chosen 0.8 cutoff.
Authors: We will expand the results section with a table providing per-layer alignment percentages for GPT-2 (including all layers), report alignment distributions at multiple cutoffs (e.g., 0.7, 0.8, 0.9), and include an ablation varying the anchoring hyperparameter to confirm that the reported high alignment rates are robust rather than sensitive to the specific threshold or hyperparameter choice. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces VASAE as an empirical training modification to standard SAEs that adds vocabulary-aligned anchoring during optimization, then reports measured alignment percentages (e.g., ~90% above 0.8 cutoff in early GPT-2 layers) and reconstruction quality comparisons. No equations, derivations, or predictions are presented that reduce to their own inputs by construction; the claims rest on the described procedure and observed outcomes on held-out data rather than self-referential definitions or fitted parameters renamed as independent results. No self-citations or uniqueness theorems are invoked as load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Nearest embedding in vocabulary space supplies a meaningful intrinsic name for each SAE feature
Reference graph
Works this paper leans on
-
[1]
doi: 10.1162/TACL_A_ 00254. Belrose, N., Ostrovsky, I., McKinney, L., Furman, Z., Smith, L., Halawi, D., Biderman, S., and Steinhardt, J. Eliciting Latent Predictions from Transformers with the Tuned Lens, November
-
[2]
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-V oss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford,...
2020
-
[3]
How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings
Ethayarajh, K. How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings. In Inui, K., Jiang, J., Ng, V ., and Wan, X. (eds.),Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP...
2019
-
[4]
doi: 10.18653/V1/D19-1006. Fiotto-Kaufman, J. F., Loftus, A. R., Todd, E., Brinkmann, J., Pal, K., Troitskii, D., Ripa, M., Belfki, A., Rager, C., Juang, C., Mueller, A., Marks, S., Sharma, A. S., Luc- chetti, F., Prakash, N., Brodley, C. E., Guha, A., Bell, J., Wallace, B. C., and Bau, D. NNsight and NDIF: De- mocratizing Access to Open-Weight Foundation...
-
[5]
D., Tillman, H., Goh, G., Troll, R., Rad- ford, A., Sutskever, I., Leike, J., and Wu, J
Gao, L., la Tour, T. D., Tillman, H., Goh, G., Troll, R., Rad- ford, A., Sutskever, I., Leike, J., and Wu, J. Scaling and evaluating sparse autoencoders. InThe Thirteenth Inter- national Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[6]
Trans- former Feed-Forward Layers Are Key-Value Memories
Geva, M., Schuster, R., Berant, J., and Levy, O. Trans- former Feed-Forward Layers Are Key-Value Memories. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.),Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Domini- can Republic, 7-11 November, 2021, pp. 5484–5495....
2021
-
[7]
Ghandeharioun, A., Caciularu, A., Pearce, A., Dixon, L., and Geva, M
doi: 10.18653/V1/2021.EMNLP-MAIN.446. Ghandeharioun, A., Caciularu, A., Pearce, A., Dixon, L., and Geva, M. Patchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Mod- els. In Salakhutdinov, R., Kolter, Z., Heller, K. A., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.),Forty-First International Conference on Ma...
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[8]
and Liang, P
Hewitt, J. and Liang, P. Designing and Interpreting Probes with Control Tasks. In Inui, K., Jiang, J., Ng, V ., and Wan, X. (eds.),Proceedings of the 2019 Confer- ence on Empirical Methods in Natural Language Pro- cessing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pp....
2019
-
[9]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D
doi: 10.18653/V1/D19-1275. Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., Hennigan, T., Noland, E., Millican, K., van den Driessche, G., Damoc, B., Guy, A., Osindero, S., Simonyan, K., Elsen, E., Vinyals, O., Rae, J. W., and Sifre, L. An empirical analysis of compu...
-
[10]
R., Ewart, A., and Sharkey, L
Huben, R., Cunningham, H., Smith, L. R., Ewart, A., and Sharkey, L. Sparse Autoencoders Find Highly Inter- pretable Features in Language Models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[11]
Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling
Inan, H., Khosravi, K., and Socher, R. Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net,
2017
-
[12]
I., Chanin, D., Lau, Y ., Farrell, E., McDougall, C., Ayonrinde, K., Till, D., Wearden, M., Conmy, A., Marks, S., and Nanda, N
Karvonen, A., Rager, C., Lin, J., Tigges, C., Bloom, J. I., Chanin, D., Lau, Y ., Farrell, E., McDougall, C., Ayonrinde, K., Till, D., Wearden, M., Conmy, A., Marks, S., and Nanda, N. Saebench: A comprehen- sive benchmark for sparse autoencoders in language model interpretability. In Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Mahar...
2025
-
[13]
Makhzani, A
URL https://proceedings.mlr.press/ v267/karvonen25a.html. Makhzani, A. and Frey, B. J. K-Sparse Autoencoders. In Bengio, Y . and LeCun, Y . (eds.),2nd International Con- ference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Pro- ceedings,
2014
-
[14]
J., Belinkov, Y ., Bau, D., and Mueller, A
Marks, S., Rager, C., Michaud, E. J., Belinkov, Y ., Bau, D., and Mueller, A. Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[15]
Pointer Sentinel Mixture Models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer Sentinel Mixture Models. In5th International Confer- ence on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceed- ings. OpenReview.net,
2017
-
[16]
and Viswanath, P
Mu, J. and Viswanath, P. All-but-the-Top: Simple and Effective Postprocessing for Word Representations. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net,
2018
-
[17]
Automati- cally Interpreting Millions of Features in Large Language Models
Paulo, G., Mallen, A., Juang, C., and Belrose, N. Automati- cally Interpreting Millions of Features in Large Language Models. In Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., and Zhu, J. (eds.),Forty-Second International Conference on Ma- chine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025, Pr...
2025
-
[18]
and Wolf, L
Press, O. and Wolf, L. Using the Output Embedding to Improve Language Models. In Lapata, M., Blunsom, P., and Koller, A. (eds.),Proceedings of the 15th Con- ference of the European Chapter of the Association for Computational Linguistics, EACL 2017, Valencia, Spain, April 3-7, 2017, Volume 2: Short Papers, pp. 157–163. Association for Computational Linguistics,
2017
-
[19]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al
doi: 10.18653/V1/E17-2025. Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9,
-
[20]
BERT Rediscovers the Classical NLP Pipeline
Tenney, I., Das, D., and Pavlick, E. BERT Rediscovers the Classical NLP Pipeline. In Korhonen, A., Traum, D. R., and Màrquez, L. (eds.),Proceedings of the 57th Conference of the Association for Computational Lin- guistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pp. 4593–4601. As- sociation for Computational Linguistics,
2019
-
[21]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A
doi: 10.18653/V1/P19-1452. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is All you Need. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V . N., and Garnett, R. (eds.),Advances in Neural Information Processing Systems 30: Annual Conference on ...
-
[22]
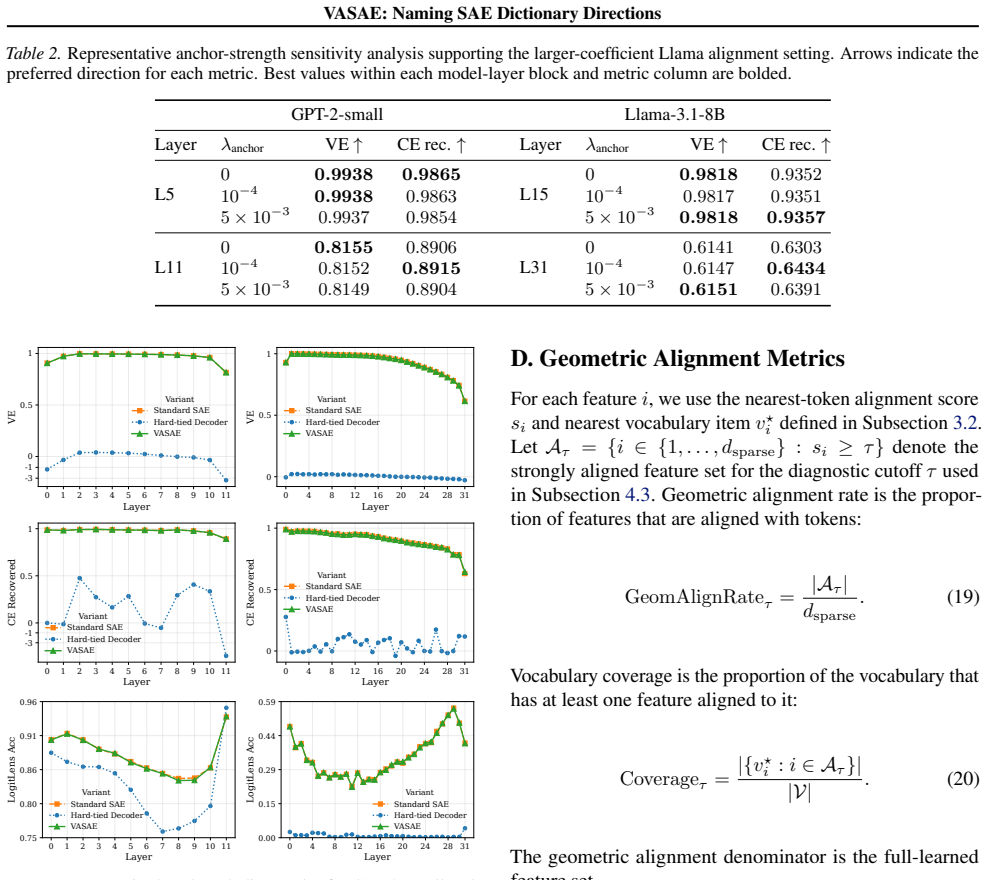
For substitution r∈ {SAE,Id,0} , let p(r) i be the resulting next-token distribution at evaluated position i, and let yi be the target next token. The average next-token cross-entropy is CEr =− 1 M MX i=1 logp (r) i (yi).(16) Here r= SAE uses ˜h, r= Id uses the original h, and r= 0uses0. The CE loss reported in Table 1 isCE SAE. CE rec.We compute CE recov...
-
[23]
The examples show displayed names around award-related and self- introduction contexts
Color indicates the raw sparse-code activation of that feature. The examples show displayed names around award-related and self- introduction contexts. F .Implementation Details for Similarity Score Computing the similarity scores {si}dsparse i=1 defined in Equa- tion 7 independently for each feature requires a nested loop over the vocabulary size |V| and...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.