Parallel Rollout Approximation for Pixel-Space Autoregressive Image Generation
Pith reviewed 2026-06-29 04:56 UTC · model grok-4.3
The pith
Parallel Rollout Approximation trains pixel-space autoregressive models to match inference conditions while staying parallel.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
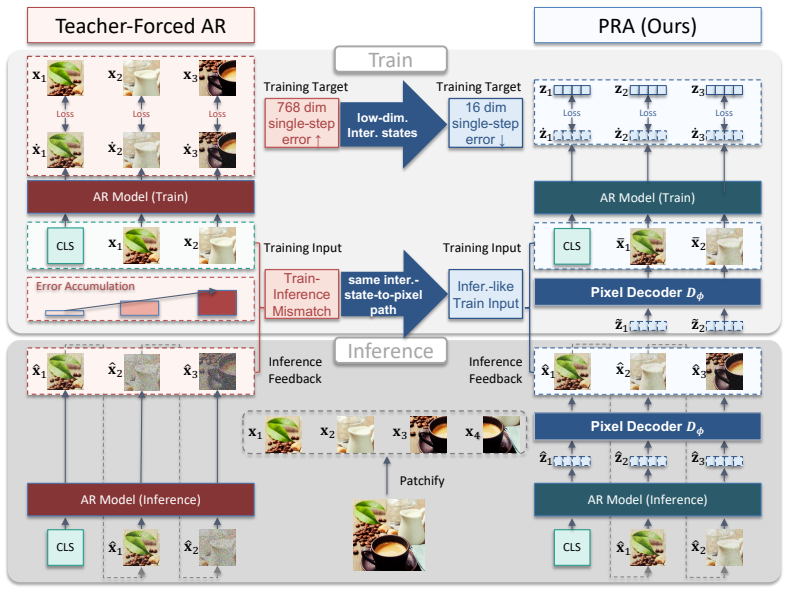
PRA generates low-dimensional intermediate states instead of high-dimensional pixel patches, then maps them back to pixel-space tokens with a pixel decoder, preserving a pixel-in, pixel-out AR interface. It also constructs inference-like pixel inputs through the same intermediate-state-to-pixel path used at inference, independently across positions, approximating the pixel-feedback interface encountered during inference-time rollout while retaining parallel teacher-forced training.
What carries the argument
Parallel Rollout Approximation (PRA), which replaces direct high-dimensional patch prediction with intermediate states decoded to pixels to build training inputs that match inference rollout conditions.
If this is right
- Pixel-space AR models can reach competitive FID scores without needing billion-parameter scales or separate tokenizers.
- Training remains fully parallel while still reducing the distribution shift that causes error accumulation over many autoregressive steps.
- The same trained models yield stronger representations for downstream classification probing than prior AR and diffusion baselines.
- Scaling model size from 135M to 511M parameters produces consistent FID gains from 2.58 to 1.94 on 256x256 ImageNet.
Where Pith is reading between the lines
- The method could extend to video or audio generation where sequential feedback is similarly expensive to simulate exactly during training.
- If the approximation remains stable at higher resolutions, it would lower the compute barrier for pixel-space AR compared with discrete-token alternatives.
- Unified generation-plus-understanding systems become more feasible because the pixel decoder already produces usable features for classification.
Load-bearing premise
That building inference-like pixel inputs independently across positions via the intermediate-state-to-pixel decoder path closely enough matches the sequential pixel feedback seen at inference time.
What would settle it
An experiment showing that models trained with PRA accumulate errors at the same rate as standard teacher-forced models when generating long sequences, or that exact rollout training still outperforms PRA by a large margin on the same architecture.
Figures

read the original abstract
Pixel-space continuous-token autoregressive (AR) generation directly models images as sequences of raw pixel patches, avoiding discrete tokenization or a separately pretrained tokenizer. However, it faces coupled challenges: high-dimensional patch generation causes large single-step errors, and teacher-forced training creates a train--inference gap that makes these errors accumulate across AR steps. Existing fixes such as $x$-prediction and input noise injection only partially mitigate these issues. Exact rollout training better matches inference-time conditions, but is impractical due to prohibitively slow sequential sampling. We propose \emph{Parallel Rollout Approximation} (PRA), a scalable framework that addresses both challenges jointly. PRA generates low-dimensional intermediate states instead of high-dimensional pixel patches, then maps them back to pixel-space tokens with a pixel decoder, preserving a pixel-in, pixel-out AR interface. It also constructs inference-like pixel inputs through the same intermediate-state-to-pixel path used at inference, independently across positions, approximating the pixel-feedback interface encountered during inference-time rollout while retaining parallel teacher-forced training. On class-conditional ImageNet-1K generation at $256\times256$ resolution, PRA-S with 135M parameters achieves an FID of 2.58, surpassing the previous billion-scale pixel-space AR result of 3.60. Scaling to PRA-L with 511M parameters further improves FID to 1.94, establishing a new state of the art among pixel-space AR models. Beyond generation, PRA achieves higher ImageNet classification probing accuracy than other AR and diffusion baselines, suggesting its potential for unified pixel-space image generation and understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Parallel Rollout Approximation (PRA) for pixel-space continuous-token autoregressive image generation. PRA predicts low-dimensional intermediate states rather than high-dimensional pixel patches, decodes them to pixel tokens via a shared path, and constructs inference-like pixel inputs independently across positions to approximate the sequential pixel-feedback interface while retaining parallel teacher-forced training. On class-conditional ImageNet-1K at 256×256, PRA-S (135M parameters) reports FID 2.58 and PRA-L (511M) reports FID 1.94, surpassing the prior billion-scale pixel-space AR result of 3.60 and establishing a new state of the art among pixel-space AR models; additional gains in ImageNet classification probing accuracy are also reported.
Significance. If the parallel construction demonstrably aligns the training distribution with inference-time rollout without substantial mismatch, the work would advance efficient pixel-space AR modeling by jointly addressing high-dimensional error accumulation and the train-inference gap, enabling smaller models to outperform much larger baselines and opening a path toward unified pixel-space generation and understanding. The concrete scaling behavior and external benchmark improvements would then constitute a clear reference point for the field.
major comments (2)
- [§3.2] §3.2: The central claim that independently applying the intermediate-state-to-pixel decoder across positions 'approximates the pixel-feedback interface encountered during inference-time rollout' is load-bearing for closing the train-inference gap, yet the manuscript supplies no quantitative measurement (e.g., KL divergence between parallel and sequential input distributions, or empirical single-step error accumulation) of the approximation quality.
- [Abstract / §4] Abstract / §4: The reported FID values of 2.58 (PRA-S) and 1.94 (PRA-L) are presented as evidence of effectiveness, but no ablations isolate the contribution of the parallel rollout construction versus other design choices, and no direct verification that the method reduces the train-inference gap (as opposed to external benchmark comparison) is included.
minor comments (1)
- The abstract's reference to 'x-prediction' should be clarified (e.g., as x_0-prediction) to align with standard notation in the AR literature.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and agree that additional quantitative analysis would strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2: The central claim that independently applying the intermediate-state-to-pixel decoder across positions 'approximates the pixel-feedback interface encountered during inference-time rollout' is load-bearing for closing the train-inference gap, yet the manuscript supplies no quantitative measurement (e.g., KL divergence between parallel and sequential input distributions, or empirical single-step error accumulation) of the approximation quality.
Authors: We agree that direct quantitative measurements of the approximation quality would provide stronger support for the claim. The manuscript demonstrates effectiveness via end-to-end metrics, but we will add experiments in the revision that quantify input distribution mismatch (e.g., via statistical distances) and single-step error accumulation between the parallel and sequential settings. revision: yes
-
Referee: [Abstract / §4] Abstract / §4: The reported FID values of 2.58 (PRA-S) and 1.94 (PRA-L) are presented as evidence of effectiveness, but no ablations isolate the contribution of the parallel rollout construction versus other design choices, and no direct verification that the method reduces the train-inference gap (as opposed to external benchmark comparison) is included.
Authors: The FID scores are benchmarked against prior pixel-space AR models. We acknowledge that isolating the parallel rollout contribution via ablations and providing direct measurements of train-inference gap reduction would be valuable. We will incorporate these ablations and controlled rollout experiments in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical benchmarks and design choices remain independent of fitted inputs
full rationale
The paper's core claims consist of a proposed architectural/training modification (PRA) whose validity is assessed via external FID and classification metrics on ImageNet-1K. No equations, parameter fits, or self-citations are shown to reduce the reported performance numbers or the method definition itself to quantities that are tautological with the inputs. The parallel approximation is presented as an engineering choice whose closeness to true rollout is left for empirical verification rather than enforced by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- intermediate state dimensionality
axioms (1)
- domain assumption The pixel decoder can map intermediate states back to pixel tokens while preserving sufficient information for the autoregressive interface to remain valid.
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
1901
-
[2]
arXiv preprint arXiv:2504.07963 (2025)
Shoufa Chen, Chongjian Ge, Shilong Zhang, Peize Sun, and Ping Luo. Pixelflow: Pixel-space generative models with flow.arXiv preprint arXiv:2504.07963,
-
[3]
Adam: A Method for Stochastic Optimization
URL https: //openreview.net/forum?id=H13wHRiL3i. Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2502.17437 (2025)
Tianhong Li, Qinyi Sun, Lijie Fan, and Kaiming He. Fractal generative models.arXiv preprint arXiv:2502.17437,
-
[6]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Uni- 3dar: Unified 3d generation and understanding via autoregression on compressed spatial tokens
Shuqi Lu, Haowei Lin, Lin Yao, Zhifeng Gao, Xiaohong Ji, Linfeng Zhang, Guolin Ke, et al. Uni- 3dar: Unified 3d generation and understanding via autoregression on compressed spatial tokens. arXiv preprint arXiv:2503.16278,
-
[9]
Autoregressive speech synthesis without vector quantization.arXiv preprint arXiv:2407.08551,
Lingwei Meng, Long Zhou, Shujie Liu, Sanyuan Chen, Bing Han, Shujie Hu, Yanqing Liu, Jinyu Li, Sheng Zhao, Xixin Wu, et al. Autoregressive speech synthesis without vector quantization.arXiv preprint arXiv:2407.08551,
-
[10]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[11]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
12 Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024a. Yutao Sun, Hangbo Bao, Wenhui Wang, Zhiliang Peng, Li Dong, Shaohan Huang, Jianyong Wang, and Furu Wei. Multimodal latent language modeling with next-...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2411.19722 (2024)
URLhttps://arxiv.org/abs/2411.19722. Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30,
-
[14]
arXiv preprint arXiv:2507.23268 (2025)
Shuai Wang, Ziteng Gao, Chenhui Zhu, Weilin Huang, and Limin Wang. Pixnerd: Pixel neural field diffusion.arXiv preprint arXiv:2507.23268, 2025a. Shuai Wang, Zhi Tian, Weilin Huang, and Limin Wang. Ddt: Decoupled diffusion transformer.arXiv preprint arXiv:2504.05741, 2025b. Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming op...
-
[15]
Vector-quantized Image Modeling with Improved VQGAN
Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized image modeling with improved vqgan. arXiv preprint arXiv:2110.04627,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with represen- tation autoencoders.arXiv preprint arXiv:2510.11690, 2025a. Guangting Zheng, Qinyu Zhao, Tao Yang, Fei Xiao, Zhijie Lin, Jie Wu, Jiajun Deng, Yanyong Zhang, and Rui Zhu. Farmer: Flow autoregressive transformer over pixels.arXiv preprint arXiv:2510.23588, 2025b. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Class conditioning is injected through K=16 learnable prefix tokens, obtained from an embedding table indexed by the class label and prepended to the patch sequence
A.2 Causal AR Transformerf θ The backbone is a causal Transformer [Vaswani et al., 2017] with pre-RMSNorm attention [Zhang and Sennrich, 2019], SwiGLU feed-forward layers [Shazeer, 2020], and 2-D rotary position embeddings (RoPE) [Su et al., 2024] over patch coordinates. Class conditioning is injected through K=16 learnable prefix tokens, obtained from an...
2017
-
[19]
With probabilitypsample, a training example is selected for masking; within selected examples, each token is replaced by a learned mask embedding with probability ptoken
To encourage zi to depend on causal context rather than only the current patch, we use two-level encoder masking during training. With probabilitypsample, a training example is selected for masking; within selected examples, each token is replaced by a learned mask embedding with probability ptoken. Unless otherwise specified, we usep sample=0.9andp token...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.