Recursive Self-Evolving Agents via Held-Out Selection
Pith reviewed 2026-06-30 11:10 UTC · model grok-4.3
The pith
RSEA's held-out selection ensures recursive self-evolution of LLM agents never regresses below the base performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
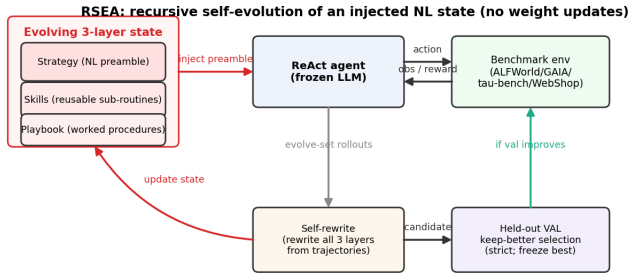
By maintaining a three-layer natural-language state and committing rewrites only when they do not regress on a held-out split, RSEA achieves recursive self-evolution that is monotone-safe: it never significantly underperforms the base agent on any benchmark and reverts to vanilla ReAct when evolved context would reduce performance.
What carries the argument
The keep-better gate on a disjoint held-out split that accepts an evolved three-layer state only if performance is at least as good as the prior state.
If this is right
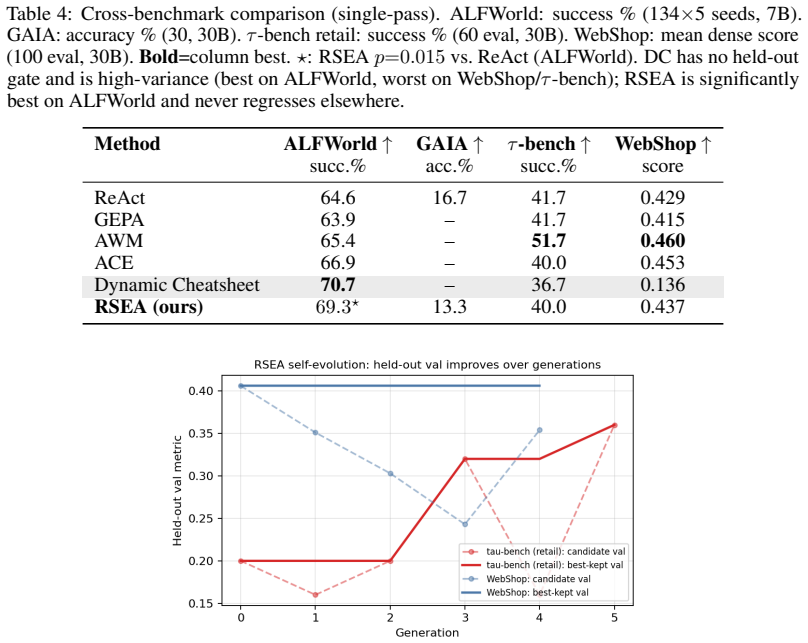
- RSEA reaches 69.3 percent on ALFWorld versus 64.6 percent for ReAct and 79.4 percent with retry.
- Unguarded methods such as Dynamic Cheatsheet reach near-best scores on ALFWorld yet fall to 0.14 on WebShop against ReAct's 0.43.
- RSEA never significantly underperforms the base agent and falls back to ReAct when evolution would hurt.
- No single artifact-evolution method wins on every benchmark; concrete-workflow induction is strongest on strong-backbone tool-use tasks.
Where Pith is reading between the lines
- The same non-regression gate could be added to other context-evolution techniques to reduce their variance without altering their rewriting logic.
- The three-layer state may serve as a reusable template for organizing evolved knowledge in other agent architectures.
- Monotone safety may become a standard requirement for any recursive improvement loop that conditions a frozen policy.
Load-bearing premise
The held-out split remains truly disjoint from the trajectories used for rewriting and is representative enough that non-regression on it guarantees non-regression on the full task distribution.
What would settle it
A case in which RSEA accepts an update via the held-out gate yet produces a statistically significant drop on the full benchmark distribution or on a new task outside the original four.
Figures

read the original abstract
LLM agents are increasingly improved without weight updates by evolving a natural-language artifact, such as reflections, workflows, playbooks, cheatsheets, or optimized prompts, that conditions a frozen policy. Such methods are typically reported as wins on the single benchmark where they help. We study them apples-to-apples and surface a sharper picture. We introduce RSEA, a Recursive Self-Evolving Agent that carries a compact three-layer natural-language state: an imperative strategy, reusable skills, and a procedural playbook. Across generations, RSEA rewrites all three layers from its own trajectories and commits a candidate only if it does not regress on a disjoint held-out split, using a strict keep-better gate. Across four diverse benchmarks, ALFWorld, GAIA, (\tau)-bench, and WebShop, and six faithful baselines, ReAct, Reflexion, GEPA, AWM, ACE, and Dynamic Cheatsheet, all evaluated on one shared local backbone, we find three main results. First, no artifact universally wins. RSEA is the strongest single-pass method on ALFWorld, reaching 69.3% compared with 64.6% for ReAct (McNemar (p=0.015)), and reaches 79.4% with retry, the best overall result. However, concrete-workflow induction, represented by AWM, is best on the strong-backbone tool-use tasks. Second, unguarded context evolution is high-variance and unsafe. Dynamic Cheatsheet, which curates context online without a held-out gate, is near-best on ALFWorld at 70.7%, yet collapses on WebShop, with a score of 0.14 compared with 0.43 for ReAct. Third, RSEA's strict held-out selection is what makes recursive self-evolution monotone-safe: it never significantly underperforms the base agent on any benchmark and falls back to vanilla ReAct when evolved context would hurt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RSEA, a recursive self-evolving LLM agent that maintains a compact three-layer natural-language state (imperative strategy, reusable skills, procedural playbook) and evolves it from its own trajectories. Evolution is guarded by a strict keep-better gate that only commits a candidate if it does not regress on a disjoint held-out split. Across ALFWorld, GAIA, τ-bench, and WebShop, and against six baselines (ReAct, Reflexion, GEPA, AWM, ACE, Dynamic Cheatsheet) on a shared backbone, the paper reports that RSEA is strongest on ALFWorld (69.3% vs. 64.6% ReAct, McNemar p=0.015), that unguarded evolution is high-variance and unsafe (e.g., Dynamic Cheatsheet collapses on WebShop), and that the held-out gate renders recursive evolution monotone-safe by never significantly underperforming the base agent.
Significance. If the held-out gate reliably ensures non-regression, the work supplies a practical, reproducible mechanism for safe context evolution in frozen-policy agents, addressing a recurring failure mode in reflection- and playbook-based methods. The multi-benchmark, single-backbone comparison is a strength, as is the explicit algorithmic rule (keep-better) rather than a fitted or self-referential quantity. The empirical demonstration that no artifact wins universally is useful for the field.
major comments (2)
- [Abstract] Abstract: the central claim that the held-out gate makes recursive evolution 'monotone-safe' (never significantly underperforms base agent) rests on the unvalidated assumption that non-regression on the held-out split implies non-regression on the full task distribution. No correlation analysis, cross-split validation, stratification by difficulty or task type, or representativeness checks are described, so the implication does not follow from the reported numbers alone.
- [Abstract] Abstract: headline results (69.3% vs 64.6%, McNemar p=0.015; 79.4% with retry) are given without error bars, number of runs, variance across seeds, or details on how the held-out split is constructed and sized relative to the evaluation set, preventing assessment of robustness or reproducibility of the non-regression claim.
minor comments (1)
- The three-layer state (imperative strategy, reusable skills, procedural playbook) is introduced without a precise specification of how each layer is initialized, updated, or represented in the prompt; a short pseudocode or example would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the robustness of the monotone-safe claim and the need for clearer statistical details. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the held-out gate makes recursive evolution 'monotone-safe' (never significantly underperforms base agent) rests on the unvalidated assumption that non-regression on the held-out split implies non-regression on the full task distribution. No correlation analysis, cross-split validation, stratification by difficulty or task type, or representativeness checks are described, so the implication does not follow from the reported numbers alone.
Authors: The held-out split is constructed as a random disjoint subset drawn from the same benchmark data pool as the evaluation set, ensuring it samples the same task distribution. The empirical results across four benchmarks demonstrate that RSEA never significantly underperforms the base ReAct agent, consistent with the gate's conservative design. We agree that direct evidence of correlation between held-out and evaluation performance would further support the claim. In the revised manuscript we will add a correlation analysis between held-out and evaluation scores, plus stratification by task type and difficulty where data permit. revision: yes
-
Referee: [Abstract] Abstract: headline results (69.3% vs 64.6%, McNemar p=0.015; 79.4% with retry) are given without error bars, number of runs, variance across seeds, or details on how the held-out split is constructed and sized relative to the evaluation set, preventing assessment of robustness or reproducibility of the non-regression claim.
Authors: We agree that variance measures, run counts, and split-construction details are necessary for reproducibility. The current version reports the McNemar p-value but omits seed-level variance. In revision we will add results averaged over five random seeds with standard deviations, explicitly state the held-out construction (random 20% disjoint split from each benchmark's data), and report its size relative to the evaluation set. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents RSEA as an algorithmic procedure (three-layer state evolution with an explicit keep-better gate on a disjoint held-out split) and supports its claims via direct empirical comparisons against baselines on fixed benchmarks. No equations, fitted parameters, or self-referential definitions appear; the monotone-safety result is an observed outcome of the rule rather than a quantity defined in terms of itself. The held-out gate is a design choice, not derived from the reported scores, and the evaluation uses shared backbones without load-bearing self-citations or uniqueness theorems. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The held-out split is representative of the task distribution and remains disjoint from trajectories used for rewriting.
invented entities (1)
-
RSEA three-layer natural-language state (imperative strategy, reusable skills, procedural playbook)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A. Agrawal et al. GEPA: Reflective prompt evolution can outperform reinforcement learning. arXiv preprint arXiv:2507.19457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Hanyu Cai, Binqi Shen, Lier Jin, Lan Hu, and Xiaojing Fan. Does tone change the answer? evaluating prompt politeness effects on modern llms: Gpt, gemini, llama.arXiv preprint arXiv:2512.12812,
-
[3]
Prototype conditioned generative replay for continual learning in NLP
Xi Chen and Min Zeng. Prototype conditioned generative replay for continual learning in NLP. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pages 12754–12770,
2025
-
[4]
9 Zhen Fang, Zhuoyang Liu, Jiaming Liu, Hao Chen, Yu Zeng, Shiting Huang, Zehui Chen, Lin Chen, Shanghang Zhang, and Feng Zhao. DualVLA: Building a generalizable embodied agent via partial decoupling of reasoning and action.arXiv preprint arXiv:2511.22134,
-
[5]
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel. Promptbreeder: Self-referential self-improvement via prompt evolution.arXiv preprint arXiv:2309.16797,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Ruiyan Han, Zhen Fang, XinYu Sun, Yuchen Ma, Ziheng Wang, Yu Zeng, Zehui Chen, Lin Chen, Wenxuan Huang, Wei-Jie Xu, et al. UniCorn: Towards self-improving unified multimodal models through self-generated supervision.arXiv preprint arXiv:2601.03193,
-
[7]
Automated Design of Agentic Systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems.arXiv preprint arXiv:2408.08435,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Shiting Huang, Zhen Fang, Zehui Chen, Siyu Yuan, Junjie Ye, Yu Zeng, Lin Chen, Qi Mao, and Feng Zhao. CRITICTOOL: Evaluating self-critique capabilities of large language models in tool-calling error scenarios.arXiv preprint arXiv:2506.13977,
-
[9]
MaPPO: Maximum a Posteriori Preference Optimization with Prior Knowledge
Guangchen Lan, Huseyin A Inan, Sahar Abdelnabi, Janardhan Kulkarni, Lukas Wutschitz, Reza Shokri, Christopher G Brinton, and Robert Sim. Contextual integrity in LLMs via reasoning and reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2025a. Guangchen Lan, Sipeng Zhang, Tianle Wang, Yuwei Zhang, Daoan Zhang, Xinpeng Wei...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Visual detector compression via location-aware discrimi- nant analysis
Qizhen Lan, Jung Im Choi, and Qing Tian. Visual detector compression via location-aware discrimi- nant analysis. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3546–3555, 2026a. Qizhen Lan, Yu-Chun Hsu, Nida Saddaf Khan, and Xiaoqian Jiang. ReCo-KD: Region- and context-aware knowledge distillation for effi...
-
[11]
Weiting Liu, Han Wu, Yufei Kuang, Xiongwei Han, Tao Zhong, Jianfeng Feng, and Wenlian Lu. Automated optimization modeling via a localizable error-driven perspective.arXiv preprint arXiv:2602.11164,
-
[12]
Jiaxuan Lu, Ziyu Kong, Yemin Wang, Rong Fu, Haiyuan Wan, Cheng Yang, Wenjie Lou, Haoran Sun, Lilong Wang, Yankai Jiang, et al. Beyond static tools: Test-time tool evolution for scientific reasoning.arXiv preprint arXiv:2601.07641,
-
[13]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general ai assistants.arXiv preprint arXiv:2311.12983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards llms as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Hume: Introducing system-2 thinking in visual-language-action model.arXiv preprint arXiv:2505.21432,
11 Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Qi Lv, Yiwen Tang, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, et al. Hume: Introducing system-2 thinking in visual-language-action model.arXiv preprint arXiv:2505.21432,
-
[16]
Dynamic cheatsheet: Test-time learning with adaptive memory.arXiv preprint arXiv:2504.07952,
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory.arXiv preprint arXiv:2504.07952,
-
[17]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Lei Wang, Chen Ma, Xueyang Feng, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 2024a. Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory.arXiv preprint arXiv:2409.07429, 2024b. Hao Wu, Hui Li, and Yiyun Su. Bridging the perception-cognition gap: Re-engineering SAM2 with hi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
doi: 10.1109/BIBM66473. 2025.11357220. Zequn Xie. CONQUER: Context-aware representation with query enhancement for text-based person search.arXiv preprint arXiv:2601.18625,
-
[20]
Chat-driven text generation and interaction for person retrieval
Zequn Xie, Chuxin Wang, Yeqiang Wang, Sihang Cai, Shulei Wang, and Tao Jin. Chat-driven text generation and interaction for person retrieval. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5259–5270,
2025
-
[21]
Zequn Xie, Xin Liu, Boyun Zhang, Yuxiao Lin, Sihang Cai, and Tao Jin. HVD: Human vision-driven video representation learning for text-video retrieval.arXiv preprint arXiv:2601.16155, 2026a. Zequn Xie, Boyun Zhang, Yuxiao Lin, and Tao Jin. Delving deeper: Hierarchical visual perception for robust video-text retrieval.arXiv preprint arXiv:2601.12768, 2026b....
-
[22]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2023a. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, and Xing Wei. FutureSightDrive: Thinking visually with spatio-temporal cot for autonomous driving.arXiv preprint arXiv:2505.17685, 2025a. Shuang Zeng, Dekang Qi, Xinyuan Chang, Feng Xiong, Shichao Xie, Xiaolong Wu, Shiyi Liang, Mu Xu, and Xing Wei. JanusVLN: Decoupling seman...
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Le Zhang, Rabiul Awal, and Aishwarya Agrawal. Contrasting intra-modal and ranking cross-modal hard negatives to enhance visio-linguistic compositional understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13774–13784, 2024a. Le Zhang, Yihong Wu, Qian Yang, and Jian-Yun Nie. Exploring the best prac...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Xiaoling Zhou, Ou Wu, and Nan Yang. Adversarial training with anti-adversaries.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 46(12):10210–10227, 2024a. Xiaoling Zhou, Wei Ye, Zhemg Lee, Rui Xie, and Shikun Zhang. Boosting model resilience via implicit adversarial data augmentation.arXiv preprint arXiv:2404.16307, 2024b. Yongchao ...
-
[26]
Chunzheng Zhu, Yangfang Lin, Shen Chen, Yijun Wang, and Jianxin Lin. MedEyes: Learning dynamic visual focus for medical progressive diagnosis.arXiv preprint arXiv:2511.22018, 2025a. Chunzheng Zhu, Yangfang Lin, Jialin Shao, Jianxin Lin, and Yijun Wang. Pathology-aware prototype evolution via LLM-driven semantic disambiguation for multicenter diabetic reti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.