Evidence-Driven LLM Agent for C-to-Synthesizable-C Conversion and Verification
Pith reviewed 2026-06-30 01:40 UTC · model grok-4.3
The pith
An evidence-isolated four-stage verifier and mismatch localization chain lets LLM agents convert ordinary C into synthesizable HLS-C more reliably than prior models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
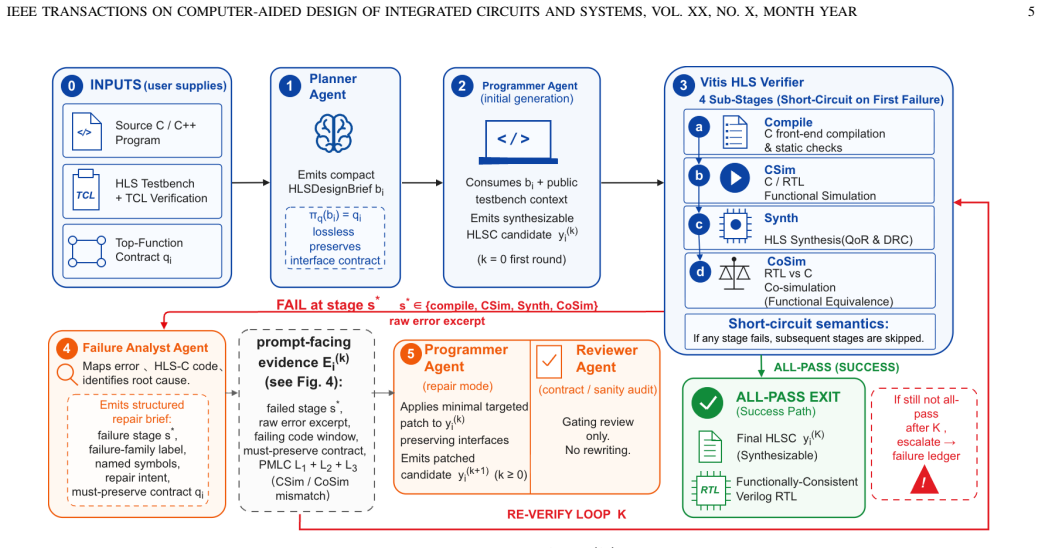
The end-to-end workflow of cooperating agents closed by the four-stage verifier under strict evidence isolation, together with the Progressive Mismatch Localization Chain and typed-query two-stage evidence RAG backed by a self-evolving family-routed repair-card pool, produces C programs that complete the full HLS pipeline where previous LLM systems do not.
What carries the argument
The four-stage verifier under strict evidence isolation, which supplies only normalized diagnostic signals to the agents instead of raw tool logs, closing the generation-verification-diagnosis-repair loop.
If this is right
- The workflow covers all four HLS pipeline stages rather than stopping at C compilation or CSim.
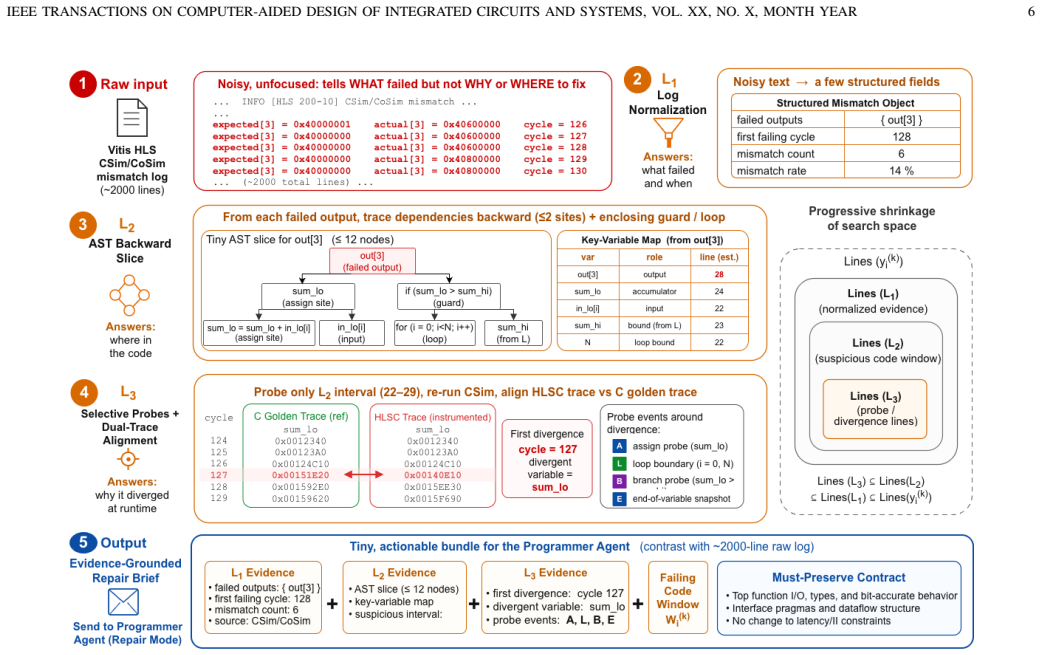
- Progressive mismatch localization reduces the search space for repairs by identifying exact source locations of CSim and CoSim failures.
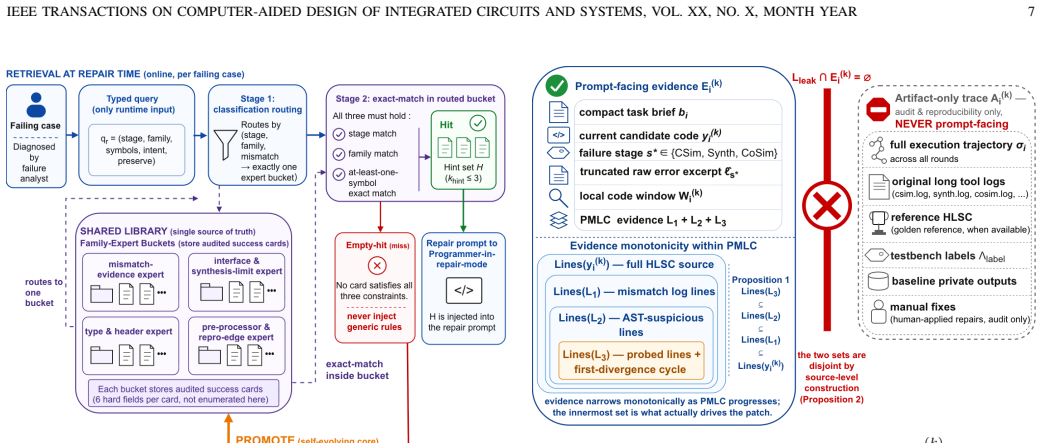
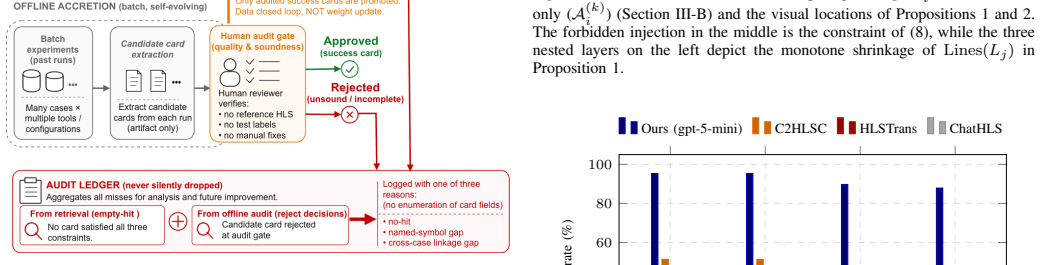
- The self-evolving repair-card pool accumulates evidence across runs and routes it by code family.
- Strict evidence isolation prevents the model from seeing unprocessed tool output and thereby improves reproducibility.
Where Pith is reading between the lines
- The same isolation pattern could be applied to other synthesis or compilation toolchains beyond Xilinx Vitis.
- If the repair-card pool is seeded with human-written fixes, the method might bootstrap from fewer LLM calls.
- Dual-trace instrumentation inside PMLC could be reused for debugging ordinary software mismatches unrelated to hardware synthesis.
Load-bearing premise
The four-stage verifier under strict evidence isolation supplies sufficient, unbiased diagnostic signals for the agents to converge on correct repairs without the evaluation becoming circular or overly optimistic.
What would settle it
A benchmark of C programs on which the agent workflow reports successful CoSim passes yet the generated RTL fails timing or resource checks when placed on the target FPGA.
Figures

read the original abstract
Software-compilable C programs routinely fail to complete the four-stage pipeline of a high-level synthesis (HLS) toolchain -- compilation, C simulation (CSim), synthesis, and C/RTL co-simulation (CoSim) -- because HLS accepts only a synthesizable subset of C (HLS-C). Yet most existing large language model (LLM) systems built for HLS code repair only cover the early pipeline stages and feed raw tool logs directly to the model, yielding brittle and hard-to-reproduce fixes. We formulate C-to-HLS-C conversion as a closed-loop generation-verification-diagnosis-repair problem on an HLS tool (Xilinx Vitis), contributing three components: an end-to-end workflow of cooperating agents closed by the four-stage verifier under strict evidence isolation; a Progressive Mismatch Localization Chain (PMLC) that localizes CSim/CoSim mismatches through log normalization, AST backward slicing, and dual-trace instrumentation; and a typed-query, two-stage evidence RAG backed by a self-evolving, family-routed repair-card pool. Experimental results show that the proposed workflow substantially outperforms all comparable state-of-the-art models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates C-to-HLS-C conversion as a closed-loop generation-verification-diagnosis-repair problem on Xilinx Vitis. It contributes an end-to-end multi-agent workflow closed by a four-stage verifier under strict evidence isolation, a Progressive Mismatch Localization Chain (PMLC) that combines log normalization, AST backward slicing, and dual-trace instrumentation, and a typed-query two-stage evidence RAG backed by a self-evolving family-routed repair-card pool. The central claim is that this workflow substantially outperforms comparable state-of-the-art models.
Significance. If the experimental results hold, the work could advance automated repair for the full HLS pipeline by replacing raw-log feedback with isolated, structured diagnostic signals. The explicit use of evidence isolation and family-routed routing directly targets circularity risks in agent feedback loops, which is a constructive architectural choice. However, the absence of any quantitative results, baselines, dataset size, or statistical tests in the provided text prevents assessment of whether these components deliver the claimed gains.
major comments (1)
- [Abstract] Abstract: the claim that 'Experimental results show that the proposed workflow substantially outperforms all comparable state-of-the-art models' is unsupported by any numbers, baselines, dataset size, or statistical tests, so the central empirical contribution cannot be evaluated from the given text.
Simulated Author's Rebuttal
We thank the referee for identifying the need for concrete evidence to support the abstract's central claim. We address this point directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Experimental results show that the proposed workflow substantially outperforms all comparable state-of-the-art models' is unsupported by any numbers, baselines, dataset size, or statistical tests, so the central empirical contribution cannot be evaluated from the given text.
Authors: We agree that the abstract's empirical claim requires supporting detail for evaluation. The full manuscript contains an Experiments section that reports results on a benchmark suite of C programs, including direct comparisons against prior LLM-based HLS repair baselines, dataset cardinality, pass rates through the four-stage Vitis pipeline, and statistical significance. To make this evidence visible at the abstract level, we will revise the abstract to include the key quantitative outcomes (success rates, relative improvements, and dataset size) while preserving its length constraints. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical LLM-agent workflow for HLS code repair, with components including a four-stage verifier under evidence isolation, PMLC for mismatch localization, and typed-query RAG. No equations, fitted parameters, or derivation chains appear in the provided abstract or claimed architecture. The central outperformance claim rests on experimental results rather than any self-definitional reduction, fitted-input prediction, or self-citation load-bearing step. The explicit mention of strict evidence isolation directly addresses potential circularity risks in the closed-loop process, leaving the evaluation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Progressive Mismatch Localization Chain (PMLC)
no independent evidence
-
typed-query two-stage evidence RAG with self-evolving repair-card pool
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey and evaluation of fpga high-level synthesis tools,
R. Nane, V .-M. Sima, C. Pilato, J. Choi, B. Fort, A. Canis, Y . T. Chen, H. Hsiao, S. Brown, F. Ferrandi et al. , “A survey and evaluation of fpga high-level synthesis tools,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , vol. 35, no. 10, pp. 1591– 1604, 2015
2015
-
[2]
Are we there yet? a study on the state of high-level synthesis,
S. Lahti, P . Sjövall, J. V anne, and T. D. Hämäläinen, “Are we there yet? a study on the state of high-level synthesis,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , vol. 38, no. 5, pp. 898–911, 2018
2018
-
[3]
Fpga hls today: successes, challenges, and opportunities,
J. Cong, J. Lau, G. Liu, S. Neuendorffer, P . Pan, K. Vissers, and Z. Zhang, “Fpga hls today: successes, challenges, and opportunities,” ACM Transactions on Reconfigurable Technology and Systems (TRETS) , vol. 15, no. 4, pp. 1–42, 2022
2022
-
[4]
StarCoder: may the source be with you!
R. Li, L. B. Allal, Y . Zi, N. Muennighoff, D. Kocetkov, C. Mou, M. Marone, C. Akiki, J. Li, J. Chim et al. , “Starcoder: may the source be with you!” arXiv preprint arXiv:2305.06161 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
V erigen: A large language model for verilog code generation,
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “V erigen: A large language model for verilog code generation,” ACM Transactions on Design Automation of Electronic Systems , vol. 29, no. 3, pp. 1–31, 2024
2024
-
[6]
V erilogeval: Evaluating large language models for verilog code generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “V erilogeval: Evaluating large language models for verilog code generation,” in 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD) . IEEE, 2023, pp. 1–8
2023
-
[7]
Rtllm: An open-source benchmark for design rtl generation with large language model,
Y . Lu, S. Liu, Q. Zhang, and Z. Xie, “Rtllm: An open-source benchmark for design rtl generation with large language model,” in 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC) . IEEE, 2024, pp. 722–727
2024
-
[8]
Rtlcoder: Outperforming gpt-3.5 in design rtl generation with our open-source dataset and lightweight solution,
S. Liu, W. Fang, Y . Lu, Q. Zhang, H. Zhang, and Z. Xie, “Rtlcoder: Outperforming gpt-3.5 in design rtl generation with our open-source dataset and lightweight solution,” in 2024 IEEE LLM Aided Design Workshop (LAD). IEEE, 2024, pp. 1–5
2024
-
[9]
Rtlfixer: Automatically fixing rtl syntax errors with large language model,
Y . Tsai, M. Liu, and H. Ren, “Rtlfixer: Automatically fixing rtl syntax errors with large language model,” in Proceedings of the 61st ACM/IEEE Design Automation Conference , 2024, pp. 1–6
2024
-
[10]
C2hlsc: Leveraging large language models to bridge the software-to-hardware design gap,
L. Collini, S. Garg, and R. Karri, “C2hlsc: Leveraging large language models to bridge the software-to-hardware design gap,” ACM Transac- tions on Design Automation of Electronic Systems , vol. 30, no. 6, pp. 1–24, 2025
2025
-
[11]
Hlstrans: Dataset for c-to-hls hardware code synthesis,
Q. Zou, N. Chen, Y . Chen, B. He, and W. Wong, “Hlstrans: Dataset for c-to-hls hardware code synthesis,” arXiv preprint arXiv:2507.04315 , 2025
-
[12]
ChatHLS: Towards Systematic Design Automation and Optimization for High-Level Synthesis
R. Li, J. Xiong, X. He, J. Zhao, J. Lv, H. Fang, L. Qi, and X. Wang, “Chathls: Towards systematic design automation and optimization for high-level synthesis,” arXiv preprint arXiv:2507.00642 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Hls-eval: A benchmark and framework for evaluating llms on high-level synthesis design tasks,
S. Abi-Karam and C. Hao, “Hls-eval: A benchmark and framework for evaluating llms on high-level synthesis design tasks,” in 2025 IEEE International Conference on LLM-Aided Design (ICLAD) . IEEE, 2025, pp. 219–226
2025
-
[14]
High-level synthesis design space explo- ration: Past, present, and future,
B. C. Schafer and Z. Wang, “High-level synthesis design space explo- ration: Past, present, and future,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , vol. 39, no. 10, pp. 2628– 2639, 2019
2019
-
[15]
Bambu: an open-source research framework for the high-level synthesis of complex applica- tions,
F. Ferrandi, V . G. Castellana, S. Curzel, P . Fezzardi, M. Fiorito, M. Lat- tuada, M. Minutoli, C. Pilato, and A. Tumeo, “Bambu: an open-source research framework for the high-level synthesis of complex applica- tions,” in 2021 58th ACM/IEEE Design Automation Conference (DAC) . IEEE, 2021, pp. 1327–1330
2021
-
[16]
From c/c++ code to high- performance dataflow circuits,
L. Josipovi ´c, A. Guerrieri, and P . Ienne, “From c/c++ code to high- performance dataflow circuits,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , vol. 41, no. 7, pp. 2142–2155, 2021. IEEE TRANSACTIONS ON COMPUTER-AIDED DESIGN OF INTEGRA TED CIRCUITS AND SYSTEMS, VOL. XX, NO. X, MONTH YEAR 10
2021
-
[17]
Autodse: Enabling software programmers to design efficient fpga accelerators,
A. Sohrabizadeh, C. H. Y u, M. Gao, and J. Cong, “Autodse: Enabling software programmers to design efficient fpga accelerators,” ACM Trans- actions on Design Automation of Electronic Systems (TODAES) , vol. 27, no. 4, pp. 1–27, 2022
2022
-
[18]
Chstone: A benchmark program suite for practical c-based high-level synthesis,
Y . Hara, H. Tomiyama, S. Honda, H. Takada, and K. Ishii, “Chstone: A benchmark program suite for practical c-based high-level synthesis,” in 2008 IEEE International Symposium on Circuits and Systems (ISCAS) . IEEE, 2008, pp. 1192–1195
2008
-
[19]
Mach- suite: Benchmarks for accelerator design and customized architectures,
B. Reagen, R. Adolf, Y . S. Shao, G.-Y . Wei, and D. Brooks, “Mach- suite: Benchmarks for accelerator design and customized architectures,” in 2014 IEEE International Symposium on Workload Characterization (IISWC). IEEE, 2014, pp. 110–119
2014
-
[20]
Rosetta: A realistic high-level synthesis benchmark suite for software programmable fpgas,
Y . Zhou, U. Gupta, S. Dai, R. Zhao, N. Srivastava, H. Jin, J. Feath- erston, Y .-H. Lai, G. Liu, G. A. V elasquez et al. , “Rosetta: A realistic high-level synthesis benchmark suite for software programmable fpgas,” in Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays , 2018, pp. 269–278
2018
-
[21]
To- wards a comprehensive benchmark for high-level synthesis targeted to fpgas,
Y . Bai, A. Sohrabizadeh, Z. Qin, Z. Hu, Y . Sun, and J. Cong, “To- wards a comprehensive benchmark for high-level synthesis targeted to fpgas,” Advances in Neural Information Processing Systems , vol. 36, pp. 45 288–45 299, 2023
2023
-
[22]
Hlspilot: Llm-based high-level syn- thesis,
C. Xiong, C. Liu, H. Li, and X. Li, “Hlspilot: Llm-based high-level syn- thesis,” in Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design , 2024, pp. 1–9
2024
-
[23]
Sage-hls: Syntax-aware ast-guided llm for high-level synthesis code generation,
M. Z. S. Khan, N. Mashnoor, M. Akyash, K. Azar, and H. Kamali, “Sage-hls: Syntax-aware ast-guided llm for high-level synthesis code generation,” in 2025 IEEE 43rd International Conference on Computer Design (ICCD) . IEEE, 2025, pp. 574–581
2025
-
[24]
Synthai: A multi agent generative ai framework for automated modular hls design generation,
S. A. Sheikholeslam and A. Ivanov, “Synthai: A multi agent generative ai framework for automated modular hls design generation,” arXiv preprint arXiv:2405.16072, 2024
-
[25]
Automated c/c++ program repair for high-level synthesis via large lan- guage models,
K. Xu, G. L. Zhang, X. Yin, C. Zhuo, U. Schlichtmann, and B. Li, “Automated c/c++ program repair for high-level synthesis via large lan- guage models,” in Proceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD , 2024, pp. 1–9
2024
-
[26]
Hlsrewriter: Efficient refactoring and optimization of c/c++ code with llms for high-level synthesis,
K. Xu, G. L. Zhang, X. Yin, C. Zhuo, U. Schlichtmann, and B. Li, “Hlsrewriter: Efficient refactoring and optimization of c/c++ code with llms for high-level synthesis,” ACM Transactions on Design Automation of Electronic Systems , vol. 31, no. 4, pp. 1–21, 2026
2026
-
[27]
Hlsdebugger: Identification and cor- rection of logic bugs in hls code with llm solutions,
J. Wang, S. Liu, Y . Lu, and Z. Xie, “Hlsdebugger: Identification and cor- rection of logic bugs in hls code with llm solutions,” in 2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD) . IEEE, 2025, pp. 1–9
2025
-
[28]
Correcthdl: Agentic hdl design with llms leveraging high-level synthesis as reference,
K. Xu, G. L. Zhang, U. Schlichtmann, and B. Li, “Correcthdl: Agentic hdl design with llms leveraging high-level synthesis as reference,” arXiv preprint arXiv:2511.16395 , 2025
-
[29]
Automatic software repair: A bibliography,
M. Monperrus, “Automatic software repair: A bibliography,” ACM Com- puting Surveys (CSUR) , vol. 51, no. 1, pp. 1–24, 2018
2018
-
[30]
Automated program repair in the era of large pre-trained language models,
C. S. Xia, Y . Wei, and L. Zhang, “Automated program repair in the era of large pre-trained language models,” in 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) . IEEE, 2023, pp. 1482–1494
2023
-
[31]
Repair is nearly generation: Multilingual program repair with llms,
H. Joshi, J. C. Sanchez, S. Gulwani, V . Le, G. V erbruggen, and I. Radi ˇcek, “Repair is nearly generation: Multilingual program repair with llms,” in Proceedings of the AAAI Conference on Artificial Intelli- gence, vol. 37, no. 4, 2023, pp. 5131–5140
2023
-
[32]
Repairagent: An autonomous, llm-based agent for program repair,
I. Bouzenia, P . Devanbu, and M. Pradel, “Repairagent: An autonomous, llm-based agent for program repair,” in 2025 IEEE/ACM 47th Interna- tional Conference on Software Engineering (ICSE) . IEEE, 2025, pp. 2188–2200
2025
-
[33]
VeriMoA: A Mixture-of-Agents Framework for Spec-to-HDL Generation
H. Ping, A. Bhattacharjee, P . Zhang, S. Li, W. Y ang, A. Cheng, X. Zhang, J. Thomason, A. Jannesari, N. Ahmed et al. , “V erimoa: A mixture-of-agents framework for spec-to-hdl generation,” arXiv preprint arXiv:2510.27617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Z. Ibnat, P . E. Calzada, R. M. Ihtemam, S. K. Saha, J. Zhou, F. Farahmandi, and M. Tehranipoor, “Deepv: a model-agnostic retrieval- augmented framework for verilog code generation with a high-quality knowledge base,” arXiv preprint arXiv:2510.05327 , 2025
-
[35]
Lift: Llm-based pragma insertion for hls via gnn supervised fine-tuning,
N. Prakriya, Z. Ding, Y . Sun, and J. Cong, “Lift: Llm-based pragma insertion for hls via gnn supervised fine-tuning,” arXiv preprint arXiv:2504.21187, 2025
-
[36]
Timelyhls: Llm- based timing-aware and architecture-specific fpga hls optimization,
N. Mashnoor, M. Akyash, H. Kamali, and K. Azar, “Timelyhls: Llm- based timing-aware and architecture-specific fpga hls optimization,” in 2025 IEEE International Conference on Omni-layer Intelligent Systems (COINS). IEEE, 2025, pp. 1–6
2025
-
[37]
Agenttts: Large language model agent for test- time compute-optimal scaling strategy in complex tasks,
F. Wang, H. Liu, Z. Dai, J. Zeng, Z. Zhang, Z. Wu, C. Luo, Z. Li, X. Tang, Q. He et al. , “Agenttts: Large language model agent for test- time compute-optimal scaling strategy in complex tasks,” Advances in Neural Information Processing Systems , vol. 38, pp. 98 396–98 433, 2026
2026
-
[38]
Can reasoning models reason about hardware? an agentic hls perspective,
L. Collini, A. Hennessee, R. Karri, and S. Garg, “Can reasoning models reason about hardware? an agentic hls perspective,” in 2025 IEEE In- ternational Conference on LLM-Aided Design (ICLAD) . IEEE, 2025, pp. 188–194
2025
-
[39]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P . Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küt- tler, M. Lewis, W.-t. Yih, T. Rocktäschel et al. , “Retrieval-augmented generation for knowledge-intensive nlp tasks,” Advances in neural in- formation processing systems , vol. 33, pp. 9459–9474, 2020
2020
-
[40]
Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection,
A. Asai, Z. Wu, Y . Wang, A. Sil, and H. Hajishirzi, “Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection,” in Inter- national conference on learning representations , vol. 2024, 2024, pp. 9112–9141
2024
-
[41]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, D. Metropolitansky, R. O. Ness, and J. Larson, “From local to global: A graph rag approach to query-focused summarization,” arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Y ao, J. Zhao, D. Y u, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” arXiv preprint arXiv:2210.03629 , 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
Self-refine: Iter- ative refinement with self-feedback,
A. Madaan, N. Tandon, P . Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Y ang et al. , “Self-refine: Iter- ative refinement with self-feedback,” Advances in neural information processing systems , vol. 36, pp. 46 534–46 594, 2023
2023
-
[44]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu et al. , “Autogen: Enabling next-gen llm applications via multi-agent conversation,” arXiv preprint arXiv:2308.08155 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Ask-eda: A design assistant empowered by llm, hybrid rag and abbreviation de-hallucination,
L. Shi, M. Kazda, B. Sears, N. Shropshire, and R. Puri, “Ask-eda: A design assistant empowered by llm, hybrid rag and abbreviation de-hallucination,” in 2024 IEEE LLM Aided Design Workshop (LAD) . IEEE, 2024, pp. 1–5
2024
-
[46]
Orassistant: A cus- tom rag-based conversational assistant for openroad,
A. Kaintura, S. S. Luar, I. I. Almeida et al. , “Orassistant: A cus- tom rag-based conversational assistant for openroad,” arXiv preprint arXiv:2410.03845, 2024. Zhe Zhao is currently pursuing the M.E. degree in integrated circuits and systems with the Shenzhen International Graduate School, Tsinghua Univer- sity, Shenzhen, China. His research interests i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.