Detecting Clinical Hallucinations in LVLMs via Counterfactual Visual Grounding Uncertainty
Pith reviewed 2026-06-30 01:33 UTC · model grok-4.3
The pith
A framework audits arbitrary responses from clinical vision-language models by grounding extracted entities and scoring uncertainty through counterfactual image perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
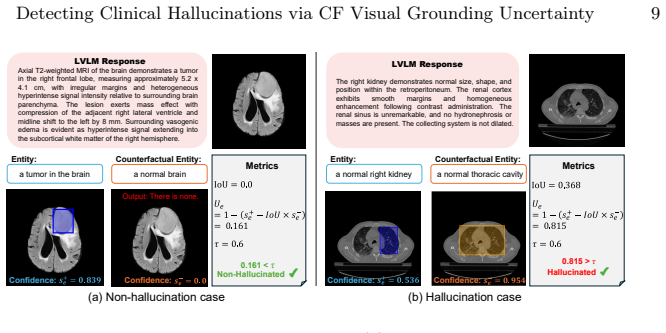
The central claim is that entity-level hallucination decisions can be made by computing a visual evidence uncertainty score that contrasts factual grounding results against those obtained after counterfactual entity perturbation; the score is formed from positive confidence, counterfactual confidence, and their grounding overlap, and this procedure yields improved detection performance, interpretable localization, and cross-model transfer without requiring changes to the target LVLM.
What carries the argument
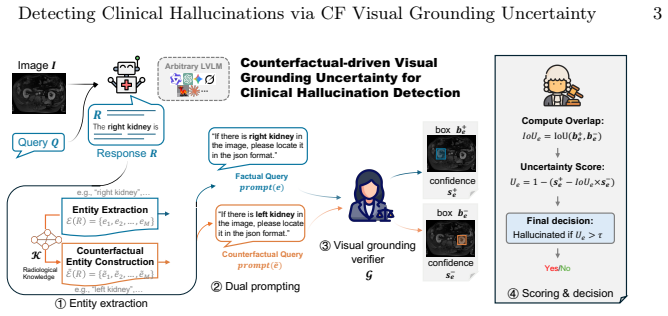
Counterfactual visual grounding uncertainty: the mechanism that extracts entities, localizes them factually and after perturbation, then derives an uncertainty score for binary hallucination classification.
If this is right
- The method improves hallucination detection performance over recent baselines on multiple medical imaging modalities and LVLM backbones.
- It supplies interpretable localization evidence for each detected hallucination.
- It exhibits strong cross-model transferability without retraining the target LVLM.
Where Pith is reading between the lines
- The same grounding-plus-counterfactual pattern could be tested on non-clinical image domains where entity localization verifiers already exist.
- If the uncertainty scores prove stable under different verifiers, the framework might support auditing pipelines that swap in new grounding models as they improve.
Load-bearing premise
The domain-adapted grounding verifier accurately localizes entities taken from arbitrary LVLM responses on clinical images.
What would settle it
A held-out test set of clinical images with known hallucinated versus supported entities where the uncertainty scores fail to separate the two groups at rates better than chance.
Figures

read the original abstract
Large vision-language models (LVLMs) are increasingly used for clinical image understanding, yet they remain vulnerable to \emph{hallucinations}--producing textual findings or attributes not supported by the image. We present a vision-traceable hallucination detection framework that audits arbitrary LVLM responses via visual evidence grounding, requiring neither modification nor internal access to the hidden states of LVLMs. Given an LVLM response, we extract visually verifiable entities and use a medical-domain-adapted Qwen-VL grounding verifier to localize each entity on the input image. To enhance the robustness of our detection method, we introduce a counterfactual entity perturbation method and estimate visual evidence uncertainty by contrasting factual and counterfactual grounding results. Specifically, we compute an entity-level uncertainty score from the positive confidence, counterfactual confidence, and their grounding overlap for binary hallucination decision-making. Experiments on multiple medical imaging modalities and LVLM backbones demonstrate that our method consistently improves hallucination detection performance over recent baselines, while providing interpretable localization evidence and strong cross-model transferability. Code and dataset are available at https://github.com/Agentic-CliniAI/CounterVHD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a black-box hallucination detection framework for LVLMs on clinical images. Given an LVLM response, entities are extracted and localized on the input image by a medical-domain-adapted Qwen-VL grounding verifier. A counterfactual entity perturbation is applied to produce factual and counterfactual grounding maps; an entity-level uncertainty score is then computed from positive confidence, counterfactual confidence, and grounding overlap to yield binary hallucination decisions. The authors claim consistent gains over recent baselines across multiple medical imaging modalities and LVLM backbones, plus interpretable localization evidence and strong cross-model transferability. Code and dataset are released.
Significance. If the central claims hold, the work supplies a practical, model-agnostic auditing tool that does not require hidden-state access—an important capability for safe clinical deployment of LVLMs. The counterfactual contrast and grounding-based uncertainty metric constitute a distinct technical contribution relative to prior logit- or embedding-based detectors. Releasing code and data supports reproducibility.
major comments (1)
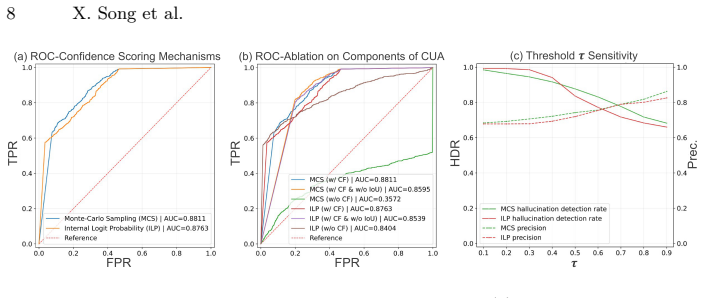
- [Abstract / Method] Abstract and method description: the binary hallucination decisions and the claimed cross-model transferability rest on the accuracy of the medical-adapted Qwen-VL grounding verifier when applied to entities extracted from arbitrary target LVLM responses. No independent localization benchmark (IoU, pointing accuracy, or similar) is reported for this verifier on the precise distribution of clinical entities that appear in the evaluated responses.
minor comments (1)
- [Abstract] The abstract supplies no quantitative metrics, dataset sizes, statistical tests, or ablation results, which prevents readers from assessing the magnitude or reliability of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The single major comment raises a valid point about the grounding verifier's accuracy, which we address below with a commitment to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the binary hallucination decisions and the claimed cross-model transferability rest on the accuracy of the medical-adapted Qwen-VL grounding verifier when applied to entities extracted from arbitrary target LVLM responses. No independent localization benchmark (IoU, pointing accuracy, or similar) is reported for this verifier on the precise distribution of clinical entities that appear in the evaluated responses.
Authors: We agree that the absence of a direct, independent localization benchmark for the medical-adapted Qwen-VL verifier on entities drawn from the target LVLM responses is a limitation. While the verifier was domain-adapted and the end-to-end hallucination detection gains (plus cross-model transfer) provide indirect support for its utility, a standalone evaluation (e.g., IoU or pointing accuracy on annotated clinical entities) would more rigorously substantiate the claims. In the revised manuscript we will add such a benchmark: we will manually annotate a representative subset of entities extracted from the evaluated responses across modalities and report localization metrics for the verifier. This addition will also clarify the basis for the reported cross-model transferability. revision: yes
Circularity Check
No circularity; method uses external verifier and contrastive perturbation
full rationale
The derivation extracts entities, applies an external medical-adapted Qwen-VL grounding verifier, generates counterfactual perturbations, and computes an uncertainty score from positive/counterfactual confidence plus overlap. None of these steps reduce by definition or self-citation to the hallucination labels being evaluated; the chain remains independent of the target data and does not invoke load-bearing self-citations or fitted-input predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A medical-domain-adapted Qwen-VL model can reliably localize extracted entities in clinical images.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Chen, J., Yang, D., Wu, T., Jiang, Y., Hou, X., Li, M., Wang, S., Xiao, D., Li, K., Zhang, L.: Detecting and evaluating medical hallucinations in large vision language models. arXiv preprint arXiv:2406.10185 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Chen, X., Wang, C., Xue, Y., Zhang, N., Yang, X., Li, Q., Shen, Y., Liang, L., Gu, J., Chen, H.: Unified hallucination detection for multimodal large language models. In: ACL. pp. 3235–3252 (2024)
2024
-
[4]
In: CVPR
Cheng, J., Fu, B., Ye, J., Wang, G., Li, T., Wang, H., Li, R., Yao, H., Cheng, J., Li, J., et al.: Interactive medical image segmentation: A benchmark dataset and baseline. In: CVPR. pp. 20841–20851 (2025) 10 X. Song et al
2025
-
[5]
Hardy, R., Kim, S.E., Rajpurkar, P., et al.: Rextrust: A model for fine-grained hallucinationdetectioninai-generatedradiologyreports.In:AAAIBridgeProgram on AI for Medicine and Healthcare. pp. 173–182 (2025)
2025
-
[6]
In: Findings of EMNLP
Jing, L., Li, R., Chen, Y., Du, X.: Faithscore: Fine-grained evaluations of hallu- cinations in large vision-language models. In: Findings of EMNLP. pp. 5042–5063 (2024)
2024
-
[7]
In: MICCAI
Khanal, B., Pokhrel, S., Bhandari, S., Rana, R., Shrestha, N., Gurung, R.B., Linte, C., Watson, A., Shrestha, Y.R., Bhattarai, B.: Hallucination-aware multimodal benchmark for gastrointestinal image analysis with large vision-language models. In: MICCAI. pp. 235–245. Springer (2025)
2025
-
[8]
In: Findings of EMNLP
Li, Q., Geng, J., Lyu, C., Zhu, D., Panov, M., Karray, F.: Reference-free hallu- cination detection for large vision-language models. In: Findings of EMNLP. pp. 4542–4551 (2024)
2024
-
[9]
In: MIC- CAI
Liao, Z., Hu, S., Zou, K., Fu, H., Zhen, L., Xia, Y.: Vision-amplified semantic entropy for hallucination detection in medical visual question answering. In: MIC- CAI. pp. 669–679. Springer (2025)
2025
-
[10]
arXiv preprint arXiv:2503.20504 (2025)
Liao, Z., Hu, S., Zou, K., Jin, M., Zhang, Y., Fu, H., Zhen, L., Xia, Y.: Univrse: Unified vision-conditioned response semantic entropy for hallucination detection in medical vision-language models. arXiv preprint arXiv:2503.20504 (2025)
-
[11]
OpenAI: Introducing GPT-5 (Aug 2025),https://openai.com/zh-Hans-CN/ index/introducing-gpt-5
2025
-
[12]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al.: Medgemma technical report. arXiv preprint arXiv:2507.05201 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
In: ACM BCB
Song, X., Liu, J., Liu, Y., Li, Y., Lei, W., Wang, R.: Rethinking radiology report generation via causal inspired counterfactual augmentation. In: ACM BCB. pp. 1–10 (2024)
2024
-
[14]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Wang, J., Wang, Y., Xu, G., Zhang, J., Gu, Y., Jia, H., Wang, J., Xu, H., Yan, M., Zhang, J., et al.: Amber: An llm-free multi-dimensional benchmark for mllms hallucination evaluation. arXiv preprint arXiv:2311.07397 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
xAI: Grok 4 (Jul 2025),https://x.ai/news/grok-4
2025
-
[17]
In: AAAI
Xiao, W., Huang, Z., Gan, L., He, W., Li, H., Yu, Z., Shu, F., Jiang, H., Zhu, L.: Detecting and mitigating hallucination in large vision language models via fine- grained ai feedback. In: AAAI. vol. 39, pp. 25543–25551 (2025)
2025
-
[18]
IEEE Trans
Zou, K., Bai, Y., Liu, B., Chen, Y., Chen, Z., Zhou, Y., Yuan, X., Wang, M., Shen, X., Cao, X., et al.: Uncertainty-aware medical diagnostic phrase identification and grounding. IEEE Trans. Pattern Anal. Mach. Intell. (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.