AEGIR: Modeling Area Emitters for Indoor Inverse Rendering using Gaussian Splatting
Pith reviewed 2026-07-01 06:16 UTC · model grok-4.3
The pith
Explicit area emitters in Gaussian Splatting separate illumination from materials more accurately than point lights or environment maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
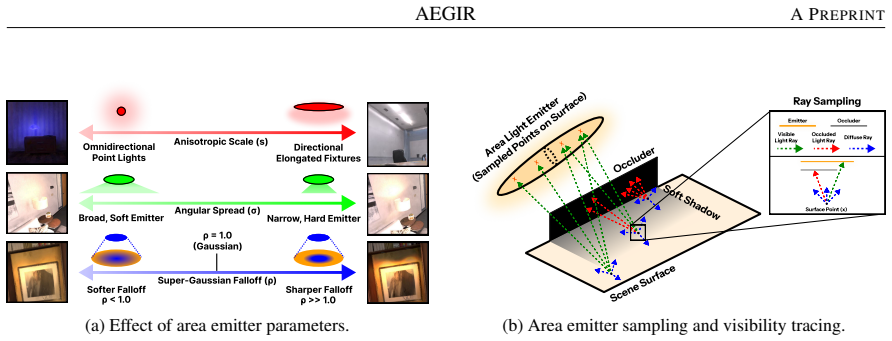
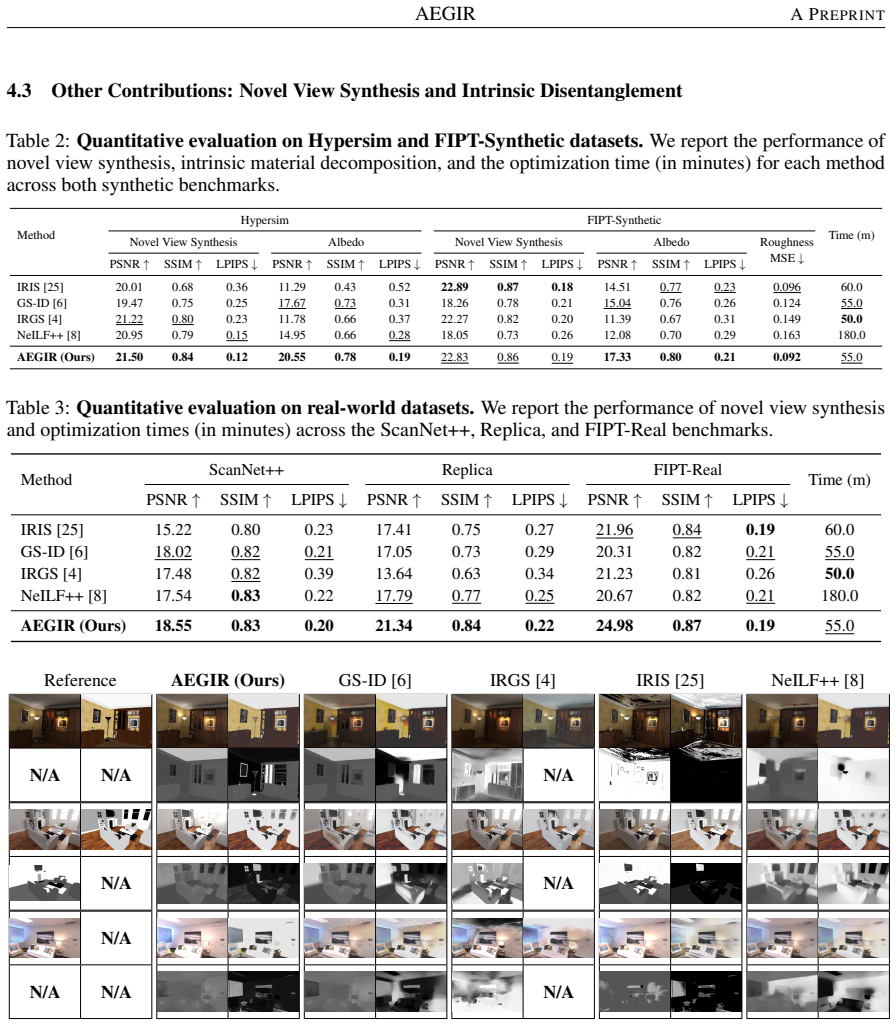
AEGIR explicitly models local area emitters within a relightable Gaussian Splatting representation. Joint optimization of emitters, materials, and geometry is achieved by a differentiable deferred rendering pipeline that integrates multiple importance sampling with targeted regularization. As a result, the method accurately simulates local light transport and produces a more consistent decomposition of illumination from materials.
What carries the argument
A differentiable deferred rendering pipeline that integrates multiple importance sampling with targeted regularization to enable joint optimization of area emitters, materials, and geometry.
If this is right
- Explicit area emitters produce correct light attenuation and realistic shadows in the reconstructed scenes.
- Novel view synthesis, controlled relighting, and virtual object insertion achieve higher quality, especially under complex local lighting.
- Illumination reconstruction improves over approximations that rely on discrete point lights, global environment maps, or implicit representations.
Where Pith is reading between the lines
- The same pipeline might support more precise material recovery when the method is applied to augmented-reality insertion tasks.
- Extending the emitter model to handle time-varying area sources could enable relighting of short video sequences.
- Testing the decomposition on captures that contain many overlapping local lights would reveal whether the regularization terms remain sufficient.
Load-bearing premise
The added degrees of freedom from flexible emitter shapes can be disambiguated from materials and geometry by multiple importance sampling and targeted regularization.
What would settle it
A side-by-side comparison of rendered shadows and intensity falloff against ground-truth measurements in a scene lit by a known rectangular emitter would show whether the area-emitter model matches physical behavior better than point-light approximations.
Figures










read the original abstract
Inverse rendering requires separating illumination from surface materials, which is highly ambiguous due to their tight coupling in observed images. While Gaussian Splatting is efficient for novel view synthesis, existing relightable methods approximate scene lighting using discrete point lights, global environment maps, or implicit representations. By ignoring the physical spatial extent of real-world emitters, these approaches produce incorrect light attenuation and unrealistic shadows. We present AEGIR (Area Emitters for Gaussian Inverse Rendering), a framework that explicitly models local area emitters within a relightable Gaussian Splatting representation. Joint optimization of emitters, materials, and geometry is challenging due to flexible emitter parameterization, which increases both the number of parameters and the ambiguity between illumination and materials. We address this by introducing a differentiable deferred rendering pipeline that integrates multiple importance sampling with targeted regularization. As a result, AEGIR accurately simulates local light transport and achieves more consistent decomposition. Experiments show that explicit area emitters improve illumination reconstruction and enhance downstream tasks, including novel view synthesis, controlled relighting, and virtual object insertion, particularly in scenes with complex local lighting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AEGIR, a Gaussian Splatting framework for indoor inverse rendering that explicitly parameterizes local area emitters rather than approximating them with point lights or environment maps. It introduces a differentiable deferred rendering pipeline combining multiple importance sampling and targeted regularization to jointly optimize emitters, materials, and geometry, claiming this yields more consistent illumination-material decomposition and improved results on novel view synthesis, controlled relighting, and virtual object insertion, especially under complex local lighting.
Significance. If the experimental claims hold, the work would address a recognized limitation in relightable 3D Gaussian Splatting by better capturing spatially extended emitters and their attenuation/shadow effects. This could meaningfully improve accuracy for indoor relighting applications. The efficiency of the GS representation combined with the deferred pipeline is a potential strength, provided the regularization demonstrably prevents the increased parameter ambiguity from producing degenerate solutions.
major comments (2)
- The abstract asserts that 'Experiments show that explicit area emitters improve illumination reconstruction' and that the MIS+regularization pipeline achieves 'more consistent decomposition,' yet supplies no quantitative metrics, ablation tables, error analysis, or scene-specific results. This is load-bearing for the central claim because the method deliberately increases degrees of freedom via flexible emitter parameterization; without evidence that the regularization terms are sufficient to prevent common degeneracies (e.g., emitter energy absorbed into albedo), the improvement cannot be evaluated.
- The weakest assumption—that multiple importance sampling plus targeted regularization inside the differentiable deferred pipeline reliably disambiguates emitter parameters from materials and geometry—is stated but not supported by any derivation, weighting schedule, or failure-case analysis. Standard inverse-rendering experience indicates such ambiguities often survive MIS alone; a concrete test (e.g., controlled synthetic scenes with known ground-truth emitters) is required to substantiate the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions planned to strengthen the submission.
read point-by-point responses
-
Referee: The abstract asserts that 'Experiments show that explicit area emitters improve illumination reconstruction' and that the MIS+regularization pipeline achieves 'more consistent decomposition,' yet supplies no quantitative metrics, ablation tables, error analysis, or scene-specific results. This is load-bearing for the central claim because the method deliberately increases degrees of freedom via flexible emitter parameterization; without evidence that the regularization terms are sufficient to prevent common degeneracies (e.g., emitter energy absorbed into albedo), the improvement cannot be evaluated.
Authors: We agree that the abstract is high-level and contains no numerical results or tables. The experiments section of the manuscript reports quantitative metrics for novel-view synthesis, relighting, and object insertion together with ablation studies on the regularization terms. To directly address the concern about degeneracies, we will add a new analysis subsection that quantifies the effect of regularization on albedo-lighting separation using error metrics on both real and synthetic data. We will also revise the abstract to reference the key quantitative improvements. revision: yes
-
Referee: The weakest assumption—that multiple importance sampling plus targeted regularization inside the differentiable deferred pipeline reliably disambiguates emitter parameters from materials and geometry—is stated but not supported by any derivation, weighting schedule, or failure-case analysis. Standard inverse-rendering experience indicates such ambiguities often survive MIS alone; a concrete test (e.g., controlled synthetic scenes with known ground-truth emitters) is required to substantiate the claim.
Authors: We acknowledge that the current manuscript does not include a formal derivation of the MIS weights or an explicit failure-case study. The method section describes the integration of MIS with the chosen regularization terms. To substantiate the disambiguation claim, we will add controlled experiments on synthetic scenes that contain known ground-truth area emitters, reporting quantitative lighting and material errors with and without the regularization terms. revision: yes
Circularity Check
No circularity; method is empirical framework without self-referential derivation
full rationale
The paper presents a practical inverse-rendering pipeline (differentiable deferred rendering + MIS + regularization) for joint optimization of area emitters, materials, and geometry in Gaussian Splatting. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the supplied text that would reduce any claimed result to its own inputs by construction. The central claim rests on experimental outcomes rather than a closed mathematical derivation, making the work self-contained against external benchmarks and free of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InECCV, 2020
2020
-
[2]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
2023
-
[3]
Relightable 3d gaussians: Realistic point cloud relighting with brdf decomposition and ray tracing, 2023
Jian Gao, Chun Gu, Youtian Lin, Zhihao Li, Hao Zhu, Xun Cao, Li Zhang, and Yao Yao. Relightable 3d gaussians: Realistic point cloud relighting with brdf decomposition and ray tracing, 2023
2023
-
[4]
Irgs: Inter-reflective gaussian splatting with 2d gaussian ray tracing
Chun Gu, Xiaofei Wei, Zixuan Zeng, Yuxuan Yao, and Li Zhang. Irgs: Inter-reflective gaussian splatting with 2d gaussian ray tracing. InCVPR, 2025
2025
-
[5]
Intrinsic image diffusion for indoor single-view material estimation
Peter Kocsis, Vincent Sitzmann, and Matthias Nießner. Intrinsic image diffusion for indoor single-view material estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[6]
Gs-id: Illumination decomposition on gaussian splatting via adaptive light aggregation and diffusion-guided material priors, 2025
Kang Du, Zhihao Liang, Yulin Shen, and Zeyu Wang. Gs-id: Illumination decomposition on gaussian splatting via adaptive light aggregation and diffusion-guided material priors, 2025
2025
-
[7]
Neilf: Neural incident light field for physically-based material estimation
Yao Yao, Jingyang Zhang, Jingbo Liu, Yihang Qu, Tian Fang, David McKinnon, Yanghai Tsin, and Long Quan. Neilf: Neural incident light field for physically-based material estimation. InEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[8]
Neilf++: Inter-reflectable light fields for geometry and material estimation.International Conference on Computer Vision (ICCV), 2023
Jingyang Zhang, Yao Yao, Shiwei Li, Jingbo Liu, Tian Fang, David McKinnon, Yanghai Tsin, and Long Quan. Neilf++: Inter-reflectable light fields for geometry and material estimation.International Conference on Computer Vision (ICCV), 2023
2023
-
[9]
Ye Yu and William A. P. Smith. Inverserendernet: Learning single image inverse rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[10]
Inverse rendering for complex indoor scenes: Shape, spatially-varying lighting and svbrdf from a single image
Zhengqin Li, Mohammad Shafiei, Ravi Ramamoorthi, Kalyan Sunkavalli, and Manmohan Chandraker. Inverse rendering for complex indoor scenes: Shape, spatially-varying lighting and svbrdf from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[11]
Irisformer: Dense vision transformers for single-image inverse rendering in indoor scenes
Rui Zhu, Zhengqin Li, Janarbek Matai, Fatih Porikli, and Manmohan Chandraker. Irisformer: Dense vision transformers for single-image inverse rendering in indoor scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[12]
Jundan Luo, Duygu Ceylan, Jae Shin Yoon, Nanxuan Zhao, Julien Philip, Anna Frühstück, Wenbin Li, Christian Richardt, and Tuanfeng Y . Wang. IntrinsicDiffusion: Joint intrinsic layers from latent diffusion models. InSIGGRAPH 2024 Conference Papers, 2024. 10 AEGIRA PREPRINT
2024
-
[13]
Rgb↔x: Image decomposition and synthesis using material- and lighting-aware diffusion models
Zheng Zeng, Valentin Deschaintre, Iliyan Georgiev, Yannick Hold-Geoffroy, Yiwei Hu, Fujun Luan, Ling- Qi Yan, and Miloš Hašan. Rgb↔x: Image decomposition and synthesis using material- and lighting-aware diffusion models. InACM SIGGRAPH 2024 Conference Papers, SIGGRAPH ’24, New York, NY , USA,
2024
-
[15]
Diffusionrenderer: Neural inverse and forward rendering with video diffusion models
Ruofan Liang, Zan Gojcic, Huan Ling, Jacob Munkberg, Jon Hasselgren, Zhi-Hao Lin, Jun Gao, Alexander Keller, Nandita Vijaykumar, Sanja Fidler, and Zian Wang. Diffusionrenderer: Neural inverse and forward rendering with video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025
2025
-
[16]
IDArb: Intrinsic decompo- sition for arbitrary number of input views and illuminations
Zhibing Li, Tong Wu, Jing Tan, Mengchen Zhang, Jiaqi Wang, and Dahua Lin. IDArb: Intrinsic decompo- sition for arbitrary number of input views and illuminations. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[17]
Philipp Langsteiner, Jan-Niklas Dihlmann, and Hendrik P. A. Lensch. Matspray: Fusing 2d material world knowledge on 3d geometry, 2025
2025
-
[18]
Mvinverse: Feed-forward multi-view inverse rendering in seconds, 2025
Xiangzuo Wu, Chengwei Ren, Jun Zhou, Xiu Li, and Yuan Liu. Mvinverse: Feed-forward multi-view inverse rendering in seconds, 2025
2025
-
[19]
Barron, Ce Liu, and Hendrik P.A
Mark Boss, Raphael Braun, Varun Jampani, Jonathan T. Barron, Ce Liu, and Hendrik P.A. Lensch. Nerd: Neural reflectance decomposition from image collections. InIEEE International Conference on Computer Vision (ICCV), 2021
2021
-
[20]
Srinivasan, Boyang Deng, Paul Debevec, William T
Xiuming Zhang, Pratul P. Srinivasan, Boyang Deng, Paul Debevec, William T. Freeman, and Jonathan T. Barron. Nerfactor: Neural factorization of shape and reflectance under an unknown illumination.ACM Trans. Graph., 40(6), dec 2021
2021
-
[21]
Barron, and Hendrik P.A
Mark Boss, Varun Jampani, Raphael Braun, Ce Liu, Jonathan T. Barron, and Hendrik P.A. Lensch. Neural- pil: Neural pre-integrated lighting for reflectance decomposition. InAdvances in Neural Information Processing Systems, 2021
2021
-
[22]
Gs-ir: 3d gaussian splatting for inverse rendering, 2023
Zhihao Liang, Qi Zhang, Ying Feng, Ying Shan, and Kui Jia. Gs-ir: 3d gaussian splatting for inverse rendering, 2023
2023
-
[23]
Svg-ir: Spatially-varying gaussian splatting for inverse rendering, 2025
Hanxiao Sun, YuPeng Gao, Jin Xie, Jian Yang, and Beibei Wang. Svg-ir: Spatially-varying gaussian splatting for inverse rendering, 2025
2025
-
[24]
Geosplatting: Towards geometry guided gaussian splatting for physically-based inverse rendering
Kai Ye, Chong Gao, Guanbin Li, Wenzheng Chen, and Baoquan Chen. Geosplatting: Towards geometry guided gaussian splatting for physically-based inverse rendering. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 28991–29000, 2025
2025
-
[25]
Factorized inverse path tracing for efficient and accurate material-lighting estimation
Liwen Wu, Rui Zhu, Mustafa B Yaldiz, Yinhao Zhu, Hong Cai, Janarbek Matai, Fatih Porikli, Tzu-Mao Li, Manmohan Chandraker, and Ravi Ramamoorthi. Factorized inverse path tracing for efficient and accurate material-lighting estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3848–3858, 2023
2023
-
[26]
IRIS: Inverse rendering of indoor scenes from low dynamic range images
Chih-Hao Lin, Jia-Bin Huang, Zhengqin Li, Zhao Dong, Christian Richardt, Tuotuo Li, Michael Zollhöfer, Johannes Kopf, Shenlong Wang, and Changil Kim. IRIS: Inverse rendering of indoor scenes from low dynamic range images. InConference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[27]
Extracting Triangular 3D Models, Materials, and Lighting From Images
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas Müller, and Sanja Fidler. Extracting Triangular 3D Models, Materials, and Lighting From Images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8280–8290, June 2022
2022
-
[28]
Jon Hasselgren, Nikolai Hofmann, and Jacob Munkberg. Shape, Light, and Material Decomposition from Images using Monte Carlo Rendering and Denoising.arXiv:2206.03380, 2022
-
[29]
Reflective gaussian splatting
Yuxuan Yao, Zixuan Zeng, Chun Gu, Xiatian Zhu, and Li Zhang. Reflective gaussian splatting. InICLR, 2025
2025
-
[30]
Sgs-intrinsic: Semantic-invariant gaussian splatting for sparse-view indoor inverse rendering, 2026
Jiahao Niu, Rongjia Zheng, Wenju Xu, Wei-Shi Zheng, and Qing Zhang. Sgs-intrinsic: Semantic-invariant gaussian splatting for sparse-view indoor inverse rendering, 2026
2026
-
[31]
Mueller, Jozef Hladky, and Markus Steinberger
Arno Coomans, Edoardo Alberto Dominici, Christian Döring, Joerg H. Mueller, Jozef Hladky, and Markus Steinberger. Real-time Neural Rendering of Dynamic Light Fields.Computer Graphics F orum, 2024. 11 AEGIRA PREPRINT
2024
-
[32]
Learning-based inverse rendering of complex indoor scenes with differentiable monte carlo raytracing
Jingsen Zhu, Fujun Luan, Yuchi Huo, Zihao Lin, Zhihua Zhong, Dianbing Xi, Rui Wang, Hujun Bao, Jiax- iang Zheng, and Rui Tang. Learning-based inverse rendering of complex indoor scenes with differentiable monte carlo raytracing. InSIGGRAPH Asia 2022 Conference Papers. ACM, 2022
2022
-
[33]
PhySG: Inverse rendering with spherical gaussians for physics-based material editing and relighting
Kai Zhang, Fujun Luan, Qianqian Wang, Kavita Bala, and Noah Snavely. PhySG: Inverse rendering with spherical gaussians for physics-based material editing and relighting. InThe IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[34]
Fast spatially- varying indoor lighting estimation
Mathieu Garon, Kalyan Sunkavalli, Sunil Hadap, Nathan Carr, and Jean-François Lalonde. Fast spatially- varying indoor lighting estimation. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[35]
Spatiotemporally consistent hdr indoor lighting estimation, 2023
Zhengqin Li, Li Yu, Mikhail Okunev, Manmohan Chandraker, and Zhao Dong. Spatiotemporally consistent hdr indoor lighting estimation, 2023
2023
-
[36]
Diffusionlight: Light probes for free by painting a chrome ball
Pakkapon Phongthawee, Worameth Chinchuthakun, Nontaphat Sinsunthithet, Amit Raj, Varun Jampani, Pramook Khungurn, and Supasorn Suwajanakorn. Diffusionlight: Light probes for free by painting a chrome ball. InArXiv, 2023
2023
-
[37]
Spatiotemporally consistent indoor lighting estimation with diffusion priors
Mutian Tong, Rundi Wu, and Changxi Zheng. Spatiotemporally consistent indoor lighting estimation with diffusion priors. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, SIGGRAPH Conference Papers ’25, New York, NY , USA,
-
[38]
Association for Computing Machinery
-
[39]
Luxdit: Lighting estimation with video diffusion transformer.arXiv preprint arXiv:2509.03680, 2025
Ruofan Liang, Kai He, Zan Gojcic, Igor Gilitschenski, Sanja Fidler, Nandita Vijaykumar, and Zian Wang. Luxdit: Lighting estimation with video diffusion transformer.arXiv preprint arXiv:2509.03680, 2025
-
[40]
Deep parametric indoor lighting estimation
Marc-André Gardner, Yannick Hold-Geoffroy, Kalyan Sunkavalli, Christian Gagné, and Jean-François Lalonde. Deep parametric indoor lighting estimation. InThe IEEE International Conference on Computer Vision (ICCV), October 2019
2019
-
[41]
Luminet: Latent intrinsics meets diffusion models for indoor scene relighting
Xiaoyan Xing, Konrad Groh, Sezer Karaoglu, Theo Gevers, and Anand Bhattad. Luminet: Latent intrinsics meets diffusion models for indoor scene relighting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 442–452, 2025
2025
-
[42]
Luxremix: Lighting decomposition and remixing for indoor scenes, 2026
Ruofan Liang, Norman Müller, Ethan Weber, Duncan Zauss, Nandita Vijaykumar, Peter Kontschieder, and Christian Richardt. Luxremix: Lighting decomposition and remixing for indoor scenes, 2026
2026
-
[43]
2d gaussian splatting for geometrically accurate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically accurate radiance fields. InSIGGRAPH 2024 Conference Papers. Association for Computing Machinery, 2024
2024
-
[44]
A density-based algorithm for discovering clusters in large spatial databases with noise
Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. InProceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, pages 226–231. AAAI Press, 1996
1996
-
[45]
Dn- splatter: Depth and normal priors for gaussian splatting and meshing
Matias Turkulainen, Xuqian Ren, Iaroslav Melekhov, Otto Seiskari, Esa Rahtu, and Juho Kannala. Dn- splatter: Depth and normal priors for gaussian splatting and meshing. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
2025
-
[46]
Susskind
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InInternational Conference on Computer Vision (ICCV) 2021, 2021
2021
-
[47]
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke M. S...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[48]
Scannet++: A high-fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
2023
-
[49]
Parker, James Bigler, Andreas Dietrich, Heiko Friedrich, Jared Hoberock, David Luebke, David McAllister, Morgan McGuire, Keith Morley, Austin Robison, and Martin Stich
Steven G. Parker, James Bigler, Andreas Dietrich, Heiko Friedrich, Jared Hoberock, David Luebke, David McAllister, Morgan McGuire, Keith Morley, Austin Robison, and Martin Stich. Optix: a general purpose ray tracing engine.ACM Trans. Graph., 29(4), July 2010. 12 AEGIRA PREPRINT
2010
-
[50]
Mitsuba 3 renderer, 2022
Wenzel Jakob, Sébastien Speierer, Nicolas Roussel, Merlin Nimier-David, Delio Vicini, Tizian Zeltner, Baptiste Nicolet, Miguel Crespo, Vincent Leroy, and Ziyi Zhang. Mitsuba 3 renderer, 2022. https://mitsuba- renderer.org
2022
-
[51]
Rendering resources, 2016
Benedikt Bitterli. Rendering resources, 2016. https://benedikt-bitterli.me/resources/
2016
-
[52]
Spatiotem- poral reservoir resampling for real-time ray tracing with dynamic direct lighting.ACM Trans
Benedikt Bitterli, Chris Wyman, Matt Pharr, Peter Shirley, Aaron Lefohn, and Wojciech Jarosz. Spatiotem- poral reservoir resampling for real-time ray tracing with dynamic direct lighting.ACM Trans. Graph., 39(4), August 2020
2020
-
[53]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. A Deferred Rendering Details This section provides a detailed mathematical description of the deferred rendering pipeline of AEGIR, including the microfacet BRDF, light transport integration, d...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.