EVLA: An Electro-Aware Multimodal Assistant for Physically-Grounded Driving Reasoning and Control
Pith reviewed 2026-06-30 09:54 UTC · model grok-4.3
The pith
EVLA integrates real-time vehicle powertrain state into vision-language models to produce physically grounded driving decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
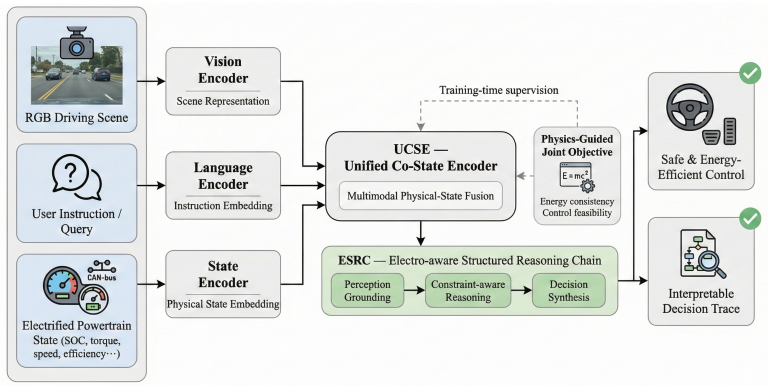
EVLA combines multi-modal scene understanding with real-time perception of the electrified powertrain state using a Unified Co-State Encoder that fuses visual, textual, and vehicle-state inputs into a shared latent representation augmented with an Energy-Efficiency Field, and an Electro-aware Structured Reasoning Chain that replaces external chain-of-thought with an internal deterministic reasoning process grounded in physical constraints and optimization objectives, trained end-to-end with a physics-guided joint loss to generate context-aware and energy-optimal driving decisions.
What carries the argument
The Unified Co-State Encoder (UCSE) fuses visual, textual, and vehicle-state inputs into a shared latent representation augmented with an Energy-Efficiency Field to model spatial energy costs, together with the Electro-aware Structured Reasoning Chain (ESRC) that performs internal deterministic reasoning grounded in physical constraints.
If this is right
- Driving decisions incorporate real-time motor torque and battery state of charge to respect actual vehicle capabilities.
- Decisions are generated as energy-optimal under explicit physical constraints via the internal reasoning chain.
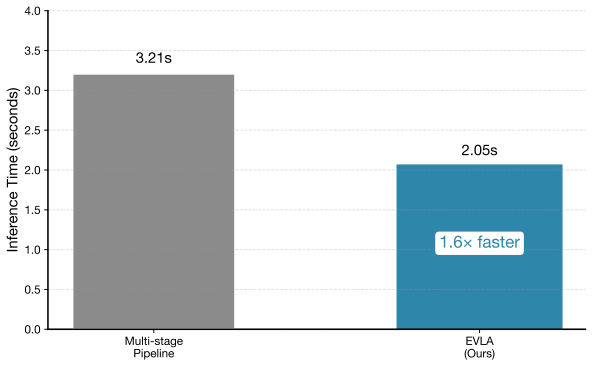
- Inference runs 36 percent faster than multi-stage pipelines that rely on external prompting.
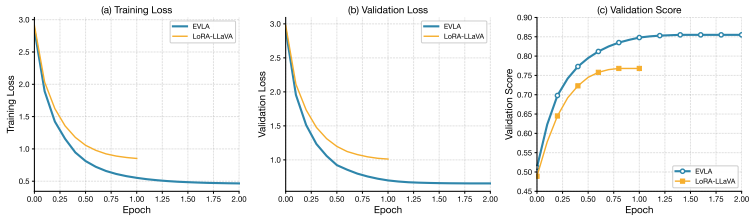
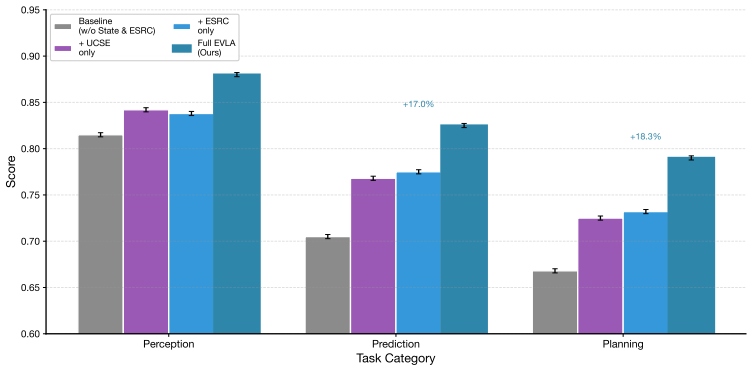
- Ablation studies confirm that removing the vehicle-state encoder or the structured reasoning chain reduces performance.
- The approach yields a final score improvement of 0.0871 and accuracy gain of 5.6 percent over strong fine-tuned VLM baselines.
Where Pith is reading between the lines
- The same fusion of state inputs and internal physical reasoning could be tested in non-driving control tasks such as robotic manipulation where actuator limits matter.
- Extending the Energy-Efficiency Field to include additional vehicle subsystems might reveal further optimization opportunities.
- Deployment on hardware with live sensor feeds would provide a direct test of whether benchmark gains translate to measurable energy savings on real roads.
- The internal reasoning chain might reduce reliance on large external language models for step-by-step guidance in other multimodal domains.
Load-bearing premise
The reported gains on the driving QA benchmark arise from the integration of vehicle-state awareness and the physics-guided loss rather than from differences in training data, model size, or evaluation protocol.
What would settle it
A controlled re-training of the baseline VLM models on the identical dataset and evaluation protocol used for EVLA, but without the UCSE or ESRC components, followed by direct comparison of final scores and accuracy on the driving QA benchmark.
Figures




read the original abstract
Modern vision-language models (VLMs) for driving assistants typically treat vehicle dynamics as a black box, resulting in decisions that lack awareness of the vehicle's real-time electro-mechanical state. To bridge this gap, we introduce the Electro-Visual-Language Assistant (EVLA) -- a novel framework that combines multi-modal scene understanding with real-time perception of the electrified powertrain state (e.g., motor torque, battery SOC). Our approach features two key innovations: first, a Unified Co-State Encoder (UCSE) that fuses visual, textual, and vehicle-state inputs into a shared latent representation, augmented with an Energy-Efficiency Field to model spatial energy costs; and second, an Electro-aware Structured Reasoning Chain (ESRC), which replaces external chain-of-thought prompting with an internal, deterministic reasoning process grounded in physical constraints and optimization objectives. Trained end-to-end with a physics-guided joint loss, EVLA learns to generate context-aware and energy-optimal driving decisions. Extensive evaluations on a driving QA benchmark demonstrate that EVLA substantially outperforms strong fine-tuned VLM baselines, improving the final score by +0.0871 and accuracy by +5.6\%. Ablation studies validate the necessity of each component, and efficiency analyses show that EVLA achieves 36\% faster inference than multi-stage pipelines. This work underscores that integrating vehicle-state awareness and structured physical reasoning is crucial for developing next-generation, physically-grounded driving assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Electro-Visual-Language Assistant (EVLA), a multimodal framework for driving reasoning that fuses visual, textual, and real-time vehicle electro-mechanical state (e.g., motor torque, battery SOC) inputs. It proposes a Unified Co-State Encoder (UCSE) augmented by an Energy-Efficiency Field for shared latent representations and an Electro-aware Structured Reasoning Chain (ESRC) for deterministic, physics-constrained internal reasoning, trained end-to-end via a physics-guided joint loss. On a driving QA benchmark, EVLA is reported to outperform strong fine-tuned VLM baselines by +0.0871 in final score and +5.6% in accuracy, with ablation studies supporting component necessity and 36% faster inference than multi-stage pipelines.
Significance. If the performance deltas can be isolated to the vehicle-state fusion and physics-guided components, the work would provide concrete evidence that grounding VLMs in electrified powertrain dynamics improves decision quality and efficiency for driving assistants, addressing a gap in current black-box VLM approaches to vehicle control.
major comments (2)
- [Evaluation / §4] Evaluation section (implied by abstract claims of benchmark results and ablations): the headline improvements (+0.0871 score, +5.6% accuracy) are presented without explicit tables or text confirming that each 'strong fine-tuned VLM baseline' uses identical base-model capacity, identical training-data volume/distribution, and identical evaluation protocol (including any CoT or prompting variations). Without these controls, the attribution of gains to UCSE/ESRC and the physics-guided joint loss cannot be isolated from potential confounds.
- [Abstract / Methods] Abstract and methods description: the 'physics-guided joint loss' is invoked as central to training but no equation, weighting scheme, or external validation (e.g., against ground-truth energy or dynamics) is supplied; this leaves open whether the loss simply regularizes toward quantities already present in the benchmark labels rather than introducing new physical constraints.
minor comments (2)
- [Abstract] The term 'final score' is used without definition or reference to the underlying metric (e.g., whether it is a composite of accuracy, energy cost, or safety).
- [Abstract] No mention of the specific driving QA benchmark name, size, or split statistics, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on evaluation controls and the physics-guided loss formulation. We address each major comment below and will incorporate clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation / §4] the headline improvements (+0.0871 score, +5.6% accuracy) are presented without explicit tables or text confirming that each 'strong fine-tuned VLM baseline' uses identical base-model capacity, identical training-data volume/distribution, and identical evaluation protocol (including any CoT or prompting variations). Without these controls, the attribution of gains to UCSE/ESRC and the physics-guided joint loss cannot be isolated from potential confounds.
Authors: We agree that fair attribution requires explicit documentation of baseline setups. The current manuscript describes the baselines as 'strong fine-tuned VLM baselines' but does not include a dedicated comparison table. In revision we will add a table in §4 listing base model capacity, training data volume and distribution, and evaluation protocol (including prompting) for each baseline to confirm they are matched except for the UCSE/ESRC and physics-guided components. revision: yes
-
Referee: [Abstract / Methods] the 'physics-guided joint loss' is invoked as central to training but no equation, weighting scheme, or external validation (e.g., against ground-truth energy or dynamics) is supplied; this leaves open whether the loss simply regularizes toward quantities already present in the benchmark labels rather than introducing new physical constraints.
Authors: The abstract and methods summary reference the physics-guided joint loss without providing its equation or weighting. We will add the explicit formulation (combining task loss with an energy-efficiency term from the Energy-Efficiency Field) and weighting scheme to the Methods section. On external validation, the benchmark includes energy-related labels; we will clarify how the loss introduces additional physical constraints beyond label matching, or note if further experiments are needed. revision: yes
Circularity Check
No circularity detected; empirical claims rest on benchmark evaluation without self-referential reductions
full rationale
The provided abstract and context describe a multimodal framework (UCSE + ESRC) trained with a physics-guided joint loss and report empirical gains (+0.0871 score, +5.6% accuracy) plus ablations on a driving QA benchmark. No equations, parameter-fitting steps, or self-citations appear that would reduce any claimed prediction or uniqueness result to the inputs by construction. Performance attribution is presented as an outcome of end-to-end training and component ablations rather than a definitional or fitted-input equivalence. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zishan Bai, Enze Ge, and Junfeng Hao. Multi-agent collaborative framework for intelligent it operations: An aoi system with context-aware compression and dynamic task scheduling.arXiv preprint arXiv:2512.13956, 2025
Pith/arXiv arXiv 2025
-
[2]
Ziqian Bi, Lu Chen, Junhao Song, Hongying Luo, Enze Ge, Junmin Huang, Tianyang Wang, Keyu Chen, Chia Xin Liang, Zihan Wei, et al. Exploring efficiency frontiers of thinking budget in medical reasoning: Scaling laws between computational resources and reasoning quality. arXiv:2508.12140, 2025
arXiv 2025
-
[3]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11621–11631, 2020
2020
-
[4]
Cofi-dec: Hallucination-resistant decoding via coarse-to-fine generative feedback in large vision-language models
Zongsheng Cao, Yangfan He, Anran Liu, Jun Xie, Zhepeng Wang, and Feng Chen. Cofi-dec: Hallucination-resistant decoding via coarse-to-fine generative feedback in large vision-language models. InProceedings of the 33rd ACM International Conference on Multimedia, pages 10709–10718, 2025
2025
-
[5]
Purifygen: A risk-discrimination and semantic-purification model for safe text-to-image generation
Zongsheng Cao, Yangfan He, Anran Liu, Jun Xie, Zhepeng Wang, and Feng Chen. Purifygen: A risk-discrimination and semantic-purification model for safe text-to-image generation. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 816–825, 2025
2025
-
[6]
Huiyi Chen, Jiawei Peng, Dehai Min, Changchang Sun, Kaijie Chen, Yan Yan, Xu Yang, and Lu Cheng. Mvi-bench: A comprehensive benchmark for evaluating robustness to misleading visual inputs in lvlms.arXiv preprint arXiv:2511.14159, 2025
Pith/arXiv arXiv 2025
-
[7]
R2i-bench: Benchmarking reasoning-driven text-to-image generation
Kaijie Chen, Zihao Lin, Zhiyang Xu, Ying Shen, Yuguang Yao, Joy Rimchala, Jiaxin Zhang, and Lifu Huang. R2i-bench: Benchmarking reasoning-driven text-to-image generation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12606–12641, 2025
2025
-
[8]
Superflow: Training flow matching models with rl on the fly.arXiv preprint arXiv:2512.17951, 2025
Kaijie Chen, Zhiyang Xu, Ying Shen, Zihao Lin, Yuguang Yao, and Lifu Huang. Superflow: Training flow matching models with rl on the fly.arXiv preprint arXiv:2512.17951, 2025
arXiv 2025
-
[9]
Enhancing neural network performance on tabular data via knowledge dis- tillation and rankgauss transformation
Xiaoxiao Deng. Enhancing neural network performance on tabular data via knowledge dis- tillation and rankgauss transformation. In2025 6th International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), pages 418–423. IEEE, 2025. 12
2025
-
[10]
Graph inference towards icd coding.arXiv preprint arXiv:2601.07496, 2026
Xiaoxiao Deng. Graph inference towards icd coding.arXiv preprint arXiv:2601.07496, 2026
-
[11]
Xudong Han, Xianglun Gao, Xiaoyi Qu, and Zhenyu Yu. Multi-agent medical decision con- sensus matrix system: An intelligent collaborative framework for oncology mdt consultations. arXiv preprint arXiv:2512.14321, 2025
arXiv 2025
-
[12]
Ge-adapter: A general and efficient adapter for enhanced video editing with pretrained text-to-image diffusion models.Expert Systems with Applications, page 129649, 2025
Yangfan He, Sida Li, Kun Li, Jianhui Wang, Binxu Li, Tianyu Shi, Yi Xin, Keqin Li, Jun Yin, Miao Zhang, et al. Ge-adapter: A general and efficient adapter for enhanced video editing with pretrained text-to-image diffusion models.Expert Systems with Applications, page 129649, 2025
2025
-
[13]
Yangfan He, Sida Li, Jianhui Wang, Kun Li, Xinyuan Song, Xinhang Yuan, Keqin Li, Kuan Lu, Menghao Huo, Jingqun Tang, et al. Enhancing low-cost video editing with lightweight adaptors and temporal-aware inversion.arXiv preprint arXiv:2501.04606, 2025
arXiv 2025
-
[14]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022
2022
-
[15]
Gui agents for continual game generation.arXiv preprint arXiv:2605.28258, 2026
Yixu Huang, Bo Li, Na Li, Zhe Wang, Kaijie Chen, Haonan Ge, Qingyi Si, Yuanzhe Shen, Ruihan Yang, Guangjing Wang, et al. Gui agents for continual game generation.arXiv preprint arXiv:2605.28258, 2026
Pith/arXiv arXiv 2026
-
[16]
Low-rank adaptation for scalable large language models: A comprehensive survey
Chia Xin Liang, Ziqian Bi, Tianyang Wang, Ming Liu, Xinyuan Song, Yichao Zhang, Junhao Song, Qian Niu, Benji Peng, Keyu Chen, et al. Low-rank adaptation for scalable large language models: A comprehensive survey. 2025
2025
-
[17]
Chia Xin Liang, Pu Tian, Caitlyn Heqi Yin, Yao Yua, Wei An-Hou, Li Ming, Tianyang Wang, Ziqian Bi, and Ming Liu. A comprehensive survey and guide to multimodal large language models in vision-language tasks.arXiv:2411.06284, 2024
-
[18]
Abductive inference in retrieval-augmented language models: Generating and validating missing premises, 2025
Shiyin Lin. Abductive inference in retrieval-augmented language models: Generating and validating missing premises, 2025
2025
-
[19]
Hybrid fuzzing with llm-guided input mutation and semantic feedback, 2025
Shiyin Lin. Hybrid fuzzing with llm-guided input mutation and semantic feedback, 2025
2025
-
[20]
Llm-driven adaptive source-sink identification and false positive mitigation for static analysis, 2025
Shiyin Lin. Llm-driven adaptive source-sink identification and false positive mitigation for static analysis, 2025
2025
-
[21]
The maximum forcing number of a polyomino.Australas
Yuqing Lin, Mujiangshan Wang, Liqiong Xu, and Fuji Zhang. The maximum forcing number of a polyomino.Australas. J. Combin, 69:306–314, 2017
2017
-
[22]
Llava-next: Improved reasoning, ocr, and world knowledge.arXiv preprint, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge.arXiv preprint, 2024
2024
-
[23]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[24]
Dora: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. In International Conference on Machine Learning (ICML), 2024
2024
-
[25]
Mingqiao Mo, Yunlong Tan, Hao Zhang, Heng Zhang, and Yangfan He. Shieldedcode: Learning robust representations for virtual machine protected code.arXiv preprint arXiv:2601.20679, 2026
-
[26]
Ordered and hamilton digraphs
WANG Mu-Jiang-shan, YUAN Jun, LIN Shang-wei, et al. Ordered and hamilton digraphs. Chinese Quarterly Journal of Mathematics, 25(3):317–326, 2010
2010
-
[27]
From text to multimodality: Exploring the evolution and impact of large language models in medical practice, 2024
Qian Niu, Keyu Chen, Ming Li, Pohsun Feng, Ziqian Bi, Lawrence KQ Yan, Yichao Zhang, Caitlyn Heqi Yin, Cheng Fei, Junyu Liu, Benji Peng, Tianyang Wang, Yunze Wang, Silin Chen, and Ming Liu. From text to multimodality: Exploring the evolution and impact of large language models in medical practice, 2024. 13
2024
-
[28]
Large language models and cognitive science: A comprehensive review of similarities, differences, and challenges, 2024
Qian Niu, Junyu Liu, Ziqian Bi, Pohsun Feng, Benji Peng, Keyu Chen, Ming Li, Lawrence KQ Yan, Yichao Zhang, Caitlyn Heqi Yin, Cheng Fei, Tianyang Wang, Yunze Wang, Silin Chen, and Ming Liu. Large language models and cognitive science: A comprehensive review of similarities, differences, and challenges, 2024
2024
-
[29]
Hybridgnn: A self-supervised graph neural network for efficient maximum matching in bipartite graphs.Symmetry, 16(12):1631, 2024
Chun-Hui Pan, Yi Qu, Yao Yao, and Mu-Jiang-Shan Wang. Hybridgnn: A self-supervised graph neural network for efficient maximum matching in bipartite graphs.Symmetry, 16(12):1631, 2024
2024
-
[30]
Benji Peng, Keyu Chen, Ming Li, Pohsun Feng, Ziqian Bi, Junyu Liu, and Qian Niu. Securing large language models: Addressing bias, misinformation, and prompt attacks.arXiv:2409.08087, 2024
-
[31]
Capacitive aptasensor coupled with microfluidic enrichment for real-time detection of trace sars-cov-2 nucleocapsid protein.Analytical chemistry, 94(6):2812–2819, 2022
Haochen Qi, Zhiwen Hu, Zhongliang Yang, Jian Zhang, Jie Jayne Wu, Cheng Cheng, Chunchang Wang, and Lei Zheng. Capacitive aptasensor coupled with microfluidic enrichment for real-time detection of trace sars-cov-2 nucleocapsid protein.Analytical chemistry, 94(6):2812–2819, 2022
2022
-
[32]
Magnet-bn: markov-guided bayesian neural networks for cali- brated long-horizon sequence forecasting and community tracking.Mathematics, 13(17):2740, 2025
Daozheng Qu and Yanfei Ma. Magnet-bn: markov-guided bayesian neural networks for cali- brated long-horizon sequence forecasting and community tracking.Mathematics, 13(17):2740, 2025
2025
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), pages 8748–8763, 2021
2021
-
[34]
Jintao Ren, Ziqian Bi, Qian Niu, Junyu Liu, Benji Peng, Sen Zhang, Xuanhe Pan, Jinlang Wang, Keyu Chen, Caitlyn Heqi Yin, et al. Deep learning and machine learning–object detection and semantic segmentation: From theory to applications.arXiv:2410.15584, 2024
-
[35]
Jiazhao Shi, Yichen Lin, Yiheng Hua, Ziyu Wang, Zijian Zhang, Wenjia Zheng, Yun Song, Kuan Lu, and Shoufeng Lu. Multi-scenario highway lane-change intention prediction: A physics-informed ai framework for three-class classification.arXiv preprint arXiv:2509.17354, 2025
-
[36]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[37]
Xinyuan Song, Yangfan He, Sida Li, Jianhui Wang, Hongyang He, Xinhang Yuan, Ruoyu Wang, Jiaqi Chen, Keqin Li, Kuan Lu, et al. Efficient temporal consistency in diffusion-based video editing with adaptor modules: A theoretical framework.arXiv preprint arXiv:2504.16016, 2025
-
[38]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Chenxu Hu, Yang Wang, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Centermamba-sam: Center-prioritized scanning and temporal prototypes for brain lesion segmentation, 2025
Yu Tian, Zhongheng Yang, Chenshi Liu, Yiyun Su, Ziwei Hong, Zexi Gong, and Jingyuan Xu. Centermamba-sam: Center-prioritized scanning and temporal prototypes for brain lesion segmentation, 2025
2025
-
[40]
An intelligent blockchain-based ac- cess control framework with federated learning for genome-wide association studies.Computer Standards & Interfaces, 84:103694, 2023
Huanhuan Wang, Xiao Zhang, Youbing Xia, and Xiang Wu. An intelligent blockchain-based ac- cess control framework with federated learning for genome-wide association studies.Computer Standards & Interfaces, 84:103694, 2023
2023
-
[41]
Conditional matching preclusion number for the cayley graph on the symmetric group.Acta Math
M Wang, W Yang, and S Wang. Conditional matching preclusion number for the cayley graph on the symmetric group.Acta Math. Appl. Sin.(Chinese Series), 36(5):813–820, 2013
2013
-
[42]
Diagnosability of cayley graph networks generated by transposition trees under the comparison diagnosis model.Annals of Applied Mathematics, 32(2):166–173, 2016
Mujiangshan Wang and Shiying Wang. Diagnosability of cayley graph networks generated by transposition trees under the comparison diagnosis model.Annals of Applied Mathematics, 32(2):166–173, 2016. 14
2016
-
[43]
Global reliable diagnosis of networks based on self-comparative diagnosis model and g-good-neighbor property.Journal of Computer and System Sciences, page 103698, 2025
Mujiangshan Wang, Shuhao Xu, Jincheng Jiang, Dong Xiang, and Sun-Yuan Hsieh. Global reliable diagnosis of networks based on self-comparative diagnosis model and g-good-neighbor property.Journal of Computer and System Sciences, page 103698, 2025
2025
-
[44]
Relation of the isolated scattering number of a graph and its complement graph.Journal of Shanxi University (Natural Science Edition), 35(2):206–210, 2012
Shi-Ying Wang, Mu-Jiang-shan Wang, Kai Feng, Shang-wei Lin, and Ming-Yu Zhang. Relation of the isolated scattering number of a graph and its complement graph.Journal of Shanxi University (Natural Science Edition), 35(2):206–210, 2012
2012
-
[45]
The edge connectivity of expanded k-ary n-cubes
Shiying Wang and Mujiangshan Wang. The edge connectivity of expanded k-ary n-cubes. Discrete Dynamics in Nature and Society, 2018(1):7867342, 2018
2018
-
[46]
A note on the connectivity of m-ary n-dimensional hypercubes.Parallel Processing Letters, 29(04):1950017, 2019
Shiying Wang and Mujiangshan Wang. A note on the connectivity of m-ary n-dimensional hypercubes.Parallel Processing Letters, 29(04):1950017, 2019
2019
-
[47]
Embedding paths into the 4-ary n-cube with faulty nodes
Shiying Wang, Jiangshan Wangmu, Zhifang Qi, and Yunxia Ren. Embedding paths into the 4-ary n-cube with faulty nodes. In2011 International Conference on Consumer Electronics, Communications and Networks (CECNet), pages 4949–4951. IEEE, 2011
2011
-
[48]
From in silico to in vitro: A comprehensive guide to validating bioinformatics findings, 2025
Tianyang Wang, Silin Chen, Yunze Wang, Yichao Zhang, Xinyuan Song, Ziqian Bi, Ming Liu, Qian Niu, Junyu Liu, Pohsun Feng, Xintian Sun, Benji Peng, Charles Zhang, Keyu Chen, Ming Li, Cheng Fei, and Lawrence KQ Yan. From in silico to in vitro: A comprehensive guide to validating bioinformatics findings, 2025
2025
-
[49]
From bench to bedside: A review of clinical trials in drug discovery and development, 2024
Tianyang Wang, Ming Liu, Benji Peng, Xinyuan Song, Charles Zhang, Xintian Sun, Qian Niu, Junyu Liu, Silin Chen, Keyu Chen, Ming Li, Pohsun Feng, Ziqian Bi, Yunze Wang, Yichao Zhang, Cheng Fei, and Lawrence KQ Yan. From bench to bedside: A review of clinical trials in drug discovery and development, 2024
2024
-
[50]
Low-power design of advanced image processing algorithms under fpga in real-time applications
Yuyao Wang. Low-power design of advanced image processing algorithms under fpga in real-time applications. In2024 IEEE 4th International Conference on Power, Electronics and Computer Applications (ICPECA), pages 1080–1084. IEEE, 2024
2024
-
[51]
Zynq soc-based acceleration of retinal blood vessel diameter measurement
Yuyao Wang. Zynq soc-based acceleration of retinal blood vessel diameter measurement. Archives of Advanced Engineering Science, pages 1–9, 2025
2025
-
[52]
Soft error evaluation and mitigation in gate diffusion input circuits
Yuyao Wang and Selahattin Sayil. Soft error evaluation and mitigation in gate diffusion input circuits. In2024 IEEE 6th International Conference on Power, Intelligent Computing and Systems (ICPICS), pages 121–128. IEEE, 2024
2024
-
[53]
Fstgat: Financial spatio-temporal graph attention network for non-stationary financial systems and its application in stock price prediction.Symmetry, 17(8):1344, 2025
Ze-Lin Wei, Hong-Yu An, Yao Yao, Wei-Cong Su, Guo Li, Saifullah, Bi-Feng Sun, and Mu- Jiang-Shan Wang. Fstgat: Financial spatio-temporal graph attention network for non-stationary financial systems and its application in stock price prediction.Symmetry, 17(8):1344, 2025
2025
-
[54]
Learning-Based Automated Adversarial Red-Teaming for Robustness Evaluation of Large Language Models
Zhang Wei, Peilu Hu, Shengning Lang, Hao Yan, Li Mei, Yichao Zhang, Chen Yang, Junfeng Hao, and Zhimo Han. Automated red-teaming framework for large language model secu- rity assessment: A comprehensive attack generation and detection system.arXiv preprint arXiv:2512.20677, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Augmented intelligence of things for emergency vehicle secure trajectory prediction and task offloading
Xiang Wu, Jian Dong, Wei Bao, Baowen Zou, Lili Wang, and Huanhuan Wang. Augmented intelligence of things for emergency vehicle secure trajectory prediction and task offloading. IEEE Internet of Things Journal, 11(22):36030–36043, 2024
2024
-
[56]
Dynamic allocation strategy of vm resources with fuzzy transfer learning method.Peer-to-Peer Networking and Applications, 13(6):2201–2213, 2020
Xiang Wu, Huanhuan Wang, Wei Tan, Dashun Wei, and Minyu Shi. Dynamic allocation strategy of vm resources with fuzzy transfer learning method.Peer-to-Peer Networking and Applications, 13(6):2201–2213, 2020
2020
-
[57]
A tutorial- generating method for autonomous online learning.IEEE Transactions on Learning Technolo- gies, 17:1532–1541, 2024
Xiang Wu, Huanhuan Wang, Yongting Zhang, Baowen Zou, and Huaqing Hong. A tutorial- generating method for autonomous online learning.IEEE Transactions on Learning Technolo- gies, 17:1532–1541, 2024
2024
-
[58]
Xiang Wu, Yong-Ting Zhang, Khin-Wee Lai, Ming-Zhao Yang, Ge-Lan Yang, and Huan-Huan Wang. A novel centralized federated deep fuzzy neural network with multi-objectives neural architecture search for epistatic detection.IEEE Transactions on Fuzzy Systems, 33(1):94–107, 2024. 15
2024
-
[59]
An adaptive federated learning scheme with differential privacy preserving.Future Generation Computer Systems, 127:362–372, 2022
Xiang Wu, Yongting Zhang, Minyu Shi, Pei Li, Ruirui Li, and Neal N Xiong. An adaptive federated learning scheme with differential privacy preserving.Future Generation Computer Systems, 127:362–372, 2022
2022
-
[60]
G-good-neighbor diagnosability under the modified comparison model for multiprocessor systems.Theoretical Computer Science, 1028:115027, 2025
Dong Xiang, Sun-Yuan Hsieh, et al. G-good-neighbor diagnosability under the modified comparison model for multiprocessor systems.Theoretical Computer Science, 1028:115027, 2025
2025
-
[61]
Vmt-adapter: Parameter-efficient transfer learning for multi-task dense scene understanding
Yi Xin, Junlong Du, Qiang Wang, Zhiwen Lin, and Ke Yan. Vmt-adapter: Parameter-efficient transfer learning for multi-task dense scene understanding. InProceedings of the AAAI confer- ence on artificial intelligence, volume 38, pages 16085–16093, 2024
2024
-
[62]
Yi Xin, Qi Qin, Siqi Luo, Kaiwen Zhu, Juncheng Yan, Yan Tai, Jiayi Lei, Yuewen Cao, Keqi Wang, Yibin Wang, et al. Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understanding.arXiv preprint arXiv:2510.06308, 2025
-
[63]
Lumina-mgpt 2.0: Stand-alone autoregressive image modeling.arXiv preprint arXiv:2507.17801, 2025
Yi Xin, Juncheng Yan, Qi Qin, Zhen Li, Dongyang Liu, Shicheng Li, Victor Shea-Jay Huang, Yupeng Zhou, Renrui Zhang, Le Zhuo, et al. Lumina-mgpt 2.0: Stand-alone autoregressive image modeling.arXiv preprint arXiv:2507.17801, 2025
-
[64]
Shengkai Xu, Hsiang Lun Kao, Tianxiang Xu, Honghui Zhang, Junqiao Wang, Runmeng Ding, Guanyu Liu, Tianyu Shi, Zhenyu Yu, Guofeng Pan, et al. Adaptive detector-verifier framework for zero-shot polyp detection in open-world settings.arXiv preprint arXiv:2512.12492, 2025
-
[65]
Wong, Zhenguo Li, and Hengshuang Zhao
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K. Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Letters, 2024
2024
-
[66]
Lawrence K. Q. Yan, Qian Niu, Ming Li, Yichao Zhang, Caitlyn Heqi Yin, Cheng Fei, Benji Peng, Ziqian Bi, Pohsun Feng, Keyu Chen, Tianyang Wang, Yunze Wang, Silin Chen, Ming Liu, Junyu Liu, Xinyuan Song, Riyang Bao, Zekun Jiang, and Ziyuan Qin. Large language model benchmarks in medical tasks, 2025
2025
-
[67]
Wcdt: World-centric diffusion transformer for traffic scene generation
Chen Yang, Yangfan He, Aaron Xuxiang Tian, Dong Chen, Jianhui Wang, Tianyu Shi, Arsalan Heydarian, and Pei Liu. Wcdt: World-centric diffusion transformer for traffic scene generation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6566–6572. IEEE, 2025
2025
-
[68]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[69]
Drdgrl: Dual-relational dynamic graph repre- sentation learning for delay-sensitive stock trend prediction
Mingjie You, Kaijie Chen, and Dawei Cheng. Drdgrl: Dual-relational dynamic graph repre- sentation learning for delay-sensitive stock trend prediction. InInternational Conference on Database Systems for Advanced Applications, pages 35–50. Springer, 2026
2026
-
[70]
Weiming You, Zhenyu Yu, Zhimo Han, Xingyu Liu, and Yichao Zhang. Large language models for enhanced user experience in virtual and augmented reality: A comprehensive framework for ranking and recommendation systems.Available at SSRN 5964834, 2025
2025
-
[71]
Lin Yu, Xiaofei Han, Yifei Kang, Chiung-Yi Tseng, Danyang Zhang, Ziqian Bi, and Zhimo Han. Affective multimodal agents with proactive knowledge grounding for emotionally aligned marketing dialogue.arXiv preprint arXiv:2511.21728, 2025
-
[72]
Probability-Entropy Calibration: An Elastic Indicator for Adaptive Fine-tuning
Wenhao Yu, Shaohang Wei, Jiahong Liu, Yifan Li, Minda Hu, Aiwei Liu, Hao Zhang, and Irwin King. Probability-entropy calibration: An elastic indicator for adaptive fine-tuning.arXiv preprint arXiv:2602.01745, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[73]
Ai for science: A comprehensive review on innovations, challenges, and future directions.International Journal of Artificial Intelligence for Science (IJAI4S), 1(1), 2025
Zhenyu Yu. Ai for science: A comprehensive review on innovations, challenges, and future directions.International Journal of Artificial Intelligence for Science (IJAI4S), 1(1), 2025
2025
-
[74]
Forgetme: Benchmarking the selective forgetting capabilities of generative models.Engineering Applica- tions of Artificial Intelligence, 161:112087, 2025
Zhenyu Yu, Mohd Yamani Idna Idris, Pei Wang, Yuelong Xia, and Yong Xiang. Forgetme: Benchmarking the selective forgetting capabilities of generative models.Engineering Applica- tions of Artificial Intelligence, 161:112087, 2025. 16
2025
-
[75]
Zhenyu Yu, Jinnian Wang, and Mohd Yamani Idna Idris. Iidm: Improved implicit diffusion model with knowledge distillation to estimate the spatial distribution density of carbon stock in remote sensing imagery.Knowledge-Based Systems, page 115131, 2025
2025
-
[76]
Charles Zhang, Benji Peng, Xintian Sun, Qian Niu, Junyu Liu, Keyu Chen, Ming Li, Pohsun Feng, Ziqian Bi, Ming Liu, et al. From word vectors to multimodal embeddings: Techniques, applications, and future directions for large language models.arXiv:2411.05036, 2024
-
[77]
Hao Zhang, Bo Huang, Zhenjia Li, Xi Xiao, Hui Yi Leong, Zumeng Zhang, Xinwei Long, Tianyang Wang, and Hao Xu. Sensitivity-lora: Low-load sensitivity-based fine-tuning for large language models.arXiv preprint arXiv:2509.09119, 2025
-
[78]
Hao Zhang, Zhenjia Li, Runfeng Bao, Yifan Gao, Xi Xiao, Heng Zhang, Shuyang Zhang, Bo Huang, Yuhang Wu, Tianyang Wang, et al. Hyperadalora: Accelerating lora rank allo- cation during training via hypernetworks without sacrificing performance.arXiv preprint arXiv:2510.02630, 2025
-
[79]
Hao Zhang, Mengsi Lyu, Zhuo Chen, Xingrun Xing, Yulong Ao, and Yonghua Lin. Pdtrim: Tar- geted pruning for prefill-decode disaggregation in inference.arXiv preprint arXiv:2509.04467, 2025
-
[80]
Hao Zhang, Mengsi Lyu, Chenrui He, Yulong Ao, and Yonghua Lin. Trimtokenator: Towards adaptive visual token pruning for large multimodal models.arXiv preprint arXiv:2509.00320, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.