GUI Agents for Continual Game Generation
Pith reviewed 2026-06-29 10:54 UTC · model grok-4.3
The pith
GUI agents turn one-shot game code generation into an iterative coding-and-playing loop that raises playability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
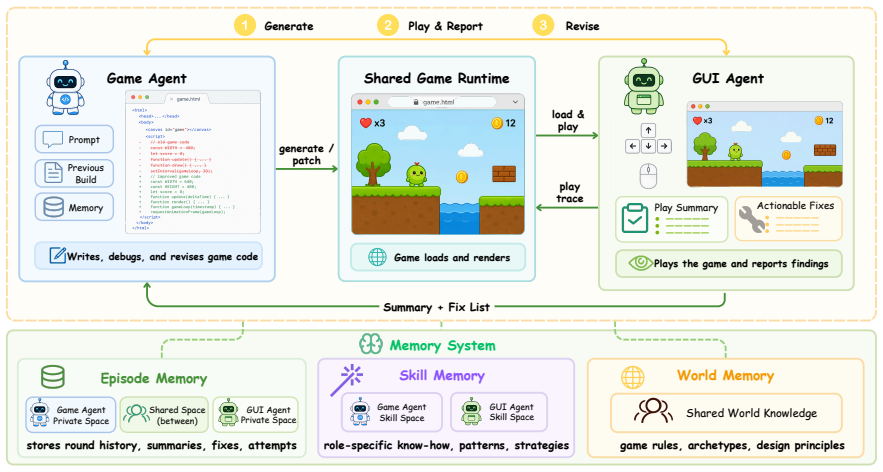
Game generation succeeds when a coding agent and a GUI agent operate in a sustained loop with shared memory, allowing the GUI agent to load each browser build, execute intended play behaviors, and return traceable judgments that the coder uses to revise until the game meets the rubric criteria.
What carries the argument
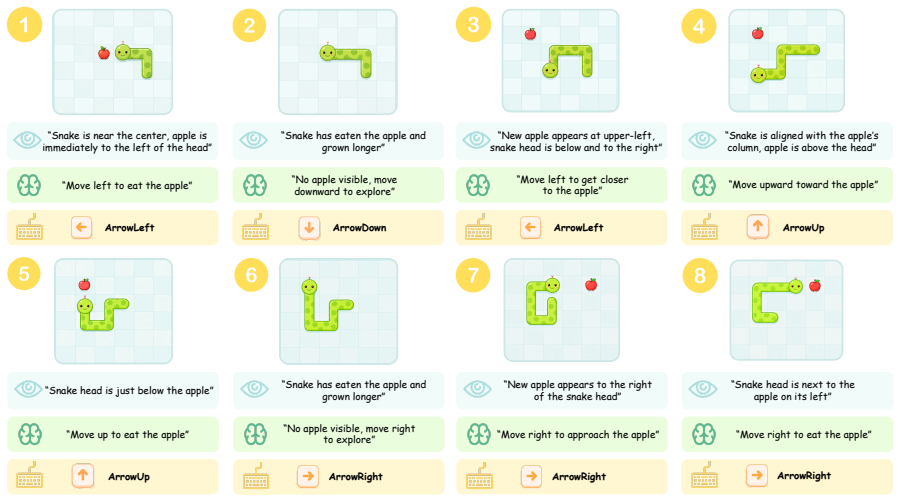
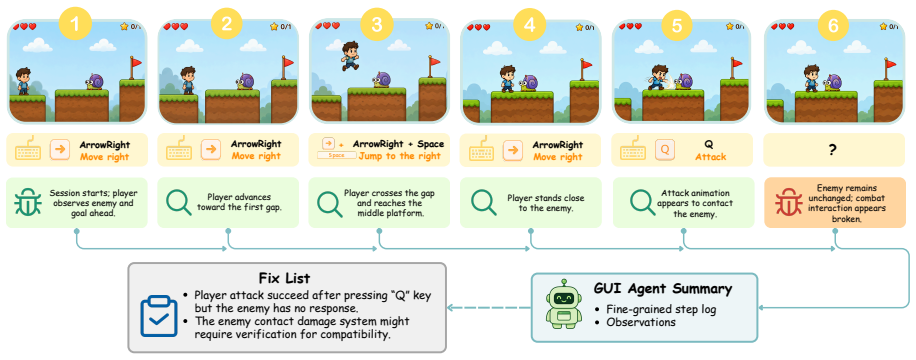
The Play2Code shared-memory loop in which a game-coding agent and a GUI playtesting agent alternate turns, with the GUI agent loading builds in a browser and judging them against expected in-play behaviors.
If this is right
- Frontier models produce low rates of playable games when generating directly from a prompt.
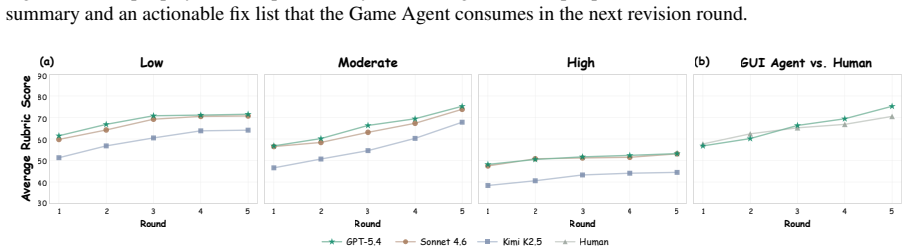
- The Play2Code loop raises the rubric pass rate by 37.1 points over single-pass generation and 14.6 points over agentic coding baselines.
- GUI-agent feedback is more traceable than human reports while showing some of the same idiosyncratic patterns as human testers.
- Game playtesting functions as a concrete testbed for studying interactive code generation.
Where Pith is reading between the lines
- The same coding-plus-tester loop could be applied to generate other interactive software such as web tools or simulations.
- Domains that require execution feedback may benefit from pairing a generator agent with a specialized tester agent rather than relying on language feedback alone.
- Increasing the number of loop iterations or adding more diverse play behaviors could allow generation of longer or more complex games.
Load-bearing premise
The GUI agent can reliably load browser builds, carry out the intended play actions, and produce rubric judgments that match what human players would find playable without missing key failures or adding bias.
What would settle it
A controlled study in which human players rate the final games from the loop and find no improvement in actual playability over the single-pass baseline, or find systematic mismatches with the agent's rubric scores.
Figures


read the original abstract
Generating a game is not the same as making one that can be played. Despite advances in code generation, existing approaches treat game generation as one-shot translation from prompt to artifact, leaving interaction-level failures undetected. We argue that evaluating and improving game generation requires a player, and study two roles for graphical user interface (GUI) agents in this process: (1) as an objective evaluator, for which we introduce PlaytestArena, a new evaluation environment that pairs 200 browser-based game generation tasks across eight genres with rubrics of expected in-play behaviors, adjudicated by a GUI agent that loads each build in a browser and plays it; and (2) as a subjective playtester, for which we propose Play2Code, where a game agent and a GUI agent operate in a sustained loop with shared memory, turning game generation into a dialogue between coding and playing. Our experiments show that even frontier models struggle to generate playable games directly, while Play2Code achieves a 66.8\% rubric pass-rate, improving over single-pass and agentic-coding baselines by 37.1 and 14.6 points respectively. Further analysis shows that GUI playtester feedback is more traceable than a human report, yet idiosyncratic in ways reminiscent of human testers, establishing game playtesting as a critical testbed for interactive code generation. Our project website is available at https://continual-game-generation.vercel.app/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PlaytestArena, a benchmark of 200 browser-based game generation tasks across eight genres with rubric-based evaluation by a GUI agent that loads and plays builds, and proposes Play2Code, a continual loop in which a coding agent and GUI playtester agent interact via shared memory. It claims that frontier models struggle with direct generation of playable games, while Play2Code reaches a 66.8% rubric pass-rate, outperforming single-pass generation by 37.1 points and agentic-coding baselines by 14.6 points; further analysis positions GUI feedback as traceable yet human-like in idiosyncrasies.
Significance. If the GUI agent's rubric judgments prove reliable proxies for human playability, the work supplies a concrete testbed and method for turning game generation into an interactive, continual process rather than one-shot translation. This could generalize to other interactive code-generation domains and supplies an explicit, reproducible evaluation harness (via the linked project site) that prior game-generation papers have often lacked.
major comments (2)
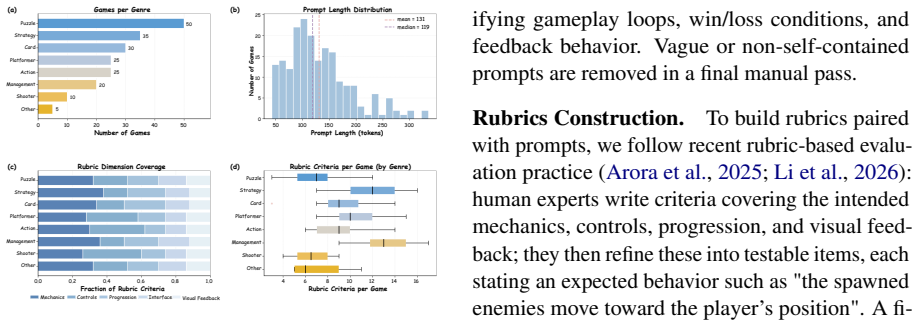
- [Experiments / PlaytestArena] Experiments / PlaytestArena description: the central empirical claims (66.8% pass-rate and the 37.1 / 14.6 point gains) rest entirely on rubric scores produced by the GUI agent; no human agreement statistics (Cohen’s kappa, percentage agreement on a labeled subset), false-negative rates on known-unplayable games, or coverage analysis across the eight genres are reported. Without this link the metric cannot be interpreted as evidence of improved playability.
- [Analysis of GUI playtester feedback] § on GUI playtester feedback: the claim that the agent’s feedback is “more traceable than a human report, yet idiosyncratic in ways reminiscent of human testers” is presented without a quantitative operationalization of traceability or a controlled comparison against human tester reports, leaving the qualitative assertion unsupported by the data shown.
minor comments (2)
- [Abstract] The abstract states concrete percentage improvements without accompanying standard errors, number of runs, or statistical tests; these details should appear in the main results table or text.
- [Play2Code method] Notation for the shared-memory loop and the exact prompt templates used by the two agents are not shown in the provided excerpt; including them would aid replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, agreeing where validation gaps exist and outlining targeted revisions to the manuscript.
read point-by-point responses
-
Referee: [Experiments / PlaytestArena] Experiments / PlaytestArena description: the central empirical claims (66.8% pass-rate and the 37.1 / 14.6 point gains) rest entirely on rubric scores produced by the GUI agent; no human agreement statistics (Cohen’s kappa, percentage agreement on a labeled subset), false-negative rates on known-unplayable games, or coverage analysis across the eight genres are reported. Without this link the metric cannot be interpreted as evidence of improved playability.
Authors: We agree that the manuscript does not report human agreement statistics, false-negative rates, or explicit coverage analysis, which weakens the direct link from rubric scores to human-perceived playability. The PlaytestArena is framed as a scalable automated benchmark with reproducible rubrics executed by GUI agents; reported gains are relative improvements under this fixed metric. In the revised manuscript we will add (1) coverage statistics across the eight genres based on the existing 200-task distribution and (2) an explicit limitations paragraph discussing the absence of human validation. Collecting new human agreement data or false-negative tests on known-unplayable builds is not feasible within the current revision and is noted as future work. revision: partial
-
Referee: [Analysis of GUI playtester feedback] § on GUI playtester feedback: the claim that the agent’s feedback is “more traceable than a human report, yet idiosyncratic in ways reminiscent of human testers” is presented without a quantitative operationalization of traceability or a controlled comparison against human tester reports, leaving the qualitative assertion unsupported by the data shown.
Authors: We accept that the traceability and idiosyncrasy claim is presented qualitatively without quantitative operationalization or controlled human comparison, rendering it unsupported by the data shown. The statement originated from inspection of shared-memory traces. In revision we will rewrite the relevant paragraph to present the observation as informal and example-driven, supply illustrative feedback excerpts, remove any implication of quantitative advantage, and add a sentence noting the lack of controlled human comparison as a limitation. revision: yes
- Human agreement statistics (Cohen’s kappa, percentage agreement), false-negative rates on known-unplayable games, and controlled quantitative comparisons against human tester reports—these require new data collection absent from the current manuscript.
Circularity Check
No circularity: empirical comparisons rest on direct measurements
full rationale
The paper reports experimental pass-rates (66.8% for Play2Code vs. baselines) obtained by running GUI agents against fixed rubrics in PlaytestArena. No equations, fitted parameters, or self-citations are used to derive these numbers; the gains are presented as observed outcomes of the described agent loop. The work contains no self-definitional reductions, fitted-input predictions, or load-bearing self-citation chains that would collapse the central claims back onto their inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
DAIN: Dynamic Agent-Based Interaction Network for Efficient and Collaborative Multimodal Reasoning
DAIN reframes multimodal fusion as dynamic agent collaboration with sparse activation, claiming SOTA results including 2.6% accuracy gain on ADNI across five benchmarks.
-
ProHiFlo: Hierarchical Flow Matching with Functional Guidance for De Novo Protein Generation
ProHiFlo introduces hierarchical coarse-to-fine flow matching with functional guidance from pretrained predictors and an adaptive SE(3)-equivariant architecture, reporting higher success rates and fewer sampling steps...
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems, 37:52040–52094
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Aashish Yadavally, Hoan Nguyen, Laurent Callot, and Gauthier Guinet. 2025. Large language model critics for execution-free evaluation of code changes.arXiv preprint arXiv:2501.16655. Keen You, Haoti...
-
[2]
Springer. Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Ji- aqi Feng, Yaliang Li, and Libing Wu. 2026. Agen- tic memory: Learning unified long-term and short- term memory management for large language model agents.arXiv preprint arXiv:2601.01885. Chenchen Zhang, Yuhang Li, Can Xu, Jiaheng Liu, Ao Liu, Changzhi Zhou, Ken Deng, Dengpeng Wu, Guanhua Huang, K...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
reach the goal tile
and Poki (Poki, 2026), selected to span the five genres listed below. We use only games that run as static HTML bundles with no login, payment, or external API depen- dency. The 20 games cover five genres: puzzle (5), strat- egy (4), card (4), platformer (4), and management (3). Compared to PlaytestArena, this testbed omits action and shooter genres becau...
2026
-
[4]
We then average over the three GUI– human pairs and, separately, over the three human–human pairs
Per-criterion agreement.For each pair of judges (one GUI–human pair or one human– human pair), we compute (a)raw agreement as the percentage of rubric criteria on which the two judges return the same verdict, and (b) Cohen’sκ, which corrects for chance agree- ment under the marginal pass-rates of each judge. We then average over the three GUI– human pairs...
-
[5]
We also reportPearson’s r on the same scores as a robustness check; the two metrics give consistent conclusions
Per-game ranking consistency.For each GUI–human or human–human pair, we score every game by the fraction of rubric criteria each judge marksPASS, then computeSpear- man’sρ between the two resulting rankings of the 32 games. We also reportPearson’s r on the same scores as a robustness check; the two metrics give consistent conclusions. C.4 Results Per-pair...
-
[6]
This phase also includes game guide (GAME_GUIDE.md) generation, which is later consumed by the GUI Agent
Game design.A specifc game design docu- ment is generated from the user requirement, according to . This phase also includes game guide (GAME_GUIDE.md) generation, which is later consumed by the GUI Agent. (§D.2)
-
[7]
Asset generation.Sprites, tilemaps, and au- dio are generated according to game deisign
-
[8]
Code implementation.The agent imple- ments scenes, entities and game logics accord- ing game design document
-
[9]
Verification.The agent runs npm run build and a headless test pass, fixing any TypeScript or runtime errors before handing the build to the GUI Agent
-
[10]
Memory capture.On completion, the agent writes any non-obvious fix patterns, pitfalls, or design decisions to skill or world memory for use in subsequent tasks. Tools.The Game Agent has access to file-system tools ( read_file, write_file, run_shell_command), project-specific code generation tools ( generate_game_guide, generate-game-assets, and the memory...
-
[11]
Initial observation.The agent observes the rendered game screen and uses short waits when necessary to distinguish loading screens from frozen or unresponsive builds
-
[12]
Game start.The agent starts the game by clicking a visible start affordance, pressing 16 the instructed key, or proceeding directly if the game auto-starts
-
[13]
It verifies the game guide through interaction rather than assum- ing it is correct
Interactive playtesting.The agent plays to- ward the stated objective using only mouse and keyboard actions. It verifies the game guide through interaction rather than assum- ing it is correct. For movement-heavy games, it holds keys long enough to produce visi- ble displacement and combines keys when chorded actions such as run-and-jump are re- quired. T...
-
[14]
It evalu- ates the start flow, controls, core mechanics, progression, and ending, and records severity- tagged findings grounded in the observed tra- jectory
Assessment.The agent summarizes whether the run was completed, reached an ending, blocked by a bug, or could not start. It evalu- ates the start flow, controls, core mechanics, progression, and ending, and records severity- tagged findings grounded in the observed tra- jectory
-
[15]
Memory capture.At the end of the session, the agent writes reusable interaction patterns, false-positive cases, and game-archetype- specific testing heuristics to memory for fu- ture playtests. Tools.The GUI Agent has access to browser- level interaction tools: browser_screenshot, browser_click, browser_drag, browser_key, browser_type, browser_scroll, and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.