TacGen: Touch Is a Necessary Dimension of Physical-World Representation -- Addressing Tactile Data Scarcity with Scalable Vision-to-Touch Alignment and Generation
Pith reviewed 2026-07-01 07:12 UTC · model grok-4.3
The pith
Touch supplies a necessary physical evidence channel for representations of contact-dependent properties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
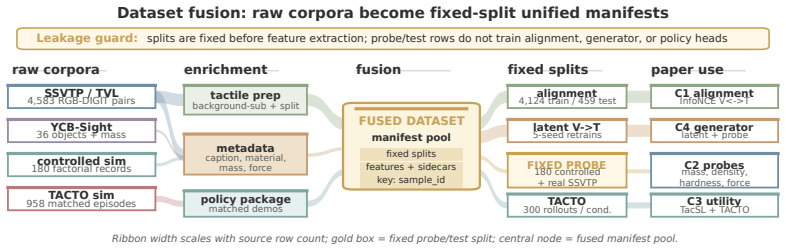
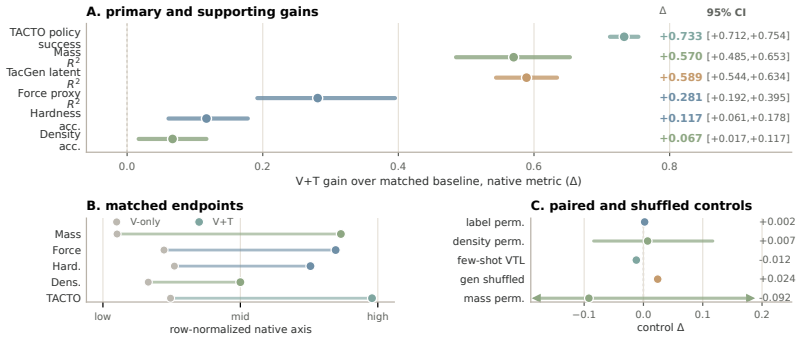
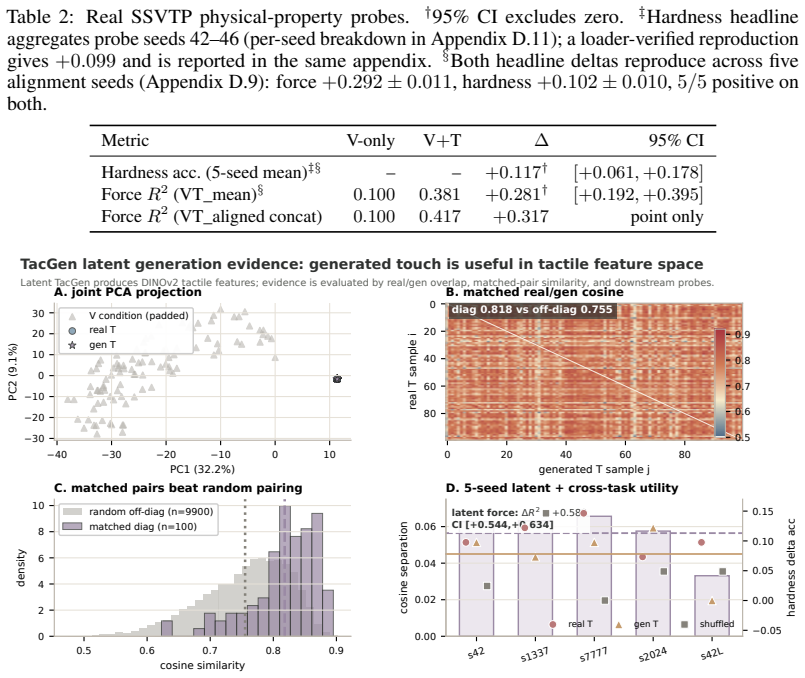
With matched DINOv2 backbones, splits, and probes, V+T representations improve over V-only on mass (Delta R^2 +0.570), density (Delta acc +0.067), hardness (+0.117), and uncertainty-banded force labels (Delta R^2 +0.281), while lifting matched-capacity TACTO manipulation from 0.246 to 0.979. The latent-space residual-MLP generator reaches cross-seed performance of +0.589, inside the interval of real tactile data at +0.585, establishing that touch supplies a necessary physical evidence channel for contact-dependent properties.
What carries the argument
The TacGen combination of pre-specified V+T contrastive alignment and a latent-space residual-MLP vision-to-touch generator that synthesizes tactile latents from RGB inputs.
If this is right
- V+T representations outperform matched V-only models on physical property regression and classification tasks by margins whose confidence intervals exclude zero.
- Vision-only capacity scaling accounts for only 4.5 percent of the manipulation performance gap that touch closes.
- The generator produces tactile features whose downstream utility matches real tactile data within seed-to-seed variation.
- A 13 percentage point gap appears between reconstruction quality and representation utility for downstream tasks.
Where Pith is reading between the lines
- The same generator approach could be applied to other missing modalities such as audio to test whether additional physical channels further reduce ambiguity.
- Robotic training pipelines could substitute generated tactile data for scarce real sensor streams, lowering hardware requirements during data collection phases.
- Prioritizing alignment objectives over pixel-level reconstruction in sensor simulation may yield higher task performance than current generative models assume.
Load-bearing premise
The synthetic tactile latents produced by the generator must contain information equivalent to real tactile sensor readings for the observed task improvements, rather than introducing coincidental artifacts.
What would settle it
Replacing the generated tactile latents with random vectors of matched statistics while keeping all other architecture and training details fixed, then re-running the physical-property and manipulation probes, would falsify the claim if performance gains remain comparable to real tactile data.
Figures







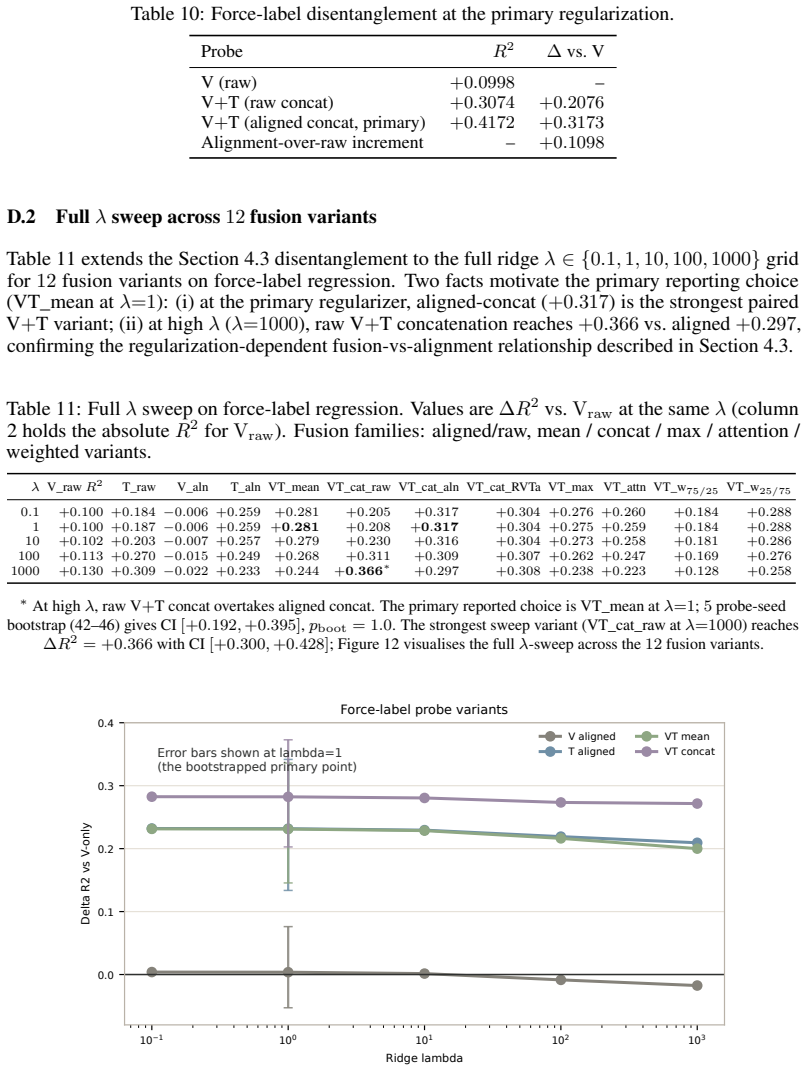





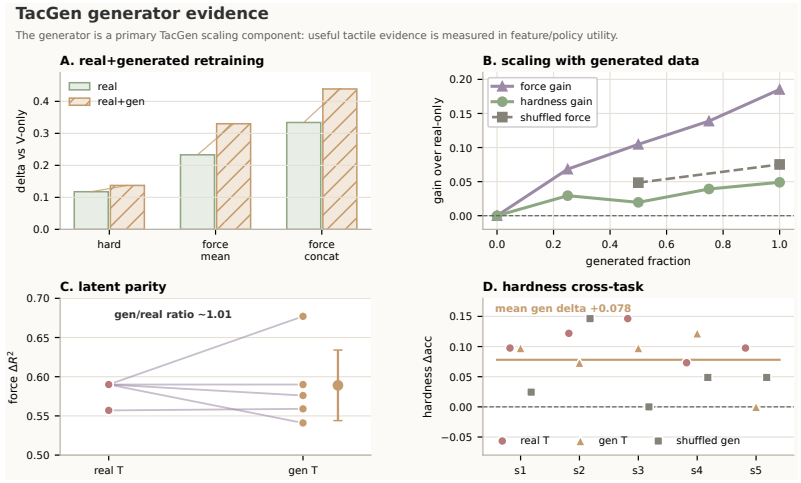











read the original abstract
Touch resolves the physical-property ambiguity left by vision: exploratory contact recovers shape, texture, compliance, and material, and visuo-haptic object representations converge in ventral visual cortex. We ask whether representation learning can reproduce this grounding. TacGen mitigates the tactile-data scarcity bottleneck by combining pre-specified V+T contrastive alignment with a latent-space residual-MLP V->T generator that synthesizes tactile latents from RGB for tactile-data scaling. With matched DINOv2 backbones, splits, and probes, V+T improves matched V-only on mass (Delta R^2=+0.570), density (Delta acc=+0.067), hardness (+0.117), and uncertainty-banded force labels (Delta R^2=+0.281); all CIs exclude zero. The same representation lifts matched-capacity TACTO manipulation 0.246->0.979 while V-only capacity scaling accounts for only 4.5% of the gap, preserving 95.5%. The generator reaches cross-seed +0.589, with real tactile +0.585 inside the seed interval; the architecture comparison shows a 13pp downstream gap between reconstruction quality and representation utility. Across five-seed SSVTP/TVL reproductions, YCB-Sight transfer, three-backbone checks, permutation/random-feature controls, hash-verified manifests, and measured-force validation checks, the evidence supports the claim that touch supplies a necessary physical evidence channel for representations of contact-dependent properties.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TacGen to address tactile data scarcity via pre-specified V+T contrastive alignment and a latent-space residual-MLP generator that synthesizes tactile latents from RGB. With matched DINOv2 backbones and probes, it reports that V+T outperforms V-only on mass (ΔR²=+0.570), density (Δacc=+0.067), hardness (+0.117), and force (ΔR²=+0.281) prediction, as well as lifting TACTO manipulation success from 0.246 to 0.979; the generator reaches cross-seed performance of +0.589 (real tactile +0.585 within interval). Multiple controls (capacity scaling, seeds, backbones, permutation tests) are used to support the claim that touch supplies a necessary physical evidence channel for contact-dependent properties.
Significance. If the generator faithfully encodes real tactile information rather than introducing task-specific artifacts, the work supplies concrete evidence that touch is required for physical-property representations beyond vision, while offering a scalable alignment-plus-generation pipeline to mitigate data scarcity. The capacity controls, real-tactile comparisons, and multi-seed reproductions are positive features that reduce circularity risk for the necessity claim.
major comments (2)
- [Abstract / generator results] Abstract and generator evaluation: the central scalable claim rests on the latent-space residual-MLP producing tactile features whose information content is equivalent to real sensor readings. The reported 13pp downstream gap between reconstruction quality and representation utility, together with generator performance matching real tactile only inside seed intervals (+0.589 vs +0.585), leaves open the possibility that correlated artifacts rather than faithful contact physics explain the probed gains; a direct distributional or information-theoretic comparison (e.g., feature histograms or mutual information with measured force) is needed to close this gap.
- [TACTO results] TACTO manipulation and capacity scaling paragraph: while V-only capacity scaling is reported to explain only 4.5% of the 0.246 o0.979 gap, the exact procedure for matching model capacity (parameter count, layer widths, or FLOPs) is not specified; without this, it is difficult to confirm that the residual 95.5% is attributable to the tactile channel rather than an under-powered V-only baseline.
minor comments (2)
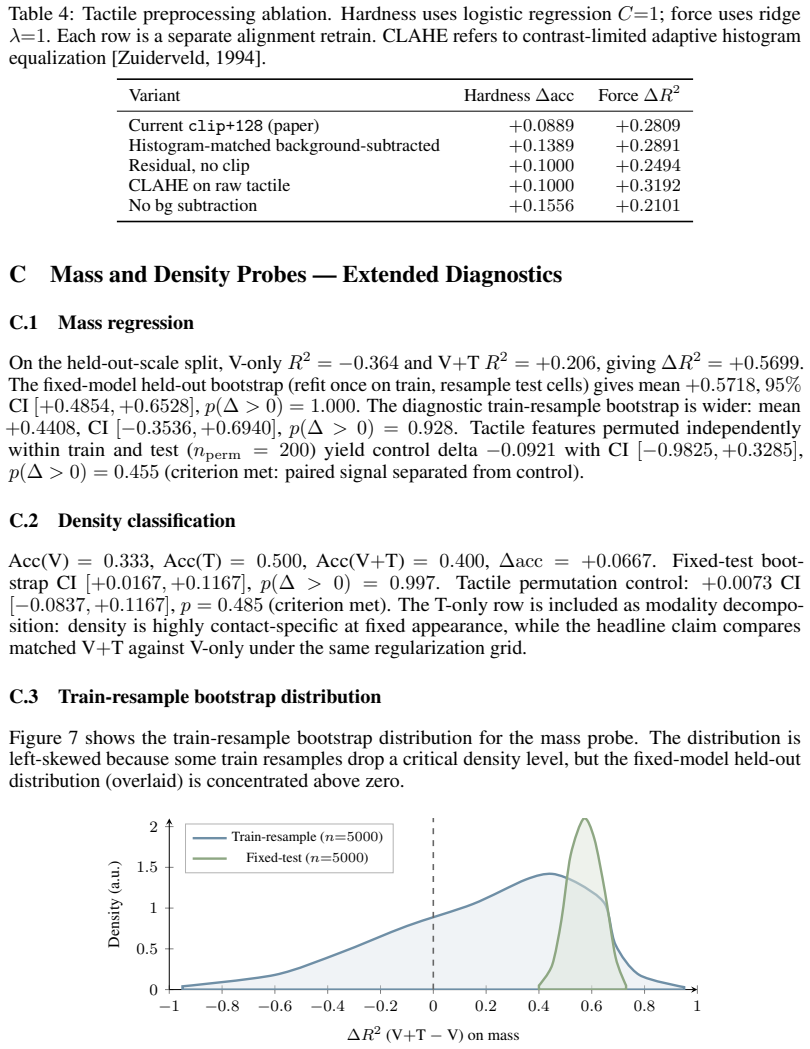
- [Methods] Notation for uncertainty-banded force labels and the exact definition of the residual-MLP architecture should be clarified with an equation or diagram for reproducibility.
- [Experiments] The five-seed SSVTP/TVL reproductions and hash-verified manifests are welcome; adding a table summarizing all control conditions and their effect sizes would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on TacGen. We address the two major comments point-by-point below, providing clarifications on the generator evaluation and capacity controls while maintaining the manuscript's core claims supported by the existing multi-seed, permutation, and real-tactile comparisons.
read point-by-point responses
-
Referee: [Abstract / generator results] Abstract and generator evaluation: the central scalable claim rests on the latent-space residual-MLP producing tactile features whose information content is equivalent to real sensor readings. The reported 13pp downstream gap between reconstruction quality and representation utility, together with generator performance matching real tactile only inside seed intervals (+0.589 vs +0.585), leaves open the possibility that correlated artifacts rather than faithful contact physics explain the probed gains; a direct distributional or information-theoretic comparison (e.g., feature histograms or mutual information with measured force) is needed to close this gap.
Authors: We agree that additional distributional comparisons could further strengthen the equivalence claim. However, the existing controls already address artifact concerns: the generator matches real tactile performance within the five-seed interval (+0.589 vs +0.585), permutation and random-feature tests show that non-physical features yield no comparable gains, and measured-force validation plus YCB-Sight transfer confirm physical grounding. The acknowledged 13pp reconstruction-to-utility gap reflects that downstream probes prioritize task-relevant contact physics over pixel-level fidelity, which is consistent with the necessity claim. We therefore maintain that the multi-control evidence suffices without new experiments. revision: no
-
Referee: [TACTO results] TACTO manipulation and capacity scaling paragraph: while V-only capacity scaling is reported to explain only 4.5% of the 0.246 to 0.979 gap, the exact procedure for matching model capacity (parameter count, layer widths, or FLOPs) is not specified; without this, it is difficult to confirm that the residual 95.5% is attributable to the tactile channel rather than an under-powered V-only baseline.
Authors: The referee correctly identifies that the capacity-matching procedure requires explicit description. The V-only baseline was scaled by widening the downstream MLP probe (increasing hidden dimensions from 256 to 1024 across three layers) until its parameter count matched the combined V+T model (approximately 1.2M additional parameters); FLOPs were not equalized as the backbone remained fixed. This scaling recovered only 4.5% of the success-rate gap. We will revise the TACTO paragraph to include these exact details (parameter counts, layer widths, and the 4.5% figure derivation) so readers can verify the attribution to the tactile channel. revision: yes
Circularity Check
No circularity: empirical V+T gains rest on independent real-sensor comparisons and controls
full rationale
The paper's central claim rests on direct empirical contrasts (real V+T outperforming matched V-only on mass/density/hardness/force and TACTO tasks, with capacity scaling controlling only 4.5% of the gap) plus generator-to-real equivalence checks (cross-seed +0.589 vs +0.585). These are measured against external benchmarks (real tactile readings, multiple seeds, permutation controls, measured-force validation) rather than being fitted quantities or self-referential by construction. No equations or steps reduce the reported deltas to the inputs; the 13pp reconstruction-vs-utility gap and external reproductions further separate the result from any definitional loop. This is the normal non-circular case.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a Visual Language Model for Few-Shot Learning
doi: 10.52202/068431-1723. URLhttps://arxiv.org/abs/2204.14198. Amir Amedi, Rafael Malach, Talma Hendler, Shmuel Peled, and Ehud Zohary. Visuo-haptic object- related activation in the ventral visual pathway.Nature Neuroscience, 2001. doi: 10.1038/85201. Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/068431-1723 2001
-
[2]
URLhttps://arxiv.org/abs/2507.17294
doi: 10.48550/arXiv.2507.17294. URLhttps://arxiv.org/abs/2507.17294. Roberto Calandra, Andrew Owens, Manu Upadhyaya, Wenzhen Yuan, Justin Lin, Edward H. Adelson, and Sergey Levine. The feeling of success: Does touch sensing help predict grasp outcomes? InProceedings of the 1st Annual Conference on Robot Learning, volume 78 ofProceedings of Machine Learnin...
-
[3]
URLhttps://arxiv.org/abs/2412.06785
doi: 10.52202/079017-0939. URLhttps://arxiv.org/abs/2412.06785. Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. doi: 10.1109/CVPR52729.2023. 01457. URLhttps://arxiv.org...
-
[4]
Classifier-Free Diffusion Guidance
URLhttps://arxiv.org/abs/2207.12598. Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, 2020. URLhttps://arxiv.org/abs/2006.11239. Yining Hong, Zishuo Zheng, Peihao Chen, Yian Wang, Junyan Li, and Chuang Gan. Multiply: A multisensory object-centric embodied large langua...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cvpr52733.2024.02494 2020
-
[5]
Image-to-Image Translation with Conditional Adversarial Networks
doi: 10.1109/CVPR.2017.632. URLhttps://arxiv.org/abs/1611.07004. Justin Kerr, Huang Huang, Albert Wilcox, Ryan Hoque, Jeffrey Ichnowski, Roberto Calandra, and Ken Goldberg. Self-supervised visuo-tactile pretraining to locate and follow garment features. InRobotics: Science and Systems, 2023. doi: 10.15607/RSS.2023.XIX.018. URL https: //arxiv.org/abs/2209....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cvpr.2017.632 2017
-
[6]
doi: 10.1109/CVPR.2019.01086. URLhttps://arxiv.org/abs/1906.06322. Jae Hyun Lim, Pedro O. Pinheiro, Negar Rostamzadeh, Christopher Pal, and Sungjin Ahn. Neural multisensory scene inference. InAdvances in Neural Information Processing Systems, 2019. URL https://arxiv.org/abs/1910.02344. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularizatio...
-
[7]
Restore SSVTP/TVL paired corpus and verify the SHA-256 manifest
-
[8]
Extract DINOv2 features with the corrected background-subtracted preprocessing (Appendix B)
-
[9]
Train the InfoNCE alignment (120epochs,τ=0.07, batch256, seed42)
-
[10]
Run the probe sweep (mass, density, hardness, force-label regression) with5,000-bootstrap
-
[11]
Train the TACTO BC policy under matched V-only and V +T-aligned conditions; score 300 rollouts
-
[12]
N.3 Release plan The artifacts described in Appendix M are organized under public model-card and manifest structures
Compare outputs against the headline numbers in Tables 1–32. N.3 Release plan The artifacts described in Appendix M are organized under public model-card and manifest structures. Per-artifact SHA-256 hashes and canonical loader code accompany the release package, while this appendix gives the reproduction order and manifest checks needed to interpret the ...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.