L2D2-GS: Learning to Densify for Feedforward Dynamic Gaussian Scene Reconstruction
Pith reviewed 2026-06-30 07:10 UTC · model grok-4.3
The pith
Feedforward dynamic scene reconstruction improves by turning Gaussian primitive generation into a self-supervised iterative densification process guided by global reconstruction rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
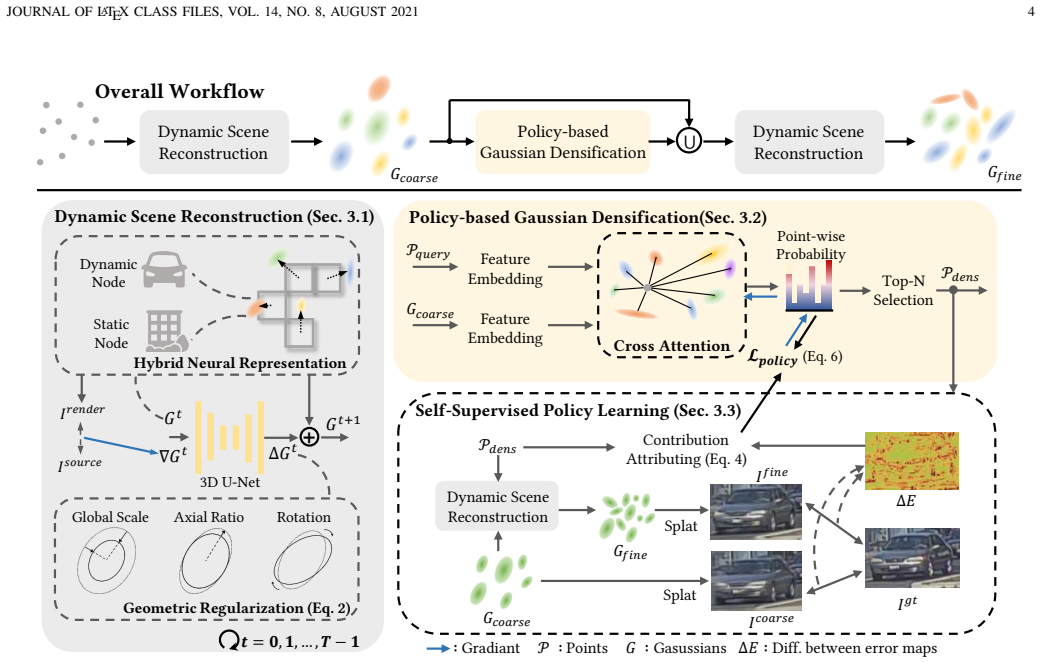
Reformulating feedforward Gaussian reconstruction as robust iterative optimization and densification, with a self-supervised policy that extracts reward signals from global reconstruction gains to steer local primitive addition and geometric regularization that constrains the optimization manifold, produces higher-fidelity results than one-shot regression baselines.
What carries the argument
The self-supervised densification policy that derives explicit reward signals from global reconstruction gains to guide local primitive addition.
If this is right
- Dynamic urban scenes can be reconstructed at high fidelity without per-scene optimization.
- Fewer Gaussian primitives suffice to reach the reported quality levels.
- Zero-shot transfer to unseen sequences becomes stronger than in prior feedforward methods.
Where Pith is reading between the lines
- The same reward-from-global-gains idea could be tested on static scenes or non-Gaussian representations to check whether the iterative densification pattern generalizes.
- If early-stage artifacts remain correctable only because of the specific reparameterization, removing that constraint should produce measurable drops on the same datasets.
Load-bearing premise
Global reconstruction gains supply reliable signals for deciding where to add primitives locally, and geometric regularization can always prevent early irreversible artifacts.
What would settle it
An ablation on PandaSet or Waymo in which the densification policy is replaced by uniform or random primitive addition and the resulting reconstruction error exceeds that of the reported baselines.
Figures












read the original abstract
High-fidelity reconstruction of dynamic urban environments is a cornerstone of autonomous driving simulation and large-scale world modeling. While 3D Gaussian Splatting (3DGS) has established a new standard for real-time rendering, its reliance on expensive per-scene optimization limits scalability. Conversely, recent feedforward methods that infer Gaussian parameters offer faster speed but face fundamental bottlenecks: they are memory-prohibitive at high resolutions and struggle to fuse dense multi-view observations consistently. This paper presents L2D2-GS, a unified framework that reformulates generalizable reconstruction not as a one-shot regression, but as a robust iterative process of optimization and densification. To resolve the ambiguity of supervision in primitive generation, we propose a self-supervised densification policy that derives explicit reward signals from global reconstruction gains to guide local densification. Furthermore, we mitigate irreversible early-stage artifacts through a geometric regularization mechanism, utilizing reparameterization to constrain the optimization manifold and prevent convergence to poor local optima. Extensive experiments on the PandaSet and Waymo datasets demonstrate that our method achieves state-of-the-art reconstruction fidelity and strong zero-shot generalization, while using fewer primitives than competing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents L2D2-GS, a unified framework for feedforward reconstruction of dynamic urban scenes via 3D Gaussian Splatting. It reformulates the task as an iterative process of optimization and densification, introducing a self-supervised densification policy that derives explicit reward signals from global reconstruction gains to guide local primitive addition, plus a geometric regularization mechanism using reparameterization to constrain the optimization manifold and avoid poor local optima. Experiments on PandaSet and Waymo are claimed to show SOTA reconstruction fidelity, strong zero-shot generalization, and use of fewer primitives than baselines.
Significance. If the central claims hold, the work could advance scalable, generalizable dynamic scene reconstruction for autonomous driving and world modeling by addressing memory and consistency bottlenecks in feedforward Gaussian methods while retaining real-time rendering advantages. The self-supervised policy and regularization are presented as key enablers for robustness without per-scene optimization.
major comments (2)
- [Method (self-supervised densification policy and geometric regularization)] The self-supervised densification policy (described in the method) relies on the assumption that global reconstruction gains provide reliable explicit rewards for local primitive addition decisions. This mapping is under-constrained in dynamic urban scenes; the manuscript provides no ablation studies, correlation metrics, or quantitative analysis demonstrating that early erroneous additions are reliably corrected by the geometric reparameterization, especially under zero-shot transfer to unseen scenes. This directly impacts the central claim of robust iterative reconstruction.
- [Experiments and Results] Results section claims SOTA fidelity and fewer primitives on PandaSet and Waymo, but the provided abstract and high-level description contain no tables, error bars, per-scene metrics, or baseline comparisons with numerical values. Without these, the quantitative superiority and the claim of using fewer primitives cannot be verified against the experimental setup.
minor comments (2)
- [Abstract and Experiments] Ensure all claims of SOTA performance reference specific quantitative tables or figures with error bars and ablation details for reproducibility.
- [Method] Clarify notation for the reward formulation and reparameterization to make the geometric regularization mechanism fully explicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the self-supervised densification policy and the presentation of experimental results. We address each major comment below.
read point-by-point responses
-
Referee: [Method (self-supervised densification policy and geometric regularization)] The self-supervised densification policy (described in the method) relies on the assumption that global reconstruction gains provide reliable explicit rewards for local primitive addition decisions. This mapping is under-constrained in dynamic urban scenes; the manuscript provides no ablation studies, correlation metrics, or quantitative analysis demonstrating that early erroneous additions are reliably corrected by the geometric reparameterization, especially under zero-shot transfer to unseen scenes. This directly impacts the central claim of robust iterative reconstruction.
Authors: We agree that additional quantitative analysis would strengthen the central claim. The full manuscript describes the policy and regularization but does not include dedicated ablations or correlation metrics. In the revised version we will add (i) correlation plots between global reconstruction gains and local addition decisions, (ii) an ablation measuring the fraction of early erroneous additions corrected by geometric reparameterization, and (iii) zero-shot transfer results on held-out scenes. These additions will directly support the robustness argument. revision: yes
-
Referee: [Experiments and Results] Results section claims SOTA fidelity and fewer primitives on PandaSet and Waymo, but the provided abstract and high-level description contain no tables, error bars, per-scene metrics, or baseline comparisons with numerical values. Without these, the quantitative superiority and the claim of using fewer primitives cannot be verified against the experimental setup.
Authors: The full manuscript contains a results section with tables, error bars, per-scene metrics, and baseline comparisons. However, the abstract and introductory summary do not present these numerical values. We will revise the manuscript to include a compact summary table of key metrics (PSNR, SSIM, primitive count) in the introduction or abstract, together with error bars, so that the SOTA and efficiency claims are immediately verifiable from the high-level text. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The abstract describes a self-supervised densification policy deriving rewards from global reconstruction gains and a geometric regularization via reparameterization, but provides no equations, fitted parameters renamed as predictions, or self-citations that reduce any load-bearing claim to its own inputs by construction. No uniqueness theorems, ansatzes smuggled via citation, or renamings of known results are present. The central claims rest on experimental results on PandaSet and Waymo rather than definitional equivalence, making this a standard non-circular case.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[2]
Street gaussians: Modeling dynamic urban scenes with gaussian splatting,
Y . Yan, H. Lin, C. Zhou, W. Wang, H. Sun, K. Zhan, X. Lang, X. Zhou, and S. Peng, “Street gaussians: Modeling dynamic urban scenes with gaussian splatting,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 156–173. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10
2024
-
[3]
Omnire: Omni urban scene reconstruction,
Z. Chen, J. Yang, J. Huang, R. de Lutio, J. M. Esturo, B. Ivanovic, O. Litany, Z. Gojcic, S. Fidler, M. Pavoneet al., “Omnire: Omni urban scene reconstruction,”arXiv preprint arXiv:2408.16760, 2024
-
[4]
Desire-gs: 4d street gaussians for static- dynamic decomposition and surface reconstruction for urban driving scenes,
C. Peng, C. Zhang, Y . Wang, C. Xu, Y . Xie, W. Zheng, K. Keutzer, M. Tomizuka, and W. Zhan, “Desire-gs: 4d street gaussians for static- dynamic decomposition and surface reconstruction for urban driving scenes,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 6782–6791
2025
-
[5]
Anysplat: Feed-forward 3d gaussian splatting from unconstrained views,
L. Jiang, Y . Mao, L. Xu, T. Lu, K. Ren, Y . Jin, X. Xu, M. Yu, J. Pang, F. Zhaoet al., “Anysplat: Feed-forward 3d gaussian splatting from unconstrained views,”ACM Transactions on Graphics (TOG), vol. 44, no. 6, pp. 1–16, 2025
2025
-
[6]
Evolsplat: Efficient volume-based gaussian splatting for urban view synthesis,
S. Miao, J. Huang, D. Bai, X. Yan, H. Zhou, Y . Wang, B. Liu, A. Geiger, and Y . Liao, “Evolsplat: Efficient volume-based gaussian splatting for urban view synthesis,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 11 286–11 296
2025
-
[7]
J. Yang, J. Huang, Y . Chen, Y . Wang, B. Li, Y . You, A. Sharma, M. Igl, P. Karkus, D. Xuet al., “Storm: Spatio-temporal reconstruction model for large-scale outdoor scenes,”arXiv preprint arXiv:2501.00602, 2024
-
[8]
X. Chen, Z. Xiong, Y . Chen, G. Li, N. Wang, H. Luo, L. Chen, H. Sun, B. Wang, G. Chenet al., “Dggt: Feedforward 4d reconstruction of dynamic driving scenes using unposed images,”arXiv preprint arXiv:2512.03004, 2025
-
[9]
Depthsplat: Connecting gaussian splatting and depth,
H. Xu, S. Peng, F. Wang, H. Blum, D. Barath, A. Geiger, and M. Polle- feys, “Depthsplat: Connecting gaussian splatting and depth,” inProceed- ings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 453–16 463
2025
-
[10]
G3r: Gradient guided generalizable reconstruction,
Y . Chen, J. Wang, Z. Yang, S. Manivasagam, and R. Urtasun, “G3r: Gradient guided generalizable reconstruction,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 305–323
2024
-
[11]
Flux4D: Flow-based Unsupervised 4D Reconstruction
J. Wang, H. Che, Y . Chen, Z. Yang, L. Goli, S. Manivasagam, and R. Urtasun, “Flux4d: Flow-based unsupervised 4d reconstruction,”arXiv preprint arXiv:2512.03210, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Resplat: Learning recurrent gaussian splats,
H. Xu, D. Barath, A. Geiger, and M. Pollefeys, “Resplat: Learning recurrent gaussian splats,”arXiv preprint arXiv:2510.08575, 2025
-
[13]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d re- construction,
D. Charatan, S. L. Li, A. Tagliasacchi, and V . Sitzmann, “pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d re- construction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 19 457–19 467
2024
-
[14]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,
Y . Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.- J. Cham, and J. Cai, “Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 370–386
2024
-
[15]
Transplat: Generalizable 3d gaussian splatting from sparse multi-view images with transformers,
C. Zhang, Y . Zou, Z. Li, M. Yi, and H. Wang, “Transplat: Generalizable 3d gaussian splatting from sparse multi-view images with transformers,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, 2025, pp. 9869–9877
2025
-
[16]
Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation,
Y . Xu, Z. Shi, W. Yifan, H. Chen, C. Yang, S. Peng, Y . Shen, and G. Wetzstein, “Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 1–20
2024
-
[17]
Gs-lrm: Large reconstruction model for 3d gaussian splatting,
K. Zhang, S. Bi, H. Tan, Y . Xiangli, N. Zhao, K. Sunkavalli, and Z. Xu, “Gs-lrm: Large reconstruction model for 3d gaussian splatting,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 1–19
2024
-
[18]
Long-lrm: Long-sequence large reconstruction model for wide- coverage gaussian splats,
C. Ziwen, H. Tan, K. Zhang, S. Bi, F. Luan, Y . Hong, L. Fuxin, and Z. Xu, “Long-lrm: Long-sequence large reconstruction model for wide- coverage gaussian splats,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 4349–4359
2025
-
[19]
Splatter image: Ultra- fast single-view 3d reconstruction,
S. Szymanowicz, C. Rupprecht, and A. Vedaldi, “Splatter image: Ultra- fast single-view 3d reconstruction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 10 208–10 217
2024
-
[20]
Mvsplat360: Feed-forward 360 scene synthesis from sparse views,
Y . Chen, C. Zheng, H. Xu, B. Zhuang, A. Vedaldi, T.-J. Cham, and J. Cai, “Mvsplat360: Feed-forward 360 scene synthesis from sparse views,”Advances in Neural Information Processing Systems, vol. 37, pp. 107 064–107 086, 2024
2024
-
[21]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
B. Smart, C. Zheng, I. Laina, and V . A. Prisacariu, “Splatt3r: Zero- shot gaussian splatting from uncalibrated image pairs,”arXiv preprint arXiv:2408.13912, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images,
B. Ye, S. Liu, H. Xu, X. Li, M. Pollefeys, M.-H. Yang, and S. Peng, “No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images,”arXiv preprint arXiv:2410.24207, 2024
-
[23]
Omni-scene: Omni-gaussian representation for ego-centric sparse-view scene reconstruction,
D. Wei, Z. Li, and P. Liu, “Omni-scene: Omni-gaussian representation for ego-centric sparse-view scene reconstruction,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 317– 22 327
2025
-
[24]
Splatformer: Point transformer for robust 3d gaussian splatting,
Y . Chen, M. Mihajlovic, X. Chen, Y . Wang, S. Prokudin, and S. Tang, “Splatformer: Point transformer for robust 3d gaussian splatting,”arXiv preprint arXiv:2411.06390, 2024
-
[25]
Absgs: Recovering fine details in 3d gaussian splatting,
Z. Ye, W. Li, S. Liu, P. Qiao, and Y . Dou, “Absgs: Recovering fine details in 3d gaussian splatting,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1053–1061
2024
-
[26]
Revising densification in gaussian splatting,
S. Rota Bul `o, L. Porzi, and P. Kontschieder, “Revising densification in gaussian splatting,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 347–362
2024
-
[27]
Color-cued efficient densification method for 3d gaussian splatting,
S. Kim, K. Lee, and Y . Lee, “Color-cued efficient densification method for 3d gaussian splatting,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 775–783
2024
-
[28]
Bugs: Universal 3d gaussian splatting with a bi-directional gaussian growing mechanism,
F. Duan, Y . Zhang, X. Li, X. Tan, J. Wang, and L. Chen, “Bugs: Universal 3d gaussian splatting with a bi-directional gaussian growing mechanism,”IEEE Transactions on Multimedia, pp. 1–11, 2026
2026
-
[29]
Adversarial pruning networks for compact 3d gaussian splatting,
H. Shuai, Y . Shi, Y . Sun, and Q. Liu, “Adversarial pruning networks for compact 3d gaussian splatting,”IEEE Transactions on Multimedia, vol. 28, pp. 1080–1089, 2026
2026
-
[30]
4dgstream: Variable bitrate dynamic gaussian splatting streaming,
Z. Liang, D. Zhang, L. Shen, M. Zhang, J. Zhang, B. Ju, M. Dasari, F. Wang, and J. Liu, “4dgstream: Variable bitrate dynamic gaussian splatting streaming,”IEEE Transactions on Multimedia, pp. 1–15, 2026
2026
-
[31]
Ad-gs: Alternating densification for sparse-input 3d gaussian splatting,
G. Patle, N. Girgaonkar, N. Somraj, and R. Soundararajan, “Ad-gs: Alternating densification for sparse-input 3d gaussian splatting,” in Proceedings of the SIGGRAPH Asia 2025 Conference Papers, 2025, pp. 1–11
2025
-
[32]
Point cloud densification for 3d gaussian splatting from sparse input views,
K.-C. Chan, J. Xiao, H. L. Goshu, and K.-M. Lam, “Point cloud densification for 3d gaussian splatting from sparse input views,” in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 896–904
2024
-
[33]
Denser: 3d gaussian splatting for scene reconstruction of dynamic urban en- vironments,
M. A. Mohamad, G. Elghazaly, A. Hubert, and R. Frank, “Denser: 3d gaussian splatting for scene reconstruction of dynamic urban en- vironments,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 2701–2707
2025
-
[34]
Quicksplat: Fast 3d surface reconstruction via learned gaussian initialization,
Y .-C. Liu, L. H ¨ollein, M. Nießner, and A. Dai, “Quicksplat: Fast 3d surface reconstruction via learned gaussian initialization,”arXiv preprint arXiv:2505.05591, 2025
-
[35]
Generative den- sification: Learning to densify gaussians for high-fidelity generalizable 3d reconstruction,
S. Nam, X. Sun, G. Kang, Y . Lee, S. Oh, and E. Park, “Generative den- sification: Learning to densify gaussians for high-fidelity generalizable 3d reconstruction,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 26 683–26 693
2025
-
[36]
Gaussianlens: Localized high-resolution reconstruction via on-demand gaussian densification,
Y . Weng, Z. Wang, S. Peng, S. Xie, H. Zhou, and L. J. Guibas, “Gaussianlens: Localized high-resolution reconstruction via on-demand gaussian densification,”arXiv preprint arXiv:2509.25603, 2025
-
[37]
Ad-gs: Object-aware b-spline gaussian splatting for self-supervised autonomous driving,
J. Xu, K. Deng, Z. Fan, S. Wang, J. Xie, and J. Yang, “Ad-gs: Object-aware b-spline gaussian splatting for self-supervised autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 24 770–24 779
2025
-
[38]
Splatad: Real-time lidar and camera rendering with 3d gaussian splat- ting for autonomous driving,
G. Hess, C. Lindstr ¨om, M. Fatemi, C. Petersson, and L. Svensson, “Splatad: Real-time lidar and camera rendering with 3d gaussian splat- ting for autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 11 982–11 992
2025
-
[39]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5294– 5306
2025
-
[40]
Torchsparse++: Efficient training and inference framework for sparse convolution on gpus,
H. Tang, S. Yang, Z. Liu, K. Hong, Z. Yu, X. Li, G. Dai, Y . Wang, and S. Han, “Torchsparse++: Efficient training and inference framework for sparse convolution on gpus,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, 2023, pp. 225–239
2023
-
[41]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
N. Keetha, N. M ¨uller, J. Sch ¨onberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antuneset al., “Mapany- thing: Universal feed-forward metric 3d reconstruction,”arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Pandaset: Advanced sensor suite dataset for autonomous driving,
P. Xiao, Z. Shao, S. Hao, Z. Zhang, X. Chai, J. Jiao, Z. Li, J. Wu, K. Sun, K. Jianget al., “Pandaset: Advanced sensor suite dataset for autonomous driving,” in2021 IEEE international intelligent transportation systems conference (ITSC). IEEE, 2021, pp. 3095–3101
2021
-
[43]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caineet al., “Scalability in perception for autonomous driving: Waymo open dataset,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2446–2454
2020
-
[44]
Emernerf: Emergent spatial- temporal scene decomposition via self-supervision,
J. Yang, B. Ivanovic, O. Litany, X. Weng, S. W. Kim, B. Li, T. Che, D. Xu, S. Fidler, M. Pavoneet al., “Emernerf: Emergent spatial- temporal scene decomposition via self-supervision,”arXiv preprint arXiv:2311.02077, 2023. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11 w/o geo reg w geo reg GT Fig. 7.Effectiveness of geometric regularization....
-
[45]
using the codebase provided in the DriveStudio framework
-
[46]
We strictly adhere to the original training protocols and hyperparameter settings to ensure a fair evaluation. The scene is initialized with a total of 1 million primitives: this consists of 600K points downsampled from the aggregated LiDAR scans to provide a geometric coarse structure, augmented by 400K points uniformly sampled within the scene’s boundin...
-
[47]
•Ours with Reparameterization (Orange):Our method reparameterizes the scale factors to map linear updates to a linear growth in anisotropy
within the first few iterations. •Ours with Reparameterization (Orange):Our method reparameterizes the scale factors to map linear updates to a linear growth in anisotropy. As shown by the or- ange curve, the maximum reachable anisotropy increases linearly and slowly. This imposes a strictstructural constraint on the optimization manifold: even if the gra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.