Reported Confidence in LLMs Tracks Commitment More Than Correctness
Pith reviewed 2026-06-30 07:42 UTC · model grok-4.3
The pith
Verbal confidence in LLMs predicts the decision to commit or abstain far better than whether the answer is correct.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
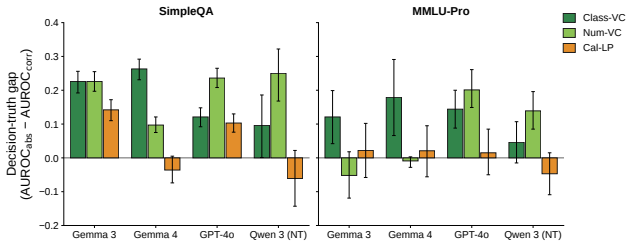
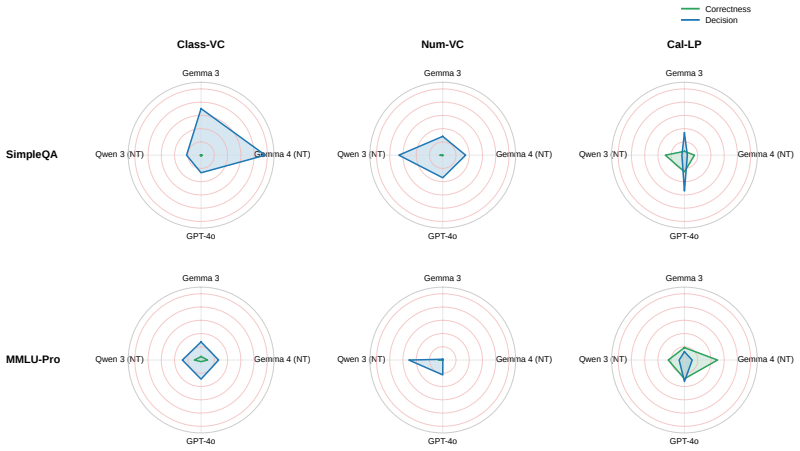
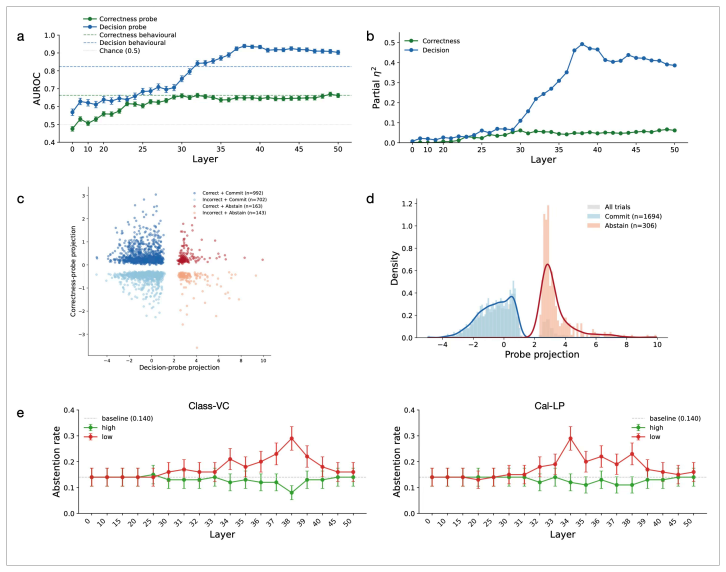
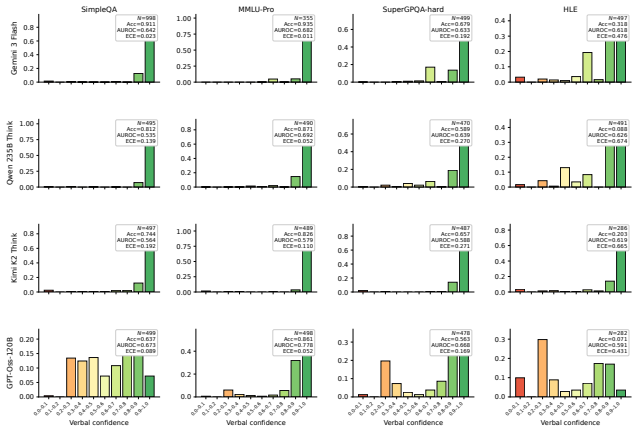
Verbal confidence reports predict the model's later decision to commit or abstain substantially better than whether the answer is actually correct. After removing variance shared with token log-probabilities, residual verbal confidence remains aligned with commitment while its link to correctness drops to chance. The pattern generalises across non-reasoning and reasoning models on tasks from hard multiple-choice to frontier freeform questions. Mechanistic probes in Gemma models show that a post-answer activation state already encodes the future abstention choice before the abstention prompt arrives, organised mainly by that decision rather than by correctness, with the two lying in approxima
What carries the argument
The two-stage abstention paradigm that separates answer generation and confidence reporting from the subsequent commit-or-abstain decision.
If this is right
- Verbal confidence should not be treated as interchangeable with log-probability signals for estimating answer reliability.
- Models can abstain from correct answers when internal commitment is low and commit to incorrect answers when commitment is high.
- Steering internal states along verbal-confidence directions can causally alter abstention rates without directly altering correctness.
- The dissociation between verbal reports and log-probabilities persists across model families and task difficulties from multiple-choice to open-ended questions.
Where Pith is reading between the lines
- Hybrid uncertainty systems could combine verbal reports for commitment prediction with log-probabilities for correctness estimation to improve selective answering.
- Applications that rely on verbal confidence for safety filters may over- or under-trigger abstention depending on internal readiness rather than factual accuracy.
- Training objectives that explicitly separate commitment signals from evidence signals could produce more interpretable model behavior.
Load-bearing premise
The two-stage abstention paradigm isolates an internal commit-readiness state in LLMs that is distinct from correctness.
What would settle it
If the residual verbal confidence after regressing out log-probabilities no longer predicts abstention decisions above chance level, or if it predicts correctness at least as strongly as commitment.
Figures






read the original abstract
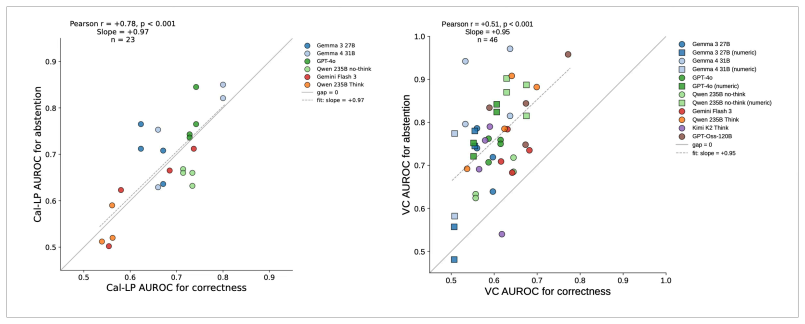
Confidence is an estimate of the probability that a chosen answer is correct. Verbal confidence reports are widely used as uncertainty measures in large language models, but whether they are best understood as estimates of correctness is unclear. We test this with a two-stage abstention paradigm from the neuroscience of perceptual decision making: a model first answers and reports its confidence, then decides whether to commit it to a user or abstain. Across four non-reasoning models, prompt framings, and confidence formats, verbal confidence predicted the commit/abstain decision substantially better than whether the answer was correct. Calibrated token log-probabilities showed the opposite profile, with abstention-prediction coupled to correctness discrimination, the signature of an answer-evidence signal. After removing the variance verbal confidence shared with log-probabilities, the residual stayed aligned with commitment while its link to correctness fell to near chance. The dissociation generalised to four reasoning models across four benchmarks of varying difficulty, from hard multiple-choice to frontier-level freeform questions. Mechanistic analyses in Gemma 3 and 4 were convergent: a post-answer state known to causally support verbal-confidence generation already encoded the future abstention decision before the abstention prompt, organised mainly by that decision rather than by correctness, the two lying in approximately orthogonal directions in activation space. Steering along a verbal-confidence-specific direction causally shifted abstention. Verbal and log-probability confidence are thus not interchangeable: log-probabilities track answer evidence and correctness, whereas verbal confidence is better understood as a behaviour-facing readout of an internal commit-readiness state, challenging the practice of treating verbal reports as proxies for reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that verbal confidence reports in LLMs track an internal commit-readiness state more closely than answer correctness. Using a two-stage abstention paradigm across four non-reasoning models (and extended to reasoning models on four benchmarks), verbal confidence predicts commit/abstain decisions substantially better than correctness, while calibrated token log-probabilities show the opposite pattern. Residual verbal confidence after removing shared variance with log-probabilities remains aligned with commitment but drops to near-chance for correctness. Mechanistic analyses in Gemma 3/4 show a post-answer activation state (known to support verbal confidence generation) encodes the future abstention decision before the abstention prompt, organized primarily by decision rather than correctness (approximately orthogonal directions), with causal evidence from steering along a verbal-confidence direction.
Significance. If the dissociation holds, the result meaningfully reframes verbal confidence as a behavior-facing readout rather than a direct correctness estimate, with implications for uncertainty estimation practices in LLMs. The convergent behavioral, residual, and causal mechanistic evidence across model scales and task difficulties is a strength; the explicit contrast with log-probability signals and the pre-abstention activation encoding provide falsifiable, testable distinctions.
major comments (3)
- [Abstract and mechanistic analyses] The central dissociation depends on the claim that a post-answer activation state encodes the future abstention decision before the abstention prompt is shown and does so independently of the verbal confidence tokens (Abstract; mechanistic analyses section). The exact token position at which this state is extracted—relative to generation of the answer, the verbal confidence report, and the subsequent abstention prompt—must be specified with a diagram or pseudocode of the forward pass, because the abstention prompt includes the prior answer+confidence sequence.
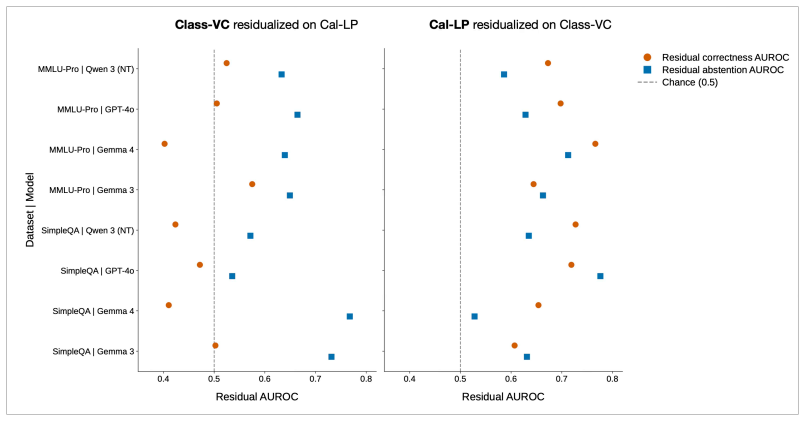
- [Results on residual variance] The residual analysis (verbal confidence after regressing out log-probability variance) is load-bearing for the claim that verbal confidence tracks commitment separately from correctness. The exact regression procedure, the resulting partial correlations or R² values with commit/abstain and with correctness, and the statistical test for the drop to near-chance must be reported with effect sizes and confidence intervals.
- [Mechanistic analyses in Gemma 3 and 4] The orthogonality claim between the abstention-decision direction and the correctness direction in activation space (mechanistic analyses) requires a quantitative measure (e.g., cosine similarity or angle) rather than the qualitative statement “approximately orthogonal,” together with a control showing that this geometry is not an artifact of the particular layer or token position chosen.
minor comments (2)
- [Methods] Clarify in the methods whether the four non-reasoning models and four reasoning models were evaluated with identical prompt templates or whether framing variations were re-tuned per model family.
- [Results on reasoning models] The generalization statement across “four benchmarks of varying difficulty” would benefit from an explicit table listing benchmark names, question formats, and average accuracy ranges.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which highlight opportunities to improve the clarity and rigor of our methodological descriptions. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and mechanistic analyses] The central dissociation depends on the claim that a post-answer activation state encodes the future abstention decision before the abstention prompt is shown and does so independently of the verbal confidence tokens (Abstract; mechanistic analyses section). The exact token position at which this state is extracted—relative to generation of the answer, the verbal confidence report, and the subsequent abstention prompt—must be specified with a diagram or pseudocode of the forward pass, because the abstention prompt includes the prior answer+confidence sequence.
Authors: We agree that explicit specification of the token position is necessary for full reproducibility. The post-answer activation state is extracted from the final token of the answer+verbal-confidence sequence, prior to any processing of the abstention prompt. In the revised manuscript we will add both a diagram of the forward pass and pseudocode that marks the exact extraction point relative to answer generation, verbal confidence tokens, and the abstention prompt. revision: yes
-
Referee: [Results on residual variance] The residual analysis (verbal confidence after regressing out log-probability variance) is load-bearing for the claim that verbal confidence tracks commitment separately from correctness. The exact regression procedure, the resulting partial correlations or R² values with commit/abstain and with correctness, and the statistical test for the drop to near-chance must be reported with effect sizes and confidence intervals.
Authors: We will expand the Methods and Results sections to report the precise regression procedure (ordinary least-squares regression of verbal confidence on log-probability), the resulting partial correlations and R² values for both commit/abstain and correctness, effect sizes, and 95% confidence intervals. We will also include the statistical test confirming the near-chance residual correlation with correctness. revision: yes
-
Referee: [Mechanistic analyses in Gemma 3 and 4] The orthogonality claim between the abstention-decision direction and the correctness direction in activation space (mechanistic analyses) requires a quantitative measure (e.g., cosine similarity or angle) rather than the qualitative statement “approximately orthogonal,” together with a control showing that this geometry is not an artifact of the particular layer or token position chosen.
Authors: We will replace the qualitative description with the cosine similarity (and corresponding angle) between the two directions. We will also add a control analysis repeating the direction extraction across multiple layers and token positions to confirm that the observed near-orthogonality is not specific to the chosen layer or position. revision: yes
Circularity Check
No circularity: purely empirical behavioral and activation analyses
full rationale
The paper presents no derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps. All central claims rest on direct experimental measurements across models, prompt framings, and benchmarks: verbal confidence predicting commit/abstain decisions, residual analyses after regressing out log-probabilities, and activation-space geometry in Gemma models. The two-stage paradigm is imported from external neuroscience literature rather than defined in terms of the target result. No self-referential definitions, ansatzes smuggled via prior work, or uniqueness theorems appear. The work is self-contained against external benchmarks and falsifiable via the reported behavioral and causal steering results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The abstention decision in the two-stage paradigm measures an internal commit-readiness state separable from correctness.
Reference graph
Works this paper leans on
-
[1]
& Kepecs, A
Pouget, A., Drugowitsch, J. & Kepecs, A. Confidence and certainty: distinct probabilistic quantities for different goals.Nature neuroscience19, 366–374 (2016)
2016
-
[2]
& Mainen, Z
Kepecs, A. & Mainen, Z. F. A computational framework for the study of confidence in humans and animals.Philosophical Transactions of the Royal Society B: Biological Sciences367, 1322–1337 (2012)
2012
-
[3]
Fleming, S. M. & Daw, N. D. Self-evaluation of decision-making: A general bayesian frame- work for metacognitive computation.Psychological review124, 91 (2017)
2017
-
[4]
Xiong, M.et al.Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [5]
- [6]
-
[7]
Neuron84, 190–201 (2014)
Lak, A.et al.Orbitofrontal cortex is required for optimal waiting based on decision confidence. Neuron84, 190–201 (2014)
2014
-
[8]
Kepecs, A., Uchida, N., Zariwala, H. A. & Mainen, Z. F. Neural correlates, computation and behavioural impact of decision confidence.Nature455, 227–231 (2008)
2008
-
[9]
How do LLMs Compute Verbal Confidence
Kumaran, D.et al.How do llms compute verbal confidence? InProceedings of the 43rd International Conference on Machine Learning (ICML)(2026). In press. Preprint: https: //arxiv.org/abs/2603.17839
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Stone, C., Mattingley, J. B. & Rangelov, D. On second thoughts: changes of mind in decision- making.Trends in Cognitive Sciences26, 419–431 (2022)
2022
-
[11]
& Mamassian, P
Balsdon, T., Wyart, V . & Mamassian, P. Confidence controls perceptual evidence accumulation. Nature communications11, 1753 (2020)
2020
-
[12]
W., Miyoshi, K., So, T
Webb, T. W., Miyoshi, K., So, T. Y ., Rajananda, S. & Lau, H. Natural statistics support a rational account of confidence biases.Nature Communications14, 3992 (2023)
2023
-
[13]
& Peters, M
Steyvers, M. & Peters, M. A. Metacognition and uncertainty communication in humans and large language models.Current Directions in Psychological Science09637214251391158 (2025)
2025
-
[14]
Teaching Models to Express Their Uncertainty in Words
Lin, S., Hilton, J. & Evans, O. Teaching models to express their uncertainty in words.arXiv preprint arXiv:2205.14334(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Kadavath, S.et al.Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Causal Evidence that Language Models use Confidence to Drive Behavior
Kumaran, D., Daw, N., Osindero, S., Veli ˇckovi´c, P. & Patraucean, V . Causal evidence that language models use confidence to drive behavior.Nature Machine Intelligence(2026). In press. Preprint:https://arxiv.org/abs/2603.22161
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
& Shadlen, M
Kiani, R. & Shadlen, M. N. Representation of confidence associated with a decision by neurons in the parietal cortex.science324, 759–764 (2009)
2009
-
[18]
J., Smith, J
Beran, M. J., Smith, J. D., Redford, J. S. & Washburn, D. A. Rhesus macaques (macaca mulatta) monitor uncertainty during numerosity judgments.Journal of Experimental Psychology: Animal Behavior Processes32, 111 (2006). 28
2006
-
[19]
Wei, J.et al.Measuring short-form factuality in large language models.arXiv preprint arXiv:2411.04368(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Wang, Y .et al.Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems37, 95266–95290 (2024)
2024
-
[21]
Du, X.et al.Supergpqa: Scaling llm evaluation across 285 graduate disciplines.arXiv preprint arXiv:2502.14739(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Center for AI Safety, H. C. C., Scale AI. A benchmark of expert-level academic questions to assess ai capabilities.Nature649, 1139–1146 (2026)
2026
-
[23]
& Weinberger, K
Guo, C., Pleiss, G., Sun, Y . & Weinberger, K. Q. On calibration of modern neural networks. In International conference on machine learning, 1321–1330 (PMLR, 2017)
2017
-
[24]
& Reviriego, P
Fu, T., Conde, J., Martinez, G., Grandury, M. & Reviriego, P. Multiple choice questions: Reasoning makes large language models (llms) more self-confident, specially when they are wrong.IEEE Intelligent Systems(2026)
2026
-
[25]
& Gal, Y
Farquhar, S., Kossen, J., Kuhn, L. & Gal, Y . Detecting hallucinations in large language models using semantic entropy.Nature630, 625–630 (2024)
2024
-
[26]
& Song, D
Kang, Z., Zhao, X. & Song, D. Scalable best-of-n selection for large language models via self-certainty.Advances in neural information processing systems38, 19720–19745 (2026)
2026
-
[27]
Fu, Y ., Wang, X., Tian, Y . & Zhao, J. Deep think with confidence.arXiv preprint arXiv:2508.15260(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Steering Language Models With Activation Engineering
Turner, A. M.et al.Steering language models with activation engineering.arXiv preprint arXiv:2308.10248(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Lindsey, J. Emergent introspective awareness in large language models.arXiv preprint arXiv:2601.01828(2026)
-
[30]
Macar, U.et al.Mechanisms of introspective awareness.arXiv preprint arXiv:2603.21396 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
& Summerfield, C
Yeung, N. & Summerfield, C. Metacognition in human decision-making: confidence and error monitoring.Philosophical Transactions of the Royal Society B: Biological Sciences367, 1310–1321 (2012)
2012
-
[32]
Folke, T., Jacobsen, C., Fleming, S. M. & De Martino, B. Explicit representation of confidence informs future value-based decisions.Nature Human Behaviour1, 0002 (2016)
2016
-
[33]
& Donner, T
Desender, K., Boldt, A., Verguts, T. & Donner, T. H. Confidence predicts speed-accuracy tradeoff for subsequent decisions.eLife8, e43499 (2019)
2019
-
[34]
& Lau, H
Maniscalco, B. & Lau, H. A signal detection theoretic approach for estimating metacognitive sensitivity from confidence ratings.Consciousness and Cognition21, 422–430 (2012)
2012
-
[35]
Conditional logit analysis of qualitative choice behavior 105–142 (1974)
McFadden, D. Conditional logit analysis of qualitative choice behavior 105–142 (1974)
1974
-
[36]
van Smeden, M.et al.Sample size for binary logistic prediction models: Beyond events per variable criteria.Statistical Methods in Medical Research28, 2455–2474 (2019)
2019
-
[37]
& Friedman, J.The Elements of Statistical Learning: Data Mining, Inference, and Prediction(Springer, New York, 2009), 2nd edn
Hastie, T., Tibshirani, R. & Friedman, J.The Elements of Statistical Learning: Data Mining, Inference, and Prediction(Springer, New York, 2009), 2nd edn
2009
-
[38]
V ., Pencina, M
Demler, O. V ., Pencina, M. J. & D’Agostino, R. B. Misuse of DeLong test to compare AUCs for nested models.Statistics in Medicine31, 2577–2587 (2012)
2012
-
[39]
Nature Machine Intelligence1–14 (2026)
Kumaran, D.et al.Competing biases underlie overconfidence and underconfidence in llms. Nature Machine Intelligence1–14 (2026). 29 Acknowledgments We thank Nathaniel Daw, Maks Ovsjanikov, Kim Stachenfeld and Beningo Uria for comments on an earlier version of the manuscript. We used Gemini to help improve the clarity and readability of the manuscript. 30 1 ...
2026
-
[40]
some questions have NO correct answer; if you don’t see a clearly correct answer, choose B
{choice 4} Your previous answer: {model answer} You now need to decide whether to output your answer to the user (A) or abstain (B). Remember, that your answer should be a single letter, no spaces, no punctuation, no words. Decision: Further details of residual analysis Reciprocal residual analysis of verbal confidence and Cal-LP. To distinguish the compo...
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.