Do Models Read What They Write? Causal Registers in Scratchpad Reasoning
Pith reviewed 2026-06-30 07:24 UTC · model grok-4.3
The pith
Models trained to write scratchpad states predict the downstream effects of edits to those states far more often than models that skip writing intermediates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
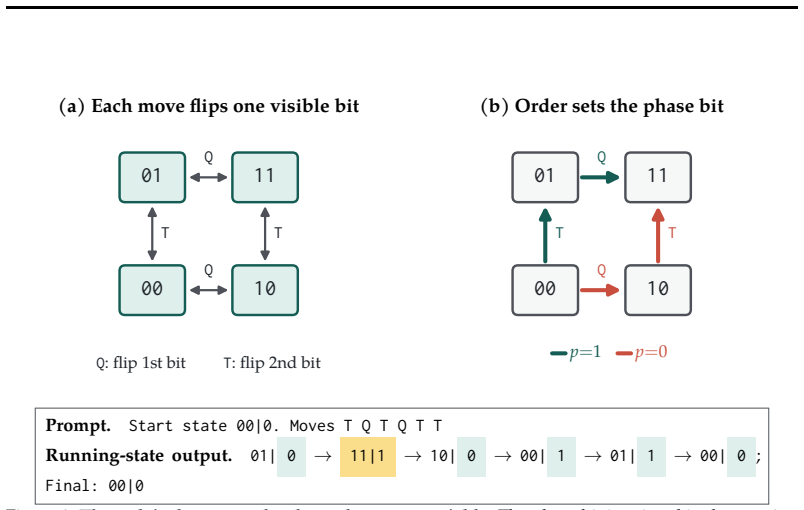
In Qwen2.5-Coder-7B and other families, a model trained to write intermediate states before the final answer follows the next phase bit implied by an edited internal state representation on 80% and 91% of held-out examples, whereas models trained only on final answers or left pretrained remain near baseline. The dependence holds after controls for generic next-token steering and for copying another continuation, and it requires both the edited state and the current move.
What carries the argument
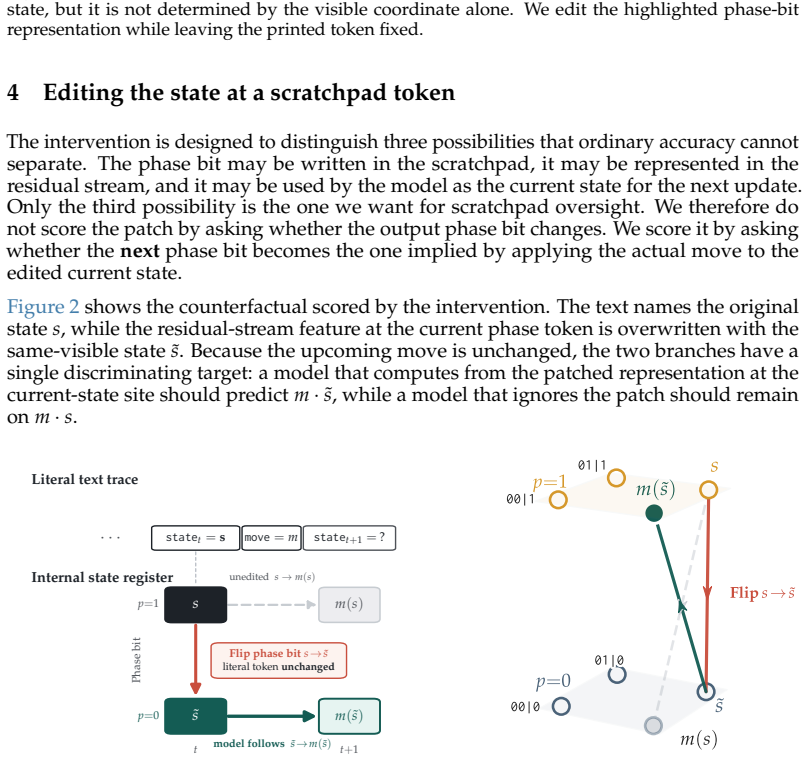
Causal intervention that edits the internal representation of one written state while the visible scratchpad text remains unchanged, measured against a known transition rule in a state-tracking task.
If this is right
- Process supervision can produce written states that the model treats as inputs to its own later steps.
- The same causal-use pattern appears across multiple model families.
- Oversight of scratchpads should aim to train states that are both legible and actually used in computation.
- The effect is specific to the edited state and the current move rather than generic continuation steering.
Where Pith is reading between the lines
- Training objectives that reward causal use of written states could be added to standard process-supervision pipelines.
- The same editing technique might be applied to more open-ended reasoning tasks to test whether causal registers appear outside controlled state tracking.
- If written states are causally active, methods that monitor or edit those states could directly influence final outputs without changing the visible text.
Load-bearing premise
Editing the internal representation of one written state while leaving the visible scratchpad text fixed isolates the causal dependence of later computation on that written state rather than on other internal variables.
What would settle it
If the state-writing model, after the internal edit, predicts the next phase bit at rates no higher than the final-answer-only control across the held-out examples in either task variant.
Figures

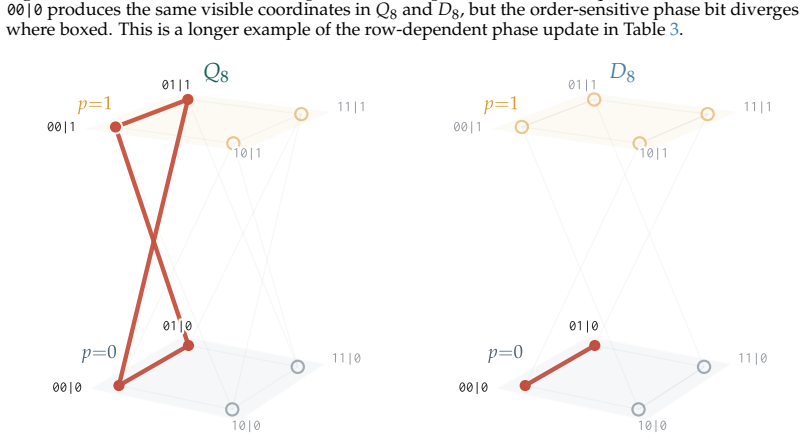



read the original abstract
A central hope behind process supervision is that models can expose intermediate variables that matter for their later behavior. For this to help with alignment, a scratchpad must be tied to the computation: when the model writes a state, later steps should compute from that state. To test this requirement, we use a controlled state-tracking task with a known update rule, comparing models trained to report only the final state with models trained to write intermediate states before giving the final answer. At evaluation, we edit the internal representation of one written state while leaving the visible scratchpad text fixed. Because the transition rule is known, the edit has a single correct downstream consequence. In Qwen2.5-Coder-7B, the state-writing model predicts the next phase bit implied by the edited state on 80% and 91% of held-out examples across the two task variants, while pretrained and final-answer-only controls remain near baseline. Additional controls rule out generic next-token steering and copying another continuation: the prediction depends on both the edited state and the current move. The same causal-use pattern replicates across model families. Together, these results suggest a sharper goal for scratchpad oversight: not just to make intermediate reasoning legible, but to train written states that the model uses as part of its computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that models trained to write intermediate states in scratchpads causally use those states in later computation. Using state-tracking tasks with known update rules, state-writing models are compared to final-answer-only and pretrained controls. Interventions edit the internal representation of a written state (visible text fixed); the state-writing model then predicts the next phase bit implied by the edit on 80% and 91% of held-out examples in two variants for Qwen2.5-Coder-7B, while controls stay near baseline. Additional controls show the effect depends on both the edited state and current move; the pattern replicates across model families.
Significance. If the result holds, the work supplies direct evidence that process supervision can produce written states that are not merely legible but causally integrated into the model's computation. This is relevant for alignment techniques that rely on scratchpad oversight. The manuscript earns credit for its explicit controls against generic next-token steering and copying, plus replication across model families, which together address the isolation concern raised by the intervention design.
minor comments (3)
- [§3] §3 (Methods): the exact layer, head, and token position at which the state representation is edited should be stated explicitly, as this detail is needed to assess whether the intervention truly targets only the written state.
- [Table 1, Figure 3] Table 1 and Figure 3: report the exact number of held-out examples and any statistical test used for the 80% / 91% figures so readers can evaluate precision and variability.
- [§5] §5 (Discussion): the claim that the result 'suggests a sharper goal for scratchpad oversight' would be strengthened by a short paragraph contrasting the observed causal-use rates with those expected under pure next-token prediction.
Simulated Author's Rebuttal
We thank the referee for their accurate summary of the work and for the positive assessment, including the recommendation for minor revision. The report correctly identifies the core contribution regarding causal use of written states under interventions. No major comments were listed in the report, so we have no point-by-point responses to provide at this stage. We remain available to address any minor suggestions or clarifications during revision.
Circularity Check
No significant circularity; empirical intervention study
full rationale
The paper reports an empirical causal intervention experiment on scratchpad reasoning in LLMs. It trains models on state-tracking tasks, performs targeted edits to internal representations of written states, and measures downstream prediction accuracy against controls (pretrained, final-answer-only, and additional steering/copying controls). No equations, fitted parameters, ansatzes, or self-citations are used to derive the central claims; the results are direct experimental measurements on held-out examples across model families. The protocol is self-contained against external benchmarks and does not reduce any prediction to a definitional equivalence or prior self-citation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The transition rule is known and each edit therefore has exactly one correct downstream consequence.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year =
J. Engels, E. J. Michaud, I. Liao, W. Gurnee, and M. Tegmark. Not all language model features are one-dimensionally linear. arXiv:2405.14860,
-
[2]
Arithmetic in the Wild: Llama uses Base-10 Addition to Reason About Cyclic Concepts
S. Feucht, T. Haklay, U. Bhalla, et al. Arithmetic in the wild: Llama uses base-10 addition to reason about cyclic concepts. arXiv:2605.01148,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
mlr.press/v119/kalatzis20a.html
S. Kantamneni and M. Tegmark. Language models use trigonometry to do addition. arXiv:2502.00873,
-
[4]
Measuring Faithfulness in Chain-of-Thought Reasoning
T. Lanham, A. Chen, A. Radhakrishnan, et al. Measuring faithfulness in chain-of-thought reasoning. arXiv:2307.13702,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
M. Nye, A. J. Andreassen, G. Gur-Ari, et al. Show your work: Scratchpads for intermediate computation with language models. arXiv:2112.00114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
In-context Learning and Induction Heads
C. Olsson, N. Elhage, N. Nanda, et al. In-context learning and induction heads. arXiv:2209.11895,
work page internal anchor Pith review Pith/arXiv arXiv
- [7]
-
[8]
11 A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. MacDiarmid. Steering language models with activation engineering. arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Manifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior
D. Wurgaft, C. Rager, M. Kowal, et al. Manifold steering reveals the shared geometry of neural network representation and behavior. arXiv:2605.05115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
A. Zou, L. Phan, S. Chen, et al. Representation engineering: A top-down approach to AI transparency. arXiv:2310.01405,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
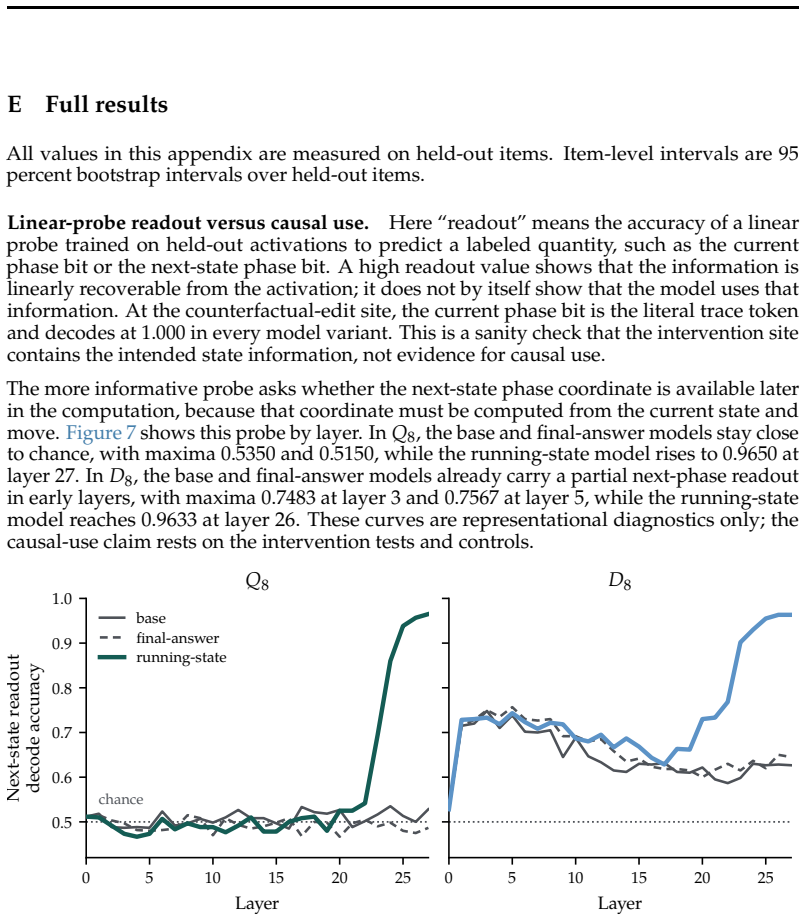
These curves are representational diagnostics only; the causal-use claim rests on the intervention tests and controls. 0 5 10 15 20 25 Layer 0.5 0.6 0.7 0.8 0.9 1.0 Next-state readout decode accuracychance Q8 base final-answer running-state 0 5 10 15 20 25 Layer D8 Figure 7: Linear-probe readout of the next-state phase coordinate by layer. Probe accuracy i...
2025
-
[12]
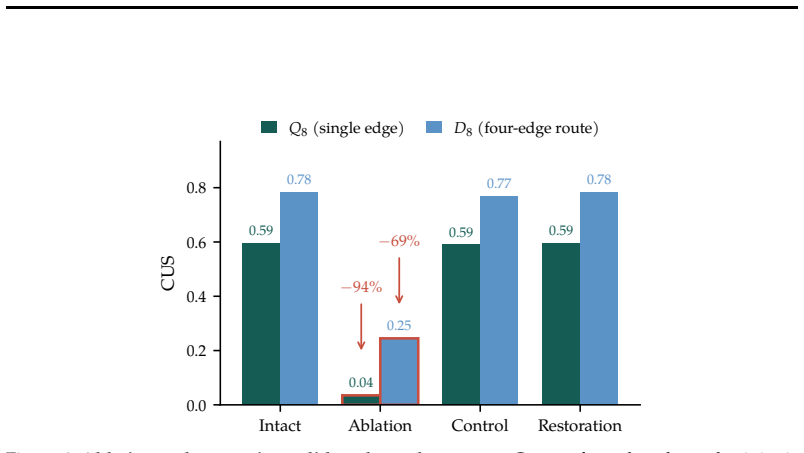
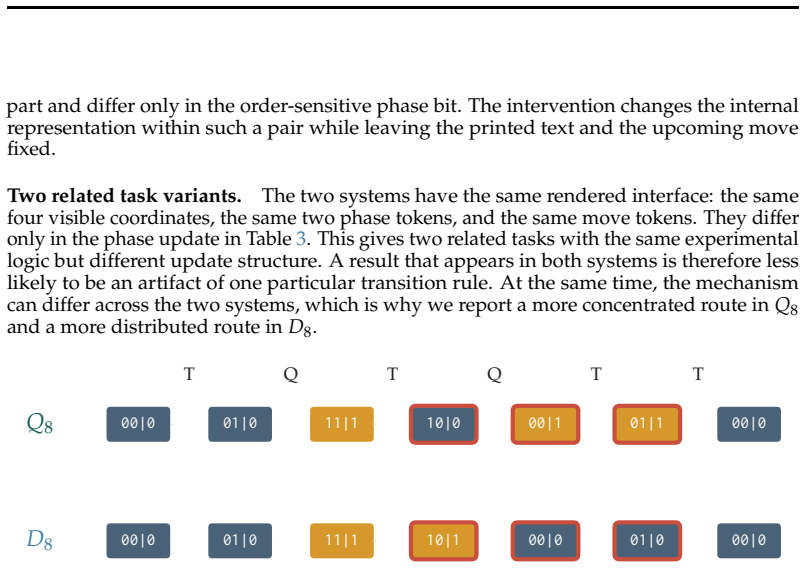
No single edge passes the single-edge criterion (the largest, L22, removes only 24 percent), so theD 8 update is distributed where theQ 8 update is concentrated
Across all ten splits both matched controls preserve the selectivity (the quotient-source and off-target destination controls stay near 0.82), the clean restoration recovers it, and ordinary unedited behavior is intact (P( ˆpt+1 =p(m·s)) = 0.88). No single edge passes the single-edge criterion (the largest, L22, removes only 24 percent), so theD 8 update ...
2000
-
[13]
Entries are mean CUS removed. Edge Alone Leave-one-out drop Layer 22, current phase bit 0.212 0.346 Layer 19, move token 0.113 0.021 Layer 25, current phase bit 0.078 0.039 Layer 23, current phase bit 0.069 0.258 Full routeE 4 (all four) 0.532 n/a 24 G Extended related work Scratchpads and faithfulness.Scratchpad and chain-of-thought methods show that ask...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.