One Scene, Two Depths: Probing Geometric Ambiguity in Monocular Foundation Models
Pith reviewed 2026-06-30 06:56 UTC · model grok-4.3
The pith
Monocular depth foundation models resolve the same layered scene to different depths, as revealed by a new benchmark on transparent scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
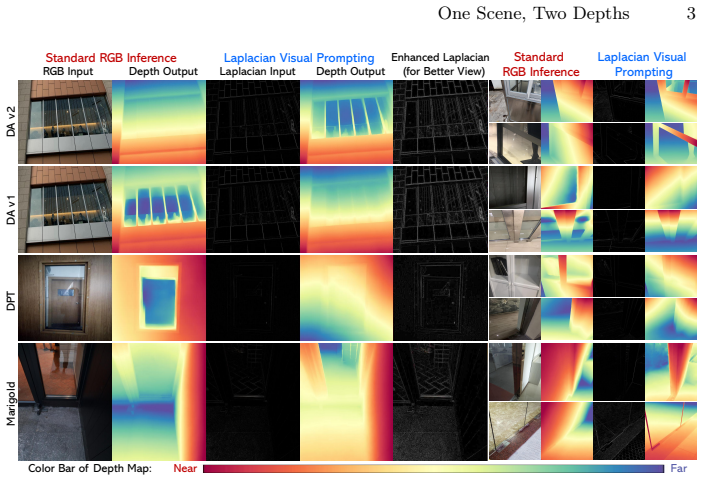
Depth foundation models exhibit diverse layer preferences on the same layered geometry under standard RGB input. Laplacian Visual Prompting, a training-free spectral input transformation, can substantially change the reported layer for certain frozen models. The strongest RGB/LVP pair reaches 75.5 percent ML-SRA on MD-3k, suggesting that multiple valid 3D interpretations of a scene can be measured, preserved, and expressed through an ambiguity-aware lens.
What carries the argument
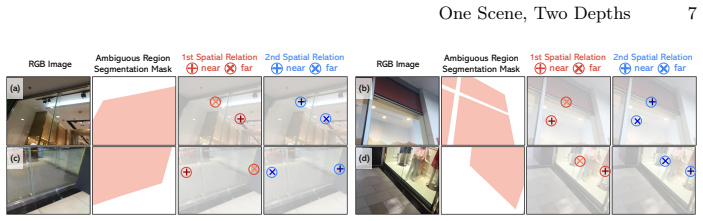
The MultiDepth-3k (MD-3k) benchmark, which uses sparse two-layer ordinal annotations on transparent scenes to measure depth-layer preference and multi-layer spatial relationship accuracy (ML-SRA).
Load-bearing premise
The sparse two-layer ordinal annotations and ML-SRA metric in MD-3k provide a reliable, annotation-independent measure of geometric layer preference.
What would settle it
All leading depth models producing identical layer selections on MD-3k under both standard RGB and LVP inputs, or ML-SRA scores failing to correlate with actual multi-surface visibility in controlled ray-tracing tests.
Figures








read the original abstract
A faithful 3D world representation should account for layered geometry, where a single camera ray may contain multiple visible and geometrically valid surfaces. Monocular depth estimation, however, reduces this structure to one scalar depth per pixel. Transparent scenes make this ambiguity measurable: the same ray can pass through foreground glass and observe the background, turning the supervised target into a convention of annotation, data, and training rather than a scene-intrinsic truth. A learned predictor exposes this convention as its depth-layer preference. We introduce MultiDepth-3k (MD-3k), a sparse two-layer ordinal benchmark for measuring depth-layer preference and multi-layer spatial relationship accuracy (ML-SRA). On MD-3k, leading depth foundation models exhibit diverse layer preferences under standard RGB input, showing that the same layered geometry can be resolved differently across models. We further find that Laplacian Visual Prompting (LVP), a training-free spectral input transformation, can substantially change the reported layer for certain frozen models. The strongest RGB/LVP pair, DAv2-L, reaches 75.5% ML-SRA. These results suggest that depth foundation models may express complementary geometric hypotheses that standard RGB inference leaves unexpressed. We invite the community to rethink depth supervision and evaluation through an ambiguity-aware lens, where multiple valid 3D interpretations are treated as geometric structure to be measured, preserved, and expressed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MultiDepth-3k (MD-3k) benchmark of sparse two-layer ordinal annotations on transparent/layered scenes to measure depth foundation models' layer preferences. It reports diverse preferences across models under standard RGB input and shows that Laplacian Visual Prompting (LVP) can alter the preferred layer for frozen models, with the strongest RGB/LVP pair (DAv2-L) reaching 75.5% ML-SRA. The central claim is that these models express complementary geometric hypotheses on the same scene that standard inference leaves unexpressed.
Significance. If MD-3k validly isolates intrinsic layer preference, the work would usefully demonstrate that current monocular depth models encode different geometric conventions on ambiguous scenes and that training-free input transformations like LVP can surface alternative hypotheses. The empirical probe on multiple foundation models and the introduction of an ambiguity-aware metric are strengths; the training-free character of LVP is also noted positively.
major comments (2)
- [§3] §3 (MD-3k construction): No details are provided on the annotation protocol, inter-annotator agreement, or explicit steps taken to ensure the two-layer ordinal labels are collected orthogonally to conventions in common depth-training corpora (e.g., foreground-glass vs. background prioritization). This is load-bearing for the claim that observed preferences and LVP effects reflect geometric ambiguity rather than dataset overlap.
- [§4] §4 (experimental results): The reported 75.5% ML-SRA and claims of 'diverse' layer preferences across models lack reported statistical controls (confidence intervals, significance tests, or model-selection criteria), making it difficult to assess whether the diversity is robust or could be explained by benchmark construction choices.
minor comments (2)
- [§3] The definition and computation of the ML-SRA metric on sparse annotations should be stated more explicitly, including how ties or missing layers are handled.
- Figure captions and axis labels for layer-preference visualizations could be clarified to indicate whether percentages are normalized per model or across the benchmark.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (MD-3k construction): No details are provided on the annotation protocol, inter-annotator agreement, or explicit steps taken to ensure the two-layer ordinal labels are collected orthogonally to conventions in common depth-training corpora (e.g., foreground-glass vs. background prioritization). This is load-bearing for the claim that observed preferences and LVP effects reflect geometric ambiguity rather than dataset overlap.
Authors: We agree that additional details on MD-3k construction are necessary to support the central claims. In the revised manuscript we will expand §3 with a full description of the annotation protocol (including annotator instructions and collection procedure), report inter-annotator agreement, and document the explicit steps taken to select scenes and instruct annotators so that labels remain orthogonal to common depth-training conventions such as foreground prioritization. revision: yes
-
Referee: [§4] §4 (experimental results): The reported 75.5% ML-SRA and claims of 'diverse' layer preferences across models lack reported statistical controls (confidence intervals, significance tests, or model-selection criteria), making it difficult to assess whether the diversity is robust or could be explained by benchmark construction choices.
Authors: We concur that statistical controls would improve interpretability. The revised §4 will include bootstrap confidence intervals for all ML-SRA scores, pairwise significance tests on layer-preference differences, and an explicit statement of model-selection criteria. These additions will allow readers to evaluate whether the observed diversity is robust. revision: yes
Circularity Check
No circularity: empirical evaluation on newly introduced benchmark
full rationale
The paper introduces MD-3k as a new sparse two-layer ordinal benchmark and reports empirical results (layer preferences, ML-SRA scores) for existing frozen models under RGB and LVP inputs. No equations, derivations, or fitted parameters are present that reduce any reported metric to quantities defined from the same evaluation data. No self-citation chains or uniqueness theorems are invoked to justify core claims. The work is self-contained as an observational probe; observed diversity in model outputs on MD-3k does not reduce to annotation conventions by construction within the paper's text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Monocular depth estimation reduces layered geometry to one scalar depth per pixel.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2203.17274 (2022)
Bahng, H., Jahanian, A., Sankaranarayanan, S., Isola, P.: Exploring visual prompts for adapting large-scale models. arXiv preprint arXiv:2203.17274 (2022)
-
[2]
In: CVPR
Bai, Y., Geng, X., Mangalam, K., Bar, A., Yuille, A.L., Darrell, T., Malik, J., Efros, A.A.: Sequential modeling enables scalable learning for large vision models. In: CVPR. pp. 22861–22872 (2024)
2024
-
[3]
In: CVPR (2021)
Bhat, S.F., Alhashim, I., Wonka, P.: Adabins: Depth estimation using adaptive bins. In: CVPR (2021)
2021
-
[4]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Bhat, S.F., Birkl, R., Wofk, D., Wonka, P., Müller, M.: Zoedepth: Zero-shot transfer by combining relative and metric depth. arXiv:2302.12288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
1–a model zoo for robust monocular relative depth estimation
Birkl, R., Wofk, D., Müller, M.: Midas v3. 1–a model zoo for robust monocular relative depth estimation. arXiv:2307.14460 (2023)
-
[6]
In: ICLR (2025)
Bochkovskiy, A., Delaunoy, A., Germain, H., Santos, M., Zhou, Y., Richter, S., Koltun, V.: Depth pro: Sharp monocular metric depth in less than a second. In: ICLR (2025)
2025
-
[7]
NeurIPS33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. NeurIPS33, 1877–1901 (2020)
1901
-
[8]
In: ICASSP
Chen, A., Lorenz, P., Yao, Y., Chen, P.Y., Liu, S.: Visual prompting for adversarial robustness. In: ICASSP. pp. 1–5. IEEE (2023)
2023
-
[9]
In: ICRA
Chen, K., Wang, S., Xia, B., Li, D., Kan, Z., Li, B.: TODE-Trans: Transparent object depth estimation with transformer. In: ICRA. pp. 4880–4886 (2023)
2023
-
[10]
In: CIKM
Chen, L., Fan, Y., Ye, Y.: Adversarial reprogramming of pretrained neural networks for fraud detection. In: CIKM. pp. 2935–2939 (2021)
2021
-
[11]
In: NeurIPS (2016)
Chen, W., Fu, Z., Yang, D., Deng, J.: Single-image depth perception in the wild. In: NeurIPS (2016)
2016
-
[12]
In: NeurIPS (2014)
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using a multi-scale deep network. In: NeurIPS (2014)
2014
-
[13]
IEEE Robotics and Automation Letters7(3), 7383–7390 (2022)
Fang, H., Fang, H.S., Xu, S., Lu, C.: Transcg: A large-scale real-world dataset for transparent object depth completion and a grasping baseline. IEEE Robotics and Automation Letters7(3), 7383–7390 (2022)
2022
-
[14]
ECCV (2024)
Fu, X., Yin, W., Hu, M., Wang, K., Ma, Y., Tan, P., Shen, S., Lin, D., Long, X.: Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image. ECCV (2024)
2024
-
[15]
Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J.W., Wallach, H., Daumé III, H., Crawford, K.: Datasheets for datasets. Commun. ACM64(12), 86–92 (nov 2021)
2021
-
[16]
IJRR (2013)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. IJRR (2013)
2013
-
[17]
In: AAAI (2025)
Gui, M., Schusterbauer, J., Prestel, U., Ma, P., Kotovenko, D., Grebenkova, O., Baumann, S.A., Hu, V.T., Ommer, B.: DepthFM: Fast monocular depth estimation with flow matching. In: AAAI (2025)
2025
-
[18]
In: CVPR (2024)
Ke, B., Obukhov, A., Huang, S., Metzger, N., Daudt, R.C., Schindler, K.: Repur- posing diffusion-based image generators for monocular depth estimation. In: CVPR (2024)
2024
-
[19]
CVPR (2023)
Khattak, M.U., Rasheed, H., Maaz, M., Khan, S., Khan, F.S.: Maple: Multi-modal prompt learning. CVPR (2023)
2023
-
[20]
TPAMI (2023) One Scene, Two Depths 17
Liang, Y., Deng, B., Liu, W., Qin, J., He, S.: Monocular depth estimation for glass walls with context: a new dataset and method. TPAMI (2023) One Scene, Two Depths 17
2023
-
[21]
In: CVPR
Mei, H., Yang, X., Wang, Y., Liu, Y., He, S., Zhang, Q., Wei, X., Lau, R.W.: Don’t hit me! glass detection in real-world scenes. In: CVPR. pp. 3687–3696 (2020)
2020
-
[22]
In: WACV
Neekhara, P., Hussain, S., Du, J., Dubnov, S., Koushanfar, F., McAuley, J.: Cross- modal adversarial reprogramming. In: WACV. pp. 2427–2435 (2022)
2022
-
[23]
In: CVPR
Piccinelli, L., Sakaridis, C., Segu, M., Yang, Y.H., Li, S., Abbeloos, W., Van Gool, L.: Unik3d: Universal camera monocular 3d estimation. In: CVPR. pp. 1028–1039 (2025)
2025
-
[24]
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Piccinelli, L., Sakaridis, C., Yang, Y.H., Segu, M., Li, S., Abbeloos, W., Van Gool, L.: Unidepthv2: Universal monocular metric depth estimation made simpler. arXiv preprint arXiv:2502.20110 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
In: ICCV (2021)
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: ICCV (2021)
2021
-
[26]
TPAMI (2022)
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., Koltun, V.: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. TPAMI (2022)
2022
-
[27]
In: ICCV (2021)
Roberts, M., Ramapuram, J., Ranjan, A., Kumar, A., Bautista, M.A., Paczan, N., Webb, R., Susskind, J.M.: Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. In: ICCV (2021)
2021
-
[28]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[29]
In: ICRA
Sajjan, S., Moore, M., Pan, M., Nagaraja, G., Lee, J., Zeng, A., Song, S.: ClearGrasp: 3D shape estimation of transparent objects for manipulation. In: ICRA. pp. 3634– 3642 (2020)
2020
-
[30]
In: CVPR (2017)
Schops, T., Schonberger, J.L., Galliani, S., Sattler, T., Schindler, K., Pollefeys, M., Geiger, A.: A multi-view stereo benchmark with high-resolution images and multi-camera videos. In: CVPR (2017)
2017
-
[31]
In: ECCV (2012)
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from rgbd images. In: ECCV (2012)
2012
-
[32]
In: ICCV Workshops
Singha, M., Pal, H., Jha, A., Banerjee, B.: AD-CLIP: Adapting domains in prompt space using CLIP. In: ICCV Workshops. pp. 4355–4364 (2023)
2023
-
[33]
ICML (2020)
Tsai, Y.Y., Chen, P.Y., Ho, T.Y.: Transfer learning without knowing: Reprogram- ming black-box machine learning models with scarce data and limited resources. ICML (2020)
2020
-
[34]
In: AAAI (2024)
Wang, H., Liu, F., Jiao, L., Wang, J., Hao, Z., Li, S., Li, L., Chen, P., Liu, X.: Vilt-clip: Video and language tuning clip with multimodal prompt learning and scenario-guided optimization. In: AAAI (2024)
2024
-
[35]
In: CVPR
Wasim, S.T., Naseer, M., Khan, S., Khan, F.S., Shah, M.: Vita-clip: Video and text adaptive clip via multimodal prompting. In: CVPR. pp. 23034–23044 (2023)
2023
-
[36]
ICCV (2025)
Wen, H., Zuo, Y., Subramanian, V., Chen, P., Deng, J.: Seeing and seeing through the glass: Real and synthetic data for multi-layer depth estimation. ICCV (2025)
2025
-
[37]
In: CVPR (2024)
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., Zhao, H.: Depth anything: Un- leashing the power of large-scale unlabeled data. In: CVPR (2024)
2024
-
[38]
NeurIPS (2024)
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. NeurIPS (2024)
2024
-
[39]
In: ICCV (2023)
Yin, W., Zhang, C., Chen, H., Cai, Z., Yu, G., Wang, K., Chen, X., Shen, C.: Metric3d: Towards zero-shot metric 3d prediction from a single image. In: ICCV (2023)
2023
-
[40]
In: ICCV (2023) 18 Xu et al
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: ICCV (2023) 18 Xu et al
2023
-
[41]
foreground
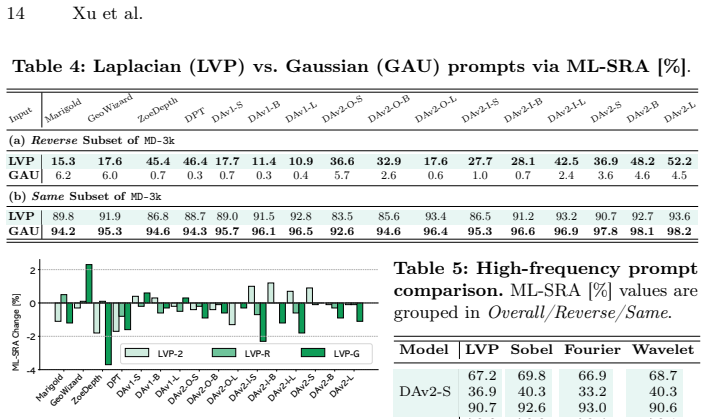
Zhu, L., Mousavian, A., Xiang, Y., Mazhar, H., van Eenbergen, J., Debnath, S., Fox, D.: RGB-D local implicit function for depth completion of transparent objects. In: CVPR. pp. 12725–12734 (2021) One Scene, Two Depths 19 Table A: ML-SRA onMD-3k with alternative high-frequency prompts.Each cell reportsOverall/Reverse/Same[%]. The effect generalizes beyond ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.