Demystifying the Design Space and Best Practices for Heterogeneous LLM Inference and Serving
Pith reviewed 2026-06-30 05:34 UTC · model grok-4.3
The pith
Heterogeneous prefill-decode LLM inference reduces to three recurring boundary decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
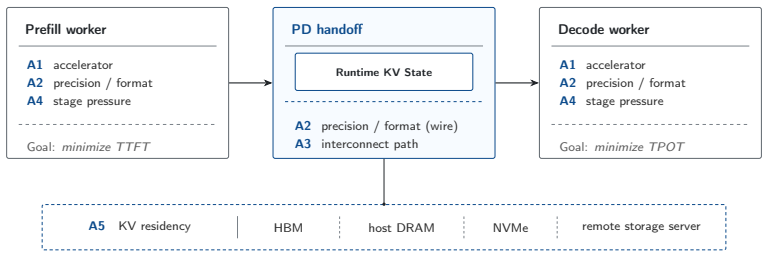
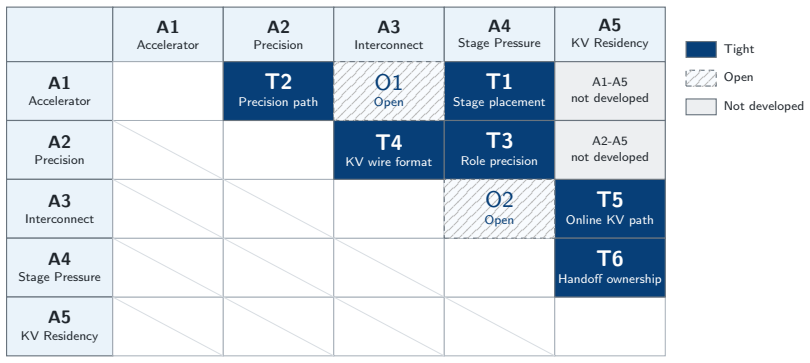
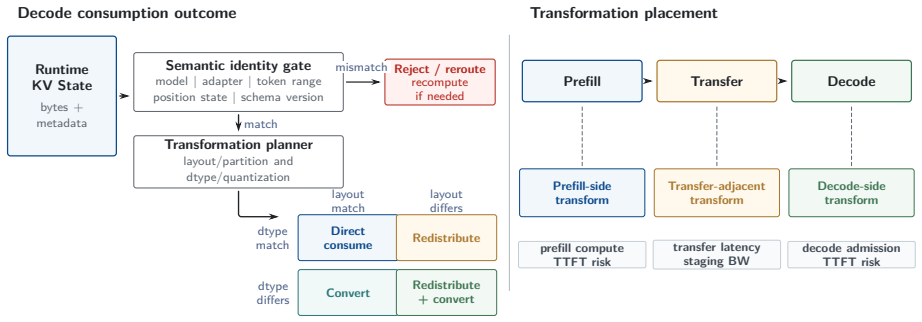
Only a subset of interactions among accelerator, precision, interconnect, and KV residency become binding constraints once PD inference becomes heterogeneous. These interactions surface through three recurring boundary decisions: compute placement, KV representation, and KV ownership. The resulting analysis yields concrete guidance: precision policy belongs to runtime roles rather than a single system-wide setting, KV transfer engines move bytes rather than tensor semantics so representation compatibility is an explicit boundary concern, and the KV handoff carries a lifecycle that requires explicit ownership spanning prefill and decode.
What carries the argument
The three recurring boundary decisions—compute placement, KV representation, and KV ownership—that surface the binding constraints within the four-axis design space of accelerator, precision, interconnect, and KV residency under stage pressure.
If this is right
- Precision policy should be assigned to individual runtime roles instead of a single system-wide setting.
- KV transfer engines must treat representation compatibility as an explicit concern whenever producer and consumer formats differ.
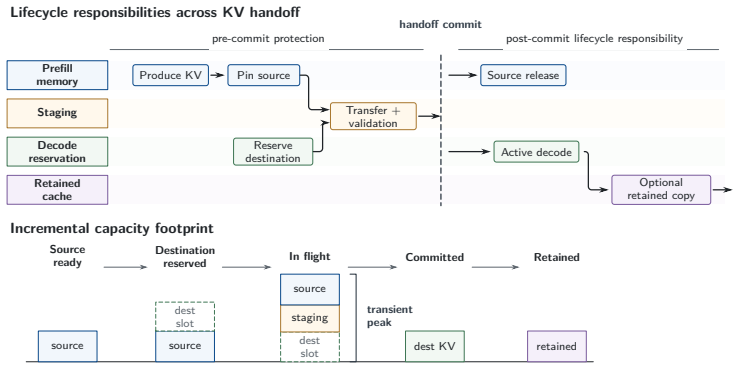
- KV handoff must carry explicit ownership, reservation, release, and failure recovery that spans both stages.
Where Pith is reading between the lines
- The same three-decision lens could be applied to other multi-stage ML pipelines that cross hardware boundaries.
- Cross-vendor and interconnect claims left open in the paper could be tested by measuring transfer overheads in a controlled multi-vendor cluster.
- If the three decisions prove exhaustive, runtime schedulers could expose them as first-class configuration primitives rather than hidden implementation details.
Load-bearing premise
The claim that the three boundary decisions are the complete set of binding constraints rests on the premise that the examined industrial deployments and runtime source code are representative of all heterogeneous setups.
What would settle it
A production heterogeneous prefill-decode deployment whose performance bottleneck cannot be traced to compute placement, KV representation, or KV ownership would falsify the reduction to three decisions.
Figures
read the original abstract
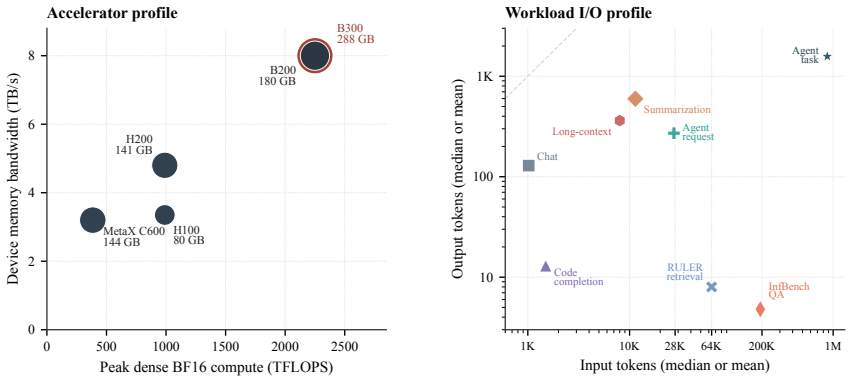
Heterogeneous prefill-decode (PD) inference is now in production: prefill on cost-efficient or supply-available accelerators, decode on bandwidth-strong ones, and KV state crossing mixed interconnects in mixed numerical formats. Each deployment makes these decisions on its own. What is missing is the picture across configurations-which decisions must be made jointly at the PD boundary, and which can be made independently. We propose a design space organized along four design axes-accelerator, precision, interconnect, and KV residency and the workload regime (stage pressure) they respond to. We show that only a subset of interactions among these factors become binding constraints once PD inference becomes heterogeneous. These interactions surface through three recurring boundary decisions: compute placement, KV representation, and KV ownership. The resulting analysis yields concrete guidance. Precision policy belongs to runtime roles rather than to a single system-wide setting, because the same low-bit format relieves different bottlenecks on each side of the boundary. KV transfer engines move bytes rather than tensor semantics, making representation compatibility an explicit boundary concern whenever producer and consumer differ. The KV handoff also carries a lifecycle-reservation, release, and failure recovery-that spans prefill and decode and requires explicit ownership. Two further interactions remain open. Cross-vendor and interconnect-related claims are stated as design guidance grounded in industrial deployment observations and source-code inspection of the runtimes involved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to demystify the design space for heterogeneous prefill-decode LLM inference by organizing it along four axes—accelerator, precision, interconnect, and KV residency—modulated by stage pressure. It argues that interactions among these axes surface as binding constraints only through three recurring boundary decisions: compute placement, KV representation, and KV ownership. This leads to guidance that precision policy should be role-specific rather than system-wide, KV transfer engines handle byte compatibility explicitly, and KV handoff requires explicit ownership spanning prefill and decode stages. The analysis is based on industrial deployment observations and runtime source-code inspection, leaving two interactions open.
Significance. If valid, this provides a practical framework for heterogeneous LLM serving systems, helping to identify which decisions must be made jointly at the PD boundary. The emphasis on real deployment observations adds value by translating production experience into structured advice on precision, representation, and ownership. Strengths include the explicit acknowledgment of open issues and grounding in observed systems rather than purely theoretical models.
major comments (1)
- [Abstract] Abstract: The claim that only three recurring boundary decisions capture the binding interactions among the four axes rests on the unverified exhaustiveness of the observed deployments and runtimes. Without a systematic enumeration of possible interactions or counterexamples (e.g., potential decisions like cross-stage scheduling that cannot be folded into the three), the completeness of the set is not demonstrated, which is load-bearing for the central characterization of the design space.
minor comments (1)
- [Abstract] Abstract: The abstract states that 'two further interactions remain open' but does not name them; specifying these in the main text would improve clarity on the scope of the analysis.
Simulated Author's Rebuttal
We thank the referee for the careful review and for acknowledging the value of grounding the framework in observed deployments. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that only three recurring boundary decisions capture the binding interactions among the four axes rests on the unverified exhaustiveness of the observed deployments and runtimes. Without a systematic enumeration of possible interactions or counterexamples (e.g., potential decisions like cross-stage scheduling that cannot be folded into the three), the completeness of the set is not demonstrated, which is load-bearing for the central characterization of the design space.
Authors: The manuscript does not claim formal or exhaustive completeness; it states that the three decisions are the recurring boundary points observed across the inspected industrial deployments and runtimes, and explicitly notes that two further interactions remain open. Cross-stage scheduling, for example, is resolved in practice through the compute-placement and KV-ownership decisions already identified. We agree that the presentation would benefit from an added paragraph in the introduction or discussion section that (a) reiterates the observational basis, (b) illustrates how additional candidate decisions map onto the three, and (c) reiterates the open issues. This clarification does not alter the core claim but makes the scope explicit. revision: partial
Circularity Check
No circularity; claims rest on external observations
full rationale
The paper organizes a design space along four axes and asserts that interactions reduce to three recurring boundary decisions (compute placement, KV representation, KV ownership). This characterization is explicitly attributed to industrial deployment observations and source-code inspection of runtimes rather than to any internal equation, fitted parameter, self-citation chain, or definitional equivalence. No equations, fitted quantities, or load-bearing self-citations appear in the supplied text. The central claim therefore does not reduce to its own inputs by construction and remains open to external falsification via additional deployments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous prefill-decode inference is already deployed in production with prefill on cost-efficient accelerators and decode on bandwidth-strong ones.
Reference graph
Works this paper leans on
-
[1]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving, 2024. OSDI 2024; arXiv:2401.09670 [cs.DC]
arXiv 2024
-
[2]
Splitwise: Efficient generative LLM inference using phase splitting, 2023
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative LLM inference using phase splitting, 2023. arXiv:2311.18677 [cs.AR]
arXiv 2023
-
[3]
AWQ: Activation-aware weight quantization for LLM compression and acceleration, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for LLM compression and acceleration, 2024. MLSys 2024 Best Paper Award; arXiv:2306.00978 [cs.CL]
Pith/arXiv arXiv 2024
-
[4]
QServe: W4A8KV4 quantization and system co-design for efficient LLM serving, 2024
Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, and Song Han. QServe: W4A8KV4 quantization and system co-design for efficient LLM serving, 2024. arXiv:2405.04532 [cs.CL]
arXiv 2024
-
[5]
LMCache: An efficient KV cache layer for enterprise-scale LLM inference,
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, and Junchen Jiang. LMCache: An efficient KV cache layer for enterprise-scale LLM inference,
-
[6]
arXiv:2510.09665 [cs.LG]
-
[7]
Mooncake: A KVCache-centric disaggregated architecture for LLM serving, 2024
Ruoyu Qin, Zheming Li, Weiran He, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: A KVCache-centric disaggregated architecture for LLM serving, 2024. arXiv:2407.00079 [cs.DC]
arXiv 2024
-
[8]
vLLM NIXL KV connector source
vLLM Project. vLLM NIXL KV connector source. https://github.com/vllm-project/vllm/tree/ d272418f459a82e1012b60116ac00659a7017cde/vllm/distributed/kv_transfer/kv_connector/ v1/nixl, 2026. Source checked at commit d272418f459a82e1012b60116ac00659a7017cde
2026
-
[9]
fabric-lib: RDMA point-to-point communication for LLM systems, 2025
Nandor Licker, Kevin Hu, Vladimir Zaytsev, and Lequn Chen. fabric-lib: RDMA point-to-point communication for LLM systems, 2025. arXiv:2510.27656 [cs.DC]
Pith/arXiv arXiv 2025
-
[10]
UB-Mesh: A hierarchically localized nD-FullMesh datacenter network architecture, 2025
Heng Liao, Bingyang Liu, Xianping Chen, Zhigang Guo, Chuanning Cheng, et al. UB-Mesh: A hierarchically localized nD-FullMesh datacenter network architecture, 2025. arXiv:2503.20377 [cs.AR]
arXiv 2025
-
[11]
Inference without interference: Disaggregate LLM inference for mixed downstream workloads, 2024
Cunchen Hu, Heyang Huang, Liangliang Xu, Xusheng Chen, Jiang Xu, Shuang Chen, Hao Feng, Chenxi Wang, Sa Wang, Yungang Bao, Ninghui Sun, and Yizhou Shan. Inference without interference: Disaggregate LLM inference for mixed downstream workloads, 2024. arXiv:2401.11181 [cs.DC]
arXiv 2024
-
[12]
NVIDIA H100 Tensor Core GPU: Product specifications
NVIDIA. NVIDIA H100 Tensor Core GPU: Product specifications. https://www.nvidia.com/en-us/ data-center/h100/, 2026. Product specifications page; accessed June 21, 2026
2026
-
[13]
NVIDIA H200 Tensor Core GPU: Specifications
NVIDIA. NVIDIA H200 Tensor Core GPU: Specifications. https://www.nvidia.com/en-us/ data-center/h200/, 2026. Product specifications page; accessed June 21, 2026
2026
-
[14]
NVIDIA DGX B200: Specifications
NVIDIA. NVIDIA DGX B200: Specifications. https://www.nvidia.com/en-us/data-center/ dgx-b200/, 2026. System specifications page used for per-GPU B200 memory and HBM bandwidth; accessed June 22, 2026
2026
-
[15]
NVIDIA HGX Platform: Specifications
NVIDIA. NVIDIA HGX Platform: Specifications. https://www.nvidia.com/en-us/data-center/hgx/,
-
[16]
HGX B200/B300 system specifications page used for Tensor Core dense-value derivations; accessed June 22, 2026
2026
-
[17]
NVIDIA Blackwell Ultra: Datasheet
NVIDIA. NVIDIA Blackwell Ultra: Datasheet. https://resources.nvidia.com/ en-us-blackwell-architecture/blackwell-ultra-datasheet , 2026. Datasheet linked from NVIDIA HGX specifications page; used for B300 per-GPU memory and HBM bandwidth; accessed June 22, 2026. 13
2026
-
[18]
MetaX C600: Product page
MetaX. MetaX C600: Product page. https://www.metax-tech.com/prod.html?cid=107&id=68, 2026. Product page for the MetaX C600; accessed June 22, 2026
2026
-
[19]
Efficient attentions for long document summarization, 2021
Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, and Lu Wang. Efficient attentions for long document summarization, 2021. NAACL 2021; arXiv:2104.02112 [cs.CL]
arXiv 2021
-
[20]
Network and systems performance characterization of MCP-enabled LLM agents, 2025
Zihao Ding, Mufeng Zhu, and Yao Liu. Network and systems performance characterization of MCP-enabled LLM agents, 2025. arXiv:2511.07426 [cs.DC]
arXiv 2025
-
[21]
RULER: What’s the real context size of your long-context language models?, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models?, 2024. COLM 2024; arXiv:2404.06654 [cs.CL]
Pith/arXiv arXiv 2024
-
[22]
∞Bench: Extending long context evaluation beyond 100k tokens,
Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Khai Hao, Xu Han, Zhen Leng Thai, Shuo Wang, Zhiyuan Liu, and Maosong Sun. ∞Bench: Extending long context evaluation beyond 100k tokens,
-
[23]
arXiv:2402.13718 [cs.CL]
-
[24]
Mix-Quant: Quantized prefilling, precise decoding for agentic LLMs, 2026
Haiquan Lu, Zigeng Chen, Gongfan Fang, Xinyin Ma, and Xinchao Wang. Mix-Quant: Quantized prefilling, precise decoding for agentic LLMs, 2026. arXiv:2605.20315 [cs.CL]
Pith/arXiv arXiv 2026
- [25]
-
[26]
QQQ: Quality quattuor-bit quantization for large language models, 2024
Ying Zhang, Peng Zhang, Mincong Huang, Jingyang Xiang, Yujie Wang, Chao Wang, Yineng Zhang, Lei Yu, Chuan Liu, and Wei Lin. QQQ: Quality quattuor-bit quantization for large language models, 2024. arXiv:2406.09904 [cs.CL]
arXiv 2024
-
[27]
KIVI: A tuning-free asymmetric 2bit quantization for KV cache, 2024
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. KIVI: A tuning-free asymmetric 2bit quantization for KV cache, 2024. ICML 2024; arXiv:2402.02750 [cs.CL]
Pith/arXiv arXiv 2024
-
[28]
SAW-INT4: System-aware 4-bit KV-cache quantization for real-world LLM serving, 2026
Jinda Jia, Jisen Li, Zhongzhu Zhou, Jung Hwan Heo, Jue Wang, Tri Dao, Shuaiwen Leon Song, Ben Athiwaratkun, Chenfeng Xu, Tianyi Zhang, and Xiaoxia Wu. SAW-INT4: System-aware 4-bit KV-cache quantization for real-world LLM serving, 2026. arXiv:2604.19157 [cs.LG]
Pith/arXiv arXiv 2026
-
[29]
Weiqing Li, Guochao Jiang, Xiangyong Ding, Zhangcheng Tao, Chuzhan Hao, Chenfeng Xu, Yuewei Zhang, and Hao Wang. FlowKV: A disaggregated inference framework with low-latency KV cache transfer and load-aware scheduling, 2025. arXiv:2504.03775 [cs.DC]
arXiv 2025
-
[30]
TENT: Transfer engine next overview
Mooncake Project. TENT: Transfer engine next overview. https://github.com/kvcache-ai/Mooncake/ blob/d0e4b6a029ab38827b872087025f621d7e432e1b/docs/source/design/tent/overview.md. Pinned implementation documentation at commit d0e4b6a029ab38827b872087025f621d7e432e1b
-
[31]
Zedong Liu, Xinyang Ma, Dejun Luo, Hairui Zhao, Bing Lu, Wenjing Huang, Yida Gu, Xingchen Liu, Zheng Wei, Jinyang Liu, Dingwen Tao, and Guangming Tan. KVServe: Service-aware KV cache compression for communication-efficient disaggregated LLM serving, 2026. SIGCOMM 2026; arXiv:2605.13734 [cs.DC]
Pith/arXiv arXiv 2026
-
[32]
Yang Pengju. SpectrumKV: Per-token mixed-precision KV cache transfer for prefill-decode disaggregated LLM serving, 2026. arXiv:2606.08635 [cs.LG]
Pith/arXiv arXiv 2026
-
[33]
Harvest: Opportunistic peer-to-peer GPU caching for LLM inference, 2026
Nikhil Gopal and Kostis Kaffes. Harvest: Opportunistic peer-to-peer GPU caching for LLM inference, 2026. arXiv:2602.00328 [cs.LG]
arXiv 2026
-
[34]
HGCA: Hybrid GPU-CPU attention for long context LLM inference, 2025
Weishu Deng, Yujie Yang, Peiran Du, Lingfeng Xiang, Zhen Lin, Chen Zhong, Song Jiang, Hui Lu, and Jia Rao. HGCA: Hybrid GPU-CPU attention for long context LLM inference, 2025. arXiv:2507.03153 [cs.LG]
arXiv 2025
-
[35]
NIXL KV cache lease
vLLM Project. NIXL KV cache lease. https://github.com/vllm-project/vllm/blob/ d272418f459a82e1012b60116ac00659a7017cde/docs/design/nixl_kv_cache_lease.md, 2026. Pinned documentation at commit d272418f459a82e1012b60116ac00659a7017cde
2026
-
[36]
SGLang PD disaggregation
SGLang Project. SGLang PD disaggregation. https://github.com/sgl-project/sglang/blob/ ff1fc1fbdff315fe44b9431ca5aae00d7bd7f733/docs/advanced_features/pd_disaggregation.md,
-
[37]
Pinned documentation at commit ff1fc1fbdff315fe44b9431ca5aae00d7bd7f733
-
[38]
NIXL KV push connector
vLLM Project. NIXL KV push connector. https://github.com/vllm-project/vllm/blob/ d272418f459a82e1012b60116ac00659a7017cde/docs/design/nixl_kv_push_connector.md, 2026. Pinned documentation at commit d272418f459a82e1012b60116ac00659a7017cde
2026
-
[39]
SGLang PD disaggregation source
SGLang Project. SGLang PD disaggregation source. https://github.com/sgl-project/sglang/tree/ ff1fc1fbdff315fe44b9431ca5aae00d7bd7f733/python/sglang/srt/disaggregation, 2026. Source checked at commit ff1fc1fbdff315fe44b9431ca5aae00d7bd7f733. 14
2026
-
[40]
CacheGen: KV cache compression and streaming for fast large language model serving, 2023
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, and Junchen Jiang. CacheGen: KV cache compression and streaming for fast large language model serving, 2023. SIGCOMM 2024; arXiv:2310.07240 [cs.NI]
arXiv 2023
-
[41]
DéjàVu: KV-cache streaming for fast, fault-tolerant generative LLM serving, 2024
Foteini Strati, Sara Mcallister, Amar Phanishayee, Jakub Tarnawski, and Ana Klimovic. DéjàVu: KV-cache streaming for fast, fault-tolerant generative LLM serving, 2024. arXiv:2403.01876 [cs.DC]
arXiv 2024
-
[42]
FlagCX: Scalable and adaptive cross-chip communication library
FlagOS AI. FlagCX: Scalable and adaptive cross-chip communication library. https: //github.com/flagos-ai/FlagCX, 2026. Repository and documentation inspected at commit de066401c49eeb0d0b9436f5e54664378e0b83a6
2026
-
[43]
Prefill-as-a-service: KVCache of next-generation models could go cross-datacenter, 2026
Ruoyu Qin, Weiran He, Yaoyu Wang, Zheming Li, Xinran Xu, Yongwei Wu, Weimin Zheng, and Mingxing Zhang. Prefill-as-a-service: KVCache of next-generation models could go cross-datacenter, 2026. arXiv:2604.15039v2
Pith/arXiv arXiv 2026
-
[44]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention,
-
[45]
SOSP 2023; arXiv:2309.06180 [cs.LG]
Pith/arXiv arXiv 2023
-
[46]
SPAD: Specialized prefill and decode hardware for disaggregated LLM inference, 2025
Hengrui Zhang, Pratyush Patel, August Ning, and David Wentzlaff. SPAD: Specialized prefill and decode hardware for disaggregated LLM inference, 2025. arXiv:2510.08544 [cs.AR]
arXiv 2025
-
[47]
Ruihan Lin, Zezhen Ding, Zean Han, and Jiheng Zhang. Large-scale LLM inference with heterogeneous workloads: Prefill-decode contention and asymptotically optimal control, 2026. arXiv:2602.02987 [cs.DC]
Pith/arXiv arXiv 2026
-
[48]
Xing Chen, Rong Shi, Lu Zhao, Lingbin Wang, Xiao Jin, Yueqiang Chen, and Hongfeng Sun. Disaggregated prefill and decoding inference system for large language model serving on multi-vendor GPUs, 2025. arXiv:2509.17542 [cs.DC]
arXiv 2025
-
[49]
Huawei cloud model-as-a-service on the CloudMatrix384 SuperPod, 2025
Ao Xiao, Bangzheng He, Baoquan Zhang, Baoxing Huai, Bingji Wang, et al. Huawei cloud model-as-a-service on the CloudMatrix384 SuperPod, 2025. arXiv:2508.02520 [cs.DC]. 15
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.