SMART-MIG: A Learning Framework for Scalable and Energy-Efficient GPU Scheduling
Pith reviewed 2026-06-30 04:42 UTC · model grok-4.3
The pith
SMART-MIG uses mean-field multi-agent reinforcement learning to repartition MIG GPUs at constant complexity, improving energy-tardiness efficiency by 18 percent over static methods while remaining within 27 percent of the theoretical energy
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SMART-MIG combines mean-field multi-agent reinforcement learning for large-scale MIG repartitioning decisions with tailored heuristic algorithms for job scheduling onto the resulting partitions. The repartitioning component maintains constant complexity regardless of the number of jobs or GPUs. Theoretical lower bounds on energy consumption and tardiness are established for benchmarking. Experiments demonstrate an 18 percent improvement in energy-tardiness efficiency relative to static partitioning, while energy use stays only 27 percent above the derived lower bound.
What carries the argument
Mean-field multi-agent reinforcement learning (MF-MARL) for deciding dynamic MIG partitions, paired with heuristic job schedulers that operate on the resulting heterogeneous slices.
If this is right
- Repartitioning decisions can be made online without the algorithmic cost growing with system size.
- Energy consumption can be kept close to a proven theoretical minimum while still meeting tardiness targets.
- The same separation of learning-based repartitioning from heuristic scheduling can be applied to other partitionable accelerators.
- Static partitioning baselines can be replaced by this adaptive approach with a quantified efficiency gain.
Where Pith is reading between the lines
- The constant-complexity property would allow the scheduler to react to sudden changes in job mix without needing to add more compute nodes for the controller itself.
- If the mean-field approximation remains accurate under bursty arrivals, the framework could be extended to co-schedule CPU and GPU resources in the same data center.
- The established lower bounds could serve as a target for future schedulers even if they use different learning methods.
Load-bearing premise
That the mean-field multi-agent reinforcement learning component combined with the tailored heuristics will produce stable, near-optimal repartitioning decisions at large scale without hidden per-step overheads or sensitivity to workload statistics not captured in the experiments.
What would settle it
Measure wall-clock time and energy for repartitioning steps on clusters with ten times more GPUs and jobs than the reported experiments while using workload traces whose statistical properties differ from the training distribution; if either the constant-complexity claim or the 18 percent efficiency gain fails to hold, the central result is falsified.
Figures

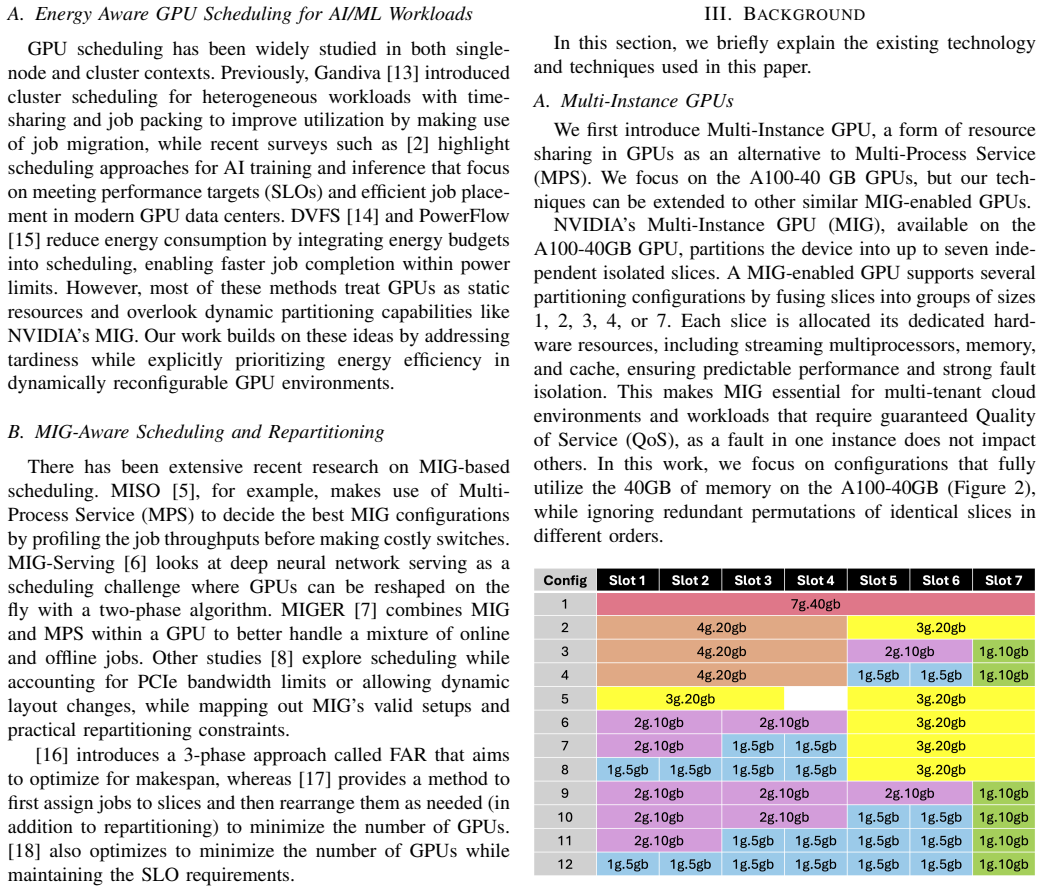








read the original abstract
The emergence of Multi-Instance GPU (MIG) technology enables us to run smaller machine learning models on partitions of a GPU rather than the entire device, thus improving utilization and reducing energy consumption, albeit with potential performance trade-offs. Meanwhile, the growing energy demands of GPU-equipped data centers motivate the development of online partitioning and scheduling schemes that not only ensure fast job processing but also achieve high energy efficiency. However, achieving energy-tardiness efficiency with manageable algorithmic complexity in large-scale scheduling remains a great challenge, due to the dual objectives of deciding on the GPU partitions and scheduling jobs onto the slices of the heterogeneous partitions. To address this challenge, we propose SMART-MIG, a parallel computing system that combines Mean-Field Multi-Agent Reinforcement Learning (MF-MARL) for large-scale MIG repartitioning with tailored heuristic algorithms for job scheduling. We demonstrate that the complexity of the repartitioning component remains constant even as the number of jobs and GPUs increases. We also establish theoretical lower bounds on energy consumption and tardiness to rigorously benchmark system performance. Finally, extensive experiments show that SMART-MIG improves the energy-tardiness efficiency by $18\%$ compared to its corresponding static-partitioning counterpart, while being only $27\%$ above the theoretical lower bound on energy consumption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SMART-MIG, a parallel computing system for Multi-Instance GPU (MIG) environments that uses Mean-Field Multi-Agent Reinforcement Learning (MF-MARL) for dynamic repartitioning combined with tailored heuristic algorithms for job scheduling. It claims that the repartitioning component has constant complexity independent of the number of jobs and GPUs, derives theoretical lower bounds on energy consumption and tardiness, and reports experimental results showing an 18% improvement in energy-tardiness efficiency over static partitioning while operating only 27% above the energy lower bound.
Significance. If the central claims hold, the work would be significant for large-scale GPU data-center scheduling by providing a scalable learning-based approach to MIG partitioning that balances energy and tardiness. The explicit provision of theoretical lower bounds is a strength, as it supplies an independent benchmark rather than relying solely on empirical comparisons. The constant-complexity claim, if substantiated, would address a key practical barrier in online scheduling at growing system sizes.
major comments (2)
- [Abstract] Abstract: The claim that 'the complexity of the repartitioning component remains constant even as the number of jobs and GPUs increases' is load-bearing for the scalability contribution, yet the text supplies no approximation-error bounds, scaling plots, or analysis of how mean-field interactions remain accurate when job-size heterogeneity or arrival correlations are present; without these, the constant-complexity assertion cannot be verified.
- [Abstract] Abstract: The headline numerical results (18% energy-tardiness efficiency gain and 27% above the energy lower bound) are presented without reference to workload characteristics, number of GPUs/jobs tested, statistical significance, or the precise derivation of the lower bounds; these omissions make it impossible to assess whether the mean-field decisions remain near-optimal or whether the 27% gap is an artifact of bound construction.
minor comments (1)
- [Abstract] The abstract refers to 'extensive experiments' but does not name the evaluation metrics for energy-tardiness efficiency or the baseline static-partitioning scheme in sufficient detail for immediate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments point-by-point below, clarifying where details appear in the full manuscript and indicating revisions to improve verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'the complexity of the repartitioning component remains constant even as the number of jobs and GPUs increases' is load-bearing for the scalability contribution, yet the text supplies no approximation-error bounds, scaling plots, or analysis of how mean-field interactions remain accurate when job-size heterogeneity or arrival correlations are present; without these, the constant-complexity assertion cannot be verified.
Authors: The constant-complexity claim follows from the mean-field limit in MF-MARL (Section 4), where each agent's local state is replaced by the population mean field, yielding per-agent decision complexity independent of the total number of jobs or GPUs. Scaling plots appear in Figure 7 and complexity analysis in Theorem 1. We acknowledge that explicit approximation-error bounds under job-size heterogeneity and correlated arrivals are not derived. We will add a short discussion of mean-field validity conditions and reference the existing scaling results in a revised abstract. revision: partial
-
Referee: [Abstract] Abstract: The headline numerical results (18% energy-tardiness efficiency gain and 27% above the energy lower bound) are presented without reference to workload characteristics, number of GPUs/jobs tested, statistical significance, or the precise derivation of the lower bounds; these omissions make it impossible to assess whether the mean-field decisions remain near-optimal or whether the 27% gap is an artifact of bound construction.
Authors: The 18% improvement is measured on synthetic workloads with 200–1000 jobs across 20–50 GPUs (Section 6.1); statistical significance is reported via 95% confidence intervals in Table 3. The energy lower bound is obtained in Section 5 by relaxing the joint partitioning+scheduling problem to independent per-job energy minimization. We will revise the abstract to include workload scale, GPU count, and explicit section references for the bound derivation. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes SMART-MIG as a combination of MF-MARL for repartitioning and heuristics for scheduling, claims constant complexity for the repartitioning component, derives theoretical lower bounds on energy and tardiness as independent benchmarks, and reports empirical gains (18% vs static partitioning, 27% above lower bound) from experiments. No load-bearing step reduces by construction to a fitted input, self-citation, or renamed ansatz; the performance figures are presented as measured outcomes of the system rather than tautological re-expressions of the inputs or approximations. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Data centers and their energy consump- tion: Frequently asked questions,
M. C. Offutt and L. Zhu, “Data centers and their energy consump- tion: Frequently asked questions,” Tech. Rep. R48646, Congressional Research Service, August 2025
2025
-
[2]
Deep learning workload scheduling in gpu datacenters: A survey,
Z. Ye, W. Gao, Q. Hu, P. Sun, X. Wang, Y . Luo, T. Zhang, and Y . Wen, “Deep learning workload scheduling in gpu datacenters: A survey,”ACM Computing Surveys, vol. 56, no. 6, pp. 1–38, 2024
2024
-
[3]
M. Abdin, J. Aneja, H. Behl, S. Bubeck, R. Eldan, S. Gunasekar, M. Harrison, R. J. Hewett, M. Javaheripi, P. Kauffmann,et al., “Phi-4 technical report,”arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Gemma 2: Improving Open Language Models at a Practical Size
G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ram ´e,et al., “Gemma 2: Improving open language models at a practical size,”arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Miso: exploiting multi-instance gpu capability on multi-tenant gpu clusters,
B. Li, T. Patel, S. Samsi, V . Gadepally, and D. Tiwari, “Miso: exploiting multi-instance gpu capability on multi-tenant gpu clusters,” inProceed- ings of the 13th Symposium on Cloud Computing, pp. 173–189, 2022
2022
-
[6]
C. Tan, Z. Li, J. Zhang, Y . Cao, S. Qi, Z. Liu, Y . Zhu, and C. Guo, “Serving dnn models with multi-instance gpus: A case of the reconfig- urable machine scheduling problem,”arXiv preprint arXiv:2109.11067, 2021
-
[7]
Miger: Integrating multi-instance gpu and multi-process service for deep learning clusters,
B. Zhang, S. Li, and Z. Li, “Miger: Integrating multi-instance gpu and multi-process service for deep learning clusters,” inProceedings of the 53rd International Conference on Parallel Processing, pp. 504–513, 2024
2024
-
[8]
Pcie bandwidth-aware scheduling for multi-instance gpus,
Y .-M. Tang, W.-F. Sun, H.-T. Ting, M.-H. Chen, I.-H. Chung, and J. Chou, “Pcie bandwidth-aware scheduling for multi-instance gpus,” inProceedings of the International Conference on High Performance Computing in Asia-Pacific Region, pp. 43–51, 2025
2025
-
[9]
Complexity of preemptive minsum scheduling on unrelated parallel machines,
R. Sitters, “Complexity of preemptive minsum scheduling on unrelated parallel machines,”Journal of Algorithms, vol. 57, no. 1, pp. 37–48, 2005
2005
-
[10]
Optimizing gpu sharing for container-based dnn serving with multi-instance gpus,
X. Wei, Z. Li, and C. Tan, “Optimizing gpu sharing for container-based dnn serving with multi-instance gpus,” inProceedings of the 17th ACM International Systems and Storage Conference, SYSTOR ’24, (New York, NY , USA), p. 68–82, Association for Computing Machinery, 2024
2024
-
[11]
Zeus: Understanding and optimizing{GPU}energy consumption of{DNN}training,
J. You, J.-W. Chung, and M. Chowdhury, “Zeus: Understanding and optimizing{GPU}energy consumption of{DNN}training,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pp. 119–139, 2023
2023
-
[12]
Energy efficient scheduling of ai/ml workloads on multi instance gpus with dynamic repartitioning,
E. Lipe, N. Karia, C. Espenshade, C. Stein, A. Tantawi, and O. Tardieu, “Energy efficient scheduling of ai/ml workloads on multi instance gpus with dynamic repartitioning,” in2025 IEEE 25th International Symposium on Cluster, Cloud and Internet Computing (CCGrid), pp. 53– 62, IEEE, 2025
2025
-
[13]
Gandiva: Introspective cluster scheduling for deep learning,
W. Xiao, R. Bhardwaj, R. Ramjee, M. Sivathanu, N. Kwatra, Z. Han, P. Patel, X. Peng, H. Zhao, Q. Zhang,et al., “Gandiva: Introspective cluster scheduling for deep learning,” in13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pp. 595–610, 2018
2018
-
[14]
The impact of gpu dvfs on the energy and performance of deep learning: An empirical study,
Z. Tang, Y . Wang, Q. Wang, and X. Chu, “The impact of gpu dvfs on the energy and performance of deep learning: An empirical study,” inProceedings of the Tenth ACM International Conference on Future Energy Systems, pp. 315–325, 2019
2019
-
[15]
Energy-efficient gpu clusters scheduling for deep learning,
D. Gu, X. Xie, G. Huang, X. Jin, and X. Liu, “Energy-efficient gpu clusters scheduling for deep learning,”arXiv preprint arXiv:2304.06381, 2023
-
[16]
Leveraging multi- instance gpus through moldable task scheduling,
J. Villarrubia, L. Costero, F. D. Igual, and K. Olcoz, “Leveraging multi- instance gpus through moldable task scheduling,”Journal of Parallel and Distributed Computing, p. 105128, 2025
2025
-
[17]
Optimal workload placement on multi-instance gpus,
B. Turkkan, P. Murali, P. Harsha, R. Arora, G. Vanloo, and C. Narayanaswami, “Optimal workload placement on multi-instance gpus,”arXiv preprint arXiv:2409.06646, 2024
-
[18]
Parvagpu: Efficient spatial gpu sharing for large- scale dnn inference in cloud environments,
M. Lee, S. Seong, M. Kang, J. Lee, G.-J. Na, I.-G. Chun, D. Nikolopou- los, and C.-H. Hong, “Parvagpu: Efficient spatial gpu sharing for large- scale dnn inference in cloud environments,” inProceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis, pp. 1–14, 2024
2024
-
[19]
Resource man- agement with deep reinforcement learning,
H. Mao, M. Alizadeh, I. Menache, and S. Kandula, “Resource man- agement with deep reinforcement learning,” inProceedings of the 15th ACM workshop on hot topics in networks, pp. 50–56, 2016
2016
-
[20]
Mean field multi-agent reinforcement learning,
Y . Yang, R. Luo, M. Li, M. Zhou, W. Zhang, and J. Wang, “Mean field multi-agent reinforcement learning,” inInternational conference on machine learning, pp. 5571–5580, PMLR, 2018
2018
-
[21]
Reinforcement learning in stationary mean-field games,
J. Subramanian and A. Mahajan, “Reinforcement learning in stationary mean-field games,” inProceedings of the 18th international conference on autonomous agents and multiagent systems, pp. 251–259, 2019
2019
-
[22]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
M. L. Pinedo,Scheduling, vol. 29. Springer, 2012
2012
-
[24]
Mean-field controls with q- learning for cooperative marl: convergence and complexity analysis,
H. Gu, X. Guo, X. Wei, and R. Xu, “Mean-field controls with q- learning for cooperative marl: convergence and complexity analysis,” SIAM Journal on Mathematics of Data Science, vol. 3, no. 4, pp. 1168– 1196, 2021
2021
-
[25]
H. Zhang, Y . Li, W. Xiao, Y . Huang, X. Di, J. Yin, S. See, Y . Luo, C. T. Lau, and Y . You, “Migperf: A comprehensive benchmark for deep learning training and inference workloads on multi-instance gpus,”arXiv preprint arXiv:2301.00407, 2023
-
[26]
Paris and elsa: An elastic scheduling al- gorithm for reconfigurable multi-gpu inference servers,
Y . Kim, Y . Choi, and M. Rhu, “Paris and elsa: An elastic scheduling al- gorithm for reconfigurable multi-gpu inference servers,” inProceedings of the 59th ACM/IEEE Design Automation Conference, pp. 607–612, 2022
2022
-
[27]
Preemptive scheduling of uniform machines subject to release dates,
J. Labetoulle, E. L. Lawler, J. K. Lenstra, and A. R. Kan, “Preemptive scheduling of uniform machines subject to release dates,” inProgress in combinatorial optimization, pp. 245–261, Elsevier, 1984
1984
-
[28]
Workload characteristics of a multi- cluster supercomputer,
H. Li, D. Groep, and L. Wolters, “Workload characteristics of a multi- cluster supercomputer,” inWorkshop on Job Scheduling Strategies for Parallel Processing, pp. 176–193, Springer, 2004
2004
-
[29]
Revolutionizing optical networks: The integration and im- pact of large language models,
S. Cruzes, “Revolutionizing optical networks: The integration and im- pact of large language models,”Optical Switching and Networking, p. 100812, 2025
2025
-
[30]
Deadline-aware online job scheduling for distributed training in heterogeneous clusters,
Y . Zhang, L. Luo, G. Sun, H. Yu, and B. Li, “Deadline-aware online job scheduling for distributed training in heterogeneous clusters,”IEEE Transactions on Cloud Computing, 2025
2025
-
[31]
{MLaaS}in the wild: Workload analysis and scheduling in{Large-Scale}heterogeneous{GPU}clusters,
Q. Weng, W. Xiao, Y . Yu, W. Wang, C. Wang, J. He, Y . Li, L. Zhang, W. Lin, and Y . Ding, “{MLaaS}in the wild: Workload analysis and scheduling in{Large-Scale}heterogeneous{GPU}clusters,” in19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), pp. 945–960, 2022
2022
-
[32]
Characterizing training performance and energy for foundation models and image classifiers on multi-instance gpus,
C. Espenshade, R. Peng, E. Hong, M. Calman, Y . Zhu, P. Parida, E. K. Lee, and M. A. Kim, “Characterizing training performance and energy for foundation models and image classifiers on multi-instance gpus,” in Proceedings of the 4th Workshop on Machine Learning and Systems, pp. 47–55, 2024
2024
-
[33]
MIG User Guide 2014; NVIDIA Multi-Instance GPU User Guide r580 documentation — docs.nvidia.com
“MIG User Guide 2014; NVIDIA Multi-Instance GPU User Guide r580 documentation — docs.nvidia.com.” https://docs.nvidia.com/datacenter/ tesla/mig-user-guide/index.html#application-considerations. Appendix Artifact Description (AD) VIII. OVERVIEW OFCONTRIBUTIONS ANDARTIFACTS A. Paper’s Main Contributions C1 SMART-MIG framework (integrating ML and OR): The pa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.