ARKD: Adaptive Reinforcement Learning-Guided Bidirectional KL Divergence Distillation for Text Generation
Pith reviewed 2026-06-30 05:57 UTC · model grok-4.3
The pith
A policy network learns to dynamically weight forward and reverse KL divergence during language model distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a reinforcement-learning-based adaptive framework, where a policy network dynamically assigns weights to forward and reverse KL divergence according to teacher-student distributional characteristics and guided by immediate reward signals, achieves dual alignment on principal and long-tail modes and yields consistent gains on Rouge-L and BertScore across benchmarks.
What carries the argument
A policy network that outputs dynamic weights for FKL and RKL based on observed distributional characteristics, trained via reinforcement learning with immediate reward signals.
If this is right
- The adaptive weighting produces consistent improvements on Rouge-L and BertScore metrics.
- Performance exceeds that of greedy heuristic weighting by 0.4-0.6 points.
- The method outperforms other baseline distillation approaches on multiple benchmarks.
- Dual alignment on both principal and long-tail modes occurs without manual tuning of the KL balance.
Where Pith is reading between the lines
- The same policy-learning idea could be applied to balance other complementary loss pairs in generative training.
- Successful deployment would reduce the engineering effort spent on choosing fixed KL weights for each new distillation task.
- Testing the policy on teacher-student pairs whose architectures differ more than those in the reported experiments would reveal the current limits of generalization.
Load-bearing premise
Immediate reward signals derived from teacher-student distributional characteristics suffice to train a policy network that remains stable and generalizes across teacher-student pairs and tasks.
What would settle it
Running the trained policy on a previously unseen teacher-student pair and finding that its chosen weights produce lower Rouge-L or BertScore than a simple equal-weight baseline would falsify the generalization claim.
Figures

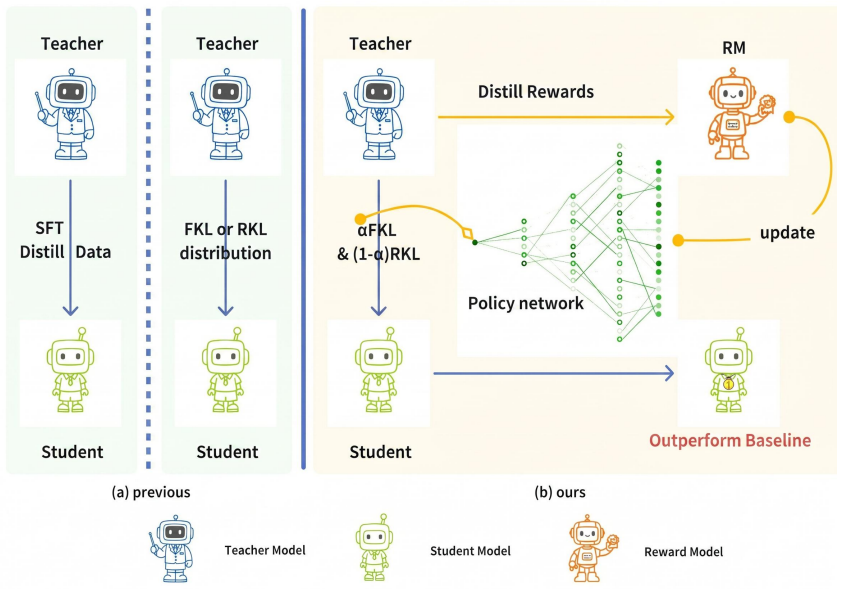




read the original abstract
Knowledge distillation (KD) is a key technique for compressing Large Language Models (LLMs), yet methods relying on a single KL objective often fail to balance primary distribution fitting with long-tail probability modeling, limiting both generation quality and generalization. To address this, we analyze the complementary roles of forward and reverse KL divergence (FKL/RKL) in distribution alignment from theoretical and empirical perspectives. We then propose a reinforcement-learning-based adaptive KL-weighted distillation framework, in which a policy network dynamically assigns weights to FKL and RKL based on teacher-student distributional characteristics, guided by immediate reward signals to achieve dual alignment on principal and long-tail modes. Extensive experiments demonstrate consistent improvements across Rouge-L and BertScore metrics, surpassing greedy heuristics by 0.4-0.6 points and outperforming other baseline methods on diverse benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ARKD, a reinforcement-learning-based adaptive KL-weighted distillation framework for compressing LLMs in text generation tasks. It analyzes the complementary roles of forward KL (FKL) and reverse KL (RKL) divergences for balancing principal distribution fitting and long-tail mode coverage, then introduces a policy network that dynamically assigns weights to FKL and RKL based on teacher-student distributional characteristics, trained via immediate reward signals. The authors claim this achieves dual alignment and report consistent metric gains on Rouge-L and BertScore, outperforming greedy heuristics by 0.4-0.6 points and other baselines across diverse benchmarks.
Significance. If the adaptive policy proves stable and generalizable without overfitting or requiring extensive per-task tuning, the work could meaningfully advance knowledge distillation for LLMs by replacing fixed or heuristic divergence weighting with a learned, reward-driven mechanism. The theoretical/empirical analysis of FKL vs. RKL complementarity provides a useful foundation, and the RL-guided approach offers a template for other adaptive alignment problems in generation.
major comments (2)
- [Methods / §3 (policy training)] Methods (policy and reward formulation): The central claim that immediate reward signals derived from teacher-student distributional characteristics suffice to train a stable, generalizable policy network is load-bearing, yet the reward function is described only at a high level in the abstract and methods overview. An explicit scalar reward definition (e.g., how mode-coverage statistics or divergence measures map to the reward) is required to assess whether the signal penalizes mode collapse or creates a fitting loop; without it, the adaptive weighting risks reducing to an unstable heuristic.
- [Experiments / §4] Experiments: The abstract asserts 'consistent improvements' and generalization across teacher-student pairs and tasks, but provides no details on statistical significance tests, ablation studies isolating the policy network, cross-task validation, or error analysis. These are necessary to substantiate that the RL policy does not overfit to training pairs and that dual alignment is achieved beyond what fixed-weight or greedy baselines deliver.
minor comments (1)
- [Abstract] Notation: 'Rouge-L' should be standardized to ROUGE-L throughout; similarly, ensure FKL/RKL abbreviations are defined on first use.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Methods (policy and reward formulation): The central claim that immediate reward signals derived from teacher-student distributional characteristics suffice to train a stable, generalizable policy network is load-bearing, yet the reward function is described only at a high level in the abstract and methods overview. An explicit scalar reward definition (e.g., how mode-coverage statistics or divergence measures map to the reward) is required to assess whether the signal penalizes mode collapse or creates a fitting loop; without it, the adaptive weighting risks reducing to an unstable heuristic.
Authors: We agree that an explicit scalar reward definition is necessary for reproducibility and to evaluate stability. The current manuscript presents the reward at a high level; in the revision we will add the precise mathematical formulation in §3, specifying how mode-coverage statistics and divergence measures are mapped to the immediate reward signal. revision: yes
-
Referee: Experiments: The abstract asserts 'consistent improvements' and generalization across teacher-student pairs and tasks, but provides no details on statistical significance tests, ablation studies isolating the policy network, cross-task validation, or error analysis. These are necessary to substantiate that the RL policy does not overfit to training pairs and that dual alignment is achieved beyond what fixed-weight or greedy baselines deliver.
Authors: We acknowledge the need for these experimental details. The revision will include statistical significance tests (p-values) for the reported 0.4-0.6 point gains, ablation studies that isolate the learned policy network from fixed-weight and greedy baselines, cross-task validation results, and error analysis on failure modes. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract describes an RL policy that learns weights for FKL/RKL from distributional characteristics and rewards, but provides no equations or self-citations that reduce the claimed dual-alignment result to a fitted parameter or tautological input by construction. No load-bearing self-citation, uniqueness theorem, or ansatz smuggling is present in the given text. The framework is a standard adaptive RL setup whose outputs are not definitionally equivalent to its inputs; external validation via Rouge-L/BertScore improvements is claimed independently of the policy fit itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Transactions of the Association for Computational Linguistics , volume=
A survey on model compression for large language models , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[3]
IEEE Transactions on Artificial Intelligence , year=
A survey on symbolic knowledge distillation of large language models , author=. IEEE Transactions on Artificial Intelligence , year=
-
[4]
ACM Transactions on Intelligent Systems and Technology , year=
Survey on knowledge distillation for large language models: methods, evaluation, and application , author=. ACM Transactions on Intelligent Systems and Technology , year=
-
[6]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Dual-space knowledge distillation for large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
RLKD: Distilling LLMs’ Reasoning via Reinforcement Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[9]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Out-of-distribution generalization in natural language processing: Past, present, and future , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[10]
MiniLLM: Knowledge Distillation of Large Language Models , volume =
Gu, Yuxian and Dong, Li and Wei, Furu and Huang, Minlie , booktitle =. MiniLLM: Knowledge Distillation of Large Language Models , volume =
-
[11]
The Twelfth International Conference on Learning Representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The Twelfth International Conference on Learning Representations , year=
-
[13]
Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
Sequence-level knowledge distillation , author=. Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
2016
-
[14]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Promptkd: Distilling student-friendly knowledge for generative language models via prompt tuning , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[15]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track) , pages=
Gkd: A general knowledge distillation framework for large-scale pre-trained language model , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track) , pages=
-
[16]
International journal of computer vision , volume=
Knowledge distillation: A survey , author=. International journal of computer vision , volume=. 2021 , publisher=
2021
-
[17]
The Twelfth International Conference on Learning Representations , year=
RLCD: Reinforcement learning from contrastive distillation for LM alignment , author=. The Twelfth International Conference on Learning Representations , year=
-
[24]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Unnatural instructions: Tuning language models with (almost) no human labor , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
See https://vicuna.lmsys.org (accessed 14 April 2023) , volume=
Vicuna: An open-source chatbot impressing gpt-4 with 90\ author=. See https://vicuna.lmsys.org (accessed 14 April 2023) , volume=
2023
-
[26]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[27]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Rethinking kullback-leibler divergence in knowledge distillation for large language models , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[28]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
F-divergence minimization for sequence-level knowledge distillation , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[29]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Revisiting knowledge distillation for autoregressive language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
Artificial Intelligence Review , volume=
Knowledge distillation and dataset distillation of large language models: Emerging trends, challenges, and future directions , author=. Artificial Intelligence Review , volume=. 2026 , publisher=
2026
-
[32]
ACM Transactions on Software Engineering and Methodology , volume=
A survey on large language models for code generation , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2026 , publisher=
2026
-
[34]
Kamal Acharya, Alvaro Velasquez, and Houbing Herbert Song. 2024. A survey on symbolic knowledge distillation of large language models. IEEE Transactions on Artificial Intelligence
2024
-
[35]
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. 2024. On-policy distillation of language models: Learning from self-generated mistakes. In The Twelfth International Conference on Learning Representations
2024
-
[36]
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, and 1 others. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90\ quality. See https://vicuna.lmsys.org (accessed 14 April 2023), 2(3):6
2023
-
[37]
Luyang Fang, Xiaowei Yu, Jiazhang Cai, Yongkai Chen, Shushan Wu, Zhengliang Liu, Zhenyuan Yang, Haoran Lu, Xilin Gong, Yufang Liu, and 1 others. 2026. Knowledge distillation and dataset distillation of large language models: Emerging trends, challenges, and future directions. Artificial Intelligence Review, 59(1):17
2026
-
[38]
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. 2021. Knowledge distillation: A survey. International journal of computer vision, 129(6):1789--1819
2021
-
[39]
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2024. Minillm: Knowledge distillation of large language models. In International Conference on Learning Representations, volume 2024, pages 32694--32717
2024
-
[40]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[41]
Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. 2023. Unnatural instructions: Tuning language models with (almost) no human labor. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14409--14428
2023
-
[42]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2026. A survey on large language models for code generation. ACM Transactions on Software Engineering and Methodology, 35(2):1--72
2026
-
[43]
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. 2026. Entropy-aware on-policy distillation of language models. arXiv preprint arXiv:2603.07079
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Gyeongman Kim, Doohyuk Jang, and Eunho Yang. 2024. Promptkd: Distilling student-friendly knowledge for generative language models via prompt tuning. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 6266--6282
2024
-
[45]
Yoon Kim and Alexander M Rush. 2016. Sequence-level knowledge distillation. In Proceedings of the 2016 conference on empirical methods in natural language processing, pages 1317--1327
2016
- [46]
-
[47]
Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Ren Lu, Thomas Mesnard, Johan Ferret, Colton Bishop, Ethan Hall, Victor Carbune, and Abhinav Rastogi. 2023. Rlaif: Scaling reinforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [48]
-
[49]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74--81
2004
- [50]
-
[51]
Shicheng Tan, Weng Lam Tam, Yuanchun Wang, Wenwen Gong, Shu Zhao, Peng Zhang, and Jie Tang. 2023. Gkd: A general knowledge distillation framework for large-scale pre-trained language model. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track), pages 134--148
2023
-
[52]
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022 a . Self-instruct: Aligning language models with self-generated instructions. arXiv preprint arXiv:2212.10560
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, and 1 others. 2022 b . Benchmarking generalization via in-context instructions on 1,600+ language tasks. arXiv preprint arXiv:2204.07705, 2(2)
-
[54]
Yuqiao Wen, Zichao Li, Wenyu Du, and Lili Mou. 2023. F-divergence minimization for sequence-level knowledge distillation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10817--10834
2023
-
[55]
Taiqiang Wu, Chaofan Tao, Jiahao Wang, Runming Yang, Zhe Zhao, and Ngai Wong. 2025. Rethinking kullback-leibler divergence in knowledge distillation for large language models. In Proceedings of the 31st International Conference on Computational Linguistics, pages 5737--5755
2025
-
[56]
Shicheng Xu, Liang Pang, Yunchang Zhu, Jia Gu, Zihao Wei, Jingcheng Deng, Feiyang Pan, Huawei Shen, and Xueqi Cheng. 2026. Rlkd: Distilling llms’ reasoning via reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 34151--34159
2026
-
[57]
Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, and Tianyi Zhou. 2024. A survey on knowledge distillation of large language models. arXiv preprint arXiv:2402.13116
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Chuanpeng Yang, Yao Zhu, Wang Lu, Yidong Wang, Qian Chen, Chenlong Gao, Bingjie Yan, and Yiqiang Chen. 2024 a . Survey on knowledge distillation for large language models: methods, evaluation, and application. ACM Transactions on Intelligent Systems and Technology
2024
-
[59]
Kevin Yang, Dan Klein, Asli Celikyilmaz, Nanyun Peng, and Yuandong Tian. 2024 b . Rlcd: Reinforcement learning from contrastive distillation for lm alignment. In The Twelfth International Conference on Learning Representations
2024
-
[60]
Linyi Yang, Yaoxian Song, Xuan Ren, Chenyang Lyu, Yidong Wang, Jingming Zhuo, Lingqiao Liu, Jindong Wang, Jennifer Foster, and Yue Zhang. 2023. Out-of-distribution generalization in natural language processing: Past, present, and future. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4533--4559
2023
-
[61]
Chaoyun Zhang, Shilin He, Jiaxu Qian, Bowen Li, Liqun Li, Si Qin, Yu Kang, Minghua Ma, Guyue Liu, Qingwei Lin, and 1 others. 2024 a . Large language model-brained gui agents: A survey. arXiv preprint arXiv:2411.18279
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Songming Zhang, Xue Zhang, Zengkui Sun, Yufeng Chen, and Jinan Xu. 2024 b . Dual-space knowledge distillation for large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18164--18181
2024
-
[63]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[64]
Zhaoyang Zhang, Shuli Jiang, Yantao Shen, Yuting Zhang, Dhananjay Ram, Shuo Yang, Zhuowen Tu, Wei Xia, and Stefano Soatto. 2026. Reinforcement-aware knowledge distillation for llm reasoning. arXiv preprint arXiv:2602.22495
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Qihuang Zhong, Liang Ding, Li Shen, Juhua Liu, Bo Du, and Dacheng Tao. 2024. Revisiting knowledge distillation for autoregressive language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10900--10913
2024
-
[66]
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. 2024. A survey on model compression for large language models. Transactions of the Association for Computational Linguistics, 12:1556--1577
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.