Towards Physical Intuitions for Alignment Dynamics: A Case Study With Randomness Crystallization
Pith reviewed 2026-06-30 06:37 UTC · model grok-4.3
The pith
Alignment for random generation tasks collapses model behavior onto a single seed distribution from pretraining during supervised fine-tuning, with reinforcement learning only redistributing probabilities within that set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
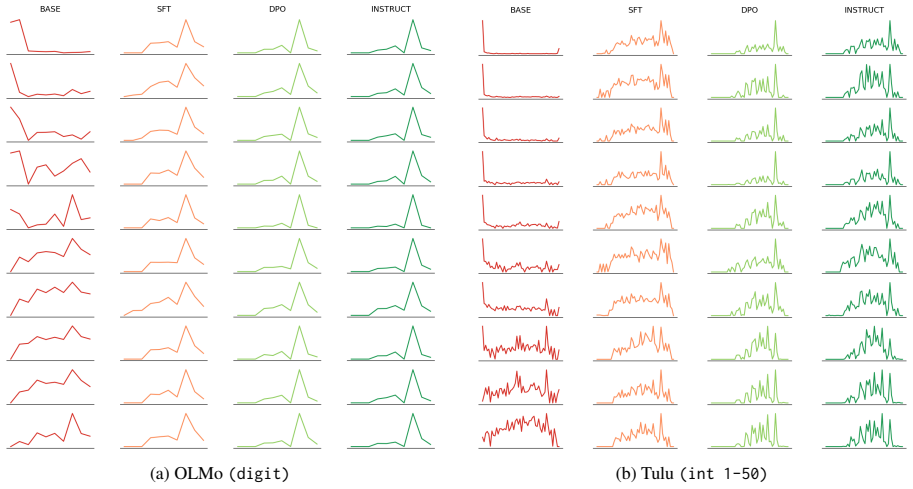
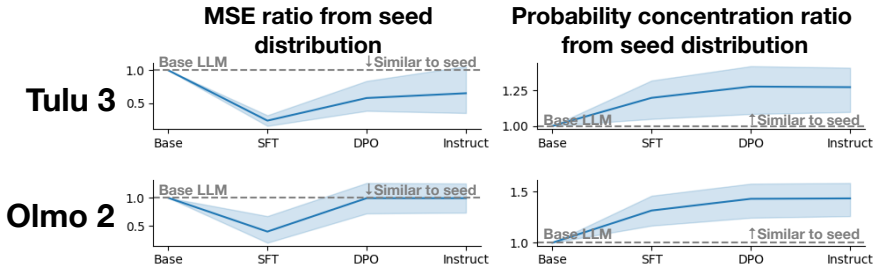
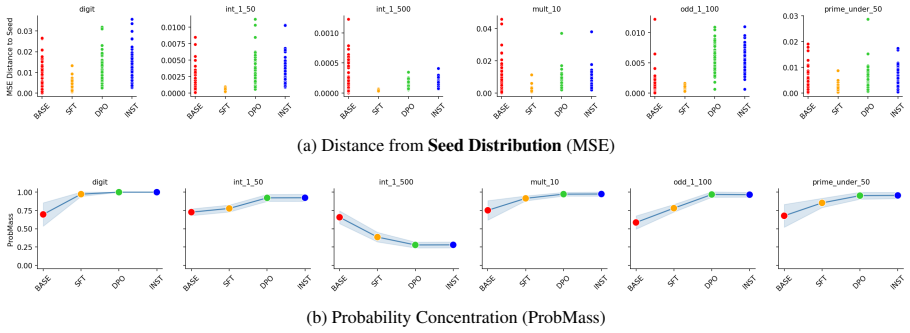
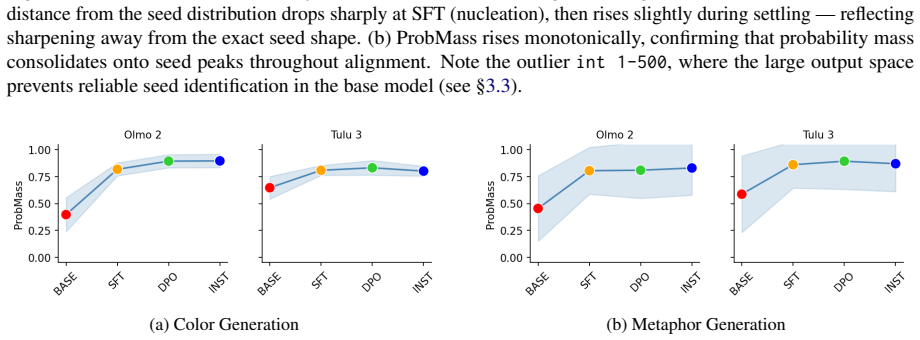
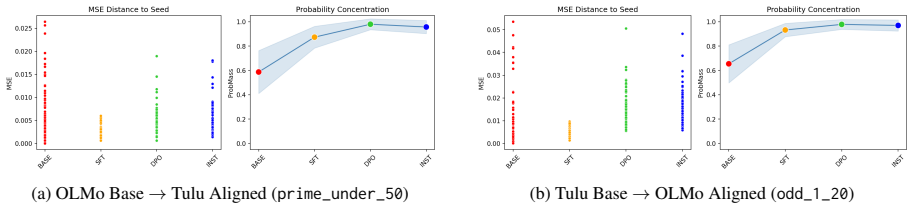
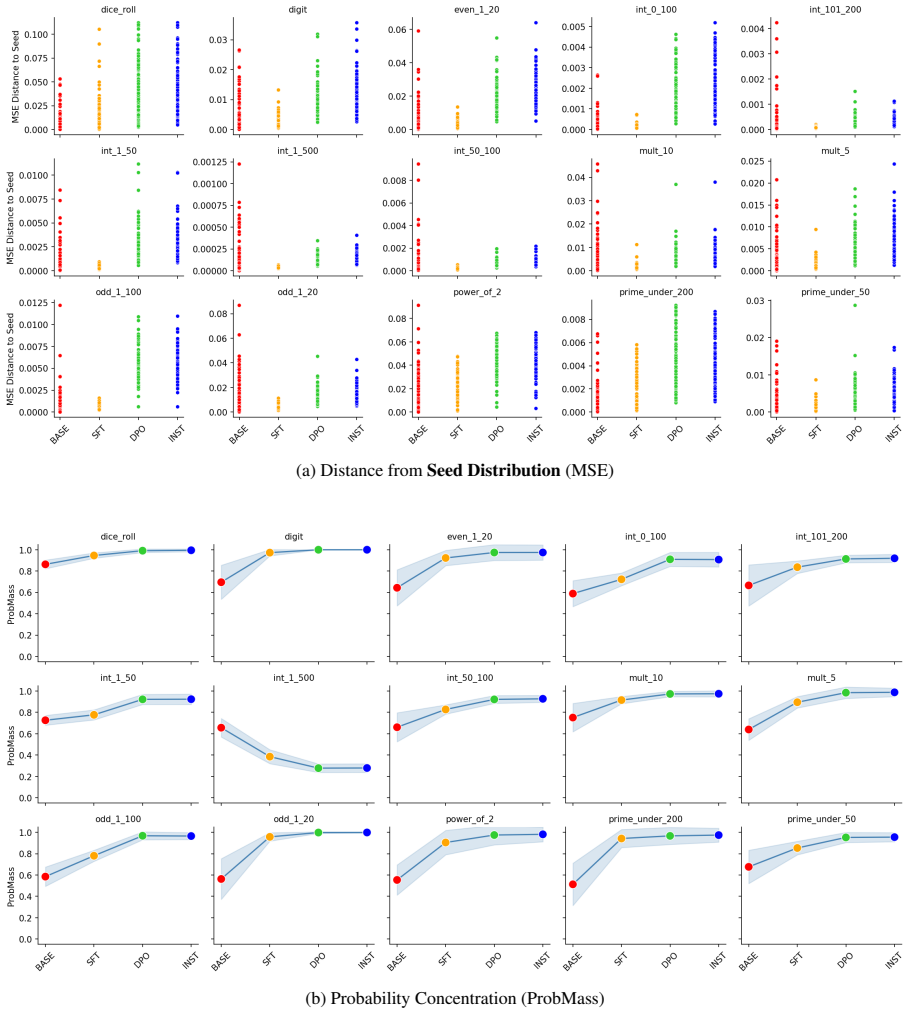
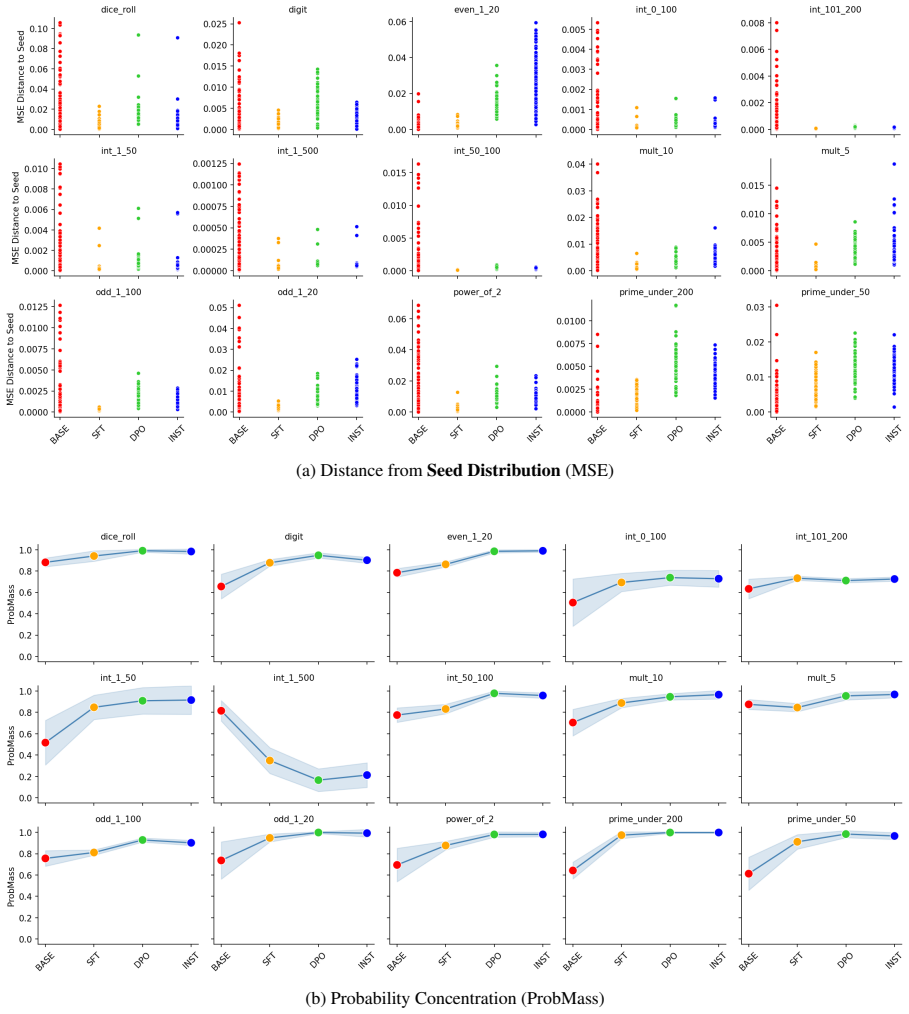
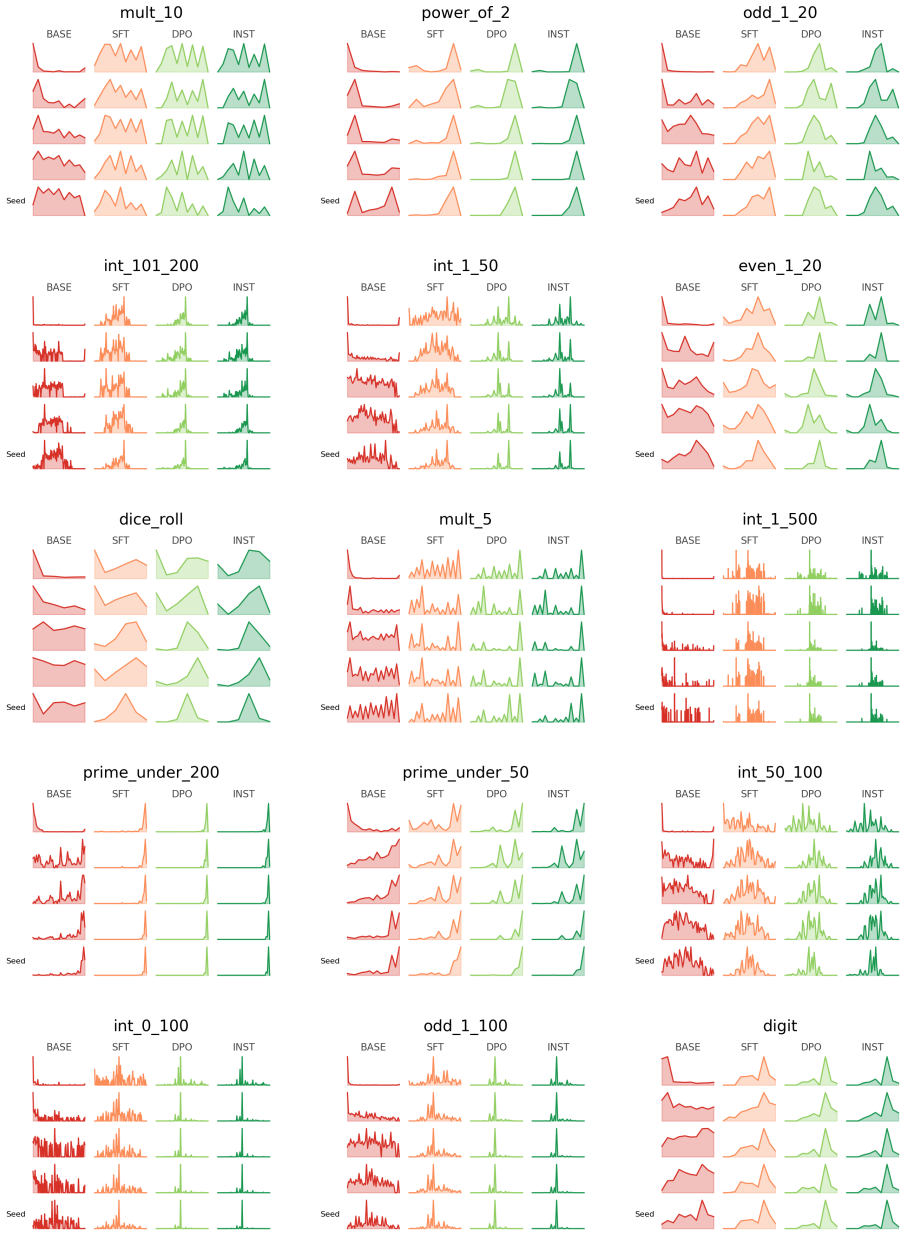
For tasks like random number generation, alignment breaks into three phases modeled on material crystallization: the high entropy liquid phase in the pretrained model, with many distinct sampling distributions promptable from the model; the nucleation phase caused by supervised finetuning, in which behavior collapses onto a single seed distribution present in the pretrained LLM; and the settling phase in which reinforcement learning techniques redistribute probability of the collapsed distribution, but largely keep it concentrated on the same options as the seed distribution.
What carries the argument
The three-phase crystallization model, which maps LLM sampling distributions to a liquid phase, a nucleation collapse during supervised fine-tuning, and a settling redistribution under reinforcement learning.
If this is right
- The set of behaviors available after complete alignment is largely fixed by the seed distribution chosen during supervised fine-tuning.
- Entropy and distribution-similarity metrics can track when a model crosses from one phase to the next during post-training.
- Reinforcement learning mainly tunes probabilities inside the nucleated set and does not create new options outside it for these tasks.
- The source of final aligned structure lies in pretraining content and the choice of fine-tuning seed rather than in later optimization steps.
Where Pith is reading between the lines
- If the phases hold, alignment methods might improve by deliberately selecting or broadening the seed distribution during supervised fine-tuning instead of relying on later reinforcement learning adjustments.
- The crystallization view could extend to other tasks where models select from a large pretrained repertoire, suggesting alignment is more selection than invention.
- A direct test would involve forcing different seed distributions through modified supervised fine-tuning and checking whether reinforcement learning can still overcome the resulting concentration.
Load-bearing premise
That the sampling distributions of an LLM during random generation tasks can be meaningfully mapped onto thermodynamic phases of crystallization in a way that reveals causal structure about alignment dynamics rather than serving as a loose metaphor.
What would settle it
If reinforcement learning after supervised fine-tuning is observed to substantially expand or replace the set of options generated by the model, rather than keeping probability concentrated on the seed distribution's options, the three-phase description would not hold.
Figures


read the original abstract
The alignment of language models is typically studied through the lens of capability benchmarks, but the dynamics of how models change during post-training remain poorly understood. We argue that the physical sciences, and thermodynamic phase-transition theory in particular, offer a principled and underexplored vocabulary for reasoning about these dynamics. As a case study, we instantiate this position through the lens of material Crystallization, which is a well-studied thermodynamic phase transition. For tasks like random number generation, this breaks into 3 phases: (1) the high entropy liquid phase in the pretrained model, with many distinct sampling distributions promptable from the model; (2) the nucleation phase caused by supervised finetuning, in which behavior collapses onto a single seed distribution present in the pretrained LLM; and (3) a settling phase in which reinforcement learning techniques redistribute probability of the collapsed distribution, but largely keep it concentrated on the same options as the seed distribution. We propose intuitive metrics to verify the transitions between these phases, and validate the idea across a range of random tasks. Crystallization is one instance of a broader class of physical frameworks we believe alignment research should import to answer questions about where alignment-induced structure comes from, why it converges where it does, and what it fundamentally cannot change.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that thermodynamic phase-transition theory, instantiated via a crystallization analogy, offers a principled vocabulary for alignment dynamics in language models. Using random number generation tasks as a case study, it posits three phases: (1) a high-entropy liquid phase in the pretrained model with many distinct promptable sampling distributions, (2) a nucleation phase induced by supervised finetuning that collapses behavior onto a single seed distribution present in the pretrained model, and (3) a settling phase under reinforcement learning that redistributes probability while preserving concentration on the same options. Intuitive metrics are proposed to verify the transitions, with validation claimed across a range of random tasks. The work positions crystallization as one example of physical frameworks that alignment research should import to address questions about the origins, convergence, and limits of alignment-induced structure.
Significance. If the proposed metrics demonstrate thermodynamic-like signatures such as discontinuous order-parameter changes or critical scaling at the claimed transition points rather than monotonic distributional shifts, the framework could supply new causal structure for understanding where alignment-induced behavior originates and what it cannot alter. The manuscript's explicit attempt to import concepts from the physical sciences is a constructive direction if substantiated with reproducible evidence.
major comments (2)
- [Abstract] Abstract: The phases are defined directly in terms of observed changes during SFT (nucleation/collapse) and RL (settling/redistribution), without reference to independent order parameters or external benchmarks; this makes the mapping vulnerable to circularity, where the description re-labels training stages rather than deriving an independent physical analogy.
- [Abstract] Abstract: The claim that intuitive metrics are proposed and validated across random tasks is not accompanied by any description of the metrics, experimental controls, error bars, or quantitative results, rendering it impossible to assess whether the framework captures non-analytic phase-transition behavior or merely tracks gradual entropy reduction and mode concentration.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the specific random tasks used and the form of the proposed metrics to allow readers to evaluate the validation claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. The comments highlight important issues of clarity in the abstract regarding phase definitions and the presentation of supporting evidence. We address each point below and indicate where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The phases are defined directly in terms of observed changes during SFT (nucleation/collapse) and RL (settling/redistribution), without reference to independent order parameters or external benchmarks; this makes the mapping vulnerable to circularity, where the description re-labels training stages rather than deriving an independent physical analogy.
Authors: We agree that the abstract's phrasing ties the phase labels closely to the SFT and RL stages, which risks appearing circular. The crystallization analogy is meant to supply an independent conceptual structure (drawing on thermodynamic concepts of nucleation from a seed and subsequent settling), with the training stages serving only as the empirical mechanisms in this case study. The proposed metrics—entropy of the output distribution, concentration on a small set of modes, and the persistence of other promptable distributions—are intended as measurable order parameters that can be tracked independently of training procedure. We will revise the abstract to foreground these metrics and their independence from the training stages, making the non-circular nature of the analogy explicit. revision: yes
-
Referee: [Abstract] Abstract: The claim that intuitive metrics are proposed and validated across random tasks is not accompanied by any description of the metrics, experimental controls, error bars, or quantitative results, rendering it impossible to assess whether the framework captures non-analytic phase-transition behavior or merely tracks gradual entropy reduction and mode concentration.
Authors: The abstract is intentionally brief and therefore omits the concrete metric definitions, controls, and results that appear in the body of the manuscript. We acknowledge that this omission makes it difficult for a reader to evaluate the strength of the evidence from the abstract alone. In revision we will expand the abstract to include a concise description of the metrics (entropy, mode concentration, and cross-prompt distribution overlap), note the use of multiple random-generation tasks as controls, and summarize the observed transitions with reference to quantitative patterns, while preserving length constraints. revision: yes
Circularity Check
Phases explicitly defined by correspondence to standard training stages (pretrain/SFT/RL) rather than independent thermodynamic signatures
specific steps
-
renaming known result
[Abstract]
"For tasks like random number generation, this breaks into 3 phases: (1) the high entropy liquid phase in the pretrained model, with many distinct sampling distributions promptable from the model; (2) the nucleation phase caused by supervised finetuning, in which behavior collapses onto a single seed distribution present in the pretrained LLM; and (3) a settling phase in which reinforcement learning techniques redistribute probability of the collapsed distribution, but largely keep it concentrated on the same options as the seed distribution."
The phases are introduced by direct identification with the training procedures (pretraining, supervised finetuning, reinforcement learning) and with the distributional changes those procedures are already known to produce. The 'crystallization' framework therefore organizes existing observations under new labels without an independent derivation that would distinguish it from a descriptive metaphor.
full rationale
The paper's central case study defines its three crystallization phases directly in terms of the conventional post-training pipeline and the distributional effects already known to occur at each stage. No equations, order parameters, or critical-phenomena tests are shown in the provided text that would derive the phase structure from physical first principles; the mapping therefore functions as a relabeling of observed SFT-induced mode collapse and RL redistribution. This matches the renaming_known_result pattern and produces partial circularity for the claimed 'principled vocabulary,' though the proposal of intuitive metrics could in principle supply independent content if those metrics were shown to detect non-analytic behavior.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Thermodynamic phase-transition theory offers a principled vocabulary for reasoning about alignment dynamics in language models
invented entities (1)
-
Crystallization phases (liquid, nucleation, settling) in alignment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
arXiv preprint arXiv:2505.00047 , year=
Base models beat aligned models at randomness and creativity , author=. arXiv preprint arXiv:2505.00047 , year=
-
[3]
2 OLMo 2 Furious , author=. arXiv preprint arXiv:2501.00656 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Artificial hivemind: The open-ended homogeneity of language models (and beyond) , author=. arXiv preprint arXiv:2510.22954 , year=
-
[6]
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting , author=. arXiv preprint arXiv:2310.11324 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2506.17871 , year=
LLM Probability Concentration: How Alignment Shrinks the Generative Horizon , author=. arXiv preprint arXiv:2506.17871 , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Lima: Less is more for alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
2025 , month = dec, howpublished =
Hallgren, Jonas , title =. 2025 , month = dec, howpublished =
2025
-
[10]
The unlocking spell on base llms: Rethinking alignment via in-context learning , author=. arXiv preprint arXiv:2312.01552 , year=
-
[11]
ICLR 2024 Workshop on Mathematical and Empirical Understanding of Foundation Models , volume=
Attributing mode collapse in the fine-tuning of large language models , author=. ICLR 2024 Workshop on Mathematical and Empirical Understanding of Foundation Models , volume=
2024
-
[12]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
1948
-
[13]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
Language models as agent models , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
2022
-
[14]
The Curious Case of Neural Text Degeneration
The curious case of neural text degeneration , author=. arXiv preprint arXiv:1904.09751 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[15]
Advances in Neural Information Processing Systems , volume=
Towards understanding grokking: An effective theory of representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[17]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Predicting structured data , volume=
A tutorial on energy-based learning , author=. Predicting structured data , volume=
-
[19]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[20]
Chemical reviews , volume=
Crystal nucleation in liquids: Open questions and future challenges in molecular dynamics simulations , author=. Chemical reviews , volume=. 2016 , publisher=
2016
-
[21]
Nature , volume=
Supercooled liquids and the glass transition , author=. Nature , volume=. 2001 , publisher=
2001
-
[22]
Journal of Physics and Chemistry of Solids , year=
The kinetics of precipitation from supersaturated solid solutions , author=. Journal of Physics and Chemistry of Solids , year=
-
[23]
Crystal Growth & Design , volume=
Role of additives in crystal nucleation from solutions: a review , author=. Crystal Growth & Design , volume=. 2021 , publisher=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.