HBM Is Not All You Need: Efficient Disaggregated LLM Serving across Memory-heterogeneous Accelerators
Pith reviewed 2026-06-30 04:23 UTC · model grok-4.3
The pith
Serving LLMs on mixed GDDR and HBM hardware with phase-wise quantization and deferred dequantization raises goodput by up to 3.2 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
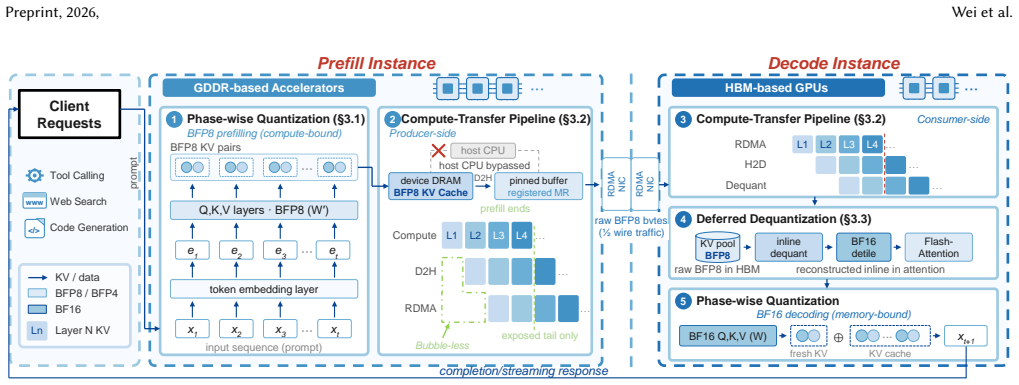
HMA-Serve pairs GDDR-based accelerators for prefill with HBM-based GPUs for decode through phase-wise quantization that keeps decode in BF16, a compute-transfer pipeline that overlaps KV cache transfers, and deferred dequantization that reduces bandwidth by shipping raw quantized bytes.
What carries the argument
HMA-Serve's phase-wise quantization, compute-transfer pipeline, and deferred dequantization that handle cross-vendor KV cache and software differences in memory-heterogeneous disaggregation.
If this is right
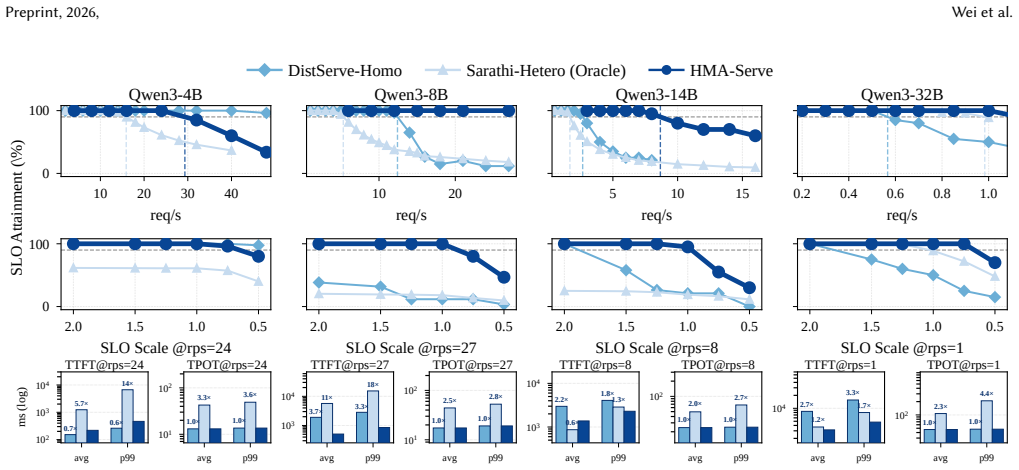
- Up to 3.2× higher goodput than state-of-the-art memory-homogeneous methods
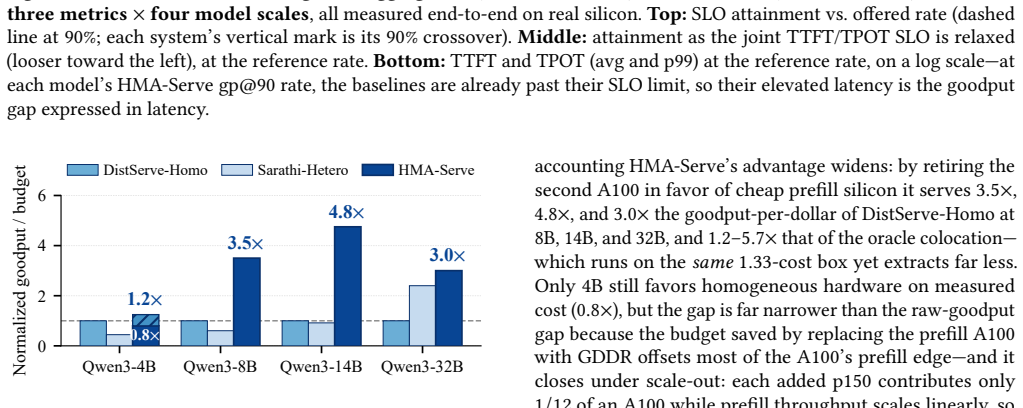
- 4.8× higher goodput-per-dollar
- No measurable loss on generation-quality benchmarks
- Effective across four Qwen3 models from 4B to 32B and three production traces
Where Pith is reading between the lines
- Hardware providers may need to improve cross-vendor compatibility for KV caches to make such mixing routine.
- Similar disaggregation could extend to other accelerator types beyond GDDR and HBM.
- Datacenter operators could reduce capital costs by matching hardware more precisely to phase requirements.
Load-bearing premise
The latency and complexity added by cross-vendor KV cache format conversion, network transfers, and deferred dequantization stay low enough that overall goodput and quality stay superior.
What would settle it
A test where the heterogeneous system with the three techniques shows equal or lower goodput than homogeneous baselines or reduced generation quality on the same models and traces.
Figures

read the original abstract
LLM inference comprises a compute-bound prefill phase and a memory-bound decode phase, and recent systems disaggregate them onto separate hardware. Yet today's datacenter GPUs rely on costly HBM whose bandwidth sits almost entirely idle during prefill. LLM serving across memory-heterogeneous accelerators (MemHA) pairs GDDR-based accelerators for prefill with HBM-based GPUs for decode, promising lower cost without sacrificing performance. Pushed to its most economical form, MemHA serving is inherently cross-vendor, since the best-suited chip for each phase may come from a different vendor. This breaks two assumptions that single-vendor disaggregation takes for granted -- a KV format both ends consume natively, and a shared software stack. We present \textbf{HMA-Serve}, a MemHA-centric disaggregated serving system pairing GDDR-based accelerators for prefill with HBM-based GPUs for decode efficiently. HMA-Serve achieves this through (1) phase-wise quantization, applying vendor-native low precision for high-throughput prefill while keeping decode in high-precision BF16, (2) a compute-transfer pipeline that overlaps each layer's KV cache transfer with later-layer prefill to reduce time-to-first-token (TTFT), and (3) deferred dequantization, shipping raw quantized bytes and reconstructing them lazily on the decode GPU to reduce network bandwidth and HBM usage. Across four Qwen3 models (4B--32B) and three production traces, HMA-Serve delivers up to $3.2\times$ higher goodput than state-of-the-art memory-homogeneous methods and $4.8\times$ higher goodput-per-dollar, with no measurable loss on generation-quality benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents HMA-Serve, a disaggregated LLM serving system that pairs GDDR-based accelerators for the compute-bound prefill phase with HBM-based GPUs for the memory-bound decode phase in a cross-vendor setting. It introduces three techniques—phase-wise quantization (vendor-native low precision for prefill, BF16 for decode), a compute-transfer pipeline overlapping KV cache transfers with later-layer prefill, and deferred dequantization (shipping quantized bytes for lazy reconstruction)—to handle KV cache format and software stack mismatches. Across four Qwen3 models (4B–32B) and three production traces, it reports up to 3.2× higher goodput and 4.8× higher goodput-per-dollar versus state-of-the-art memory-homogeneous methods, with no measurable loss on generation-quality benchmarks.
Significance. If the reported gains hold after accounting for cross-vendor overheads, the result would be significant for LLM serving systems by showing that costly HBM bandwidth is largely idle during prefill and that cheaper GDDR accelerators can be used effectively for that phase. The empirical evaluation across multiple model sizes and real traces, combined with explicit handling of cross-vendor KV cache issues, provides practical evidence for heterogeneous accelerator deployments. The work explicitly credits the three techniques for preserving TTFT and quality while improving cost-efficiency.
major comments (1)
- [Evaluation / Results] The central claim that the three techniques keep cross-vendor overheads (KV cache format conversion, network transfers, deferred dequantization) low enough to deliver the 3.2× goodput and 4.8× goodput-per-dollar gains is load-bearing, yet the manuscript provides no quantitative breakdown (e.g., per-layer transfer time, dequantization compute cost, or bandwidth savings versus homogeneous baselines) in the evaluation. Without this, it is impossible to verify that the added latency and bandwidth costs do not scale with model size or trace characteristics and erode the net benefit.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from an explicit definition of 'goodput' (e.g., tokens per second under latency SLOs) and 'goodput-per-dollar' to allow direct comparison with prior disaggregation work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation. We address the major comment below and will incorporate the requested breakdown in the revised manuscript.
read point-by-point responses
-
Referee: The central claim that the three techniques keep cross-vendor overheads (KV cache format conversion, network transfers, deferred dequantization) low enough to deliver the 3.2× goodput and 4.8× goodput-per-dollar gains is load-bearing, yet the manuscript provides no quantitative breakdown (e.g., per-layer transfer time, dequantization compute cost, or bandwidth savings versus homogeneous baselines) in the evaluation. Without this, it is impossible to verify that the added latency and bandwidth costs do not scale with model size or trace characteristics and erode the net benefit.
Authors: We agree that an explicit quantitative breakdown of the overheads from phase-wise quantization, the compute-transfer pipeline, and deferred dequantization is needed to substantiate the net gains. In the revised manuscript we will add a dedicated subsection (and associated figures/tables) that reports per-layer KV cache transfer latency, dequantization compute cost on the decode GPU, and effective bandwidth savings relative to the memory-homogeneous baselines. These measurements will be shown for all four Qwen3 model sizes and across the three production traces to demonstrate that the overheads remain small and do not scale in a way that erodes the reported 3.2× goodput and 4.8× goodput-per-dollar improvements. revision: yes
Circularity Check
No circularity; claims rest on empirical measurements
full rationale
The paper describes an engineering system (HMA-Serve) with three concrete techniques and evaluates it through experiments on four models and three traces, reporting measured goodput and goodput-per-dollar gains. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims are directly tied to external benchmarks (production traces, generation-quality metrics) rather than reducing to inputs by construction, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dennis Abts, Jonathan Ross, Jonathan Sparling, Mark Wong-VanHaren, Max Baker, Tom Hawkins, Andrew Bell, John Thompson, Temes- ghen Kahsai, Garrin Kimmell, Jennifer Hwang, Rebekah Leslie-Hurd, Michael Bye, E. R. Creswick, Matthew Boyd, Mahitha Venigalla, Evan Laforge, Jon Purdy, Purushotham Kamath, Dinesh Maheshwari, Michael Beidler, Geert Rosseel, Omar Ah...
-
[2]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM In- ference with Sarathi-Serve. In18th USENIX Symposium on Operat- ing Systems Design and Implementation (OSDI 24)(Santa Clara, CA, USA). USENIX Association, USA, 117–134.htt...
2024
- [3]
-
[4]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Atten- tion with IO-Awareness. InAdvances in Neural Information Process- ing Systems 35 (NeurIPS 2022)(New Orleans, LA, USA). Curran As- sociates, Inc.http://papers.nips.cc/paper_files/paper/2022/hash/ 67d57c32e20fd0a7a302cb81d36e40d...
2022
-
[5]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Sto- ica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23). As- sociation for Computing Machinery, New ...
-
[6]
Haiquan Lu, Zigeng Chen, Gongfan Fang, Xinyin Ma, and Xinchao Wang. 2026. Mix-Quant: Quantized Prefilling, Precise Decoding for Agentic LLMs.arXiv preprint arXiv:2605.20315(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA) 7 Preprint, 2026, Wei et al. (Buenos Aires, Argentina). IEEE, 118–132. doi:10.1109/ISCA59...
-
[8]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading More Storage for Less Computation — A KVCache-centric Ar- chitecture for Serving LLM Chatbot. In23rd USENIX Conference on File and Storage Technologies (FAST 25)(Santa Clara, CA, USA). USENIX As- sociation, USA, 155–170....
2025
-
[9]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22)(Carlsbad, CA, USA). USENIX Association, USA, 521–538.https://www.usenix. org/conference/osdi22/presentation/yu
2022
-
[10]
Hengrui Zhang, Pratyush Patel, August Ning, and David Wentzlaff
- [11]
-
[12]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: disaggregating prefill and decoding for goodput-optimized large language model serv- ing. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation(Santa Clara, CA, USA)(OSDI’24). USENIX Association, USA, Art...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.