GeoEdit: Geometry-Aware Object Editing via Dual-Branch Denoising
Pith reviewed 2026-06-30 06:46 UTC · model grok-4.3
The pith
GeoEdit decouples scenes in 3D then applies dual-branch denoising to enforce rigid object geometry while freeing background synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
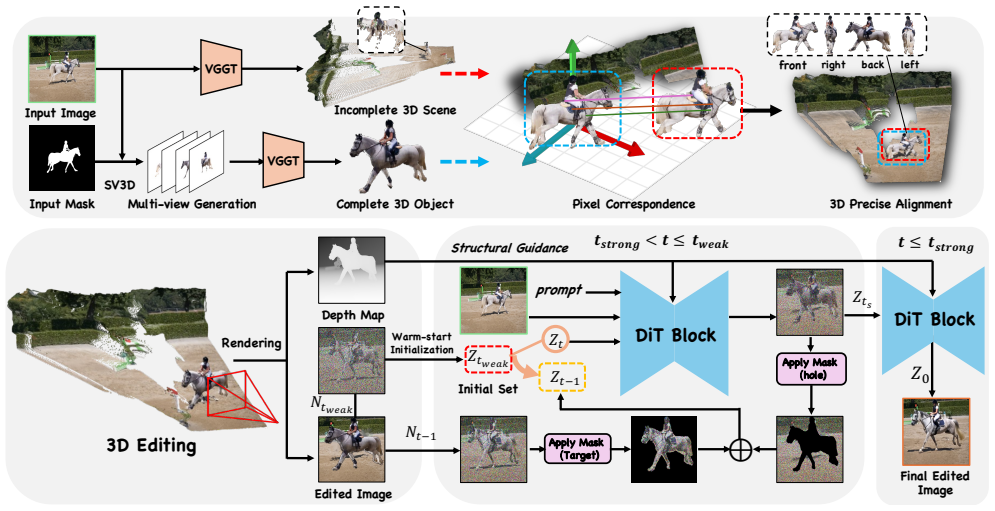
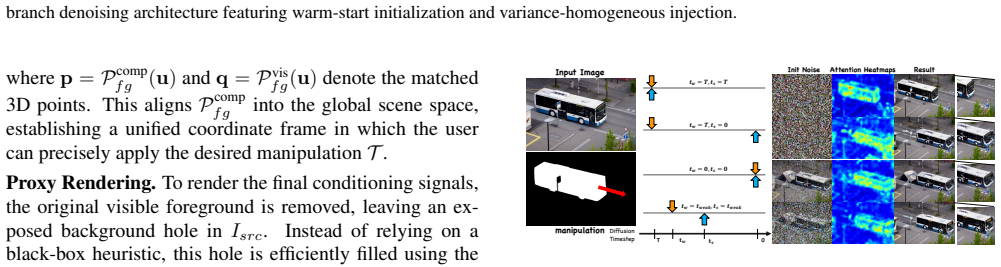
We present GeoEdit, a training-free Lift-Manipulate-Render-Denoise pipeline that decouples scene and object in 3D, aligns them through point correspondence, and renders a geometry-aligned proxy with a structural depth map. A Dual-Branch Denoising stage then refines this proxy: a video diffusion backbone preserves object identity, while 3D constraints are injected into the foreground within a narrow denoising window at matching noise variance (variance-homogeneous injection). The background denoises freely. Because the injected signal matches the native latent statistics, self-attention stays undisturbed.
What carries the argument
Dual-Branch Denoising with variance-homogeneous injection, which applies 3D constraints only to the foreground branch inside a narrow denoising window while the background branch remains free.
If this is right
- Object edits obey rigid 3D geometry without training.
- Background regions synthesize plausible content without leakage from the object.
- Identity of the manipulated object is preserved across the edit.
- The method handles translation, rotation, and camera movement with pose-aware metrics.
- No additional model training is required beyond the base video diffusion backbone.
Where Pith is reading between the lines
- The variance-homogeneous injection technique could be tested on other asymmetric editing tasks such as adding or removing objects.
- GeoEditBench may become a reference set for measuring geometric fidelity in future diffusion editors.
- Extending the narrow denoising window to multiple scales might further reduce residual artifacts in complex scenes.
- The lift-to-3D step could be replaced by other depth estimators to check robustness of the overall pipeline.
Load-bearing premise
Accurate 3D decoupling via point correspondence and structural depth map rendering can be performed without introducing artifacts that later denoising cannot correct, and the injected signal at matching noise variance leaves self-attention undisturbed.
What would settle it
Running the pipeline on a test image where the rendered proxy has visible misalignment from point correspondence errors, then checking whether the final output still shows perspective violations or ghosting that the dual-branch stage fails to remove.
Figures




read the original abstract
Precisely manipulating objects in a single photograph (translation, rotation, scaling) while obeying 3D physical constraints remains unsolved for diffusion-based editors. Current 2D methods lack spatial awareness and produce perspective violations. Forcing structural proxies into the latent space also disrupts variance homogeneity, and the resulting self-attention leakage leads to ghosting and background blur. The core difficulty is asymmetric: the relocated object must follow a rigid geometry, yet the uncovered background needs freedom to synthesize plausible content. We present GeoEdit, a training-free Lift-Manipulate-Render-Denoise pipeline that satisfies both constraints. We decouple scene and object in 3D, align them through point correspondence, and render a geometry-aligned proxy with a structural depth map. A Dual-Branch Denoising stage then refines this proxy: a video diffusion backbone preserves object identity, while 3D constraints are injected into the foreground within a narrow denoising window at matching noise variance (variance-homogeneous injection). The background denoises freely. Because the injected signal matches the native latent statistics, self-attention stays undisturbed. We also introduce GeoEditBench, a pose-aware benchmark covering object translation, object rotation, and camera movement with pose-aware evaluation metrics. Experiments confirm consistent gains in geometric accuracy, identity fidelity, and background quality. Our codes are available at https://github.com/Heey731/GeoEdit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce GeoEdit, a training-free Lift-Manipulate-Render-Denoise pipeline for 3D geometry-aware object editing (translation, rotation, scaling) in single images. It decouples scene/object via 3D point correspondence, renders a geometry-aligned proxy with structural depth map, and applies Dual-Branch Denoising: a video diffusion backbone preserves object identity while variance-homogeneous injection enforces rigid 3D constraints on the foreground within a narrow denoising window, allowing free background synthesis. The key assertion is that matching native latent statistics leaves self-attention undisturbed. It also introduces GeoEditBench with pose-aware metrics and reports consistent gains in geometric accuracy, identity fidelity, and background quality. Code is released at https://github.com/Heey731/GeoEdit.
Significance. If the central claims hold, the work would be significant for diffusion-based editing by addressing the asymmetric constraints of rigid object manipulation versus free background synthesis without requiring training or fine-tuning. The training-free nature, explicit code release, and introduction of a pose-aware benchmark are strengths that support reproducibility and further evaluation.
major comments (2)
- [Abstract] Abstract: The claim that 'Because the injected signal matches the native latent statistics, self-attention stays undisturbed' is load-bearing for the Dual-Branch Denoising separation of rigid object vs. free background constraints, yet no equations, attention-map analysis, or ablation is referenced to show that variance matching alone prevents shifts in attention weights from mismatched spatial structure or edge statistics in the depth-rendered proxy.
- [Abstract] Abstract (and implied method section): The pipeline relies on accurate 3D decoupling and structural depth map rendering without introducing uncorrectable artifacts, but the abstract supplies no error analysis, failure cases, or quantitative validation of the point correspondence step under the claimed manipulations (translation/rotation/camera movement).
minor comments (1)
- [Abstract] The abstract mentions 'consistent gains' but does not name the baselines or report specific metric values; this should be expanded with quantitative results from the experiments section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications from the manuscript and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'Because the injected signal matches the native latent statistics, self-attention stays undisturbed' is load-bearing for the Dual-Branch Denoising separation of rigid object vs. free background constraints, yet no equations, attention-map analysis, or ablation is referenced to show that variance matching alone prevents shifts in attention weights from mismatched spatial structure or edge statistics in the depth-rendered proxy.
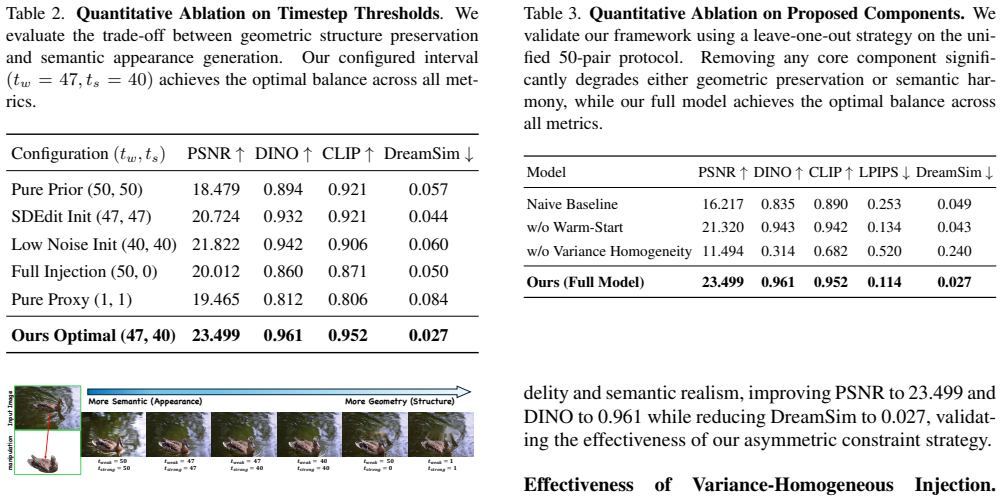
Authors: The manuscript explains the variance-homogeneous injection in Section 3.3 as matching both mean and variance of the native latents at each timestep, which preserves the input distribution to self-attention layers. This is supported by the ablation in Section 4.3 (Table 3) showing degraded identity preservation and increased ghosting when variance matching is removed. We agree that direct attention-map evidence would strengthen the claim and will add equations for the injection process plus attention visualization comparisons in the revised method section, with a reference added to the abstract. revision: yes
-
Referee: [Abstract] Abstract (and implied method section): The pipeline relies on accurate 3D decoupling and structural depth map rendering without introducing uncorrectable artifacts, but the abstract supplies no error analysis, failure cases, or quantitative validation of the point correspondence step under the claimed manipulations (translation/rotation/camera movement).
Authors: Section 4.2 and Table 2 report quantitative results on GeoEditBench for all three manipulation types using pose-aware metrics that directly measure geometric fidelity after point correspondence and rendering. Qualitative failure cases arising from correspondence errors are shown in the supplementary material. The abstract is concise by design, but we will revise it to reference the benchmark validation and error analysis already present in the full paper. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper describes a training-free Lift-Manipulate-Render-Denoise pipeline for geometry-aware editing, relying on 3D decoupling via point correspondence, structural depth map rendering, and variance-homogeneous injection into a dual-branch denoising process. No equations, fitted parameters, or quantitative predictions appear in the abstract or described method that reduce by construction to the inputs. Claims about self-attention remaining undisturbed are asserted as following from matching native latent statistics, but without any self-definitional loop, fitted-input renaming, or load-bearing self-citation chain. The introduction of GeoEditBench and empirical results provide external validation points independent of the method's internal logic. This is a standard descriptive methods paper with no detectable circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models operate on latent spaces where variance-homogeneous signals can be injected without disrupting self-attention
invented entities (2)
-
Dual-Branch Denoising
no independent evidence
-
variance-homogeneous injection
no independent evidence
Reference graph
Works this paper leans on
-
[1]
6, 7, 14
Gemini 2.5 flash image (nano banana) — google ai stu- dio.https://aistudio.google.com/models/ gemini-2-5-flash-image. 6, 7, 14
-
[2]
Blended diffusion for text-driven editing of natural images
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18208–18218, 2022. 3, 5
2022
-
[3]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Sak- sham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv e-prints, pages arXiv–2506,
-
[4]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18392–18402, 2023. 2
2023
-
[5]
Wei Cao, Hao Zhang, Fengrui Tian, Yulun Wu, Yingying Li, Shenlong Wang, Ning Yu, and Yaoyao Liu. Freeor- bit4d: Training-free arbitrary camera redirection for monoc- ular videos via geometry-complete 4d reconstruction.arXiv preprint arXiv:2601.18993, 2026. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9650–9660, 2021. 6
2021
-
[7]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Jiacheng Chen, Ramin Mehran, Xuhui Jia, Saining Xie, and Sanghyun Woo. Blenderfusion: 3d-grounded vi- sual editing and generative compositing.arXiv preprint arXiv:2506.17450, 2025. 2, 3
-
[9]
Yiyang Chen, Xuanhua He, Xiujun Ma, and Yue Ma. Con- textflow: Training-free video object editing via adaptive con- text enrichment.arXiv preprint arXiv:2509.17818, 2025. 2
-
[10]
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based seman- tic image editing with mask guidance.arXiv preprint arXiv:2210.11427, 2022. 3
-
[11]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023. 2
2023
-
[12]
Dit4edit: Dif- fusion transformer for image editing
Kunyu Feng, Yue Ma, Bingyuan Wang, Chenyang Qi, Haozhe Chen, Qifeng Chen, and Zeyu Wang. Dit4edit: Dif- fusion transformer for image editing. InProceedings of 9 the AAAI Conference on Artificial Intelligence, pages 2969– 2977, 2025. 2
2025
-
[13]
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981. 13
1981
-
[14]
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dream- sim: Learning new dimensions of human visual similar- ity using synthetic data.arXiv preprint arXiv:2306.09344,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
PAI-Studio: Cinematic Video Background Replacement with Camera-Aware Motion
Heyuan Gao, Bangxun Tang, Yiren Song, Guian Fang, Zijian He, Jie Yang, and Mike Zheng Shou. Pai-studio: Cinematic video background replacement with camera-aware motion. arXiv preprint arXiv:2606.01399, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Id-animator: Zero-shot identity-preserving human video generation,
Xuanhua He, Quande Liu, Shengju Qian, Xin Wang, Tao Hu, Ke Cao, Keyu Yan, and Jie Zhang. Id-animator: Zero-shot identity-preserving human video generation.arXiv preprint arXiv:2404.15275, 2024. 2
-
[17]
Xuanhua He, Quande Liu, Zixuan Ye, Weicai Ye, Qi- ulin Wang, Xintao Wang, Qifeng Chen, Pengfei Wan, Di Zhang, and Kun Gai. Fulldit2: Efficient in-context con- ditioning for video diffusion transformers.arXiv preprint arXiv:2506.04213, 2025. 2
-
[18]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 13
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2, 3
2020
-
[20]
Ex- posure bias can alleviate itself via directional and frequency rectification in flow matching, 2026
Guanbo Huang, Jingjia Mao, Fanding Huang, Fengkai Liu, Xiangyang Luo, Yaoyuan Liang, Jiasheng Lu, Xiaoe Wang, Pei Liu, Ruiliu Fu, Ruqi Huang, and Shao-Lun Huang. Ex- posure bias can alleviate itself via directional and frequency rectification in flow matching, 2026. 3
2026
-
[21]
Image-to-image translation with conditional adver- sarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adver- sarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134,
-
[22]
Vace: All-in-one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 17191–17202, 2025. 4, 5, 13
2025
-
[23]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4401–4410, 2019. 2
2019
-
[24]
Finedance: A fine-grained choreography dataset for 3d full body dance generation
Ronghui Li, Junfan Zhao, Yachao Zhang, Mingyang Su, Zeping Ren, Han Zhang, Yansong Tang, and Xiu Li. Finedance: A fine-grained choreography dataset for 3d full body dance generation. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 10234– 10243, 2023. 2
2023
-
[25]
Lodge: A coarse to fine diffusion network for long dance generation guided by the characteristic dance primitives
Ronghui Li, YuXiang Zhang, Yachao Zhang, Hongwen Zhang, Jie Guo, Yan Zhang, Yebin Liu, and Xiu Li. Lodge: A coarse to fine diffusion network for long dance generation guided by the characteristic dance primitives. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1524–1534, 2024
2024
-
[26]
Lodge++: High-quality and long dance genera- tion with robust choreography patterns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Ronghui Li, Hongwen Zhang, Yachao Zhang, Yuxiang Zhang, Youliang Zhang, Jie Guo, Yan Zhang, Xiu Li, and Yebin Liu. Lodge++: High-quality and long dance genera- tion with robust choreography patterns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 2
2025
-
[27]
Zero-1-to-3: Zero-shot one image to 3d object, 2023
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object, 2023. 2
2023
-
[28]
SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. Syncdreamer: Gen- erating multiview-consistent images from a single-view im- age.arXiv preprint arXiv:2309.03453, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022. 2
2022
-
[30]
Follow your pose: Pose- guided text-to-video generation using pose-free videos
Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Siran Chen, Xiu Li, and Qifeng Chen. Follow your pose: Pose- guided text-to-video generation using pose-free videos. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 4117–4125, 2024. 2
2024
-
[31]
Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation
Yue Ma, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, Wei Liu, et al. Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–12, 2024. 2
2024
-
[32]
Magic- stick: Controllable video editing via control handle transfor- mations
Yue Ma, Xiaodong Cun, Sen Liang, Jinbo Xing, Yingqing He, Chenyang Qi, Siran Chen, and Qifeng Chen. Magic- stick: Controllable video editing via control handle transfor- mations. In2025 IEEE/CVF Winter Conference on Applica- tions of Computer Vision (WACV), pages 9385–9395. IEEE,
-
[33]
Controllable video generation: A survey.arXiv preprint arXiv:2507.16869,
Yue Ma, Kunyu Feng, Zhongyuan Hu, Xinyu Wang, Yucheng Wang, Mingzhe Zheng, Xuanhua He, Chenyang Zhu, Hongyu Liu, Yingqing He, et al. Controllable video generation: A survey.arXiv preprint arXiv:2507.16869,
-
[34]
Yue Ma, Kunyu Feng, Xinhua Zhang, Hongyu Liu, David Junhao Zhang, Jinbo Xing, Yinhan Zhang, Ayden Yang, Zeyu Wang, and Qifeng Chen. Follow-your-creation: Empowering 4d creation through video inpainting.arXiv preprint arXiv:2506.04590, 2025
-
[35]
Follow-your-click: Open-domain regional image animation via motion prompts
Yue Ma, Yingqing He, Hongfa Wang, Andong Wang, Leqi Shen, Chenyang Qi, Jixuan Ying, Chengfei Cai, Zhifeng Li, Heung-Yeung Shum, et al. Follow-your-click: Open-domain regional image animation via motion prompts. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 6018–6026, 2025
2025
-
[36]
Yue Ma, Yulong Liu, Qiyuan Zhu, Ayden Yang, Kunyu Feng, Xinhua Zhang, Zhifeng Li, Sirui Han, Chenyang Qi, and Qifeng Chen. Follow-your-motion: Video motion transfer via efficient spatial-temporal decoupled finetuning.arXiv preprint arXiv:2506.05207, 2025. 10
-
[37]
Yue Ma, Zexuan Yan, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, et al. Follow-your-emoji-faster: To- wards efficient, fine-controllable, and expressive freestyle portrait animation.arXiv preprint arXiv:2509.16630, 2025
-
[38]
Group editing: Edit multiple im- ages in one go.arXiv preprint arXiv:2603.22883, 2026
Yue Ma, Xinyu Wang, Qianli Ma, Qinghe Wang, Mingzhe Zheng, Xiangpeng Yang, Hao Li, Chongbo Zhao, Jixuan Ying, Harry Yang, et al. Group editing: Edit multiple im- ages in one go.arXiv preprint arXiv:2603.22883, 2026
-
[39]
Fastvmt: Eliminat- ing redundancy in video motion transfer.arXiv preprint arXiv:2602.05551, 2026
Yue Ma, Zhikai Wang, Tianhao Ren, Mingzhe Zheng, Hongyu Liu, Jiayi Guo, Mark Fong, Yuxuan Xue, Zixi- ang Zhao, Konrad Schindler, et al. Fastvmt: Eliminat- ing redundancy in video motion transfer.arXiv preprint arXiv:2602.05551, 2026. 2
-
[40]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jia- jun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equa- tions.arXiv preprint arXiv:2108.01073, 2021. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[41]
Object 3dit: Language-guided 3d-aware image editing.Advances in Neural Information Processing Systems, 36:3497–3516,
Oscar Michel, Anand Bhattad, Eli VanderBilt, Ranjay Kr- ishna, Aniruddha Kembhavi, and Tanmay Gupta. Object 3dit: Language-guided 3d-aware image editing.Advances in Neural Information Processing Systems, 36:3497–3516,
-
[42]
Accelerating autoregressive video diffusion via history-guided cache and residual correc- tion
Kepan Nan, Wangbo Zhao, Penghao Zhou, Jun Li, Zhenheng Yang, Jian Yang, and Ying Tai. Accelerating autoregressive video diffusion via history-guided cache and residual correc- tion. InCVPR, pages 43740–43750, 2026. 2
2026
-
[43]
Drag your gan: Interactive point-based manipulation on the generative image manifold
Xingang Pan, Ayush Tewari, Thomas Leimk ¨uhler, Lingjie Liu, Abhimitra Meka, and Christian Theobalt. Drag your gan: Interactive point-based manipulation on the generative image manifold. InACM SIGGRAPH 2023 conference pro- ceedings, pages 1–11, 2023. 2
2023
-
[44]
Diffusion handles enabling 3d edits for diffusion models by lifting ac- tivations to 3d
Karran Pandey, Paul Guerrero, Matheus Gadelha, Yannick Hold-Geoffroy, Karan Singh, and Niloy J Mitra. Diffusion handles enabling 3d edits for diffusion models by lifting ac- tivations to 3d. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7695– 7704, 2024. 3
2024
-
[45]
Styleclip: Text-driven manipulation of stylegan imagery
Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. Styleclip: Text-driven manipulation of stylegan imagery. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 2085–2094,
2085
-
[46]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 4195–4205,
-
[47]
Fatezero: Fus- ing attentions for zero-shot text-based video editing
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. Fatezero: Fus- ing attentions for zero-shot text-based video editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15932–15942, 2023. 2
2023
-
[48]
U2-net: Go- ing deeper with nested u-structure for salient object detec- tion.Pattern recognition, 106:107404, 2020
Xuebin Qin, Zichen Zhang, Chenyang Huang, Masood De- hghan, Osmar R Zaiane, and Martin Jagersand. U2-net: Go- ing deeper with nested u-structure for salient object detec- tion.Pattern recognition, 106:107404, 2020. 13
2020
-
[49]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 6
2021
-
[50]
Vi- sion transformers for dense prediction
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021. 2
2021
-
[51]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 3
2022
-
[53]
Penghui Ruan, Bojia Zi, Xianbiao Qi, Youze Huang, Rong Xiao, Pichao Wang, Jiannong Cao, and Yuhui Shi. Ctrl&shift: High-quality geometry-aware object manipula- tion in visual generation.arXiv preprint arXiv:2602.11440,
-
[54]
Geodiffuser: Geometry-based image editing with diffusion models
Rahul Sajnani, Jeroen Vanbaar, Jie Min, Kapil D Katyal, and Srinath Sridhar. Geodiffuser: Geometry-based image editing with diffusion models. InProceedings of the Winter Confer- ence on Applications of Computer Vision, pages 472–482,
-
[55]
In- terpreting the latent space of gans for semantic face editing
Yujun Shen, Jinjin Gu, Xiaoou Tang, and Bolei Zhou. In- terpreting the latent space of gans for semantic face editing. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 9243–9252, 2020. 2
2020
-
[56]
Yutao Shen, Junkun Yuan, Toru Aonishi, Hideki Nakayama, and Yue Ma. Follow-your-preference: Towards preference- aligned image inpainting.arXiv preprint arXiv:2509.23082,
-
[57]
Dragdiffusion: Harnessing diffusion models for interactive point-based image editing
Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Han- shu Yan, Wenqing Zhang, Vincent YF Tan, and Song Bai. Dragdiffusion: Harnessing diffusion models for interactive point-based image editing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8839–8849, 2024. 2
2024
-
[58]
Time-to-move: Training-free motion controlled video generation via dual-clock denoising, 2025
Assaf Singer, Noam Rotstein, Amir Mann, Ron Kimmel, and Or Litany. Time-to-move: Training-free motion controlled video generation via dual-clock denoising.arXiv preprint arXiv:2511.08633, 2025. 2, 3, 5
-
[59]
Pro- cesspainter: Learning to draw from sequence data
Yiren Song, Shijie Huang, Chen Yao, Hai Ci, Xiaojun Ye, Jiaming Liu, Yuxuan Zhang, and Mike Zheng Shou. Pro- cesspainter: Learning to draw from sequence data. InSIG- GRAPH Asia 2024 Conference Papers, pages 1–10, 2024. 2
2024
-
[60]
StreamingEffect: Real-Time Human-Centric Video Effect Generation
Yiren Song, Cheng Liu, Yuxin Jiang, and Mike Zheng Shou. Streamingeffect: Real-time human-centric video effect gen- eration.arXiv preprint arXiv:2605.17019, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
VISTA: Triplet-Supervised Video Style Transfer with Diffusion Transformers
Yiren Song, Wangzi Yao, Haofan Wang, and Mike Zheng Shou. Vista: Triplet-supervised video style transfer with dif- fusion transformers.arXiv preprint arXiv:2605.17312, 2026. 2 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
An image inpainting technique based on the fast marching method.Journal of graphics tools, 9(1): 23–34, 2004
Alexandru Telea. An image inpainting technique based on the fast marching method.Journal of graphics tools, 9(1): 23–34, 2004. 4, 13
2004
-
[65]
Sv3d: Novel multi-view syn- thesis and 3d generation from a single image using latent video diffusion
Vikram V oleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. Sv3d: Novel multi-view syn- thesis and 3d generation from a single image using latent video diffusion. InEuropean Conference on Computer Vi- sion, pages 439–457. Springer, 2024. 3, 5, 13
2024
-
[66]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 4, 5, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Cove: Unleashing the diffusion fea- ture correspondence for consistent video editing.Advances in Neural Information Processing Systems, 37:96541–96565,
Jiangshan Wang, Yue Ma, Jiayi Guo, Yicheng Xiao, Gao Huang, and Xiu Li. Cove: Unleashing the diffusion fea- ture correspondence for consistent video editing.Advances in Neural Information Processing Systems, 37:96541–96565,
-
[68]
Taming rectified flow for inversion and editing.arXiv preprint arXiv:2411.04746,
Jiangshan Wang, Junfu Pu, Zhongang Qi, Jiayi Guo, Yue Ma, Nisha Huang, Yuxin Chen, Xiu Li, and Ying Shan. Tam- ing rectified flow for inversion and editing.arXiv preprint arXiv:2411.04746, 2024. 2
-
[69]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 3, 5, 13
2025
-
[70]
Synsin: End-to-end view synthesis from a sin- gle image
Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. Synsin: End-to-end view synthesis from a sin- gle image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7467–7477,
-
[71]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 6, 7, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Holistically-nested edge de- tection, 2015
Saining Xie and Zhuowen Tu. Holistically-nested edge de- tection, 2015. 2
2015
-
[73]
Smrabooth: Subject and motion representation alignment for customized video generation
Xuancheng Xu, Yaning Li, Sisi You, and Bing-Kun Bao. Smrabooth: Subject and motion representation alignment for customized video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16130–16141, 2026. 2
2026
-
[74]
Contranerf: Gen- eralizable neural radiance fields for synthetic-to-real novel view synthesis via contrastive learning
Hao Yang, Lanqing Hong, Aoxue Li, Tianyang Hu, Zhen- guo Li, Gim Hee Lee, and Liwei Wang. Contranerf: Gen- eralizable neural radiance fields for synthetic-to-real novel view synthesis via contrastive learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16508–16517, 2023. 2
2023
-
[75]
VideoCoF: Unified Video Editing with Temporal Reasoner
Xiangpeng Yang, Ji Xie, Yiyuan Yang, Yan Huang, Min Xu, and Qiang Wu. Unified video editing with temporal reasoner. arXiv preprint arXiv:2512.07469, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Unic: Unified in-context video editing.ICLR 2026, 2025
Zixuan Ye, Xuanhua He, Quande Liu, Qiulin Wang, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Qifeng Chen, and Wenhan Luo. Unic: Unified in-context video editing.ICLR 2026, 2025. 2
2026
-
[77]
Image sculpting: Precise ob- ject editing with 3d geometry control
Jiraphon Yenphraphai, Xichen Pan, Sainan Liu, Daniele Panozzo, and Saining Xie. Image sculpting: Precise ob- ject editing with 3d geometry control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4241–4251, 2024. 6, 7, 14
2024
-
[78]
Objectmover: Gener- ative object movement with video prior
Xin Yu, Tianyu Wang, Soo Ye Kim, Paul Guerrero, Xi Chen, Qing Liu, Zhe Lin, and Xiaojuan Qi. Objectmover: Gener- ative object movement with video prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17682–17691, 2025. 3
2025
-
[79]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 2, 5
2023
-
[80]
3ditscene: Editing any scene via language-guided disen- tangled gaussian splatting
Qihang Zhang, Yinghao Xu, Chaoyang Wang, Hsin-Ying Lee, Gordon Wetzstein, Bolei Zhou, and Ceyuan Yang. 3ditscene: Editing any scene via language-guided disen- tangled gaussian splatting. InInternational Conference on Learning Representations, pages 2760–2775, 2025. 3
2025
-
[81]
Objectadd: adding objects into image via a training-free diffusion modification fashion.Pattern Recog- nition, page 112807, 2025
Ziyue Zhang, Mingbao Lin, Quanjian Song, Yuxin Zhang, and Rongrong Ji. Objectadd: adding objects into image via a training-free diffusion modification fashion.Pattern Recog- nition, page 112807, 2025. 2
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.