SciIR: A Large-scale Training Dataset and Benchmark for Scientific Image Reasoning Generation
Pith reviewed 2026-06-30 06:45 UTC · model grok-4.3
The pith
Fine-tuning on an 82k scientific image dataset lifts model performance on a new reasoning benchmark from 35% to 43%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
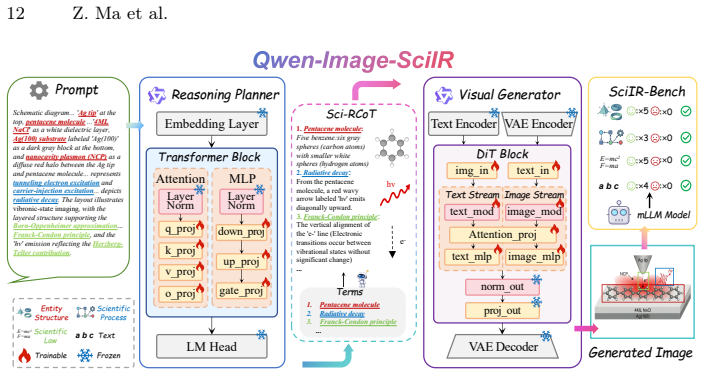
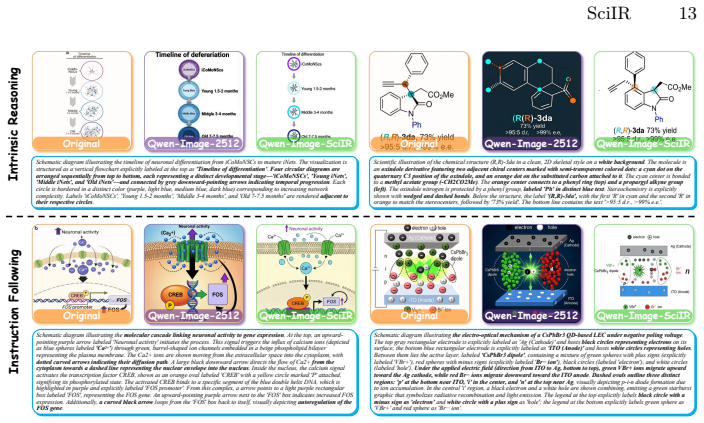
Scientific image generation requires explicit modeling of three semiotic dimensions of reasoning—Entity Structure/Icon, Scientific Process/Index, and Scientific Law/Symbol—together with a Scientific Reasoning Chain-of-Thought; the SciIR-82k dataset supplies the necessary training pairs while SciIR-Bench supplies the aligned evaluation, and fine-tuning on the dataset demonstrably raises model scores from 35% to 43%.
What carries the argument
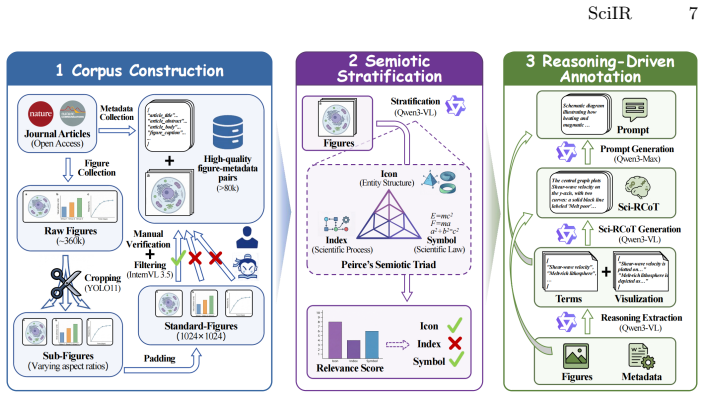
The three semiotic dimensions (Entity Structure/Icon, Scientific Process/Index, Scientific Law/Symbol) plus the Atomic Checklist, which together organize the dataset hierarchically and convert scientific accuracy into fine-grained verifiable questions.
If this is right
- Fine-tuning on SciIR-82k produces measurable gains in scientific reasoning within generated images.
- The Atomic Checklist enables process-oriented rather than purely outcome-oriented evaluation of scientific image accuracy.
- Current text-to-image models exhibit clear deficiencies across all three semiotic dimensions on SciIR-Bench.
- Hierarchical organization of image-text pairs by semiotic level supports structured training for visual logic.
- Sci-RCoT annotations supply explicit intermediate reasoning steps that improve alignment with scientific content.
Where Pith is reading between the lines
- The semiotic framing could be tested on image generation tasks outside science to check whether the same three dimensions organize non-scientific visual reasoning.
- Improvement after fine-tuning implies that process-level supervision may transfer to other multimodal reasoning benchmarks that currently rely on outcome-only metrics.
- Larger-scale versions of SciIR-82k could be used to measure how much additional data is needed before gains plateau on the benchmark.
- The checklist format might be adapted to create automatic verifiers for other domains where logical consistency matters more than visual realism.
Load-bearing premise
The mapping of Peirce's Semiotic Triad onto the three core dimensions plus the Atomic Checklist provides a valid and comprehensive framework that converts outcome-oriented scientific accuracy into process-oriented verifiable questions.
What would settle it
An experiment in which models trained on SciIR-82k still produce images that violate core scientific relations not detected by the Atomic Checklist, or in which fine-tuning yields no measurable gain on SciIR-Bench.
Figures

read the original abstract
While Text-to-Image (T2I) models have shown remarkable success in generating photorealistic visual content, they still struggle with the rigorous semantic alignment and logical reasoning required for scientific imagery. Inspired by Peirce's Semiotic Triad, we introduce Scientific Image Reasoning (SciIR), a comprehensive resource for training and evaluation of scientific image generation. We formalize scientific reasoning into three core dimensions: Entity Structure (Icon), Scientific Process (Index), and Scientific Law (Symbol). Specifically, to overcome the scarcity of training data in scientific image generation, we elaborately create SciIR-82k, a large-scale dataset containing over 80,000 high-quality scientific image-text pairs from cutting-edge publications. The dataset is hierarchically organized according to the semiotic dimensions and incorporates a Scientific Reasoning Chain-of-Thought (Sci-RCoT) to explicitly model underlying visual logic. For evaluation, we propose SciIR-Bench, which aligns with these three semiotic levels and employs an Atomic Checklist to convert the outcome-oriented scientific accuracy into process-oriented, verifiable, fine-grained questions. Our extensive experiments reveal significant deficiencies in current models' scientific reasoning capabilities. Furthermore, by fine-tuning on the SciIR-82k dataset, we developed the Qwen-Image-SciIR model, which achieves a substantial improvement on the SciIR-Bench, increasing the final score from 35\% to 43\%, laying a solid foundation for future advances in scientific image generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SciIR as a framework for scientific image reasoning in text-to-image models, drawing on Peirce's Semiotic Triad to define three dimensions (Entity Structure/Icon, Scientific Process/Index, Scientific Law/Symbol). It contributes SciIR-82k, a dataset of over 80,000 image-text pairs from scientific publications with hierarchical organization and Sci-RCoT chains, plus SciIR-Bench that uses an Atomic Checklist to produce fine-grained, process-oriented evaluation questions. Experiments document deficiencies in existing models and report that fine-tuning yields a Qwen-Image-SciIR model whose SciIR-Bench score rises from 35% to 43%.
Significance. If the semiotic mapping and Atomic Checklist are shown to track genuine scientific reasoning, the work supplies a large, publicly useful training resource and evaluation protocol that directly targets a documented weakness in current T2I systems. The scale of SciIR-82k and the explicit modeling of visual logic via Sci-RCoT constitute concrete assets for the community; the reported 8-point absolute gain after fine-tuning, if reproducible and statistically supported, would constitute the first quantified demonstration that domain-specific data of this form improves scientific fidelity.
major comments (3)
- [Benchmark section] The central empirical claim (35% → 43% improvement) rests on SciIR-Bench scores reflecting actual reasoning gains, yet the manuscript provides no inter-annotator agreement statistics, expert correlation study, or ablation demonstrating that Atomic Checklist scores align with independent human judgments of scientific correctness (Benchmark section).
- [Dataset construction and semiotic dimensions] The Peirce-triad decomposition into Entity Structure, Scientific Process, and Scientific Law is presented as comprehensive, but no evidence is given that the mapping is complete or that the three dimensions are orthogonal; an ablation removing one dimension and re-measuring model performance would be required to support the claim that the framework is load-bearing (Dataset construction and § on semiotic dimensions).
- [Experiments and results tables] Table reporting the 35%–43% scores does not state the aggregation rule across the three semiotic dimensions, the number of test items per dimension, or whether the improvement is statistically significant; without these details the magnitude of the gain cannot be interpreted (Experiments and results tables).
minor comments (2)
- [Dataset curation] The description of how SciIR-82k pairs were filtered for quality and how the Scientific Reasoning Chain-of-Thought was generated lacks concrete procedural steps or inter-annotator metrics.
- [Figures] Figure captions for example image-text pairs should explicitly label which semiotic dimension each example is intended to exercise.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, with plans to revise the manuscript for greater clarity and rigor where appropriate.
read point-by-point responses
-
Referee: [Benchmark section] The central empirical claim (35% → 43% improvement) rests on SciIR-Bench scores reflecting actual reasoning gains, yet the manuscript provides no inter-annotator agreement statistics, expert correlation study, or ablation demonstrating that Atomic Checklist scores align with independent human judgments of scientific correctness (Benchmark section).
Authors: We agree that empirical validation of the Atomic Checklist against human judgments would strengthen the benchmark. The checklist items are intentionally atomic and derived from explicit, verifiable criteria tied to the semiotic dimensions to promote objectivity. In the revised manuscript we will add inter-annotator agreement statistics from the annotation process and report results from a small-scale expert correlation study in the Benchmark section. revision: yes
-
Referee: [Dataset construction and semiotic dimensions] The Peirce-triad decomposition into Entity Structure, Scientific Process, and Scientific Law is presented as comprehensive, but no evidence is given that the mapping is complete or that the three dimensions are orthogonal; an ablation removing one dimension and re-measuring model performance would be required to support the claim that the framework is load-bearing (Dataset construction and § on semiotic dimensions).
Authors: The three dimensions follow directly from Peirce’s semiotic triad (icon/index/symbol), a theoretically established framework chosen for its ability to separate structural, procedural, and law-based aspects of scientific imagery. We will expand the dataset construction section with additional theoretical justification for their distinctiveness. A full ablation requiring separate model retraining on dimension subsets is computationally prohibitive at this scale; we will instead note this as a limitation and future direction rather than claim empirical orthogonality. revision: partial
-
Referee: [Experiments and results tables] Table reporting the 35%–43% scores does not state the aggregation rule across the three semiotic dimensions, the number of test items per dimension, or whether the improvement is statistically significant; without these details the magnitude of the gain cannot be interpreted (Experiments and results tables).
Authors: We thank the referee for noting these omissions. The reported score is the unweighted average across the three dimensions. In the revision we will update the table caption, Experiments section, and text to state the aggregation rule explicitly, report the exact number of test items per dimension, and include a statistical significance assessment of the 35% to 43% improvement (computing p-values where the per-item data allow). revision: yes
Circularity Check
No circularity: empirical dataset/benchmark construction with independent evaluation
full rationale
The paper's core contribution is the creation of SciIR-82k (data collection from publications, hierarchical organization by semiotic dimensions, addition of Sci-RCoT) and SciIR-Bench (mapping to three dimensions plus Atomic Checklist for scoring). The reported 35%→43% improvement is an empirical fine-tuning result on held-out benchmark items, not a derivation, fitted parameter, or self-referential equation. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text; the Peirce mapping is presented as an adopted framework rather than a derived result that reduces to the paper's own inputs. The work is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Peirce's Semiotic Triad can be mapped to and structures scientific image reasoning into Entity Structure (Icon), Scientific Process (Index), and Scientific Law (Symbol)
Reference graph
Works this paper leans on
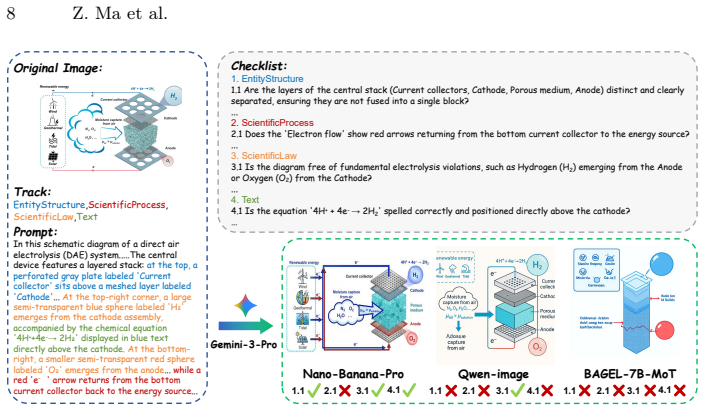
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
Cai, Q., Chen, J., Chen, Y., Li, Y., Long, F., Pan, Y., Qiu, Z., Zhang, Y., Gao, F., Xu, P., et al.: Hidream-i1: A high-efficient image generative foundation model with sparse diffusion transformer. arXiv preprint arXiv:2505.22705 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
arXiv preprint arXiv:2505.22126 (2025)
Chang, Y., Feng, Y., Sun, J., Ai, J., Li, C., Zhou, S.K., Zhang, K.: Sridbench: Benchmark of scientific research illustration drawing of image generation model. arXiv preprint arXiv:2505.22126 (2025)
-
[4]
In: IEEE Conf
Changpinyo, S., Sharma, P., Ding, N., Soricut, R.: Conceptual 12M: Pushing web- scale image-text pre-training to recognize long-tail visual concepts. In: IEEE Conf. Comput. Vis. Pattern Recog. (2021) 16 Z. Ma et al
2021
-
[5]
arXiv preprint arXiv:2505.23493 (2025)
Chen, K., Lin, Z., Xu, Z., Shen, Y., Yao, Y., Rimchala, J., Zhang, J., Huang, L.: R2i-bench: Benchmarking reasoning-driven text-to-image generation. arXiv preprint arXiv:2505.23493 (2025)
-
[6]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Esser, P., Kulal, S., Blattmann, A., Entezari, R., M"uller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Int. Conf. Mach. Learn. (2024)
2024
-
[9]
arXiv preprint arXiv:2509.09680 (2025)
Fang, R., Yu, A., Duan, C., Huang, L., Bai, S., Cai, Y., Wang, K., Liu, S., Liu, X., Li, H.: Flux-reason-6m & prism-bench: A million-scale text-to-image reasoning dataset and comprehensive benchmark. arXiv preprint arXiv:2509.09680 (2025)
- [10]
-
[11]
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. Adv. Neural Inform. Process. Syst.36, 52132–52152 (2023)
2023
-
[12]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021)
2021
-
[13]
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inform. Process. Syst.30(2017)
2017
-
[14]
Hu, Y., Liu, B., Kasai, J., Wang, Y., Ostendorf, M., Krishna, R., Smith, N.A.: Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. In: Int. Conf. Comput. Vis. pp. 20406–20417 (2023)
2023
-
[15]
Huang, K., Sun, K., Xie, E., Li, Z., Liu, X.: T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. Adv. Neural Inform. Process. Syst.36, 78723–78747 (2023)
2023
-
[16]
https://github.com/ ultralytics/ultralytics(2024), software version 11.0.0
Jocher, G., Chaurasia, A., Qiu, J.: Ultralytics YOLO. https://github.com/ ultralytics/ultralytics(2024), software version 11.0.0. Accessed: 2025-12-21
2024
-
[17]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Ku, M., Jiang, D., Wei, C., Yue, X., Chen, W.: Viescore: Towards explainable metrics for conditional image synthesis evaluation. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 12268–12290 (2024)
2024
-
[18]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dock- horn, T., English, J., English, Z., Esser, P., et al.: Flux. 1 kontext: Flow match- ing for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
In: IEEE Conf
Li, J., Chai, W., Fu, X., Xu, H., Xie, S.: Science-t2i: Addressing scientific illusions in image synthesis. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 2734–2744 (2025)
2025
-
[20]
arXiv preprint arXiv:2503.19312 (2025) SciIR 17
Liao, J., Yang, Z., Li, L., Li, D., Lin, K., Cheng, Y., Wang, L.: Imagegen-cot: Enhancing text-to-image in-context learning with chain-of-thought reasoning. arXiv preprint arXiv:2503.19312 (2025) SciIR 17
-
[21]
arXiv preprint arXiv:2601.17027 (2026)
Lin, H., Qin, C., Liu, Z., Pei, Q., Li, Y., Zhong, Z., Gao, X., Wang, Y., He, C., Wu, L.: Scientific image synthesis: Benchmarking, methodologies, and downstream utility. arXiv preprint arXiv:2601.17027 (2026)
-
[22]
Lin, Z., Pathak, D., Li, B., Li, J., Xia, X., Neubig, G., Zhang, P., Ramanan, D.: Evaluating text-to-visual generation with image-to-text generation. In: Eur. Conf. Comput. Vis. pp. 366–384. Springer (2024)
2024
-
[23]
In: IEEE Conf
Ma, Y., Liu, X., Chen, X., Liu, W., Wu, C., Wu, Z., Pan, Z., Xie, Z., Zhang, H., Yu, X., et al.: Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 7739–7751 (2025)
2025
-
[24]
IEEE Trans
Ma, Z., Zhang, Y., Jia, G., Zhao, L., Ma, Y., Ma, M., Liu, G., Zhang, K., Ding, N., Li, J., et al.: Efficient diffusion models: A comprehensive survey from principles to practices. IEEE Trans. Pattern Anal. Mach. Intell. (2025)
2025
-
[25]
Ma, Z., Zhao, L., Qi, B., Zhou, B.: Neural residual diffusion models for deep scalable vision generation. Adv. Neural Inform. Process. Syst.37, 117456–117480 (2024)
2024
-
[26]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Niu, Y., Ning, M., Zheng, M., Jin, W., Lin, B., Jin, P., Liao, J., Feng, C., Ning, K., Zhu, B., et al.: Wise: A world knowledge-informed semantic evaluation for text-to-image generation. arXiv preprint arXiv:2503.07265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Onoe, Y., Rane, S., Berger, Z., Bitton, Y., Cho, J., Garg, R., Ku, A., Parekh, Z., Pont-Tuset, J., Tanzer, G., Wang, S., Baldridge, J.: DOCCI: Descriptions of Connected and Contrasting Images. In: Eur. Conf. Comput. Vis. (2024)
2024
-
[28]
arXiv preprint arXiv:2505.22407 (2025)
Pan, J., Ma, Z., Zhang, K., Ding, N., Zhou, B.: Self-reflective reinforcement learning for diffusion-based image reasoning generation. arXiv preprint arXiv:2505.22407 (2025)
-
[29]
Peirce, C.S.: Collected papers of charles sanders peirce, vol. 5. Harvard University Press (1934)
1934
-
[30]
arXiv preprint arXiv:2503.21758 (2025)
Qin, Q., Zhuo, L., Xin, Y., Du, R., Li, Z., Fu, B., Lu, Y., Yuan, J., Li, X., Liu, D., et al.: Lumina-image 2.0: A unified and efficient image generative framework. arXiv preprint arXiv:2503.21758 (2025)
-
[31]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: Int. Conf. Mach. Learn. pp. 8748–8763. PmLR (2021)
2021
-
[32]
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X.: Improved techniques for training gans. Adv. Neural Inform. Process. Syst.29(2016)
2016
-
[33]
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large-scale dataset for training next generation image-text models. Adv. Neural Inform. Process. Syst.35, 25278–25294 (2022)
2022
-
[34]
Sidorov, O., Hu, R., Rohrbach, M., Singh, A.: Textcaps: a dataset for image captioning with reading comprehension. In: Eur. Conf. Comput. Vis. pp. 742–758. Springer (2020)
2020
-
[35]
arXiv (2024)
Singla, V., Yue, K., Paul, S., Shirkavand, R., Jayawardhana, M., Ganjdanesh, A., Huang, H., Bhatele, A., Somepalli, G., Goldstein, T.: From Pixels to Prose: A Large Dataset of Dense Image Captions. arXiv (2024)
2024
-
[36]
arXiv preprint arXiv:2508.17472 (2025)
Sun, K., Fang, R., Duan, C., Liu, X., Liu, X.: T2i-reasonbench: Benchmark- ing reasoning-informed text-to-image generation. arXiv preprint arXiv:2508.17472 (2025)
-
[37]
Sun, K., Pan, J., Ge, Y., Li, H., Duan, H., Wu, X., Zhang, R., Zhou, A., Qin, Z., Wang, Y., et al.: Journeydb: A benchmark for generative image understanding. Adv. Neural Inform. Process. Syst.36, 49659–49678 (2023) 18 Z. Ma et al
2023
-
[38]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregres- sive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
arXiv preprint arXiv:2501.18427 (2025)
Xie, E., Chen, J., Zhao, Y., Yu, J., Zhu, L., Wu, C., Lin, Y., Zhang, Z., Li, M., Chen, J., et al.: Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer. arXiv preprint arXiv:2501.18427 (2025)
-
[43]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal understanding and generation. arXiv preprint arXiv:2408.12528 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Yang, L., Liu, J., Hong, S., Zhang, Z., Huang, Z., Cai, Z., Zhang, W., Cui, B.: Improving diffusion-based image synthesis with context prediction. Adv. Neural Inform. Process. Syst.36, 37636–37656 (2023)
2023
-
[46]
arXiv preprint arXiv:2508.09987 (2025)
Ye, J., Jiang, D., Wang, Z., Zhu, L., Hu, Z., Huang, Z., He, J., Yan, Z., Yu, J., Li, H., et al.: Echo-4o: Harnessing the power of gpt-4o synthetic images for improved image generation. arXiv preprint arXiv:2508.09987 (2025)
- [47]
-
[48]
arXiv preprint arXiv:2408.01181 (2024)
Zhang, Q., Dai, X., Yang, N., An, X., Feng, Z., Ren, X.: Var-clip: Text-to-image generator with visual auto-regressive modeling. arXiv preprint arXiv:2408.01181 (2024)
-
[49]
arXiv preprint arXiv:2601.23265 (2026)
Zhu, D., Meng, R., Song, Y., Wei, X., Li, S., Pfister, T., Yoon, J.: Paperbanana: Automating academic illustration for ai scientists. arXiv preprint arXiv:2601.23265 (2026)
-
[50]
Open Access
Zhu, M., Lin, Z., Weng, Y., Lu, P., Xie, Q., Wei, Y., Liu, S., Sun, Q., Zhang, Y.: Autofigure: Generating and refining publication-ready scientific illustrations. In: Int. Conf. Learn. Represent. (2026) A Dataset Source, License, and Compliance To ensure full copyright compliance and transparency, we strictly limit our data sources to open-access articles...
2026
-
[51]
Minimum Resolution:The width or height of the bounding box was less than 128 pixels
-
[52]
Extreme Aspect Ratio:The aspect ratio (width/height) fell outside the range of[0.33, 3.0], ensuring that extremely narrow or flat artifacts were excluded
-
[53]
Abnormal Area Occupancy:The detection region occupied between 75%and90%ofthetotalfigurearea.Thisheuristicwasspecificallyapplied to filter out potential full-figure layout misclassifications or background elements while retaining valid single-panel figures. B.2 Image Standardization To ensure input consistency while preserving the original aspect ratio and...
-
[54]
We sample pixels from the specific edges (top/bottom or left/right) requiring extension
-
[55]
If a dominant color constitutes> 55%of the edge pixels, it is used for padding
-
[56]
REJECT” are discarded. Cases with low confidence are routed to manual review. Stage 2: Manual Spot-CheckA random 10% subset of the “KEEP
Otherwise, the mean RGB value of the edge pixels is calculated and applied. –Resampling:We use the Lanczos filter for high-quality downsampling to preserve fine text and structural details during resizing. B.3 Dual-Stage Filtering We employ a cascade of automated and manual filtering to ensure high data quality. 22 Z. Ma et al. Stage 1: VLM FilteringWe us...
-
[57]
Entity–Law:Structural hierarchies governed by abstract physical rules
-
[58]
3.Entity–Process:Spatial transitions during experimental workflows
Law–Process:Dynamic state changes constrained by conservation laws. 3.Entity–Process:Spatial transitions during experimental workflows. C.3 Adaptive Difficulty Stratification To disentangle instruction-following capabilities from intrinsic scientific reasoning, we implemented an automated bifurcation strategy based on semantic saturation. Within each grou...
-
[59]
top-left
Positional Accuracy:Only if a specific position is explicitly defined in the prompt (e.g., “top-left”). To prevent hallucinated constraints, the model is strictly forbidden from assuming positions (e.g., “inside”) if only vague prepositions (e.g., “labeled”) are used. –Layer 2: Track-Customized Rules (Scientific Content).Based on the Core Track Type (Scie...
-
[60]
Impossible States
Scientific Law:Checks for “Impossible States” (e.g., violations of gravity, chemically impossible bonds)
-
[61]
Entity Structure:Checks for structural coherence (e.g., ensuring dis- tinct objects are not fused)
-
[62]
ghost” steps). D.2 Automated Adjudication The evaluation phase employs a VLM as a “Senior Scientific Image Reviewer
Scientific Process:Checks for flow logic conservation (e.g., no orphaned loops or “ghost” steps). D.2 Automated Adjudication The evaluation phase employs a VLM as a “Senior Scientific Image Reviewer.” The model receives the generated image, the original prompt, and the checklist JSON. Reviewer System PromptTo mimic human peer review, the system prompt enf...
-
[63]
VisualEvidenceRetrieval:Explicitlylocatethespecificelementmentioned in the checklist question within the image
-
[64]
Yes” (Pass) or “No
Reasoning:Formulate a one-sentence justification basedonlyon visual observation. 3.Verdict:Assign a binary “Yes” (Pass) or “No” (Fail). SciIR 25 Table 6: Ablation Study. Variant SL ES SP Text Final Qwen-Image-2512 40 50 37 15 35 w/o Sci-RCoT 41 54 39 15 38 w/o Planner 42 56 49 14 41 w/o Taxonomy 41 54 45 15 39 Full 43 59 53 15 43 Table 7: Effect of Judge....
-
[65]
- You must explicitly specify this style at the beginning of the generated instruction
Complete Visual Style: - Observe the original image, identify its specific drawing style (e.g., Schematic diagram, Photorealistic render, etc.). - You must explicitly specify this style at the beginning of the generated instruction
-
[66]
explicitly labeled as
Complete Text Rendering: - Observe key text in the original image (labels, legends, axis titles). - You must include mandatory text rendering requirements in the instruction, using phrases like "explicitly labeled as...", "including the text...", "with axis labeled..." etc
-
[67]
sci_RCoT
Integrate Scientific Logic: - Use the visualization items in reasoning to describe entity structure, topological relationships, and dynamic processes. - Language must be coherent, building a complete scene, not a simple list. Output Requirements: Please do not output text directly, but output a JSON object containing the following two fields: - "sci_RCoT"...
-
[68]
Analyze: Read the sci-RCoT to understand the scientific semantics
-
[69]
A realistic 3D render
Preserve Style: Extract the visualization style requirement (typically the first sentence or phrase of sci-RCoT, e.g., "A realistic 3D render...", "A schematic diagram of...", "A cross-section view..."). This must be the opening of your abstract_prompt
-
[70]
Map & Replace: Identify the description in sci-RCoT that corresponds to ’ visualization’ in Reasoning, and strictly replace it with the ’terms’ provided in Reasoning
-
[71]
Include text rendering requests in abstract_prompt if they are necessary for scientific clarity or context
Text Selection: Determine necessary text labels based on the sci-RCoT context. Include text rendering requests in abstract_prompt if they are necessary for scientific clarity or context
-
[72]
Compress: Synthesize the result into an abstract_prompt without visual descriptions
-
[73]
abstract_prompt
Synchronization: Extract exactly the text strings that are explicitly requested to be rendered in your generated abstract_prompt and populate the retained_text list. Constraints & Guardrails: - Semantic Integrity: The replacement must perfectly match the original scientific semantics. - Style Consistency: The output must start with the original visualizat...
-
[74]
Impossible States
ScientificLaw (Focus: Logic & Constraints) Definition: Focuses on laws, principles, and constraints. Positive Check Strategy: Decompose complex laws into specific scientific constraints. Negative Check Strategy (Hallucination): Check for violations of fundamental domain rules (axioms). Ensure no "Impossible States" exist (e.g., objects defying gravity, in...
-
[75]
EntityStructure
EntityStructure (Focus: Composition & Topology) Definition: Focuses on scientific entities (nouns). Positive Check Strategy: Decompose into Morphological (Shape), Chromatic (Color), and Component (Parts) or other structural checks. Negative Check Strategy (Hallucination): Check for structural coherence. Ensure distinct objects are clearly separated (not f...
-
[76]
ghost" steps, and that all directional indicators (arrows) have valid start and end points (no orphaned loops). Category:
ScientificProcess (Focus: Flow & Causality) Definition: Focuses on flows, steps, and interactions. Positive Strategy: Decompose into Directional (Arrows/Flow), Phase (State changes), and Interaction checks. Negative Check Strategy (Hallucination): Check for flow logic conservation. Ensure the diagram depicts only the requested stages without hallucinated ...
-
[77]
A Scientific Image (generated based on a prompt)
-
[78]
Original Input Prompt: The full text description used to generate the image (for context)
-
[79]
SciIR 33 Evaluation Criteria For each question in the checklist, perform the following steps:
Validation Checklist (JSON) containing specific questions. SciIR 33 Evaluation Criteria For each question in the checklist, perform the following steps:
-
[80]
Visual Evidence Retrieval: Look at the image to find the specific element mentioned in the question
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.