FacePlex: Full-Duplex Joint Speech-Facial Motion Generation for Conversational Avatars
Pith reviewed 2026-06-30 06:36 UTC · model grok-4.3
The pith
FacePlex generates speech tokens and facial motion tokens jointly at every streaming step for online conversational avatars.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
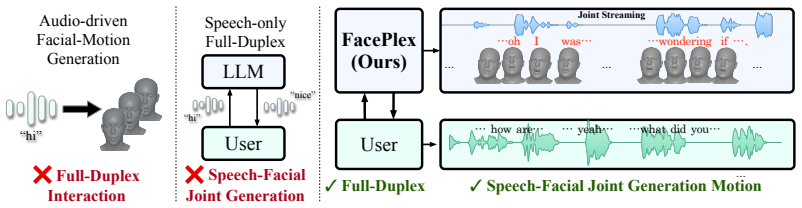
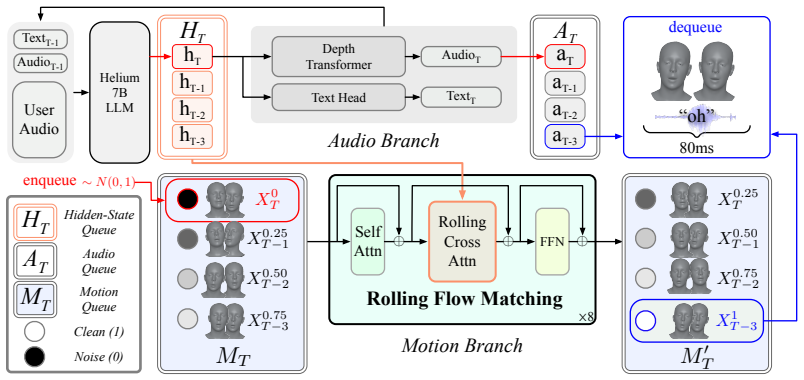
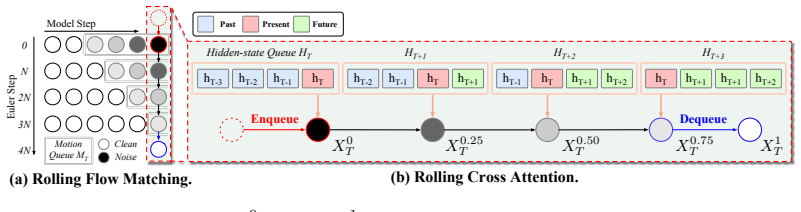
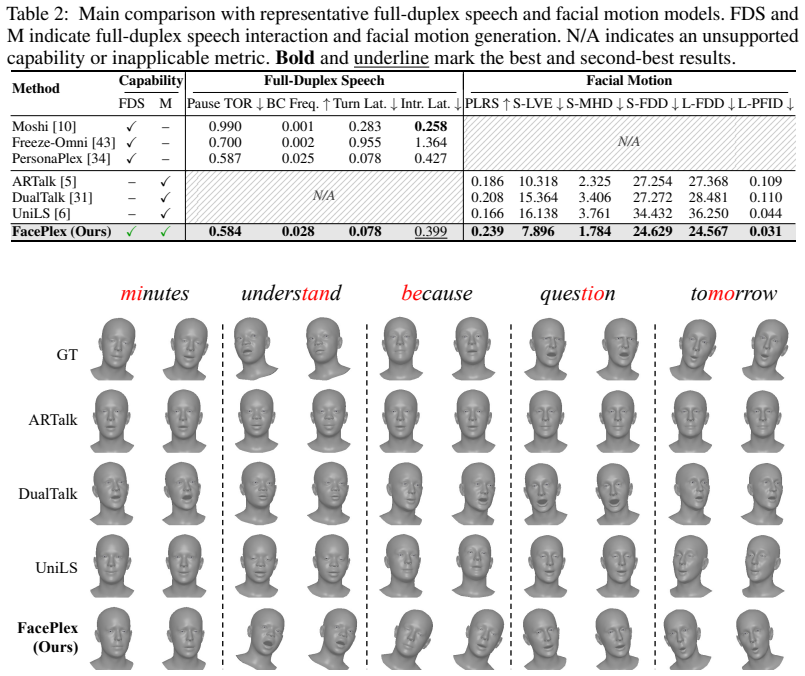
FacePlex is a unified streaming framework for full-duplex joint speech-facial motion generation. It adapts flow matching through Rolling Flow Matching, which commits new motion frames at each streaming step, and couples audio and motion queues through Rolling Cross-Attention so that speech and facial motion condition each other progressively. This produces speech and motion tokens together every step under online constraints and improves lip-sync quality and motion fidelity over audio-driven baselines.
What carries the argument
Rolling Flow Matching and Rolling Cross-Attention, which together enable joint conditioning and incremental commitment of motion frames within a single streaming pipeline.
If this is right
- Full-duplex conversational avatars can run under continuous online constraints without separate audio and animation stages.
- Lip-sync quality and motion fidelity improve relative to models that animate a face from already-available audio.
- Speech and motion can mutually condition each other as generation proceeds rather than after one modality is complete.
- Ablation results isolate the contribution of the rolling mechanisms to the observed quality gains.
Where Pith is reading between the lines
- Avatar systems could move from post-hoc animation pipelines to single-stream joint generation, reducing cumulative delay in interactive settings.
- The same rolling commitment pattern might apply to additional modalities such as gesture or eye movement within the same framework.
- Real-time communication tools could adopt the joint output directly instead of routing audio through a separate facial animation module.
Load-bearing premise
Jointly producing speech tokens and facial motion tokens at every streaming step via the rolling mechanisms is both feasible and superior to separate speech-only or audio-driven systems.
What would settle it
A live streaming test in which an audio-first pipeline followed by separate motion generation matches or exceeds FacePlex on measured lip-sync error and motion naturalness while meeting the same latency bound.
Figures



read the original abstract
Natural face-to-face conversation requires real-time speech generation together with synchronized facial motion. Existing systems only partially address this problem: speech-only full-duplex models can generate speech in real time but do not produce facial motion, while audio-driven facial motion models animate a face from already available audio rather than jointly generating speech and motion online. To bridge this gap, we first formalize full-duplex joint speech-facial motion generation, where speech tokens and facial motion tokens are produced together every step. Building on this formulation, we propose FacePlex, a unified streaming framework with two key components. First, Rolling Flow Matching adapts flow matching to online motion generation by committing new motion frames at each streaming step. Second, Rolling Cross-Attention couples the streaming audio queue with the motion queue, allowing speech and facial motion to condition each other as generation progresses. Through extensive experiments, ablation studies, and a user study, we show that FacePlex enables full-duplex joint speech-facial motion generation under online streaming constraints, while achieving stronger lip-sync quality and motion fidelity than audio-driven facial motion baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to formalize full-duplex joint speech-facial motion generation and proposes FacePlex, a streaming framework using Rolling Flow Matching and Rolling Cross-Attention to jointly generate speech and facial motion tokens in real time. It asserts through experiments, ablations, and a user study that it enables this under online constraints and outperforms audio-driven baselines in lip-sync and motion fidelity.
Significance. If substantiated, this would represent a meaningful advance in conversational AI avatars by addressing the joint real-time generation of speech and synchronized facial motion, which existing systems handle separately. The rolling adaptations of flow matching and cross-attention could influence streaming generative models more broadly.
major comments (1)
- [Abstract] The abstract asserts superior performance from experiments, ablations, and a user study, but provides no quantitative results, baselines, or methodological details; without these, the support for the central claim cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for their feedback on the abstract. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts superior performance from experiments, ablations, and a user study, but provides no quantitative results, baselines, or methodological details; without these, the support for the central claim cannot be assessed.
Authors: We acknowledge that the abstract does not include specific quantitative results, baseline names, or methodological details. This is standard for abstracts due to length limits, with full details (including lip-sync metrics, motion fidelity comparisons to audio-driven baselines, ablation studies, and user study outcomes) provided in the Experiments and Results sections of the manuscript. To strengthen the abstract's support for the claims, we will revise it to include one or two key quantitative highlights from the experiments. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description formalize full-duplex joint generation as a new problem statement and introduce Rolling Flow Matching plus Rolling Cross-Attention as adaptations of established flow matching and attention mechanisms. No equations, fitted parameters, or self-citations are shown that would reduce any claimed prediction or result to an input quantity defined by the authors' own prior work. The derivation chain remains self-contained against external benchmarks such as standard flow matching and attention techniques, with validation via experiments rather than definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.22554 (2025) 4, 5, 22, 29
Vasu Agrawal, Akinniyi Akinyemi, Kathryn Alvero, Morteza Behrooz, Julia Buffalini, Fabio Maria Carlucci, Joy Chen, Junming Chen, Zhang Chen, Shiyang Cheng, et al. Seamless interaction: Dyadic audiovisual motion modeling and large-scale dataset.arXiv preprint arXiv:2506.22554, 2025
-
[2]
Wiley- Interscience, 2000
John C Bellamy.Digital Telephony (Wiley Series in Telecommunications and Signal Processing). Wiley- Interscience, 2000
2000
-
[3]
Percep- tually accurate 3d talking head generation: New definitions, speech-mesh representation, and evaluation metrics
Lee Chae-Yeon, Oh Hyun-Bin, Han EunGi, Kim Sung-Bin, Suekyeong Nam, and Tae-Hyun Oh. Percep- tually accurate 3d talking head generation: New definitions, speech-mesh representation, and evaluation metrics. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21065–21074, 2025
2025
-
[4]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
2024
-
[5]
Artalk: Speech-driven 3d head animation via autoregressive model
Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, and Tatsuya Harada. Artalk: Speech-driven 3d head animation via autoregressive model. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–9, 2025
2025
-
[6]
Xuangeng Chu, Ruicong Liu, Yifei Huang, Yun Liu, Yichen Peng, and Bo Zheng. Unils: End-to-end audio-driven avatars for unified listening and speaking.arXiv preprint arXiv:2512.09327, 2025
-
[7]
Using uh and um in spontaneous speaking.Cognition, 84(1):73–111, 2002
Herbert H Clark and Jean E Fox Tree. Using uh and um in spontaneous speaking.Cognition, 84(1):73–111, 2002
2002
-
[8]
Capture, learning, and synthesis of 3d speaking styles
Daniel Cudeiro, Timo Bolkart, Cassidy Laidlaw, Anurag Ranjan, and Michael J Black. Capture, learning, and synthesis of 3d speaking styles. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10101–10111, 2019
2019
-
[9]
Emotional speech-driven animation with content-emotion disentanglement
Radek Danˇeˇcek, Kiran Chhatre, Shashank Tripathi, Yandong Wen, Michael Black, and Timo Bolkart. Emotional speech-driven animation with content-emotion disentanglement. InSIGGRAPH Asia 2023 Conference Papers, pages 1–13, 2023
2023
-
[10]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Stable audio open
Zach Evans, Julian D Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. Stable audio open. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[12]
Faceformer: Speech-driven 3d facial animation with transformers
Yingruo Fan, Zhaojiang Lin, Jun Saito, Wenping Wang, and Taku Komura. Faceformer: Speech-driven 3d facial animation with transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18770–18780, 2022
2022
-
[13]
Pauses, gaps and overlaps in conversations.Journal of Phonetics, 38(4): 555–568, 2010
Mattias Heldner and Jens Edlund. Pauses, gaps and overlaps in conversations.Journal of Phonetics, 38(4): 555–568, 2010
2010
-
[14]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[15]
Audio-driven facial animation by joint end-to-end learning of pose and emotion.ACM Transactions on Graphics (ToG), 36(4):1–12, 2017
Tero Karras, Timo Aila, Samuli Laine, Antti Herva, and Jaakko Lehtinen. Audio-driven facial animation by joint end-to-end learning of pose and emotion.ACM Transactions on Graphics (ToG), 36(4):1–12, 2017
2017
-
[16]
Forgotten little words: How backchannels and particles may facilitate speech planning in conversation?Frontiers in Psychology, 11:593671, 2020
Birgit Knudsen, Ava Creemers, and Antje S Meyer. Forgotten little words: How backchannels and particles may facilitate speech planning in conversation?Frontiers in Psychology, 11:593671, 2020
2020
-
[17]
Streamdiffusion: A pipeline-level solution for real-time interactive generation
Akio Kodaira, Chenfeng Xu, Toshiki Hazama, Takanori Yoshimoto, Kohei Ohno, Shogo Mitsuhori, Soichi Sugano, Hanying Cho, Zhijian Liu, Masayoshi Tomizuka, et al. Streamdiffusion: A pipeline-level solution for real-time interactive generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12371–12380, 2025
2025
-
[18]
Turn-taking in human communication–origins and implications for language process- ing.Trends in cognitive sciences, 20(1):6–14, 2016
Stephen C Levinson. Turn-taking in human communication–origins and implications for language process- ing.Trends in cognitive sciences, 20(1):6–14, 2016. 10
2016
-
[19]
Tianye Li, Timo Bolkart, Michael. J. Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4D scans.ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6): 194:1–194:17, 2017. URLhttps://doi.org/10.1145/3130800.3130813
-
[20]
Guan-Ting Lin, Jiachen Lian, Tingle Li, Qirui Wang, Gopala Anumanchipalli, Alexander H Liu, and Hung- yi Lee. Full-duplex-bench: A benchmark to evaluate full-duplex spoken dialogue models on turn-taking capabilities.arXiv preprint arXiv:2503.04721, 2025
-
[21]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Reactface: Online multiple appropriate facial reaction generation in dyadic interactions.IEEE Transactions on Visualization and Computer Graphics, 31(9):6190–6207, 2024
Cheng Luo, Siyang Song, Weicheng Xie, Micol Spitale, Zongyuan Ge, Linlin Shen, and Hatice Gunes. Reactface: Online multiple appropriate facial reaction generation in dyadic interactions.IEEE Transactions on Visualization and Computer Graphics, 31(9):6190–6207, 2024
2024
-
[24]
Cheng Luo, Jianghui Wang, Bing Li, Siyang Song, and Bernard Ghanem. Omniresponse: Online mul- timodal conversational response generation in dyadic interactions.arXiv preprint arXiv:2505.21724, 2025
-
[25]
Mit Press, 1998
Dominic W Massaro.Perceiving talking faces: From speech perception to a behavioral principle. Mit Press, 1998
1998
-
[26]
Hearing lips and seeing voices.Nature, 264(5588):746–748, 1976
Harry McGurk and John MacDonald. Hearing lips and seeing voices.Nature, 264(5588):746–748, 1976
1976
-
[27]
Eliya Nachmani, Alon Levkovitch, Roy Hirsch, Julian Salazar, Chulayuth Asawaroengchai, Soroosh Mariooryad, Ehud Rivlin, RJ Skerry-Ryan, and Michelle Tadmor Ramanovich. Spoken question answering and speech continuation using spectrogram-powered llm.arXiv preprint arXiv:2305.15255, 2023
-
[28]
Learning to listen: Modeling non-deterministic dyadic facial motion
Evonne Ng, Hanbyul Joo, Liwen Hu, Hao Li, Trevor Darrell, Angjoo Kanazawa, and Shiry Ginosar. Learning to listen: Modeling non-deterministic dyadic facial motion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20395–20405, 2022
2022
-
[29]
Can language models learn to listen? InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10083–10093, 2023
Evonne Ng, Sanjay Subramanian, Dan Klein, Angjoo Kanazawa, Trevor Darrell, and Shiry Ginosar. Can language models learn to listen? InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10083–10093, 2023
2023
-
[30]
Emotalk: Speech-driven emotional disentanglement for 3d face animation
Ziqiao Peng, Haoyu Wu, Zhenbo Song, Hao Xu, Xiangyu Zhu, Jun He, Hongyan Liu, and Zhaoxin Fan. Emotalk: Speech-driven emotional disentanglement for 3d face animation. InProceedings of the IEEE/CVF international conference on computer vision, pages 20687–20697, 2023
2023
-
[31]
Dualtalk: Dual-speaker interaction for 3d talking head conversations
Ziqiao Peng, Yanbo Fan, Haoyu Wu, Xuan Wang, Hongyan Liu, Jun He, and Zhaoxin Fan. Dualtalk: Dual-speaker interaction for 3d talking head conversations. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21055–21064, 2025
2025
-
[32]
A lip sync expert is all you need for speech to lip generation in the wild
KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Namboodiri, and CV Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. InProceedings of the 28th ACM international conference on multimedia, pages 484–492, 2020
2020
-
[33]
Meshtalk: 3d face animation from speech using cross-modality disentanglement
Alexander Richard, Michael Zollhöfer, Yandong Wen, Fernando De la Torre, and Yaser Sheikh. Meshtalk: 3d face animation from speech using cross-modality disentanglement. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1173–1182, 2021
2021
-
[34]
Rajarshi Roy, Jonathan Raiman, Sang-gil Lee, Teodor-Dumitru Ene, Robert Kirby, Sungwon Kim, Jaehyeon Kim, and Bryan Catanzaro. Personaplex: V oice and role control for full duplex conversational speech models.arXiv preprint arXiv:2602.06053, 2026
-
[35]
AudioPaLM: A Large Language Model That Can Speak and Listen
Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. Audiopalm: A large language model that can speak and listen.arXiv preprint arXiv:2306.12925, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Rolling diffusion models.arXiv preprint arXiv:2402.09470, 2024
David Ruhe, Jonathan Heek, Tim Salimans, and Emiel Hoogeboom. Rolling diffusion models.arXiv preprint arXiv:2402.09470, 2024
-
[37]
A simplest systematics for the organization of turn-taking for conversation.language, 50(4):696–735, 1974
Harvey Sacks, Emanuel A Schegloff, and Gail Jefferson. A simplest systematics for the organization of turn-taking for conversation.language, 50(4):696–735, 1974. 11
1974
-
[38]
Universals and cultural variation in turn-taking in conversation.Proceedings of the National Academy of Sciences, 106(26): 10587–10592, 2009
Tanya Stivers, Nicholas J Enfield, Penelope Brown, Christina Englert, Makoto Hayashi, Trine Heinemann, Gertie Hoymann, Federico Rossano, Jan Peter De Ruiter, Kyung-Eun Yoon, et al. Universals and cultural variation in turn-taking in conversation.Proceedings of the National Academy of Sciences, 106(26): 10587–10592, 2009
2009
-
[39]
Visual contribution to speech intelligibility in noise.The journal of the acoustical society of america, 26(2):212–215, 1954
William H Sumby and Irwin Pollack. Visual contribution to speech intelligibility in noise.The journal of the acoustical society of america, 26(2):212–215, 1954
1954
-
[40]
Diffposetalk: Speech-driven stylistic 3d facial animation and head pose generation via diffusion models
Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Lin, Jenny Sheng, Yu-Hui Wen, Minjing Yu, and Yong-jin Liu. Diffposetalk: Speech-driven stylistic 3d facial animation and head pose generation via diffusion models. ACM Transactions on Graphics (ToG), 43(4):1–9, 2024
2024
-
[41]
Improving and generalizing flow-based generative models with minibatch optimal transport.Transactions on Machine Learning Research
Alexander Tong, Kilian FATRAS, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector-Brooks, Guy Wolf, and Yoshua Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.Transactions on Machine Learning Research
-
[42]
Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen llm
Xiong Wang, Yangze Li, Chaoyou Fu, Yunhang Shen, Lei Xie, Ke Li, Xing Sun, and Long Ma. Freeze- omni: A smart and low latency speech-to-speech dialogue model with frozen llm.arXiv preprint arXiv:2411.00774, 2024
-
[43]
Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen LLM
Xiong Wang, Yangze Li, Chaoyou Fu, Yike Zhang, Yunhang Shen, Lei Xie, Ke Li, Xing Sun, and Long MA. Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen LLM. In F orty-second International Conference on Machine Learning, 2025. URL https://openreview.net/ forum?id=s1EImzs5Id
2025
-
[44]
Codetalker: Speech-driven 3d facial animation with discrete motion prior
Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, and Tien-Tsin Wong. Codetalker: Speech-driven 3d facial animation with discrete motion prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12780–12790, 2023
2023
-
[45]
On getting a word in edgewise
Victor H Yngve. On getting a word in edgewise. InPapers from the sixth regional meeting Chicago Linguistic Society, April 16-18, 1970, Chicago Linguistic Society, Chicago, pages 567–578, 1970
1970
-
[46]
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 15757–15773, 2023
2023
-
[47]
Omniflatten: An end-to-end gpt model for seamless voice conversation
Qinglin Zhang, Luyao Cheng, Chong Deng, Qian Chen, Wen Wang, Siqi Zheng, Jiaqing Liu, Hai Yu, Chao-Hong Tan, Zhihao Du, et al. Omniflatten: An end-to-end gpt model for seamless voice conversation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 14570–14580, 2025
2025
-
[48]
Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation
Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8652–8661, 2023
2023
-
[49]
Responsive listening head generation: a benchmark dataset and baseline
Mohan Zhou, Yalong Bai, Wei Zhang, Ting Yao, Tiejun Zhao, and Tao Mei. Responsive listening head generation: a benchmark dataset and baseline. InEuropean conference on computer vision, pages 124–142. Springer, 2022
2022
-
[50]
Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis, and Dingzeyu Li. Makelttalk: speaker-aware talking-head animation.ACM Transactions On Graphics (TOG), 39(6):1–15, 2020. 12 In this Appendix, we provide supplementary details and supporting analyses for FacePlex as follows: A. Data Construction. . . . . . . . . . . . . . . . . ....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.