Predicting Timbre Traits for Interpretable Assessment of Musical Sound Synthesizers
Pith reviewed 2026-06-30 04:58 UTC · model grok-4.3
The pith
A neural timbre trait predictor matches human ratings at r=0.66 and ranks synthesizer variants identically to FAD.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present a timbre trait predictor that uses a frozen CLAP audio neural embedding and a shallow learnable component trained on human timbre judgments for 31 instruments. This model correlates with human ratings at r=0.66 and, when used to evaluate TokenSynth, yields MAE-based rankings that match those from FAD while enabling qualitative analysis of isolated sounds to identify needed improvements in particular timbral dimensions.
What carries the argument
The timbre trait predictor, which maps CLAP embeddings of audio to scores on 20 descriptive timbre traits via a shallow trainable layer.
Load-bearing premise
The model trained exclusively on real instrument recordings will accurately score synthesized sounds from TokenSynth without major domain shift or the need for retraining.
What would settle it
A new human listening study that rates TokenSynth outputs on the 20 timbre traits and finds that the predictor's MAE rankings diverge from both the human averages and the FAD rankings.
Figures


read the original abstract
Measuring neural audio synthesizers' performance is now routinely conducted using distribution based metrics such as the Fr\'echet Audio Distance (FAD). Although this metric can be correlated with human perception, it offers limited interpretability beyond ranking different approaches. In this paper, we introduce a deep neural timbre trait predictor composed of a pretrained audio neural embedding (CLAP), and a shallow learnable component. The latter is trained using the RWC musical instrument database and human judgments of 20 timbre descriptions (e.g., woody, percussive, rumbling, etc.) for 31 instruments. The resulting model shows strong correlation with average human ratings (r = 0.66, p < 0.001). We then demonstrate the benefit of this predictor for evaluating the performance of TokenSynth, a neural sound synthesizer. First, the Mean Absolute Error (MAE) computed over the set of generated sounds under different conditioning modalities of the model provides the same ranking as a FAD computed with the RWC database as a reference, suggesting that the proposed predictors are able to provide equivalent information on a distributional basis. Second, because the model is able to qualitatively analyze isolated sounds, we can determine which generated sounds could be improved and identify specific timbral dimensions that need adjustment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a timbre trait predictor using a pretrained CLAP audio embedding followed by a shallow learnable component. The shallow head is trained on the RWC musical instrument database paired with human ratings for 20 timbre descriptors (e.g., woody, percussive). On RWC data the model achieves r = 0.66 (p < 0.001) correlation with average human ratings. The predictor is then applied to TokenSynth-generated sounds under varying conditioning modalities; the resulting per-sound trait vectors yield a mean absolute error (MAE) ranking across modalities that matches the ranking obtained from Fréchet Audio Distance (FAD) computed against the RWC reference set. The authors argue that the trait-based MAE supplies equivalent distributional information to FAD while additionally enabling per-sound interpretability.
Significance. If the reported generalization holds, the work supplies a concrete, human-interpretable alternative (or complement) to black-box distributional metrics for neural synthesizer evaluation. The use of an existing pretrained embedding plus a lightweight trainable head, together with the explicit linkage of MAE rankings to FAD rankings, is a practical contribution that could be adopted by the audio-synthesis community.
major comments (2)
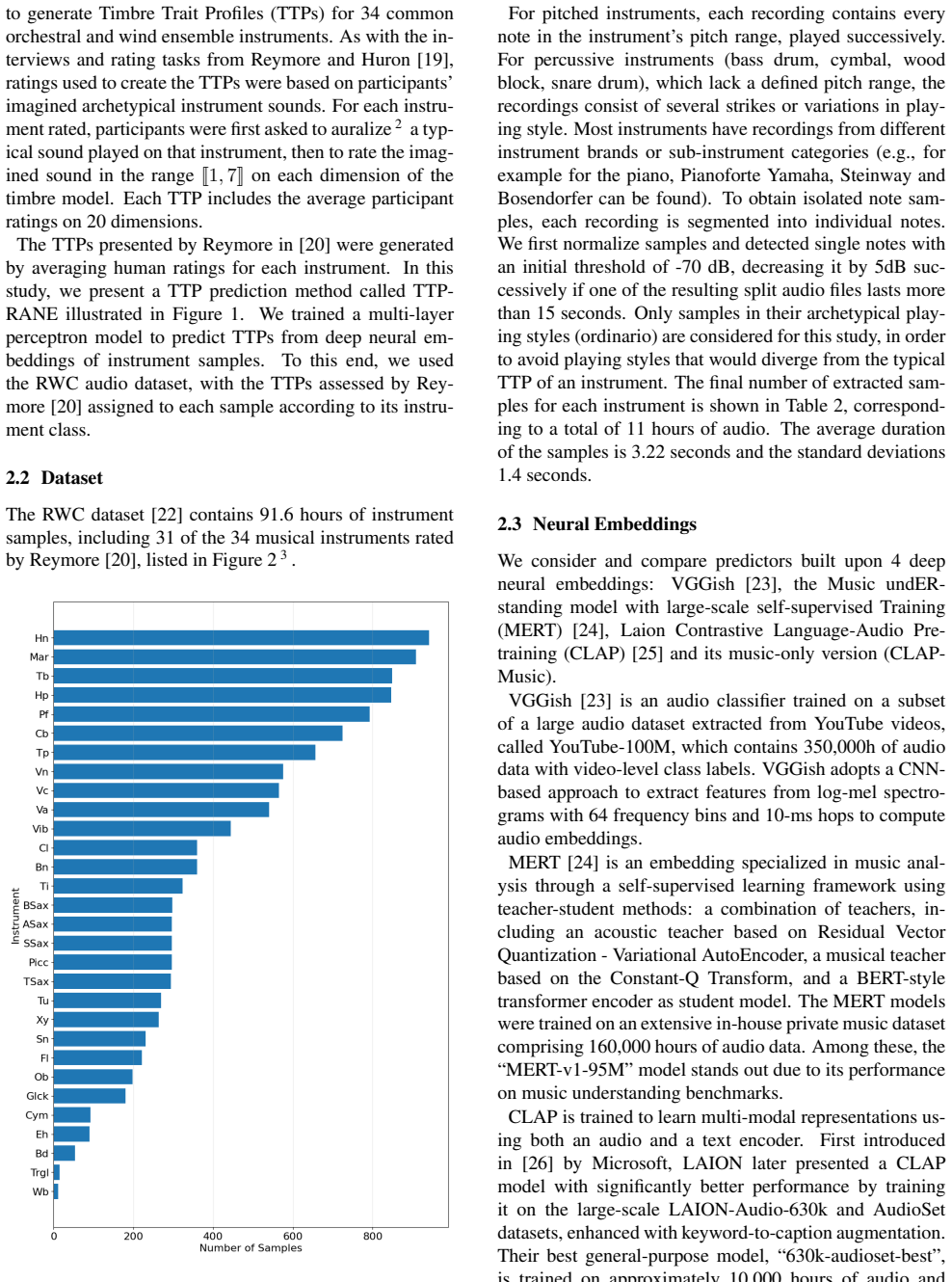
- [Evaluation on TokenSynth (implied § on application to generated sounds)] The central claim that MAE over predicted timbre traits supplies the same ranking as FAD (and therefore validates the predictor for synthetic audio) rests on the untested assumption that the RWC-trained shallow head produces reliable trait scores on TokenSynth outputs. No human ratings, cross-domain correlation, or even qualitative sanity check on the generated sounds are reported; the only quantitative result cited is the RWC correlation (r = 0.66).
- [Methods / Predictor training] Training, validation, and test splits for the shallow component, regularization details, and any error bars or statistical tests on the reported r = 0.66 are absent from the abstract and methods description, making it impossible to assess whether the correlation reflects genuine predictive power or overfitting to the 31-instrument RWC set.
minor comments (2)
- [Abstract] The abstract states that MAE “provides the same ranking as a FAD” but does not specify the exact FAD reference set, embedding model, or number of generated samples per conditioning modality; these details are required for reproducibility.
- [Predictor architecture] Notation for the 20 timbre traits and the precise definition of the shallow learnable component (linear layer? MLP?) should be given explicitly, together with the loss function used to fit the human ratings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: The central claim that MAE over predicted timbre traits supplies the same ranking as FAD (and therefore validates the predictor for synthetic audio) rests on the untested assumption that the RWC-trained shallow head produces reliable trait scores on TokenSynth outputs. No human ratings, cross-domain correlation, or even qualitative sanity check on the generated sounds are reported; the only quantitative result cited is the RWC correlation (r = 0.66).
Authors: We agree that the manuscript provides no direct human validation or qualitative checks on TokenSynth outputs, relying instead on the observed agreement between trait-based MAE rankings and FAD rankings as indirect evidence of applicability. This constitutes a genuine limitation of the current experiments. In revision we will add an explicit discussion of this assumption and include qualitative descriptions of trait predictions on selected generated examples to provide a basic sanity check. revision: partial
-
Referee: Training, validation, and test splits for the shallow component, regularization details, and any error bars or statistical tests on the reported r = 0.66 are absent from the abstract and methods description, making it impossible to assess whether the correlation reflects genuine predictive power or overfitting to the 31-instrument RWC set.
Authors: The full methods section describes the 5-fold cross-validation procedure, L2 regularization on the shallow head, and the Pearson correlation with associated p-value. Error bars on the correlation were not reported. We will expand the abstract and methods summary to include these details explicitly and add error bars in the revision. revision: yes
Circularity Check
No significant circularity; model trained on independent human ratings and applied externally
full rationale
The paper trains the CLAP + shallow predictor on RWC real-instrument recordings paired with 20 human timbre ratings, reports r=0.66 correlation against those ratings, then applies the fixed model to TokenSynth outputs to obtain per-sound trait vectors and distributional MAE. MAE ranking is compared to an independent FAD metric. No equations, self-citations, or steps reduce the reported correlation or MAE back to the fitted parameters by construction. Domain-shift risk is a validity concern, not circularity. No patterns from the enumerated list are present.
Axiom & Free-Parameter Ledger
free parameters (1)
- shallow learnable component weights
Reference graph
Works this paper leans on
-
[1]
Predicting Timbre Traits for Interpretable Assessment of Musical Sound Synthesizers
INTRODUCTION The evaluation of synthesized music instruments has be- come increasingly important as digital audio technology continues to advance. Whether for virtual instruments or AI-generated sounds, the ability to objectively measure how closely a synthesized sample matches its real-world counterpart is crucial for both developers and musicians. The s...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
sparkling/brilliant 11. hollow
-
[3]
focused/compact 12. woody
-
[4]
airy/breathy
pure/clear 13. airy/breathy
-
[5]
nasal/reedy
open 14. nasal/reedy
-
[6]
raspy/grainy
ringing/long decay 15. raspy/grainy
-
[7]
rumbling/low
resonant/vibrant 16. rumbling/low
-
[8]
direct/loud
sustained/even 17. direct/loud
-
[9]
percussive
soft/singing 18. percussive
-
[10]
shrill/noisy
watery/fluid 19. shrill/noisy
-
[11]
brassy/metallic Table 1: Dimensions of the Timbre Trait Profiles (TTP)
muted/veiled 20. brassy/metallic Table 1: Dimensions of the Timbre Trait Profiles (TTP). for the evaluation of generative instrument audio synthe- sis. The paper is organized as follows. Section 2.1 introduces the work of Reymore and what timbre traits are. Section 2 presents the training procedure and model performance. Section 3 presents the application...
-
[12]
imagine the sound of
PREDICTING TIMBRE TRAITS 2.1 Definition The 20 dimensions of the timbre qualia model proposed by Reymore and Huron [19] were empirically derived through a two-stage process. First, open-ended interviews with 23 musicians generated 77 descriptive categories of tim- bre qualia, which were refined via content analysis and pile sorting. Second, 460 musicians ...
-
[13]
one with one hidden layer of size 256, and 3) a funnel- shaped architecture with 2 hidden layers of sizes 256 and
-
[14]
Re- duce on Plateau
We use a learning rate of 0.01 scheduled with a “Re- duce on Plateau” scheduler, an Adam optimizer and a max- imum of 300 epochs per training. We apply early stopping on the validation set with a patience of 20 epochs; that is, the training stops when the loss of the predictions on the validation set does not decrease during 20 consecutive epochs, and we ...
-
[15]
Embeddings Distance: Computation of the distance 𝑑(Ei,t 𝑗)between the audio embeddingE i and the trait’s text embeddingt𝑗
-
[16]
Normalization: Divide the distance by max𝑖,𝑗(𝑑(Ei,t 𝑗))
-
[17]
2.6 Results To assess the performance of the evaluated models, we consider the Pearson correlation between the predicted TTPs and the ground truth TTPs
Prediction: Derive the predicted trait value as1− 𝑑(Ei,t 𝑗). 2.6 Results To assess the performance of the evaluated models, we consider the Pearson correlation between the predicted TTPs and the ground truth TTPs. Each element of the pre- diction array is the average of the predictions for a spe- cific timbre trait and instrument in the RWC dataset. As th...
-
[18]
CELLO”, “SNARE DRUM
ASSESSING TOKENSYNTH In this section, we demonstrate the potential of using the timbre trait predictor to assess the performance of a musi- cal instrument synthesizer: TokenSynth. 3.1 Overall Synthesis Assessment TokenSynth [21] is a neural synthesizer that lever- ages token-based audio representations to enable text- to-instrument synthesis. This synthes...
2000
-
[19]
We 1) demonstrate the 5 The sounds discussed here as well as others can be listened to via the companion page
DISCUSSION In this paper, we propose a new machine listening task: Timbre Traits Profiles prediction. We 1) demonstrate the 5 The sounds discussed here as well as others can be listened to via the companion page. effectiveness of a simple learnable reweighting of deep neural audio embeddings and 2) exemplify the use of TTP prediction for assessing the per...
-
[20]
Finally, while the TTP-RANE- CLAP model has been studied here for the sole evaluation of musical audio synthesizer, it may also be useful in mu- sic analysis
new deep neural architectures to improve our TTP pre- diction model and 2) new ways to condition or train musi- cal audio synthesizers using respectively a TTP-RANE in- spired conditioner or loss. Finally, while the TTP-RANE- CLAP model has been studied here for the sole evaluation of musical audio synthesizer, it may also be useful in mu- sic analysis. R...
-
[21]
Fr ´echet audio distance: A metric for evaluating music enhance- ment algorithms,
K. Kilgour, M. Zuluaga, D. Roblek, and al, “Fr ´echet audio distance: A metric for evaluating music enhance- ment algorithms,” inINTERSPEECH, 2019
2019
-
[22]
Correlation of fr´echet audio distance with human perception of en- vironmental audio is embedding dependent,
M. Tailleur, J. Lee, M. Lagrange, and al, “Correlation of fr´echet audio distance with human perception of en- vironmental audio is embedding dependent,” inEU- SIPCO, 2024
2024
-
[24]
Timbre as a multidimensional attribute of complex tones,
R. Plomp, “Timbre as a multidimensional attribute of complex tones,” inFrequency Analysis and Periodicity Detection in Hearing. Sijthoff, 1970
1970
-
[25]
Psychoacoustics and music: A report from michigan state university,
D. L. Wessel, “Psychoacoustics and music: A report from michigan state university,”PACE: Bulletin of the Computer Arts Society, 1973
1973
-
[26]
Multidimensional perceptual scaling of musical timbres,
J. M. Grey, “Multidimensional perceptual scaling of musical timbres,”The Journal of the Acoustical Society of America, 1977
1977
-
[27]
Perceptual scaling of synthesized musical timbres: Common dimensions, specificities, and latent subject classes,
S. McAdams, S. Winsberg, S. Donnadieu, and al, “Perceptual scaling of synthesized musical timbres: Common dimensions, specificities, and latent subject classes,”Psychological Research, 1995
1995
-
[28]
Instru- ment sound description in the context of MPEG-7,
G. Peeters, S. McAdams, and P. Herrera, “Instru- ment sound description in the context of MPEG-7,” in ICMC, 2000
2000
-
[29]
Release of timbral characterisation tools for semantically anno- tating non-musical content,
A. Pearce, S. Safavi, T. Brookes, and al, “Release of timbral characterisation tools for semantically anno- tating non-musical content,” AudioCommons, Report D5.8, 2019
2019
-
[30]
First prototype of timbral characterisation tools for semantically anno- tating non-musical content,
A. Pearce, T. Brookes, and R. Mason, “First prototype of timbral characterisation tools for semantically anno- tating non-musical content,” AudioCommons, Report D5.2, 2016
2016
-
[31]
Second prototype of timbral characterisation tools for seman- tically annotating non-musical content,
A. Pearce, S. Safavi, T. Brookes, and al, “Second prototype of timbral characterisation tools for seman- tically annotating non-musical content,” AudioCom- mons, Report D5.6, 2017
2017
-
[32]
The timbre toolbox: Audio descriptors of musical signals,
G. Peeters, B. Giordano, P. Susini, N. Misdariis, and al, “The timbre toolbox: Audio descriptors of musical signals,”Journal of the Acoustical Society of America, 2011
2011
-
[33]
Timbre toolbox- r2021a,
S. Kazazis and S. McAdams, “Timbre toolbox- r2021a,” 2023. [Online]. Available: https://github. com/MPCL-McGill/TimbreToolbox-R2021a
2023
-
[34]
Does timbral brightness scale with frequency and spectral centroid,
E. Schubert and J. Wolfe, “Does timbral brightness scale with frequency and spectral centroid,”Acustica, 2006
2006
-
[35]
Caetano, C
M. Caetano, C. Saitis, and K. Siedenburg,Audio Con- tent Descriptors of Timbre, 2019
2019
-
[36]
Per- ception and modeling of affective qualities of musical instrument sounds across pitch registers,
S. McAdams, C. Douglas, and N. N. Vempala, “Per- ception and modeling of affective qualities of musical instrument sounds across pitch registers,”Frontiers in Psychology, 2017
2017
-
[37]
Modeling noise-related timbre semantic categories of orchestral instrument sounds with audio features, pitch register, and instrument family,
L. Reymore, E. Beauvais-Lacasse, B. K. Smith, and al, “Modeling noise-related timbre semantic categories of orchestral instrument sounds with audio features, pitch register, and instrument family,”Frontiers in Psychol- ogy, 2022
2022
-
[38]
Timbre anal- ysis of music audio signals with convolutional neural networks,
J. Pons, O. Slizovskaia, R. Gong, and al, “Timbre anal- ysis of music audio signals with convolutional neural networks,” inEUSIPCO, 2017
2017
-
[39]
Using auditory imagery tasks to map the cognitive linguistic dimensions of musical instrument timbre qualia,
L. Reymore and D. Huron, “Using auditory imagery tasks to map the cognitive linguistic dimensions of musical instrument timbre qualia,”Psychomusicology: Music, Mind, and Brain, 2020
2020
-
[40]
Characterizing prototypical musical in- strument timbres with timbre trait profiles,
L. Reymore, “Characterizing prototypical musical in- strument timbres with timbre trait profiles,”Musicae Scientiae, 2021
2021
-
[41]
Tokensynth: A token- based neural synthesizer for instrument cloning and text-to-instrument,
K. Kim, J. Koo, S. Lee, and al, “Tokensynth: A token- based neural synthesizer for instrument cloning and text-to-instrument,”CoRR, 2025
2025
-
[42]
Rwc music database: Music genre database and musical instrument sound database,
M. Goto, H. Hashiguchi, T. Nishimura, and al, “Rwc music database: Music genre database and musical instrument sound database,” inISMIR, 2003. [Online]. Available: https://doi.org/10.5281/zenodo.1415536
-
[43]
Very deep convo- lutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convo- lutional networks for large-scale image recognition,” ITAIMLE, 2015
2015
-
[44]
Mert: Acous- tic music understanding model with large-scale self- supervised training,
Y . Li, R. Yuan, G. Zhang, and al, “Mert: Acous- tic music understanding model with large-scale self- supervised training,” inICLR, 2024
2024
-
[45]
Large-scale con- trastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,
Y . Wu, K. Chen, T. Zhang, and al, “Large-scale con- trastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inICASSP, 2024
2024
-
[46]
Clap: Learning audio concepts from natural language super- vision,
B. Elizalde, S. Deshmukh, M. A. Ismail, and al, “Clap: Learning audio concepts from natural language super- vision,”CoRR, 2022
2022
-
[47]
Adapting frechet audio distance for generative music evaluation,
A. Gui, H. Gamper, S. Braun, and al, “Adapting frechet audio distance for generative music evaluation,” in ICASSP, 2024
2024
-
[48]
Neural audio synthesis of musical notes with wavenet autoencoders,
J. Engel, C. Resnick, A. Roberts, and al, “Neural audio synthesis of musical notes with wavenet autoencoders,” JML, 2017
2017
-
[49]
C. Raffel, “Learning-based methods for comparing se- quences, with applications to audio-to-midi alignment and matching,” Ph.D. dissertation, 2016. [Online]. Available: https://doi.org/10.7916/D8N58MHV
-
[50]
Timbre semantic associations vary both between and within instruments: An empirical study incorporating register and pitch height,
L. Reymore, J. Noble, C. Saitis, C. Traube, and al, “Timbre semantic associations vary both between and within instruments: An empirical study incorporating register and pitch height,”Music Perception: An Inter- disciplinary Journal, 2023
2023
-
[51]
Variations in timbre qualia with register and dynamics in the oboe and french horn,
L. Reymore, “Variations in timbre qualia with register and dynamics in the oboe and french horn,”Empirical Musicology Review, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.