Set-Inclusive Uncertainty Modeling for Robust Brain Tumor Segmentation
Pith reviewed 2026-06-30 06:12 UTC · model grok-4.3
The pith
Modeling representations as Gaussians with mean regularization and set-inclusive variance scaling captures uncertainty from missing MRI modalities in brain tumor segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a probabilistic representation framework that models representations as Gaussian distributions, where their mean captures task information and their variance measures uncertainty from missing evidence. To make variance reflect information deficiency, we regularize the mean from each partial configuration toward its full-modality counterpart, while scaling the variance with the discrepancy between their aligned means. We further introduce a set-inclusive strategy that exploits the hierarchical structure of modality subsets and enforces an ordering constraint to maintain their consistent uncertainty relationships.
What carries the argument
Gaussian distributions for representations whose means are regularized from partial to full modality configurations and whose variances are scaled by mean discrepancy, subject to a set-inclusive ordering constraint on modality subsets.
If this is right
- The model produces superior segmentation accuracy over baselines across diverse missing-modality scenarios on BraTS 2018 and 2020.
- Variance values reflect the degree of information deficiency caused by absent modalities.
- Uncertainty relationships remain consistent across different subsets of available modalities due to the ordering constraint.
- The framework avoids encoding incomplete evidence into overconfident deterministic representations.
Where Pith is reading between the lines
- The same mean-regularization and variance-scaling approach could be tested on other multimodal medical imaging tasks such as cardiac or abdominal segmentation.
- Uncertainty maps produced by the model might be used in clinical workflows to flag cases where additional scans would most reduce segmentation error.
- A direct check of whether higher predicted variance on a given voxel predicts higher error rates when that modality is missing would provide an independent validation signal.
Load-bearing premise
That regularizing each partial-modality mean toward its full-modality counterpart and scaling variance by the resulting discrepancy, together with the set-inclusive ordering constraint, will make the variance accurately reflect the information lost from missing modalities.
What would settle it
On BraTS 2018 or 2020 test cases with held-out missing-modality combinations, if the method shows no gain in Dice or Hausdorff scores over strong deterministic baselines and its predicted variances fail to correlate with actual segmentation errors, the central modeling claim would be falsified.
Figures

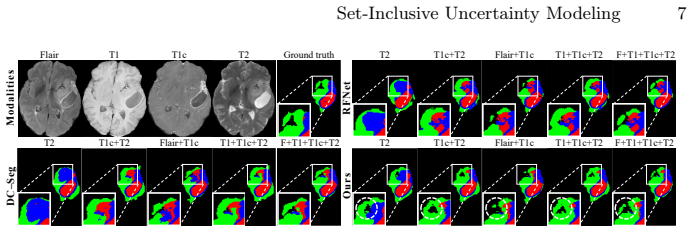
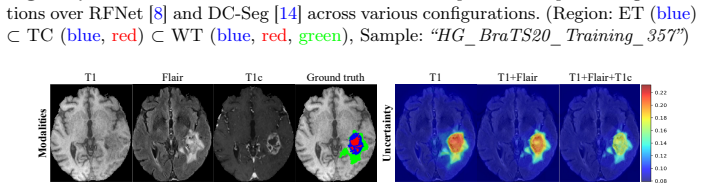


read the original abstract
Multimodal MRI is essential for accurate brain tumor segmentation. However, acquiring all modalities at inference is often challenging in practice, which causes intrinsic uncertainty due to unavoidable information loss. Without modeling this uncertainty, existing methods encode incomplete evidence into deterministic representations that appear plausible but lack reliability. In this regime, we propose a probabilistic representation framework that models representations as Gaussian distributions, where their mean captures task information and their variance measures uncertainty from missing evidence. To make variance reflect information deficiency, we regularize the mean from each partial configuration toward its full-modality counterpart, while scaling the variance with the discrepancy between their aligned means. We further introduce a set-inclusive strategy that exploits the hierarchical structure of modality subsets and enforces an ordering constraint to maintain their consistent uncertainty relationships. Extensive experiments on BraTS 2018 and 2020 demonstrate that our approach offers superior performance over baselines across diverse missing-modality scenarios. Code and model checkpoint are available at https://github.com/atlas-sky/SIUM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a probabilistic representation framework for robust brain tumor segmentation under missing MRI modalities. Representations are modeled as Gaussians where the mean encodes task-relevant information and the variance is intended to quantify uncertainty due to missing evidence. This is achieved by regularizing each partial-modality mean toward its full-modality counterpart and scaling the variance proportionally to the discrepancy between these aligned means; a set-inclusive strategy with an ordering constraint is introduced to enforce consistent uncertainty relationships across modality subsets. Extensive experiments on BraTS 2018 and 2020 are reported to demonstrate superior performance over baselines across diverse missing-modality scenarios.
Significance. If the core modeling assumptions hold, the approach could provide more reliable uncertainty estimates in clinical scenarios where not all modalities are available, addressing a practical limitation in multimodal medical imaging. The public release of code and checkpoints strengthens reproducibility.
major comments (3)
- [§3] §3 (Method), the variance scaling construction: the claim that scaling variance with the mean discrepancy causes variance to 'reflect information deficiency' is a central modeling assumption, yet the experiments report only segmentation metrics (Dice, etc.) with no direct validation such as correlation between learned variance and ground-truth information loss or ablation on whether discrepancy is dominated by missing evidence versus optimization artifacts.
- [§3.2] §3.2 (Set-inclusive strategy): the ordering constraint is presented as enforcing consistent uncertainty relationships across modality subsets, but no quantitative verification is provided that this constraint is satisfied in the trained models (e.g., empirical checks on variance ordering for nested modality sets).
- [§4] §4 (Experiments): while superiority on BraTS 2018/2020 is claimed across missing-modality scenarios, the evaluation lacks controls that isolate whether performance gains stem from the uncertainty modeling versus other implementation choices (e.g., the regularization strength or network architecture differences from baselines).
minor comments (2)
- [§3] Notation for the Gaussian parameters (mean and variance) should be introduced with explicit equations early in §3 to avoid ambiguity when referring to 'aligned means'.
- [§4] Figure captions for qualitative results should explicitly state which modality subsets are shown and whether the displayed uncertainty maps correspond to the proposed variance term.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method), the variance scaling construction: the claim that scaling variance with the mean discrepancy causes variance to 'reflect information deficiency' is a central modeling assumption, yet the experiments report only segmentation metrics (Dice, etc.) with no direct validation such as correlation between learned variance and ground-truth information loss or ablation on whether discrepancy is dominated by missing evidence versus optimization artifacts.
Authors: We acknowledge that direct validation of the central modeling assumption would strengthen the presentation. While the consistent gains in segmentation metrics under missing-modality conditions provide supporting evidence for the design, we agree that additional analysis is needed. In the revised manuscript we will add an ablation correlating learned variance with mean discrepancy and an analysis separating the contribution of missing evidence from optimization effects, to be placed in Section 4. revision: yes
-
Referee: [§3.2] §3.2 (Set-inclusive strategy): the ordering constraint is presented as enforcing consistent uncertainty relationships across modality subsets, but no quantitative verification is provided that this constraint is satisfied in the trained models (e.g., empirical checks on variance ordering for nested modality sets).
Authors: The ordering constraint is imposed via the hierarchical loss during training. We recognize the value of post-hoc empirical verification. We will include quantitative checks confirming that variance ordering holds for nested modality subsets in the trained models; these results will be added to the experiments section of the revised paper. revision: yes
-
Referee: [§4] §4 (Experiments): while superiority on BraTS 2018/2020 is claimed across missing-modality scenarios, the evaluation lacks controls that isolate whether performance gains stem from the uncertainty modeling versus other implementation choices (e.g., the regularization strength or network architecture differences from baselines).
Authors: The reported baselines follow the original implementations in the literature, and our backbone is chosen for comparability. To more clearly isolate the contribution of the uncertainty modeling and set-inclusive components, we will add ablation studies on regularization strength together with architecture-matched comparisons in the revised experiments section. revision: yes
Circularity Check
Variance scaling by mean discrepancy enforces reflection of information deficiency by construction
specific steps
-
self definitional
[Abstract]
"To make variance reflect information deficiency, we regularize the mean from each partial configuration toward its full-modality counterpart, while scaling the variance with the discrepancy between their aligned means."
The paper states its goal (variance reflects information deficiency) and immediately defines the mechanism (scale variance by mean discrepancy) to achieve that goal. The asserted property of the variance is therefore true by the construction of the representation rather than derived from first principles or validated against an independent measure of information loss.
full rationale
The paper's core claim is that variance measures uncertainty from missing evidence. This is achieved by an explicit design rule that scales variance with the discrepancy between partial-configuration and full-modality means after regularization. The relationship therefore holds by the model's definitional construction rather than by independent derivation or external validation. The set-inclusive ordering constraint adds structure but inherits the same definitional premise. No self-citations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text, so circularity is partial and localized to the uncertainty modeling step.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Representations can be modeled as Gaussian distributions where the mean captures task information and the variance measures uncertainty from missing evidence.
- ad hoc to paper Regularizing partial-configuration means toward full-modality counterparts and scaling variance with mean discrepancy will make variance reflect information deficiency.
- ad hoc to paper The hierarchical structure of modality subsets can be exploited with an ordering constraint to maintain consistent uncertainty relationships.
Reference graph
Works this paper leans on
-
[1]
In: ISBI
Baek, S., Sim, J., Dere, M., et al.: Modality-agnostic style transfer for holistic feature imputation. In: ISBI. pp. 1–5. IEEE (2024)
2024
-
[2]
In: MICCAI
Baek, S., Sim, J., Wu, G., et al.: Ocl: Ordinal contrastive learning for imputating features with progressive labels. In: MICCAI. pp. 334–344. Springer (2024)
2024
-
[3]
Baid, U., Ghodasara, S., Mohan, S., et al.: The rsna-asnr-miccai brats 2021 bench- mark on brain tumor segmentation and radiogenomic classification. arXiv preprint arXiv:2107.02314 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Scientific data 9(1), 453 (2022)
Bakas, S., Sako, C., Akbari, H., et al.: The university of pennsylvania glioblastoma (upenn-gbm) cohort: advanced mri, clinical, genomics, & radiomics. Scientific data 9(1), 453 (2022)
2022
-
[5]
JMI7(3), 031505– 031505 (2020)
Bakas, S., Shukla, G., Akbari, H., et al.: Overall survival prediction in glioblastoma patients using structural magnetic resonance imaging (mri): advanced radiomic features may compensate for lack of advanced mri modalities. JMI7(3), 031505– 031505 (2020)
2020
-
[6]
PLoS One12(5), e0177135 (2017)
Blystad, I., Warntjes, J.M., Smedby, Ö., et al.: Quantitative mri for analysis of peritumoral edema in malignant gliomas. PLoS One12(5), e0177135 (2017)
2017
-
[7]
Radiology299(2), 313–323 (2021)
Conte, G.M., Weston, A.D., Vogelsang, D.C., et al.: Generative adversarial net- works to synthesize missing t1 and flair mri sequences for use in a multisequence brain tumor segmentation model. Radiology299(2), 313–323 (2021)
2021
-
[8]
In: ICCV
Ding, Y., Yu, X., Yang, Y.: Rfnet: Region-aware fusion network for incomplete multi-modal brain tumor segmentation. In: ICCV. pp. 3975–3984 (2021)
2021
-
[9]
In: MICCAI
Dorent, R., Joutard, S., Modat, M., et al.: Hetero-modal variational encoder- decoder for joint modality completion and segmentation. In: MICCAI. pp. 74–82. Springer (2019) 10 S. Baek & J. Park et al
2019
-
[10]
Medical image analysis35, 18–31 (2017)
Havaei, M., Davy, A., Warde-Farley, D., Biard, A., Courville, A., Bengio, Y., Pal, C., Jodoin, P.M., Larochelle, H.: Brain tumor segmentation with deep neural net- works. Medical image analysis35, 18–31 (2017)
2017
-
[11]
Procedia computer science102, 317–324 (2016)
Işın, A., Direkoğlu, C., Şah, M.: Review of mri-based brain tumor image segmenta- tion using deep learning methods. Procedia computer science102, 317–324 (2016)
2016
-
[12]
Medical image analysis 36, 61–78 (2017)
Kamnitsas, K., Ledig, C., Newcombe, V.F., et al.: Efficient multi-scale 3d cnn with fully connected crf for accurate brain lesion segmentation. Medical image analysis 36, 61–78 (2017)
2017
-
[13]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
In: MICCAI
Li, H., Li, Z., Mao, Y., et al.: Dc-seg: Disentangled contrastive learning for brain tumor segmentation with missing modalities. In: MICCAI. pp. 138–148. Springer (2025)
2025
-
[15]
In: AAAI
Liu, H., Wei, D., Lu, D., et al.: M3ae: multimodal representation learning for brain tumor segmentation with missing modalities. In: AAAI. vol. 37, pp. 1657–1665 (2023)
2023
-
[16]
Ecology 26, 297–302 (1945)
Lr, D.: Measures of the amount of ecologic association between species. Ecology 26, 297–302 (1945)
1945
-
[17]
TMI34(10), 1993–2024 (2014)
Menze, B.H., Jakab, d., Bauer, S., et al.: The multimodal brain tumor image seg- mentation benchmark (brats). TMI34(10), 1993–2024 (2014)
1993
-
[18]
TMI35(5), 1240–1251 (2016)
Pereira, S., Pinto, A., Alves, V., et al.: Brain tumor segmentation using convolu- tional neural networks in mri images. TMI35(5), 1240–1251 (2016)
2016
-
[19]
TMI39(4), 1170–1183 (2019)
Sharma,A.,Hamarneh,G.:Missingmripulsesequencesynthesisusingmulti-modal generative adversarial network. TMI39(4), 1170–1183 (2019)
2019
-
[20]
NeurIPS 30(2017)
Vaswani, A., Shazeer, N., Parmar, N., et al.: Attention is all you need. NeurIPS 30(2017)
2017
-
[21]
In: MICCAI
Zhang, Y., He, N., Yang, J., et al.: mmformer: Multimodal medical transformer for incomplete multimodal learning of brain tumor segmentation. In: MICCAI. pp. 107–117. Springer (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.