Grasp-Oriented Non-Prehensile Manipulation via Learning a Graspability Field
Pith reviewed 2026-06-30 05:14 UTC · model grok-4.3
The pith
Learning a graspability field lets one reinforcement learning policy reconfigure objects for grasping without predefined poses or external planners.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
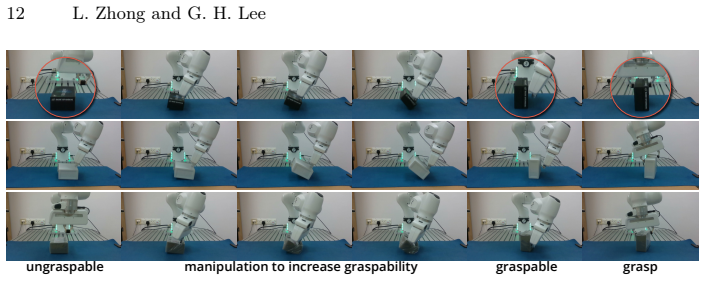
A graspability field constructed from synthesized grasps supplies a scalar measure of how suitable any object configuration is for grasp execution. Training a reinforcement learning policy to maximize this measure produces a single controller that manipulates objects into graspable states and automatically switches to grasping once the field value indicates readiness, eliminating the need for target poses, external planners, or manually specified stopping conditions. The same field values correlate with real-world grasp success.
What carries the argument
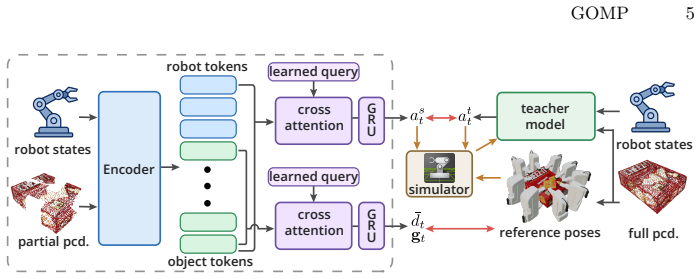
The graspability field: a scalar function over object configurations that quantifies grasp feasibility, derived from a set of synthesized grasps and used both as reinforcement learning reward and termination criterion.
If this is right
- A single policy suffices for the full sequence from non-prehensile reconfiguration to grasp execution.
- Manipulation terminates automatically when the graspability field reaches a suitable threshold.
- No separate external planner or manually chosen target pose is required.
- The learned field values serve as a predictor of real-world grasp success.
Where Pith is reading between the lines
- The same field-based objective could be applied to prepare objects for other actions besides grasping.
- Replacing discrete pose targets with continuous feasibility fields may simplify other multi-stage robotic tasks.
- Expanding the set of synthesized grasps to cover more object geometries would test how far the current construction generalizes.
Load-bearing premise
The graspability field built from synthesized grasps accurately reflects real-world grasp feasibility and transfers from simulation to physical robots.
What would settle it
Physical-robot trials in which the policy's graspability values show no correlation with measured grasp success rates would falsify the claim that the field captures usable grasp feasibility.
Figures



read the original abstract
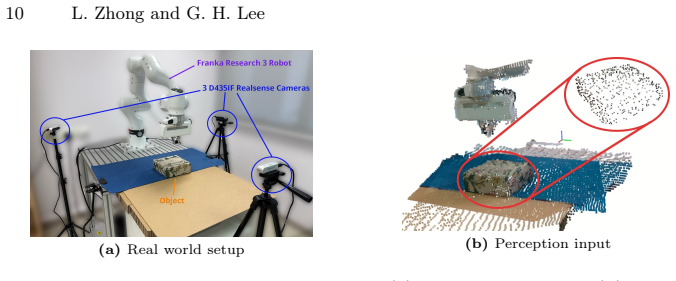
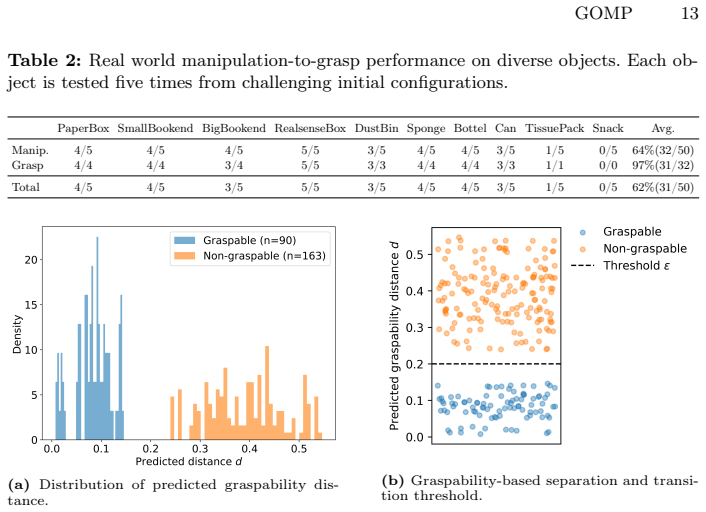
Non-prehensile manipulation is often used as a preparatory step for robotic grasping, yet existing approaches typically require a predefined target object pose. In practice, however, objects admit multiple graspable configurations and the desired pose is not known in advance. We reformulate non-prehensile manipulation for grasping as optimizing an object centric graspability objective rather than reaching a specific pose. We construct a graspable set from synthesized grasps and define a graspability field that measures how suitable an object configuration is for successful grasp execution. The scalar measure provides a dense learning signal for reinforcement learning and determines when to terminate manipulation. This yields a closed-loop manipulation-to-grasp pipeline driven by a single policy. Experiments in simulation and on a real robot show that the policy reliably reconfigures objects into graspable states and transitions to grasping without external planners or manually specified stopping conditions. The predicted graspability distance correlates with real world grasp success, which indicates that the learned representation captures grasp feasibility of object configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes reformulating non-prehensile manipulation as optimization of an object-centric graspability objective rather than a target pose. A graspability field is constructed from synthesized grasps to supply a dense RL reward signal and an automatic termination condition, yielding a single closed-loop policy that reconfigures objects into graspable states and transitions to grasping. Experiments in simulation and on a physical robot are reported to show reliable performance and correlation between the predicted graspability distance and real-world grasp success.
Significance. If the generalization claims hold, the work offers a unified objective for preparatory manipulation and grasping that removes the need for separate pose planners or hand-crafted stopping rules, which could simplify pipelines for robotic manipulation in unstructured settings.
major comments (3)
- [Abstract] Abstract: the central claim that the graspability field 'captures grasp feasibility of object configurations' and enables reliable real-robot transfer rests on correlation with grasp success, yet no quantitative metrics (e.g., Pearson coefficient, success-rate tables, or failure-case analysis) are supplied to establish that the correlation is not driven by shared simulation artifacts.
- [§3] The construction of the graspable set from synthesized grasps (presumably §3) defines the field via simulation-based synthesis; any unmodeled mismatch in friction, contact compliance, or sensor noise creates a domain gap that directly affects both the RL reward and the termination signal, yet the manuscript provides no ablation on domain-randomization strength or sim-to-real transfer metrics.
- [§5] Experiments section: the assertion that the policy 'transitions to grasping without external planners or manually specified stopping conditions' is load-bearing for the closed-loop contribution, but no comparison against baselines that use explicit termination or separate grasp planners is reported, leaving the advantage of the single-policy formulation unquantified.
minor comments (2)
- [§3] Notation for the graspability scalar and distance should be introduced with a clear equation reference rather than prose description only.
- [§5] Figure captions for real-robot trials should list the number of objects, trials per object, and success criteria to allow reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which help clarify the strength of our claims on correlation, domain transfer, and the benefits of the unified policy. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the graspability field 'captures grasp feasibility of object configurations' and enables reliable real-robot transfer rests on correlation with grasp success, yet no quantitative metrics (e.g., Pearson coefficient, success-rate tables, or failure-case analysis) are supplied to establish that the correlation is not driven by shared simulation artifacts.
Authors: We agree that the abstract would benefit from explicit quantitative support. The manuscript body reports real-robot grasp success rates conditioned on graspability values, but we will revise the abstract to include a Pearson correlation coefficient between predicted graspability distance and observed grasp success, plus a table of success rates across binned graspability thresholds in both simulation and on the physical robot. Failure cases will also be briefly analyzed to address potential simulation artifacts. revision: yes
-
Referee: [§3] The construction of the graspable set from synthesized grasps (presumably §3) defines the field via simulation-based synthesis; any unmodeled mismatch in friction, contact compliance, or sensor noise creates a domain gap that directly affects both the RL reward and the termination signal, yet the manuscript provides no ablation on domain-randomization strength or sim-to-real transfer metrics.
Authors: The current manuscript demonstrates successful sim-to-real transfer through physical robot experiments, but we concur that dedicated ablations on randomization strength are absent. We will add an ablation varying domain randomization parameters (friction, compliance, noise) and report the resulting sim-to-real success rates and graspability prediction accuracy to quantify robustness to the domain gap. revision: yes
-
Referee: [§5] Experiments section: the assertion that the policy 'transitions to grasping without external planners or manually specified stopping conditions' is load-bearing for the closed-loop contribution, but no comparison against baselines that use explicit termination or separate grasp planners is reported, leaving the advantage of the single-policy formulation unquantified.
Authors: The experiments show reliable closed-loop behavior on the real robot using only the learned graspability signal for both reward and termination. However, we acknowledge that the advantage over pipelines with explicit termination rules remains unquantified without direct baselines. Adding such comparisons would require substantial additional implementation and fair metric alignment; we will therefore expand the discussion section to address this limitation and identify it as future work rather than performing new baseline experiments in the revision. revision: partial
Circularity Check
No circularity: graspability field constructed independently from synthesized grasps and validated externally
full rationale
The paper constructs a graspable set from synthesized grasps and defines a graspability field as a scalar measure of configuration suitability for grasping. This field supplies a dense RL reward and termination signal, with the resulting policy evaluated in simulation and on physical robots where predicted distances correlate with real grasp success. No derivation step reduces by construction to fitted parameters from the same data, self-citations, or renamed inputs; the chain relies on external synthesis and physical validation rather than self-definition. This is the most common honest outcome for papers whose central quantities are defined upstream of the learning loop and tested against independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthesized grasps can define a graspable set that supports learning a generalizable field for real-world use.
invented entities (1)
-
graspability field
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: CoRL
Breyer, M., Chung, J.J., Ott, L., Siegwart, R., Nieto, J.: Volumetric grasping net- work: Real-time 6 dof grasp detection in clutter. In: CoRL. pp. 1602–1611. PMLR (2021)
2021
-
[2]
The International Journal of Robotics Research36(3), 261–268 (2017)
Calli, B., Singh, A., Bruce, J., Walsman, A., Konolige, K., Srinivasa, S., Abbeel, P., Dollar, A.M.: Yale-cmu-berkeley dataset for robotic manipulation research. The International Journal of Robotics Research36(3), 261–268 (2017)
2017
-
[3]
In: ICRA
Calli, B., Singh, A., Walsman, A., Srinivasa, S., Abbeel, P., Dollar, A.M.: The ycb object and model set: Towards common benchmarks for manipulation research. In: ICRA. pp. 510–517. IEEE (2015)
2015
-
[4]
IEEE Robotics & Automation Magazine22(3), 36–52 (2015)
Calli, B., Walsman, A., Singh, A., Srinivasa, S., Abbeel, P., Dollar, A.M.: Bench- marking in manipulation research: Using the yale-cmu-berkeley object and model set. IEEE Robotics & Automation Magazine22(3), 36–52 (2015)
2015
-
[5]
In: ICRA
Cheng, X., Huang, E., Hou, Y., Mason, M.T.: Contact mode guided motion plan- ning for quasidynamic dexterous manipulation in 3d. In: ICRA. pp. 2730–2736. IEEE (2022)
2022
-
[6]
In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP)
Cho, K., Van Merriënboer, B., Gulçehre, Ç., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using rnn encoder–decoder for statistical machine translation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). pp. 1724–1734 (2014)
2014
-
[7]
In: ICLR (2024)
Cho, Y., Han, J., Cho, Y., Kim, B.: Corn: Contact-based object representation for nonprehensile manipulation of general unseen objects. In: ICLR (2024)
2024
-
[8]
In: CoRL
Deng, S., Yan, M., Wei, S., Ma, H., Yang, Y., Chen, J., Zhang, Z., Yang, T., Zhang, X., Cui, H., et al.: Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data. In: CoRL. PMLR (2025)
2025
-
[9]
In: IROS
Ding, K., Chen, B., Wu, R., Li, Y., Zhang, Z., Gao, H.a., Li, S., Zhou, G., Zhu, Y., Dong, H., et al.: Preafford: Universal affordance-based pre-grasping for diverse objects and environments. In: IROS. pp. 7278–7285. IEEE (2024)
2024
-
[10]
In: IROS
Dogar, M.R., Srinivasa, S.S.: Push-grasping with dexterous hands: Mechanics and a method. In: IROS. pp. 2123–2130. IEEE (2010)
2010
-
[11]
IEEE TRO (2023)
Fang, H.S., Wang, C., Fang, H., Gou, M., Liu, J., Yan, H., Liu, W., Xie, Y., Lu, C.: Anygrasp: Robust and efficient grasp perception in spatial and temporal domains. IEEE TRO (2023)
2023
-
[12]
arXiv preprint arXiv:1912.13470 (2019)
Fang, H.S., Wang, C., Gou, M., Lu, C.: Graspnet: a large-scale clustered and densely annotated dataset for object grasping. arXiv preprint arXiv:1912.13470 (2019)
arXiv 1912
-
[13]
In: CVPR
Fang, H.S., Wang, C., Gou, M., Lu, C.: Graspnet-1billion: A large-scale benchmark for general object grasping. In: CVPR. pp. 11444–11453 (2020)
2020
-
[14]
International Journal of Advanced Robotic Systems14(1), 1729881416682706 (2016) 16 L
Guo, D., Sun, F., Kong, T., Liu, H.: Deep vision networks for real-time robotic grasp detection. International Journal of Advanced Robotic Systems14(1), 1729881416682706 (2016) 16 L. Zhong and G. H. Lee
2016
-
[15]
In: 2021 30th IEEE International Conference on Robot & Human Interactive Communication (RO-MAN)
Hager, J., Bauer, R., Toussaint, M., Mainprice, J.: Graspme-grasp manifold estima- tor. In: 2021 30th IEEE International Conference on Robot & Human Interactive Communication (RO-MAN). pp. 626–632. IEEE (2021)
2021
-
[16]
IEEE RAL 10(11), 11180–11187 (2025)
Hu, B., Tian, H., Wang, D., Huang, H., Zhu, X., Walters, R., Platt, R.: Push-grasp policy learning using equivariant models and grasp score optimization. IEEE RAL 10(11), 11180–11187 (2025)
2025
-
[17]
arXiv preprint arXiv:2502.03072 (2025)
Huang, Y., Davies, T., Yan, J., Chen, X., Tian, Y., Hu, L.: Robograsp: A universal grasping policy for robust robotic control. arXiv preprint arXiv:2502.03072 (2025)
arXiv 2025
-
[18]
good robot!
Hundt, A., Killeen, B., Greene, N., Wu, H., Kwon, H., Paxton, C., Hager, G.D.: “good robot!”: Efficient reinforcement learning for multi-step visual tasks with sim to real transfer. IEEE RAL5(4), 6724–6731 (2020)
2020
-
[19]
In: RSS (2024)
Jiang, B., Wu, Y., Zhou, W., Paxton, C., Held, D.: Hacman++: Spatially-grounded motion primitives for manipulation. In: RSS (2024)
2024
-
[20]
arXiv preprint arXiv:2104.01542 (2021)
Jiang, Z., Zhu, Y., Svetlik, M., Fang, K., Zhu, Y.: Synergies between affordance and geometry: 6-dof grasp detection via implicit representations. arXiv preprint arXiv:2104.01542 (2021)
arXiv 2021
-
[21]
arXiv preprint arXiv:2502.18015 (2025)
Jung, H., Lee, D., Park, H., Kim, J., Kim, B.: Spin: distilling skill-rrt for long-horizon prehensile and non-prehensile manipulation. arXiv preprint arXiv:2502.18015 (2025)
arXiv 2025
-
[22]
ACM TOG39(6), 1–14 (2020)
Laine, S., Hellsten, J., Karras, T., Seol, Y., Lehtinen, J., Aila, T.: Modular primi- tives for high-performance differentiable rendering. ACM TOG39(6), 1–14 (2020)
2020
-
[23]
arXiv preprint arXiv:2412.06931 (2024)
Lee, H.Y., Zhou, P., Duan, A., Ma, W., Yang, C., Navarro-Alarcon, D.: Non-prehensile tool-object manipulation by integrating llm-based planning and manoeuvrability-driven controls. arXiv preprint arXiv:2412.06931 (2024)
arXiv 2024
-
[24]
In: 2024 International Conference on Advanced Robotics and Mechatronics (ICARM)
Li, D., Zhao, C., Yang, S., Ma, L., Li, Y., Zhang, W.: Learning instruction-guided manipulation affordance via large models for embodied robotic tasks. In: 2024 International Conference on Advanced Robotics and Mechatronics (ICARM). pp. 662–667. IEEE (2024)
2024
-
[25]
In: ICCV (2025)
Li, G., Tsagkas, N., Song, J., Mon-Williams, R., Vijayakumar, S., Shao, K., Sevilla- Lara, L.: Learning precise affordances from egocentric videos for robotic manipu- lation. In: ICCV (2025)
2025
-
[26]
arXiv preprint arXiv:2511.06240 (2025)
Lin, T.J., Yeh, J.F., Su, H.T., Lin, C.Y., Chen, Y.T., Hsu, W.H.: Affordance- guided coarse-to-fine exploration for base placement in open-vocabulary mobile manipulation. arXiv preprint arXiv:2511.06240 (2025)
arXiv 2025
-
[27]
The international journal of robotics research15(6), 533–556 (1996)
Lynch, K.M., Mason, M.T.: Stable pushing: Mechanics, controllability, and plan- ning. The international journal of robotics research15(6), 533–556 (1996)
1996
-
[28]
In: ICCV (2025)
Lyu, J., Li, Z., Shi, X., Xu, C., Wang, Y., Wang, H.: Dywa: Dynamics-adaptive world action model for generalizable non-prehensile manipulation. In: ICCV (2025)
2025
-
[29]
arXiv preprint arXiv:1703.09312 (2017)
Mahler,J.,Liang,J.,Niyaz,S.,Laskey,M.,Doan,R.,Liu,X.,Ojea,J.A.,Goldberg, K.: Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. arXiv preprint arXiv:1703.09312 (2017)
Pith/arXiv arXiv 2017
-
[30]
The International Journal of Robotics Research18(11), 1129–1141 (1999)
Mason, M.T.: Progress in nonprehensile manipulation. The International Journal of Robotics Research18(11), 1129–1141 (1999)
1999
-
[31]
arXiv preprint arXiv:2511.04831 (2025)
Mittal, M., Roth, P., Tigue, J., Richard, A., Zhang, O., et al.: Isaac Lab - A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning. arXiv preprint arXiv:2511.04831 (2025)
Pith/arXiv arXiv 2025
-
[32]
In: Proceedings of the ACM SIGGRAPH/Eurographics symposium on computer animation
Mordatch, I., Popović, Z., Todorov, E.: Contact-invariant optimization for hand manipulation. In: Proceedings of the ACM SIGGRAPH/Eurographics symposium on computer animation. pp. 137–144 (2012)
2012
-
[33]
ACM TOG31(4), 1–8 (2012) GOMP 17
Mordatch, I., Todorov, E., Popović, Z.: Discovery of complex behaviors through contact-invariant optimization. ACM TOG31(4), 1–8 (2012) GOMP 17
2012
-
[34]
NVIDIA: Isaac Sim,https://github.com/isaac-sim/IsaacSim, (accessed June 29, 2026)
2026
-
[35]
In: IROS (2020)
Pohl, C., Hitzler, K., Grimm, R., Zea, A., Hanebeck, U.D., Asfour, T.: Affordance- based grasping and manipulation in real world applications. In: IROS (2020)
2020
-
[36]
arXiv preprint arXiv:2509.20550 (2025)
Srinivas, S.K., Shukla, Y., Arnold, A., Chitta, S.: Graspfactory: A large object- centric grasping dataset. arXiv preprint arXiv:2509.20550 (2025)
arXiv 2025
-
[37]
Sundermeyer, M., Mousavian, A., Triebel, R., Fox, D.: Contact-graspnet: Efficient 6-dofgraspgenerationinclutteredscenes.In:ICRA.pp.13438–13444.IEEE(2021)
2021
-
[38]
In: ICRA
Urain, J., Funk, N., Peters, J., Chalvatzaki, G.: Se(3)-diffusionfields: Learning smooth cost functions for joint grasp and motion optimization through diffusion. In: ICRA. IEEE (2023)
2023
-
[39]
In: ICCV
Wang, C., Fang, H.S., Gou, M., Fang, H., Gao, J., Lu, C.: Graspness discovery in clutters for fast and accurate grasp detection. In: ICCV. pp. 15964–15973 (October 2021)
2021
-
[40]
In: ICRA
Wang, R., Zhang, J., Chen, J., Xu, Y., Li, P., Liu, T., Wang, H.: Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation. In: ICRA. pp. 11359–11366. IEEE (2023)
2023
-
[41]
arXiv preprint arXiv:2503.23120 (2025)
Wang, Y., Li, Y., Yang, Y., Chen, Y.: Dexterous non-prehensile manipulation for ungraspable object via extrinsic dexterity. arXiv preprint arXiv:2503.23120 (2025)
arXiv 2025
-
[42]
In: ICRA
Weng, T., Held, D., Meier, F., Mukadam, M.: Neural grasp distance fields for robot manipulation. In: ICRA. pp. 1814–1821. IEEE (2023)
2023
-
[43]
IEEE RAL6(4), 6337–6344 (2021)
Xu, K., Yu, H., Lai, Q., Wang, Y., Xiong, R.: Efficient learning of goal-oriented push-grasping synergy in clutter. IEEE RAL6(4), 6337–6344 (2021)
2021
-
[44]
IEEE RAL9(12), 10842–10849 (2024)
Xu, R., Shen, Y., Li, X., Wu, R., Dong, H.: Naturalvlm: Leveraging fine-grained natural language for affordance-guided visual manipulation. IEEE RAL9(12), 10842–10849 (2024)
2024
-
[45]
In: CoRL
Yuan, W., Duan, J., Blukis, V., Pumacay, W., Krishna, R., Murali, A., Mousavian, A., Fox, D.: Robopoint: A vision-language model for spatial affordance prediction in robotics. In: CoRL. PMLR (2025)
2025
-
[46]
In: IROS
Zeng, A., Song, S., Welker, S., Lee, J., Rodriguez, A., Funkhouser, T.: Learning synergies between pushing and grasping with self-supervised deep reinforcement learning. In: IROS. pp. 4238–4245. IEEE (2018)
2018
-
[47]
In: CoRL
Zhang,J.,Liu,H.,Li,D.,Yu,X.,Geng,H.,Ding,Y.,Chen,J.,Wang,H.:Dexgrasp- net 2.0: Learning generative dexterous grasping in large-scale synthetic cluttered scenes. In: CoRL. PMLR (2024)
2024
-
[48]
arXiv preprint arXiv:2506.04646 (2025)
Zhong, Z., Golestaneh, S., Chamzas, C.: Activepusher: Active learning and planning with residual physics for nonprehensile manipulation. arXiv preprint arXiv:2506.04646 (2025)
Pith/arXiv arXiv 2025
-
[49]
In: CoRL
Zhou, W., Held, D.: Learning to grasp the ungraspable with emergent extrinsic dexterity. In: CoRL. pp. 150–160. PMLR (2023)
2023
-
[50]
In: CoRL
Zhou, W., Jiang, B., Yang, F., Paxton, C., Held, D.: Hacman: Learning hybrid actor-critic maps for 6d non-prehensile manipulation. In: CoRL. pp. 241–265. PMLR (2023)
2023
-
[51]
arXiv preprint arXiv:2511.11052 (2025) 18 L
Zhu, J., Tie, C., Cao, X., Wang, Y., Guo, J., Chen, Z., Chen, H., Chen, J., Xiao, Y., Wu, R., et al.: Adaptpnp: Integrating prehensile and non-prehensile skills for adaptive robotic manipulation. arXiv preprint arXiv:2511.11052 (2025) 18 L. Zhong and G. H. Lee Appendix A Additional Results A.1 Qualitative Manipulation Simulation Results Fig. 7:Qualitative...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.