Factorizable Normalizing Flows for parameter-dependent density morphing
Pith reviewed 2026-06-30 03:38 UTC · model grok-4.3
The pith
Factorizable Normalizing Flows represent a density that changes with continuous parameters by composing a fixed reference flow with a learnable polynomial transformation that factors over each parameter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
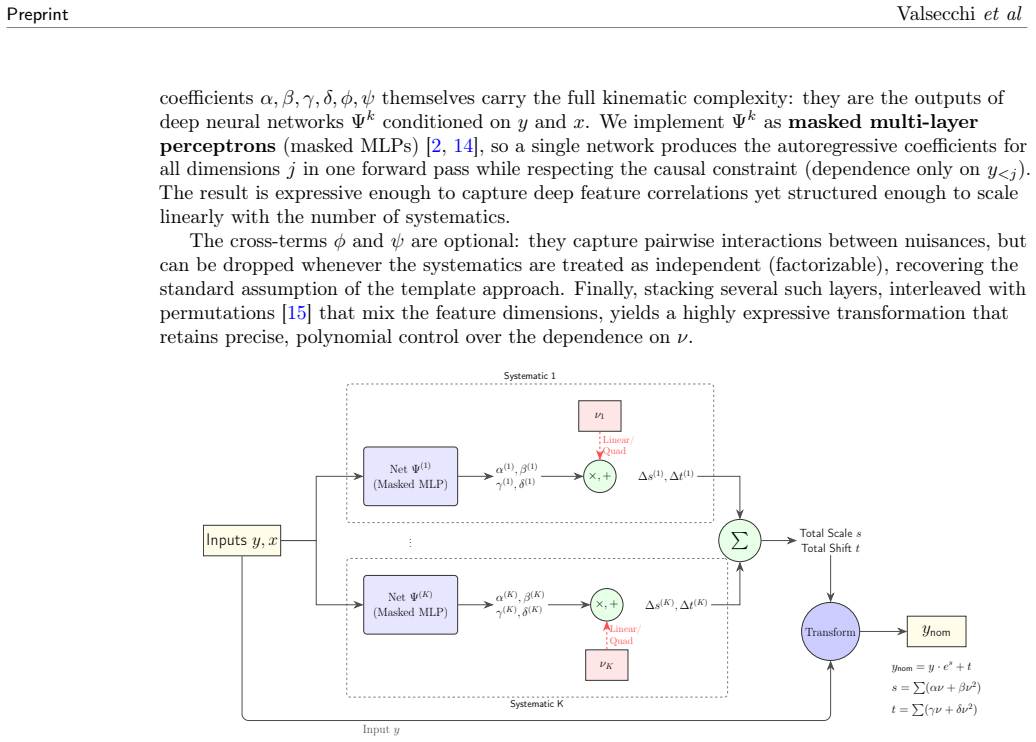
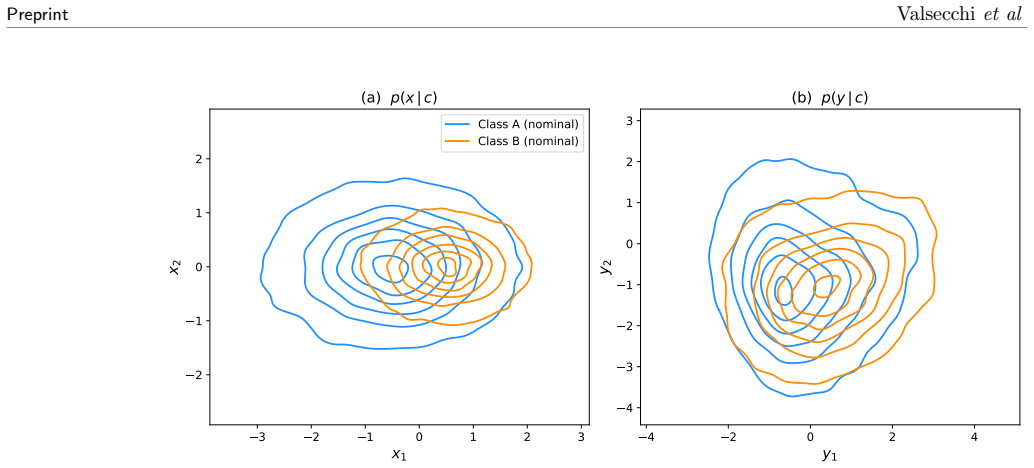
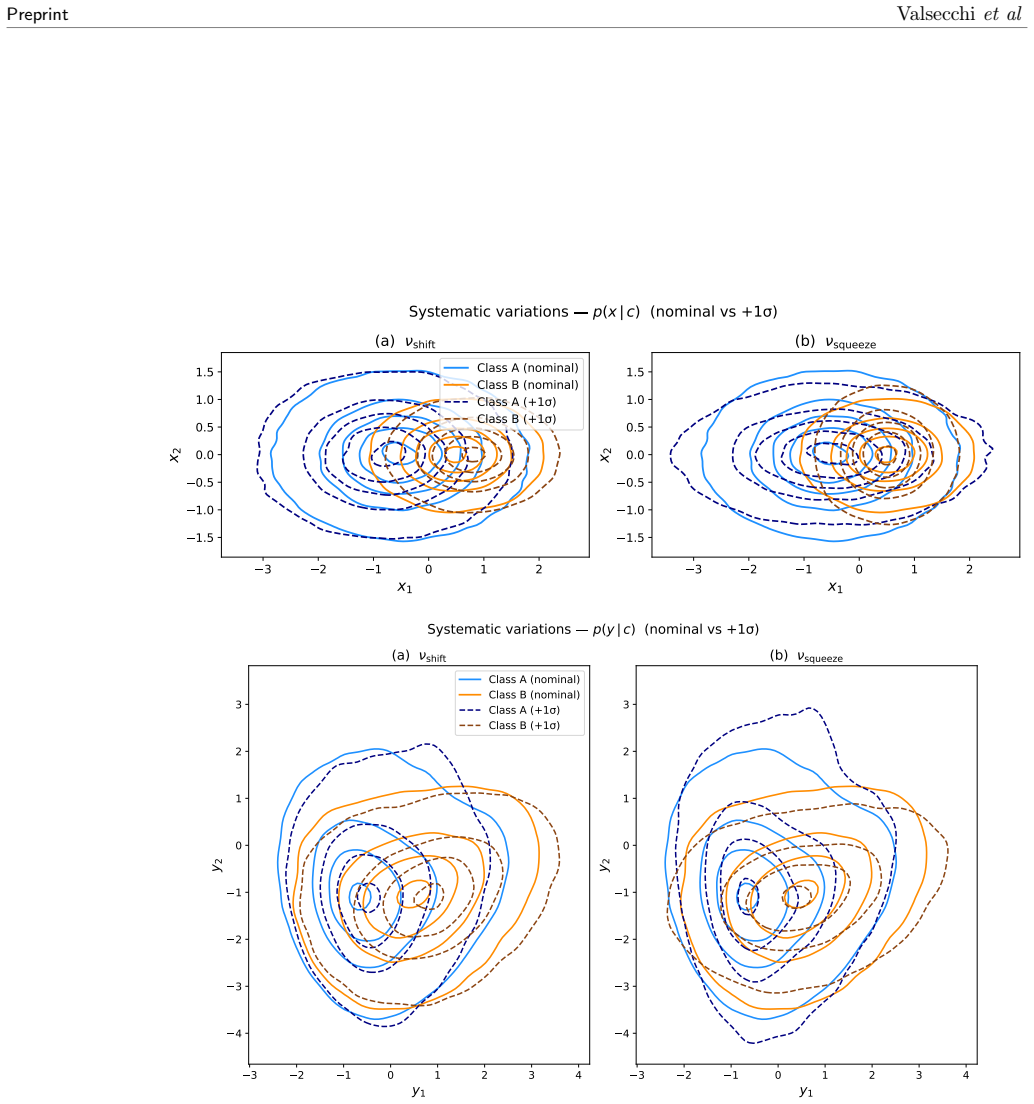
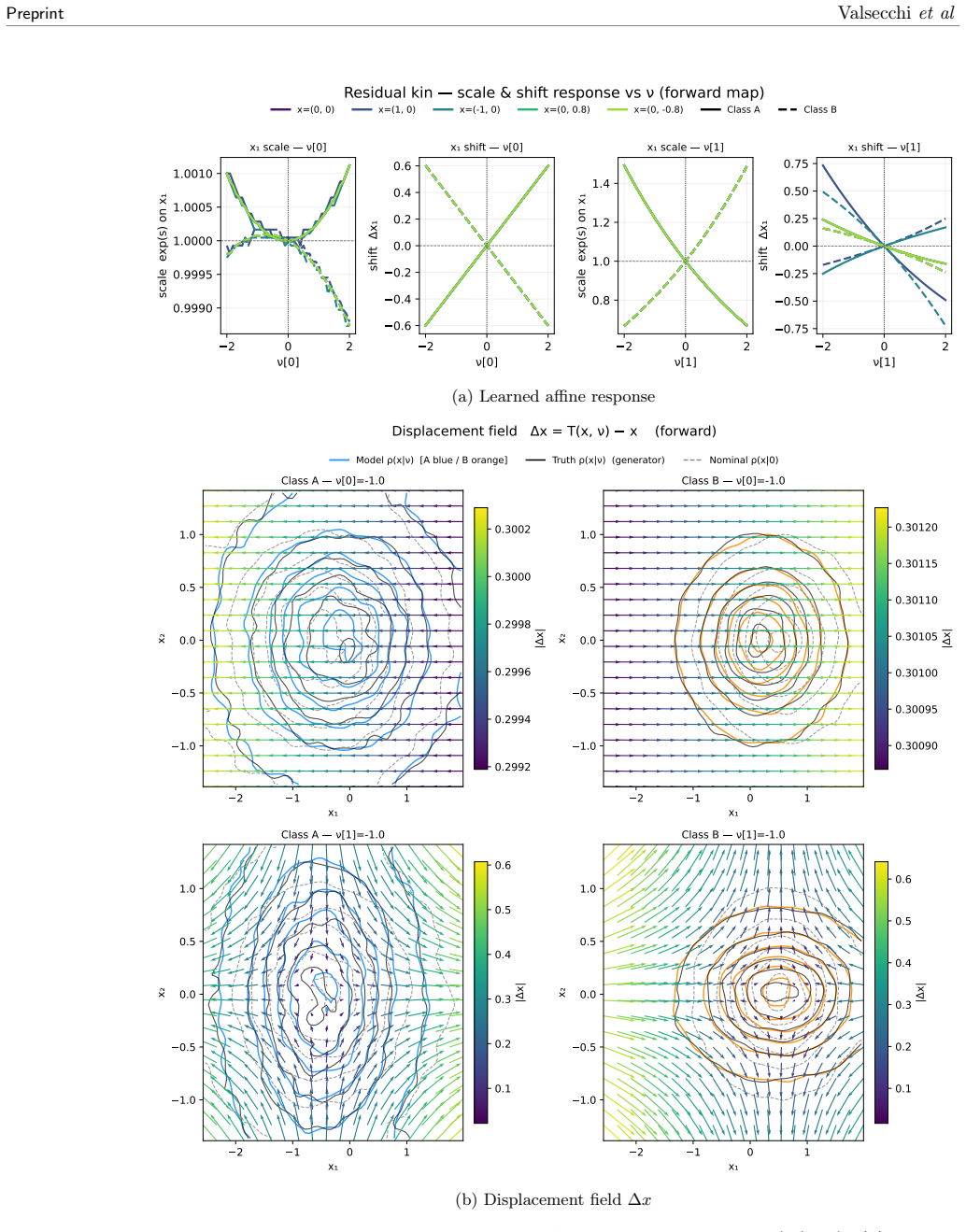
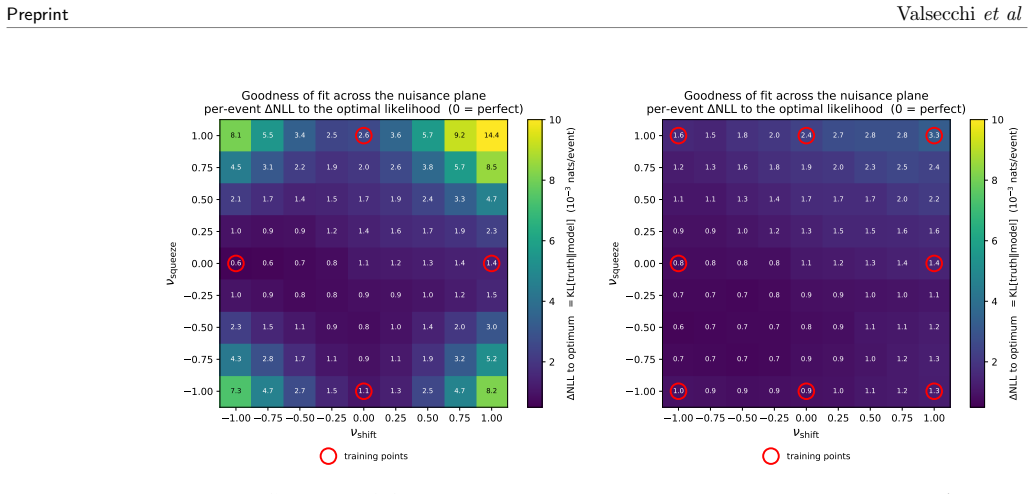
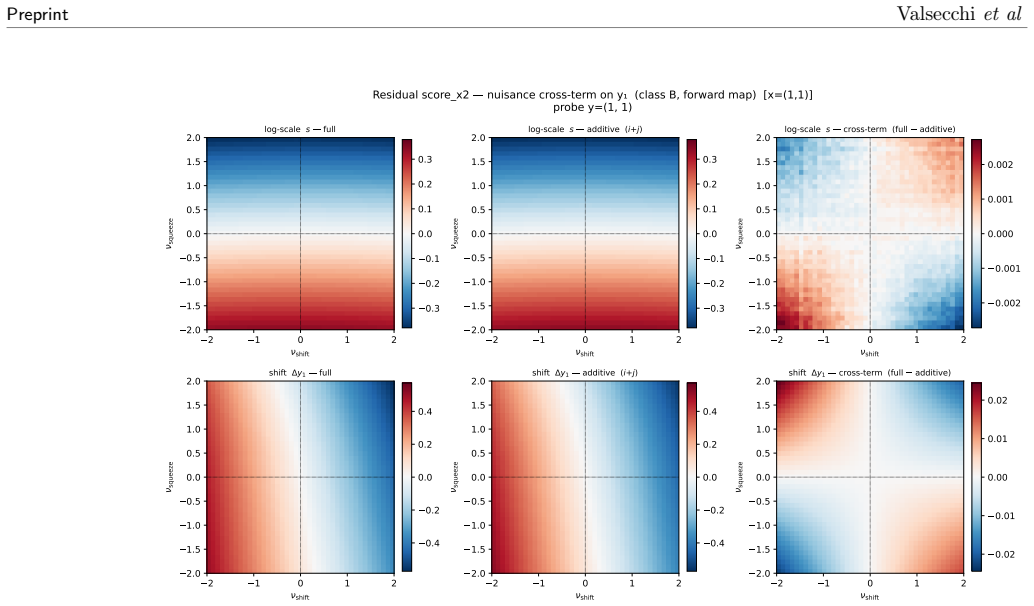
Factorizable Normalizing Flows model the parameter-dependent density as a fixed high-fidelity flow for a reference configuration composed with a learnable transformation that is polynomial in the parameters and factorized over them. Each parameter's effect is learned independently from samples in which that parameter alone is varied. The combined response of many parameters is recovered by summation at inference without ever sampling their combinatorially large joint space. On a controlled problem with two interpretable deformations applied jointly, the learned transformation reproduces the true deformations and matches the optimal likelihood, while optional interaction terms capture residua
What carries the argument
The learnable transformation that is polynomial in the parameters and factorized over them, composed with a fixed reference flow.
If this is right
- Each parameter's deformation is learned from samples that vary only that parameter.
- The response for any combination of parameters is recovered by summing the individual transformations.
- The overall model scales linearly with the number of parameters rather than exponentially.
- The likelihood remains tractable for downstream inference.
- Optional interaction terms can be added to capture residual correlations under strong joint variations.
Where Pith is reading between the lines
- The same structure could be applied to any simulation or measurement campaign where densities must be evaluated across continuous parameter grids.
- Because individual effects are learned separately, the method may reduce the number of full joint samples needed in large-scale physics analyses.
- If the polynomial order is increased systematically, the same factorization could test whether higher-order parameter effects remain separable.
- The explicit factorization makes it straightforward to inspect which single parameter drives a given change in the density shape.
Load-bearing premise
The way a density deforms with parameters can be captured by a polynomial that factors over the parameters and composes with one fixed reference flow.
What would settle it
On the controlled test case with two known joint deformations, train the model and check whether the recovered transformation exactly matches the true deformations and reaches the optimal likelihood value.
Figures


read the original abstract
Normalizing Flows excel at modeling a single fixed density, yet many problems across the sciences, such as high energy physics, instead require modeling how that density deforms as a function of continuous parameters: the strength of a physical effect, a calibration constant, or a source of systematic uncertainty. Learning a separate flow for every parameter configuration quickly becomes intractable, since the number of joint settings grows exponentially with the number of parameters. We introduce Factorizable Normalizing Flows (FNFs), which represent the parameter-dependent density as a fixed, high-fidelity flow for a reference configuration composed with a learnable transformation that is polynomial in the parameters and factorized over them. This structure has a practical consequence: each parameter's effect is learned in isolation, from samples in which that parameter alone is varied. The combined response of many parameters is then recovered by summation at inference, without ever sampling their combinatorially large joint space. On a controlled problem with two interpretable deformations applied jointly to the data, the learned transformation reproduces the true deformations and matches the optimal likelihood, while optional interaction terms capture residual correlations when several parameters vary strongly at once. The resulting model is interpretable, scales linearly with the number of parameters, and keeps the likelihood tractable. This provides a general tool for any inference workflow requiring continuous density morphing, and directly enables the next generation of unbinned likelihood fits in high energy physics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Factorizable Normalizing Flows (FNFs) to model how a density deforms continuously with multiple parameters. A fixed high-fidelity reference flow is composed with a learnable polynomial transformation that factorizes over parameters (with optional interaction terms). Each parameter's effect is learned separately from single-parameter variation samples; the joint effect is recovered by summation at inference time. On a controlled two-parameter example the learned map is reported to recover the true deformations and achieve optimal likelihood while remaining interpretable and linearly scaling.
Significance. If the empirical claims hold, the construction supplies a practical route to continuous density morphing that avoids the exponential cost of joint sampling, preserves tractable likelihoods, and yields interpretable per-parameter effects. This directly addresses a recurring need in high-energy physics for unbinned likelihood fits that incorporate systematic variations without retraining separate flows.
major comments (1)
- [Abstract] Abstract: the central empirical claim states that the learned transformation 'reproduces the true deformations and matches the optimal likelihood' on the controlled two-parameter problem, yet no numerical values (log-likelihoods, KL divergences, reconstruction errors), error bars, or baseline comparisons are supplied. This absence leaves the strength of the supporting evidence difficult to evaluate.
minor comments (2)
- The weakest-assumption paragraph in the reader's note correctly identifies that the method relies on the deformation being adequately captured by a polynomial factorized map; the manuscript should state this modeling assumption explicitly and discuss its domain of validity.
- Implementation details (network architectures, polynomial degree, training procedure, and how the reference flow is held fixed) are not mentioned in the abstract and should be added to the methods section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the supportive summary and recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim states that the learned transformation 'reproduces the true deformations and matches the optimal likelihood' on the controlled two-parameter problem, yet no numerical values (log-likelihoods, KL divergences, reconstruction errors), error bars, or baseline comparisons are supplied. This absence leaves the strength of the supporting evidence difficult to evaluate.
Authors: We agree that the abstract would benefit from explicit quantitative support for the central claim. The detailed log-likelihood values, KL divergences, reconstruction errors, and baseline comparisons are already reported with error bars in Section 4 (Experiments) and Table 1 of the manuscript. In the revised version we will insert a concise summary of the key numerical results (e.g., achieved log-likelihood matching the optimum within reported uncertainty) directly into the abstract while preserving its length constraints. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines FNFs explicitly as a fixed reference flow composed with a new learnable polynomial-in-parameters factorized transformation (with optional interactions). The central performance claim is validated on a controlled synthetic problem by direct comparison to the known true deformations and optimal likelihood; the factorization is learned from isolated single-parameter samples and combined by summation at inference. No equation reduces the reported reproduction of deformations or likelihood match to a quantity already fitted inside the same model by construction. The structure is presented as an ansatz chosen for tractability and linear scaling, not derived from a self-citation chain or uniqueness theorem. This is a self-contained construction against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- polynomial coefficients
axioms (1)
- domain assumption Density morphing can be represented by composition with a factorized polynomial transformation
Reference graph
Works this paper leans on
-
[1]
The frontier of simulation-based inference
Kyle Cranmer, Johann Brehmer, and Gilles Louppe. The frontier of simulation-based inference. Proc. Nat. Acad. Sci., 117(48):30055–30062, 2020. doi:10.1073/pnas.1912789117
-
[2]
Ivan Kobyzev, Simon J. D. Prince, and Marcus A. Brubaker. Normalizing Flows: An Introduction and Review of Current Methods.IEEE Trans. Pattern Anal. Mach. Intell., 43(11): 3964–3979, 2021. doi:10.1109/TPAMI.2020.2992934
-
[3]
Michele Vallisneri, Marco Crisostomi, Aaron D. Johnson, and Patrick M. Meyers. Rapid parameter estimation for pulsar-timing-array datasets with variational inference and normalizing flows.Phys. Rev. Lett., 135:071401, Aug 2025. doi:10.1103/p3f7-rbmv. URL https://link.aps.org/doi/10.1103/p3f7-rbmv
-
[4]
Normalizing Flows for Probabilistic Modeling and Inference.J
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing Flows for Probabilistic Modeling and Inference.J. Mach. Learn. Res., 22(57):1–64, 2021. URLhttps://jmlr.org/papers/v22/19-1028.html
2021
-
[5]
tex.eprint: https://www.science.org/doi/pdf/10.1126/science.aaw1147
Frank Noé, Simon Olsson, Jonas Köhler, and Hao Wu. Boltzmann generators: Sampling equilibrium states of many-body systems with deep learning.Science, 365(6457):eaaw1147, 2019. doi:10.1126/science.aaw1147
-
[6]
M. S. Albergo, G. Kanwar, and P. E. Shanahan. Flow-based generative models for Markov chain Monte Carlo in lattice field theory.Phys. Rev. D, 100(3):034515, 2019. doi:10.1103/PhysRevD.100.034515. 14 Preprint Valsecchiet al
-
[7]
The CMS statistical analysis and combination tool: COMBINE.Comput
CMS Collaboration. The CMS statistical analysis and combination tool: COMBINE.Comput. Softw. Big Sci., 8(1):19, 2024. doi:10.1007/s41781-024-00121-4
-
[8]
HistFactory: A tool for creating statistical models for use with RooFit and RooStats
Kyle Cranmer, George Lewis, Lorenzo Moneta, Akira Shibata, and Wouter Verkerke. HistFactory: A tool for creating statistical models for use with RooFit and RooStats. Technical report, New York U., 2012. URLhttps://cds.cern.ch/record/1456844
arXiv 2012
-
[9]
Max Baak, Stefan Gadatsch, Robert Harrington, and Wouter Verkerke. Interpolation between multi-dimensional histograms using a new non-linear moment morphing method.Nucl. Instrum. Meth. A, 771:39–48, 2015. doi:10.1016/j.nima.2014.10.033
-
[10]
Springer, Cham, 3rd edition, 2023
Luca Lista.Statistical Methods for Data Analysis: With Applications in Particle Physics, volume 1003 ofLecture Notes in Physics. Springer, Cham, 3rd edition, 2023. ISBN 978-3-031-19933-2. doi:10.1007/978-3-031-19934-9
-
[11]
Density estimation using Real NVP
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using Real NVP. In International Conference on Learning Representations (ICLR), 2017
2017
-
[12]
Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling
Diederik P. Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling. Improved Variational Inference with Inverse Autoregressive Flow. InAdvances in Neural Information Processing Systems, volume 29, pages 4743–4751, 2016
2016
-
[13]
Masked autoregressive flow for density estimation, 2018
George Papamakarios, Theo Pavlakou, and Iain Murray. Masked autoregressive flow for density estimation, 2018. URLhttps://arxiv.org/abs/1705.07057
Pith/arXiv arXiv 2018
-
[14]
MADE: Masked Autoencoder for Distribution Estimation
Mathieu Germain, Karol Gregor, Iain Murray, and Hugo Larochelle. MADE: Masked Autoencoder for Distribution Estimation. InProceedings of the 32nd International Conference on Machine Learning (ICML), volume 37 ofPMLR, pages 881–889, 2015
2015
-
[15]
Kingma and Prafulla Dhariwal
Diederik P. Kingma and Prafulla Dhariwal. Glow: Generative Flow with Invertible 1x1 Convolutions. InAdvances in Neural Information Processing Systems, volume 31, pages 10215–10224, 2018
2018
-
[16]
Neural spline flows,
Conor Durkan, Artur Bekasov, Iain Murray, and George Papamakarios. Neural spline flows,
-
[17]
URLhttps://arxiv.org/abs/1906.04032
arXiv 1906
-
[18]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An Imperative Style, High-Perfo...
2019
-
[19]
Zuko: Normalizing flows in pytorch, 2022
François Rozet et al. Zuko: Normalizing flows in pytorch, 2022. URL https://pypi.org/project/zuko
2022
-
[20]
valsdav/factorizable-normalizing-flow: v1.0, 2026
Davide Valsecchi. valsdav/factorizable-normalizing-flow: v1.0, 2026. URL https://doi.org/10.5281/zenodo.21011625
-
[21]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URL https://arxiv.org/abs/1711.05101
Pith/arXiv arXiv 2019
-
[22]
Computational Optimal Transport.Found
Gabriel Peyré and Marco Cuturi. Computational Optimal Transport.Found. Trends Mach. Learn., 11(5-6):355–607, 2019. doi:10.1561/2200000073
-
[23]
OT-Flow: Fast and Accurate Continuous Normalizing Flows via Optimal Transport
Derek Onken, Samy Wu Fung, Xingjian Li, and Lars Ruthotto. OT-Flow: Fast and Accurate Continuous Normalizing Flows via Optimal Transport. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 9223–9232, 2021. doi:10.1609/aaai.v35i10.17113
-
[24]
Chin-Wei Huang, Ricky T. Q. Chen, Christos Tsirigotis, and Aaron Courville. Convex potential flows: Universal probability distributions with optimal transport and convex optimization, 2021. URLhttps://arxiv.org/abs/2012.05942
arXiv 2021
-
[25]
Brandon Amos, Lei Xu, and J. Zico Kolter. Input convex neural networks, 2017. URL https://arxiv.org/abs/1609.07152. 15 Preprint Valsecchiet al
Pith/arXiv arXiv 2017
-
[26]
Improving and Generalizing Flow-Based Generative Models with Minibatch Optimal Transport.Trans
Alexander Tong, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector-Brooks, Kilian Fatras, Guy Wolf, and Yoshua Bengio. Improving and Generalizing Flow-Based Generative Models with Minibatch Optimal Transport.Trans. Mach. Learn. Res., 2024, 2024. URLhttps://openreview.net/forum?id=HgDwiZrpVq. Introduces OT-CFM
2024
-
[27]
Patrick T. Komiske, Eric M. Metodiev, and Jesse Thaler. The Metric Space of Collider Events. Phys. Rev. Lett., 123(4):041801, 2019. doi:10.1103/PhysRevLett.123.041801
-
[28]
A continuous calibration of the ATLAS flavour-tagging classifiers via optimal transportation maps, 2025
ATLAS Collaboration. A continuous calibration of the ATLAS flavour-tagging classifiers via optimal transportation maps, 2025. Preprint
2025
-
[29]
Mind the Gap: Navigating Inference with Optimal Transport Maps, 2025
Malte Algren, Tobias Golling, Francesco Armando Di Bello, and Christopher Pollard. Mind the Gap: Navigating Inference with Optimal Transport Maps, 2025
2025
-
[30]
Advancing Tools for Simulation-Based Inference.SciPost Phys
Henning Bahl, Víctor Bresó-Pla, Giovanni De Crescenzo, and Tilman Plehn. Advancing Tools for Simulation-Based Inference.SciPost Phys. Core, 8:060, 2025. doi:10.21468/SciPostPhysCore.8.3.060
-
[31]
A Guide to Constraining Effective Field Theories with Machine Learning.Phys
Johann Brehmer, Kyle Cranmer, Gilles Louppe, and Juan Pavez. A Guide to Constraining Effective Field Theories with Machine Learning.Phys. Rev. D, 98(5):052004, 2018. doi:10.1103/PhysRevD.98.052004
-
[32]
Unifying Simulation and Inference with Normalizing Flows.Phys
Claudius Krause et al. Unifying Simulation and Inference with Normalizing Flows.Phys. Rev. D, 111:076004, 2025. doi:10.1103/PhysRevD.111.076004
-
[33]
Data-Driven High-Dimensional Statistical Inference with Generative Models.JHEP, 11:129, 2025
Oz Amram and Manuel Szewc. Data-Driven High-Dimensional Statistical Inference with Generative Models.JHEP, 11:129, 2025. doi:10.1007/JHEP11(2025)129
-
[34]
Unbinned inclusive cross-section measurements with machine-learned systematic uncertainties.Phys
Lisa Benato, Cristina Giordano, Claudius Krause, Ang Li, Robert Schöfbeck, Dennis Schwarz, Maryam Shooshtari, and Daohan Wang. Unbinned inclusive cross-section measurements with machine-learned systematic uncertainties.Phys. Rev. D, 112:052006, Sep 2025. doi:10.1103/zwzt-1rrw. URLhttps://link.aps.org/doi/10.1103/zwzt-1rrw
-
[35]
Unbinned multivariate observables for global SMEFT analyses from machine learning.JHEP, 03:033, 2023
Raquel Gomez Ambrosio, Jaco ter Hoeve, Maeve Madigan, Juan Rojo, and Veronica Sanz. Unbinned multivariate observables for global SMEFT analyses from machine learning.JHEP, 03:033, 2023. doi:10.1007/JHEP03(2023)033
-
[36]
An implementation of neural simulation-based inference for parameter estimation in ATLAS.Rept
ATLAS Collaboration. An implementation of neural simulation-based inference for parameter estimation in ATLAS.Rept. Prog. Phys., 2025. doi:10.1088/1361-6633/add370
-
[37]
ATLAS Collaboration. Measurement of off-shell Higgs boson production in theH→ZZ→4ℓ decay channel using a neural simulation-based inference technique in 13 TeV pp collisions with the ATLAS detector.Rept. Prog. Phys., 2025. doi:10.1088/1361-6633/adcd9a
-
[38]
Refinable modeling for unbinned SMEFT analyses.Mach
Robert Schöfbeck. Refinable modeling for unbinned SMEFT analyses.Mach. Learn. Sci. Tech., 6:015007, 2025. doi:10.1088/2632-2153/ad9fd1
-
[39]
Multiscale Flow for Robust and Optimal Cosmological Analysis
Biwei Dai and Uroš Seljak. Multiscale Flow for Robust and Optimal Cosmological Analysis. Proc. Nat. Acad. Sci., 121(9):e2309624121, 2024. doi:10.1073/pnas.2309624121
-
[40]
Maximilian Dax, Stephen R. Green, Jonathan Gair, Jakob H. Macke, Alessandra Buonanno, and Bernhard Schölkopf. Real-Time Gravitational Wave Science with Neural Posterior Estimation. Phys. Rev. Lett., 127(24):241103, 2021. doi:10.1103/PhysRevLett.127.241103
-
[41]
Caio Daumann, Mauro Donegà, Johannes Erdmann, Massimiliano Galli, Jan Lukas Späh, and Davide Valsecchi. One flow to correct them all: Improving simulations in high-energy physics with a single normalising flow and a switch.Comput. Softw. Big Sci., 8(1):23, 2024. doi:10.1007/s41781-024-00125-0
-
[42]
Generative Unfolding with Distribution Mapping
Anja Butter, Sascha Diefenbacher, Nathan Huetsch, Vinicius Mikuni, Benjamin Nachman, Sofia Palacios Schweitzer, and Tilman Plehn. Generative Unfolding with Distribution Mapping. SciPost Phys., 18:200, 2025. doi:10.21468/SciPostPhys.18.6.200
-
[43]
Analysis-ready generative unfolding, 2025
Anja Butter, Nathan Huetsch, Vinicius Mikuni, Benjamin Nachman, and Sofia Palacios Schweitzer. Analysis-ready generative unfolding, 2025. URL https://arxiv.org/abs/2509.02708. 16 Preprint Valsecchiet al
arXiv 2025
-
[44]
Simulation-prior independent neural unfolding procedure, 2025
Anja Butter, Theo Heimel, Nathan Huetsch, Michael Kagan, and Tilman Plehn. Simulation-prior independent neural unfolding procedure, 2025. URL https://arxiv.org/abs/2507.15084
arXiv 2025
-
[45]
T2K Collaboration. Machine Learning-Assisted Unfolding for Neutrino Cross-section Measurements with the OmniFold Technique.Phys. Rev. D, 112:012008, 2025. doi:10.1103/PhysRevD.112.012008
-
[46]
Anders Andreassen and Benjamin Nachman. Neural networks for full phase-space reweighting and parameter tuning.Physical Review D, 101(9), May 2020. ISSN 2470-0029. doi:10.1103/physrevd.101.091901. URLhttp://dx.doi.org/10.1103/PhysRevD.101.091901. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.