Why Solve It Twice? Hierarchical Accumulation of Skills for Transfer-Efficient ML Engineering
Pith reviewed 2026-07-02 20:12 UTC · model grok-4.3
The pith
Organizing ML engineering skills into global, domain, and competition-specific tiers lets agents transfer knowledge across tasks instead of rediscovering it each time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HASTE maintains a 159-skill inventory partitioned into three tiers and uses an orchestrator to abstract and move knowledge upward. When the same inventory is reloaded in tiered form across eight competitions the medal rate reaches 100 percent; flat reloading of the identical skills yields only 62.5 percent, identical to starting with an empty inventory. On the full twenty-two-competition benchmark the system attains 77.3 percent medals. Warm-start runs require 52 percent fewer iterations and retain 85 percent of proposed changes once fifty or more skills are present.
What carries the argument
The three-tier hierarchy (global, domain, competition-specific) coupled to an LLM orchestrator that performs abstraction and promotion between tiers.
If this is right
- Tiered loading of a fixed skill inventory doubles the medal rate relative to flat loading or no skills.
- Warm-start competitions require 52 percent fewer refinement iterations than cold starts.
- The fraction of agent-proposed changes that are kept rises from 42 percent to 85 percent as the skill inventory grows past fifty items.
- Knowledge organization can reduce the need for stronger base models or larger compute budgets.
Where Pith is reading between the lines
- The same tiering principle could reduce repeated discovery in other sequential agent tasks such as iterative software development.
- If the abstraction step scales without introducing errors, larger inventories become feasible without proportional token costs.
- Comparing cold-start and warm-start curves on new benchmarks would quantify how much hierarchy substitutes for raw model capability.
Load-bearing premise
The skills admit a stable partition into the three scope tiers and the orchestrator abstractions remain accurate and non-misleading when reloaded in new competitions.
What would settle it
Running the identical 159-skill inventory through the eight competitions once with tiered loading and once with flat loading, and finding that the tiered condition no longer produces a 100 percent medal rate or that abstractions degrade later performance.
Figures


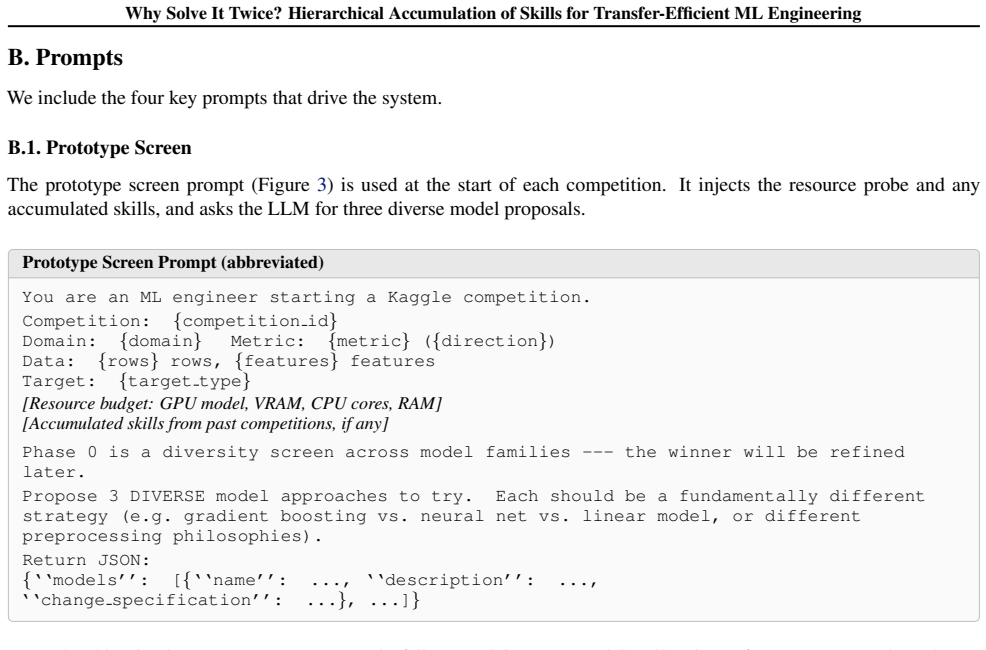

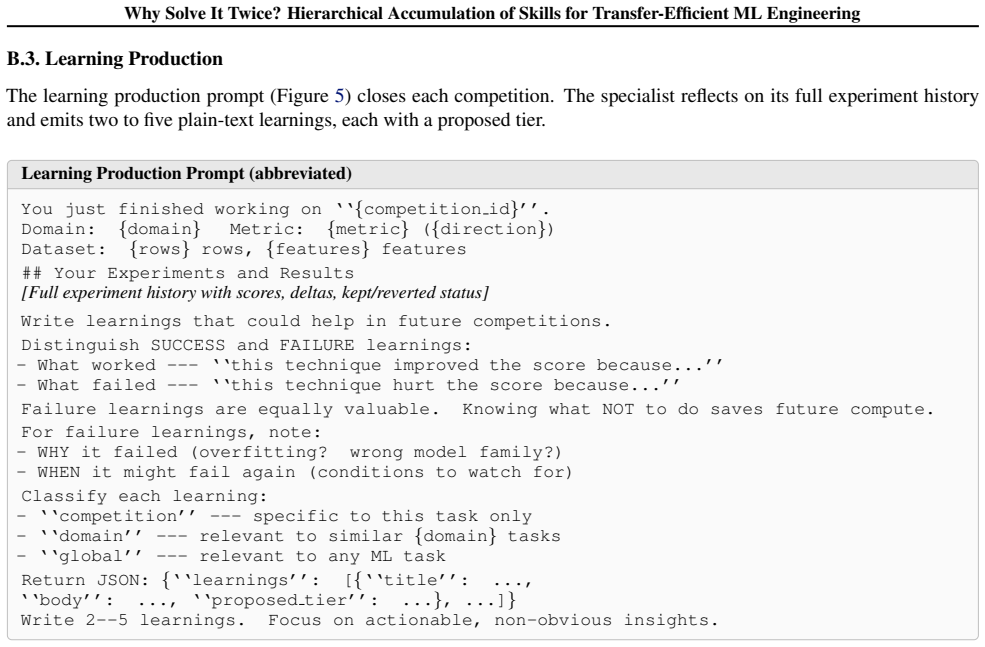

read the original abstract
ML engineering agents waste compute rediscovering known techniques because every competition is a cold start. We present HASTE, a hierarchical multi-agent system that organizes cross-competition knowledge into three scope tiers (global, domain, and competition-specific), each coupled to a matching agent level. An orchestrator coordinates domain specialists and promotes learning between tiers via LLM-driven abstraction. A controlled ablation provides evidence for scoped loading: holding a 159-skill inventory constant across 8 competitions, tiered loading achieves a 100% medal rate while flat loading reaches only 62.5%, the same medal rate as loading no skills, and consumes 2x the output tokens. On the full MLE-Bench Lite benchmark (22 Kaggle competitions), HASTE reaches a medal rate of 77.3% using Claude Sonnet 4.6 at 12h per competition; this is a single-seed campaign result, and multi-seed replication is the priority follow-up. In a cold-start run, the system begins with no accumulated skills. In warm-start runs, it reloads skills learned from earlier competitions, using only global and domain-level skills for transfer across competitions. Warm starts use 52% fewer refinement iterations, and the fraction of proposed changes kept by the agent rises from 42% at low inventory to 85% once 50+ skills are available. These results suggest that better knowledge organization can partly substitute for model strength and compute budget in ML-engineering agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HASTE, a hierarchical multi-agent system for ML engineering that partitions accumulated skills into three scope tiers (global, domain, competition-specific) managed by matching agent levels, with an orchestrator performing LLM-driven abstraction to transfer knowledge across competitions. Holding a fixed 159-skill inventory across 8 competitions, the ablation reports tiered loading reaching 100% medal rate while flat loading reaches only 62.5% (identical to no skills) and uses twice the output tokens. On the full MLE-Bench Lite (22 competitions) the system attains 77.3% medal rate in a single-seed run; warm-start runs reduce refinement iterations by 52% and raise the fraction of kept changes from 42% to 85% once 50+ skills are available.
Significance. If the tiered organization and abstraction mechanism prove robust under replication, the work demonstrates that explicit knowledge scoping can substitute for additional model scale or compute in ML agents. The fixed-inventory ablation is a methodological strength because it isolates the contribution of hierarchical loading from skill-set growth. The manuscript correctly flags single-seed replication as the immediate next step.
major comments (2)
- [Abstract] Abstract (tiered loading paragraph): the 100% vs 62.5% medal-rate gap is presented as evidence for scoped loading, yet the manuscript supplies no decision rules, prompts, or validation protocol for partitioning the 159 skills into the three tiers or for confirming that LLM abstractions remain accurate and non-misleading when reloaded; without these the result could reflect implicit per-competition curation absent from the flat baseline.
- [Abstract] Abstract (ablation description): the quantitative claim rests on a single-seed experiment with no error bars or statistical tests reported, even though the text itself identifies multi-seed replication as the priority follow-up; this leaves the magnitude of the tiered-loading advantage vulnerable to run-to-run variance.
minor comments (2)
- [Abstract] The abstract states results for 'Claude Sonnet 4.6'; confirm the exact model identifier and version used in the experiments.
- [Abstract] The manuscript notes that warm-start runs reload only global and domain-level skills; clarify whether competition-specific skills are ever carried forward or are always reset.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the fixed-inventory ablation as a methodological strength. We address each major comment below, indicating where revisions will be made to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract (tiered loading paragraph): the 100% vs 62.5% medal-rate gap is presented as evidence for scoped loading, yet the manuscript supplies no decision rules, prompts, or validation protocol for partitioning the 159 skills into the three tiers or for confirming that LLM abstractions remain accurate and non-misleading when reloaded; without these the result could reflect implicit per-competition curation absent from the flat baseline.
Authors: We agree that the manuscript does not supply the requested decision rules, prompts, or validation protocol for tier partitioning and abstraction accuracy. This is a valid concern that could affect interpretation of whether the tiered advantage is due to hierarchy or unstated curation. In the revised version we will add a new subsection detailing: (1) explicit criteria for assigning skills to global/domain/competition-specific tiers, (2) the LLM prompt templates used for abstraction when reloading skills, and (3) a validation protocol (manual review of a sample of abstractions for accuracy). Example partitions from the 159-skill set will also be included. These additions will be placed in the methods section to support reproducibility. revision: yes
-
Referee: [Abstract] Abstract (ablation description): the quantitative claim rests on a single-seed experiment with no error bars or statistical tests reported, even though the text itself identifies multi-seed replication as the priority follow-up; this leaves the magnitude of the tiered-loading advantage vulnerable to run-to-run variance.
Authors: The manuscript already states that both the 77.3% result and the ablation are single-seed and flags multi-seed replication as the priority follow-up. We acknowledge that the absence of error bars or statistical tests leaves the 100% vs 62.5% gap open to variance concerns. Because the experiments are computationally expensive we cannot add new seeds for this revision. We will, however, revise the abstract and results to more prominently state the single-seed limitation and note the lack of variance estimates. This improves presentation while preserving the existing claims. revision: partial
Circularity Check
No significant circularity; results are direct experimental outcomes
full rationale
The paper's central claims rest on controlled ablation experiments that hold a fixed 159-skill inventory constant and directly measure medal rates (100% tiered vs 62.5% flat) and iteration counts across competitions. These are empirical measurements rather than quantities derived from fitted parameters, self-referential equations, or load-bearing self-citations. No equations are presented that reduce a prediction to its own inputs by construction, and the skill-tier partitioning and abstraction steps are described as experimental conditions without being justified via prior self-citation chains or uniqueness theorems. The derivation chain is therefore self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-driven abstraction produces skills that remain useful when reloaded across competitions
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2303. 11366. Sumers, T. R., Yao, S., Narasimhan, K., and Grif- fiths, T. L. Cognitive architectures for language agents.Transactions on Machine Learning Research,
-
[2]
URLhttps://openreview.net/forum? id=1i6ZCvflQJ. Sutton, R. S., Precup, D., and Singh, S. Between MDPs and semi-MDPs: A framework for temporal abstrac- tion in reinforcement learning.Artificial Intelligence, 112:181–211, 1999. URLhttps://doi.org/10. 1016/S0004-3702(99)00052-1. Talebirad, Y ., Parsaee, A., Szepesvari, C. Y ., Nadiri, A., and Zaiane, O. Towa...
-
[3]
URLhttps://arxiv.org/abs/2305. 02499. Zhao, A., Huang, D., Xu, Q., Lin, M., Liu, Y .-J., and Huang, G. Expel: Llm agents are experiential learn- ers. InAAAI, 2024. URLhttps://doi.org/10. 1609/aaai.v38i17.29936. Zhu, X., Chen, Y ., Tian, H., et al. Ghost in the minecraft: Generally capable agents for open-world environments via large language models with t...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
UNDERFITTING --- train score near baseline, small gap
-
[5]
OVERFITTING --- large train-val gap, high train score
-
[6]
FEATURE GAP --- top features dominate, score plateaus
-
[7]
NOISE CEILING --- high CV variance, score fluctuates
-
[8]
DISTRIBUTION MISMATCH --- train-val-test disagreement
-
[9]
Propose ONE atomic change to improve the score
DIMINISHING RETURNS --- each iter improves <0.1% Mention which mode applies and which past skill (if any) influenced your decision. Propose ONE atomic change to improve the score. Return JSON:{‘‘plan’’: ..., ‘‘change specification’’: ..., ‘‘decision’’: ‘‘CONTINUE’’ | ‘‘NEXT TIER’’ | ‘‘STOP’’} Figure 4.Abbreviated refinement proposal prompt. The tier label...
-
[10]
‘‘skip’’ --- already covered or too obvious
-
[11]
‘‘competition’’ --- too specific (dataset quirks, row indices)
-
[12]
Abstract it
‘‘domain’’ --- generalizable to similar tasks. Abstract it
-
[13]
‘‘global’’ --- universally useful across all ML tasks
-
[14]
Note conditions under which each holds
‘‘conflict’’ --- contradicts an existing learning. Note conditions under which each holds. ## Quality Standards - Be selective. Promote AT MOST 50% of learnings. - Abstractions MUST NOT mention specific competition names, dataset names, or exact score values. Bad: ‘‘On aerial-cactus, AUC reached 0.9997’’ Good: ‘‘When AUC is near ceiling (>0.999), further ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.