Cross-Fitted Survey-Weighted TMLE with Design-Based Variance for Causal Machine Learning
Pith reviewed 2026-07-01 01:12 UTC · model grok-4.3
The pith
Cross-fitting at the cluster level restores valid coverage for survey-weighted TMLE once flexible learners exceed the Donsker boundary.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our central result, established in theory and simulation, is that this validity turns on cross-fitting at the cluster level. Once flexible learners cross a complexity (Donsker) boundary, single-fit survey TMLE can severely under-cover, and internal cluster-aware cross-validation does not substitute for cross-fitting; among the estimators we evaluate, only out-of-fold fitting at the cluster level restores valid coverage.
What carries the argument
Survey-weighted TMLE with Taylor-series linearization variance treating the primary sampling unit as the replication unit, combined with cluster-level cross-fitting of the nuisance estimators.
If this is right
- Asymptotic normality holds under the nuisance product-rate condition when cluster-level cross-fitting is applied.
- The linearization variance estimator is design-consistent only with that cross-fitting.
- In simulations, single-fit and internal-CV estimators cover at 0.85-0.91 while cluster-cross-fitted holds at 0.93-0.95.
- An aggressively grown learner drives single-fit coverage as low as 0.22.
- The approach applies to stratified multistage designs and yields open-source software.
Where Pith is reading between the lines
- The same cluster-level cross-fitting requirement may appear in other survey-weighted doubly robust estimators that rely on flexible nuisance fits.
- Dependence induced by the sampling design is not broken by within-cluster cross-validation, which is why it fails to restore coverage.
- The number of primary sampling units likely modulates how large the coverage gain from cluster cross-fitting becomes.
- Extensions to other causal functionals such as the effect on the treated would follow the same cluster-cross-fit logic under the same rate condition.
Load-bearing premise
The product of the convergence rates of the two nuisance estimators must be faster than the square root of sample size.
What would settle it
A simulation or NHANES-style analysis in which the single-fit estimator's coverage falls well below 0.93 while the cluster-cross-fitted version stays near nominal levels.
Figures

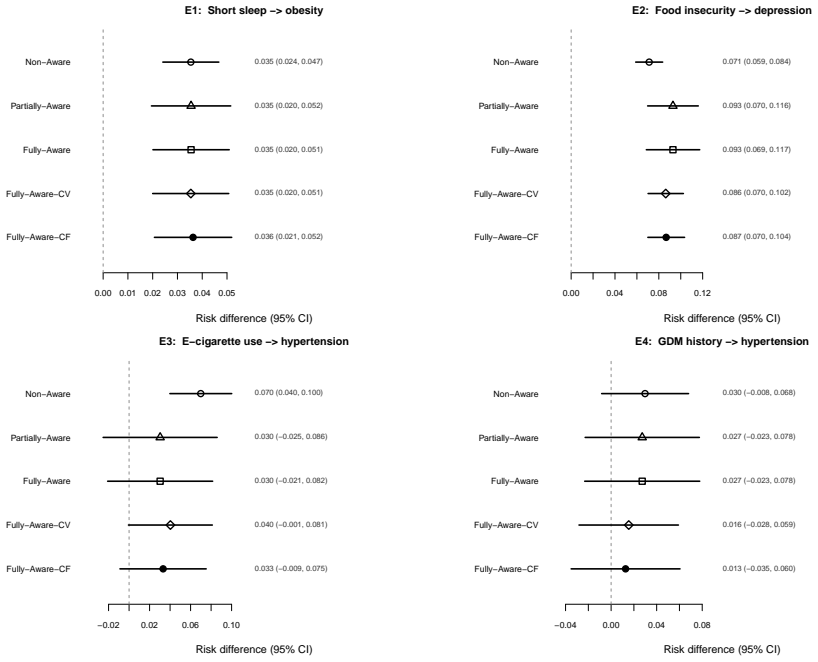
read the original abstract
Cross-fitting is not a refinement of survey-weighted causal machine learning but, once the nuisances are flexible, what restores valid inference. We study the population average treatment effect under a stratified multistage design, estimated by a survey-aware targeted maximum likelihood estimator (TMLE) whose variance is obtained by Taylor-series linearization of the influence function, treating the primary sampling unit as the replication unit. Our central result, established in theory and simulation, is that this validity turns on cross-fitting at the cluster level. Once flexible learners cross a complexity (Donsker) boundary, single-fit survey TMLE can severely under-cover, and internal cluster-aware cross-validation does not substitute for cross-fitting; among the estimators we evaluate, only out-of-fold fitting at the cluster level restores valid coverage. In simulations spanning a many-PSU and an NHANES-like design, on a diverse ensemble the single-fit and internal cross-validation estimators cover at about 0.89-0.91 and 0.85-0.88 while the cross-fitted estimator holds at 0.93-0.95, and an aggressively grown learner drives single-fit coverage to 0.22. Two scope choices are deliberate: survey-weighted point estimation is prior work, and the nuisance product-rate condition is assumed and probed empirically. Within these conditions we prove asymptotic normality and design-consistency of the linearization variance. Four NHANES analyses and open-source software illustrate the method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for estimating the population average treatment effect via survey-weighted TMLE under stratified multistage sampling (with design-based variance from Taylor linearization of the influence function), cluster-level cross-fitting is required to achieve valid coverage once flexible nuisance learners cross the Donsker boundary. Single-fit and internal cluster-aware CV versions under-cover (simulated coverages 0.89-0.91 and 0.85-0.88), while cluster cross-fitting maintains 0.93-0.95; asymptotic normality and design-consistency of the variance are proved under the assumed nuisance product-rate condition, with simulations and four NHANES analyses provided.
Significance. If the results hold within the stated scope, the work usefully extends TMLE to survey settings with modern ML nuisances by isolating the necessity of cluster-level cross-fitting. Credit is due for the explicit scoping of assumptions (product-rate condition assumed and empirically probed), the simulation designs spanning many-PSU and NHANES-like cases, the real-data illustrations, and the open-source software release. These elements support practical adoption.
major comments (1)
- [Abstract] Abstract: the central claim that cluster-level cross-fitting restores valid coverage (while single-fit does not) is conditioned on the nuisance product-rate condition. The manuscript states this condition is assumed rather than derived for the survey-weighted, stratified multistage setting with flexible learners; because the asymptotic normality and linearization-variance consistency proofs rest on it, additional justification or sensitivity analysis for when the condition holds under survey weights would be load-bearing for the comparison of estimators.
minor comments (2)
- [Abstract] Abstract: the reported coverage ranges (0.89-0.91, 0.85-0.88, 0.93-0.95) and the 0.22 figure for the aggressively grown learner should cite the specific simulation table or section where the ensemble and design variants are tabulated.
- The distinction between 'internal cluster-aware cross-validation' and true out-of-fold cluster cross-fitting could be clarified with a short algorithmic pseudocode or diagram in the methods section.
Simulated Author's Rebuttal
We appreciate the referee's careful review and recommendation for minor revision. Below we provide a point-by-point response to the major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that cluster-level cross-fitting restores valid coverage (while single-fit does not) is conditioned on the nuisance product-rate condition. The manuscript states this condition is assumed rather than derived for the survey-weighted, stratified multistage setting with flexible learners; because the asymptotic normality and linearization-variance consistency proofs rest on it, additional justification or sensitivity analysis for when the condition holds under survey weights would be load-bearing for the comparison of estimators.
Authors: We agree that the product-rate condition is assumed rather than derived, as explicitly stated in the manuscript. This is a deliberate scope choice, consistent with the broader TMLE literature where the condition is imposed on the nuisance estimators to guarantee the desired asymptotics when flexible learners are used. The proofs show that under this condition, cluster cross-fitting is necessary for valid inference, while single-fit is not. Survey weights are incorporated into the weighted loss functions for nuisance estimation, but the product-rate condition takes the same form as in the unweighted case. The simulations already include sensitivity analysis by varying the complexity of the learners (including an aggressively grown learner that drives single-fit coverage to 0.22) under both many-PSU and NHANES-like designs with survey weights. To further address the comment, we will revise the abstract to state the assumption more explicitly at the outset and add a sentence in the discussion clarifying that the condition is probed empirically rather than derived. We believe this strengthens the presentation without altering the scope. revision: yes
Circularity Check
Minor self-citation on point estimation; central cross-fitting claim remains independent
full rationale
The paper states that survey-weighted point estimation is prior work and assumes the nuisance product-rate condition (probed in simulations), then proves asymptotic normality and design-consistency of the linearization variance within those conditions. No equations or claims reduce the central result (necessity of cluster-level cross-fitting for valid coverage with flexible learners) to a fitted quantity defined by the same data or to a self-citation chain by construction. Simulations are presented as an independent empirical check. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption nuisance product-rate condition
Reference graph
Works this paper leans on
-
[1]
1999 , publisher =
Analysis of Health Surveys , author =. 1999 , publisher =
1999
-
[2]
The American Statistician , volume=
High-dimensional propensity score and its machine learning extensions in residual confounding control , author=. The American Statistician , volume=. 2025 , publisher=
2025
-
[3]
Sankhya , volume=
Regression analysis for sample survey , author=. Sankhya , volume=
-
[4]
Journal of the American Statistical Association , volume=
A simple method for approximating the variance of a complicated estimate , author=. Journal of the American Statistical Association , volume=. 1971 , publisher=
1971
-
[5]
Targeted Learning: Causal Inference for Observational and Experimental Data , pages=
Foundations of TMLE , author=. Targeted Learning: Causal Inference for Observational and Experimental Data , pages=. 2011 , publisher=
2011
-
[6]
Journal of Statistical Software , volume=
tmle: an R package for targeted maximum likelihood estimation , author=. Journal of Statistical Software , volume=
-
[7]
Research Methods in Medicine & Health Sciences , volume=
Implementing TMLE in the presence of a continuous outcome , author=. Research Methods in Medicine & Health Sciences , volume=. 2024 , publisher=
2024
-
[8]
Statistics in medicine , volume=
Targeted maximum likelihood estimation for a binary treatment: A tutorial , author=. Statistics in medicine , volume=. 2018 , publisher=
2018
-
[9]
The international journal of biostatistics , volume=
Targeted maximum likelihood learning , author=. The international journal of biostatistics , volume=. 2006 , publisher=
2006
-
[10]
Statistical methods in medical research , volume=
Evaluating treatment effectiveness under model misspecification: a comparison of targeted maximum likelihood estimation with bias-corrected matching , author=. Statistical methods in medical research , volume=. 2016 , publisher=
2016
-
[11]
Epidemiology , volume=
Targeted maximum likelihood estimation for pharmacoepidemiologic research , author=. Epidemiology , volume=. 2016 , publisher=
2016
-
[12]
Annals of epidemiology , volume=
Application of targeted maximum likelihood estimation in public health and epidemiological studies: a systematic review , author=. Annals of epidemiology , volume=. 2023 , publisher=
2023
-
[13]
Journal of preventive medicine and public health , volume=
Inappropriate survey design analysis of the Korean National Health and Nutrition Examination Survey may produce biased results , author=. Journal of preventive medicine and public health , volume=
-
[14]
Public health nutrition , volume=
How to use replicate weights in health survey analysis using the National Nutrition and Physical Activity Survey as an example , author=. Public health nutrition , volume=. 2019 , publisher=
2019
-
[15]
2022 , publisher=
Comparison of National Data Sources to Assess Preventive Care in the US Population , author=. 2022 , publisher=
2022
-
[16]
Journal of Health Monitoring , volume=
European health interview survey (EHIS) 2--background and study methodology , author=. Journal of Health Monitoring , volume=
-
[17]
1995 , publisher=
A guide to living standards measurement study surveys and their data sets , author=. 1995 , publisher=
1995
-
[18]
Health reports , volume=
Combining cycles of the Canadian community health survey , author=. Health reports , volume=. 2009 , publisher=
2009
-
[19]
International journal of epidemiology , volume=
Demographic and health surveys: a profile , author=. International journal of epidemiology , volume=. 2012 , publisher=
2012
-
[20]
American Journal of Obstetrics & Gynecology MFM , volume=
Trends in gestational diabetes mellitus among nulliparous pregnant individuals with singleton live births in the United States between 2011 to 2019: an age-period-cohort analysis , author=. American Journal of Obstetrics & Gynecology MFM , volume=. 2023 , publisher=
2011
-
[21]
Diabetes Research and Clinical Practice , year=
Gestational diabetes: The public health relevance and approach , author=. Diabetes Research and Clinical Practice , year=
-
[22]
PLoS medicine , volume=
Increased risk of ischemic heart disease, hypertension, and type 2 diabetes in women with previous gestational diabetes mellitus, a target group in general practice for preventive interventions: a population-based cohort study , author=. PLoS medicine , volume=. 2018 , publisher=
2018
-
[23]
2009 , note =
National Health and Nutrition Examination Survey: Blood Pressure Procedures Manual , author =. 2009 , note =
2009
-
[24]
Statistics in medicine , volume=
Multiple imputation using chained equations: issues and guidance for practice , author=. Statistics in medicine , volume=. 2011 , publisher=
2011
-
[25]
AStA Advances in Statistical Analysis , volume=
Semiparametric predictive mean matching , author=. AStA Advances in Statistical Analysis , volume=. 2009 , publisher=
2009
-
[26]
Pharmaceutical Statistics , pages=
Finding the Optimal Number of Splits and Repetitions in Double Cross-Fitting Targeted Maximum Likelihood Estimators , author=. Pharmaceutical Statistics , pages=. 2025 , doi=
2025
-
[27]
American Journal of Epidemiology , pages=
Towards Robust Causal Inference in Epidemiological Research: Employing Double Cross-fit TMLE in Right Heart Catheterization Data , author=. American Journal of Epidemiology , pages=. 2024 , publisher=
2024
-
[28]
Diabetes care , volume=
Increased risk of hypertension after gestational diabetes mellitus: findings from a large prospective cohort study , author=. Diabetes care , volume=. 2011 , publisher=
2011
-
[29]
American journal of epidemiology , volume=
Implementation of G-computation on a simulated data set: demonstration of a causal inference technique , author=. American journal of epidemiology , volume=. 2011 , publisher=
2011
-
[30]
Hypertension , volume=
Association between gestational diabetes mellitus and hypertension: a systematic review and meta-analysis of cohort studies with a quantitative bias analysis of uncontrolled confounding , author=. Hypertension , volume=. 2024 , publisher=
2024
-
[31]
International Statistical Review , volume=
Efficient and robust propensity-score-based methods for population inference using epidemiologic cohorts , author=. International Statistical Review , volume=. 2022 , publisher=
2022
-
[32]
The Wiley Handbook of Psychometric Testing: A Multidisciplinary Reference on Survey, Scale and Test Development , editor =
Lu, Bo and Lemeshow, Stanley , title =. The Wiley Handbook of Psychometric Testing: A Multidisciplinary Reference on Survey, Scale and Test Development , editor =. 2018 , pages =
2018
-
[33]
Journal of data Science , volume=
A comparison of propensity score and linear regression analysis of complex survey data , author=. Journal of data Science , volume=
-
[34]
Biostatistics , volume=
It's all about balance: propensity score matching in the context of complex survey data , author=. Biostatistics , volume=. 2019 , publisher=
2019
-
[35]
Health Services and Outcomes Research Methodology , pages=
Propensity score weighting analysis with complex survey data for estimating population-level treatment effects on survival: a simulation study , author=. Health Services and Outcomes Research Methodology , pages=. 2025 , publisher=
2025
-
[36]
Journal of Survey Statistics and Methodology , pages=
Comparative effectiveness of propensity score estimation methods for inverse probability of treatment weighting analysis with complex survey data: a simulation study , author=. Journal of Survey Statistics and Methodology , pages=. 2025 , publisher=
2025
-
[37]
Statistical methods in medical research , volume=
Propensity score matching and complex surveys , author=. Statistical methods in medical research , volume=. 2018 , publisher=
2018
-
[38]
, author=
Combining Propensity Score Methods and Complex Survey Data to Estimate Population Treatment Effects. , author=. Society for Research on Educational Effectiveness , year=
-
[39]
Health services research , volume=
Generalizing observational study results: applying propensity score methods to complex surveys , author=. Health services research , volume=. 2014 , publisher=
2014
-
[40]
The American Statistician , volume=
Causal Inference with Complex Surveys: A Unified Perspective on Sample Selection and Exposure Selection , author=. The American Statistician , volume=. 2025 , publisher=
2025
-
[41]
Journal of causal inference , volume=
Propensity score analysis with survey weighted data , author=. Journal of causal inference , volume=. 2015 , publisher=
2015
-
[42]
Computational statistics & data analysis , volume=
Measuring model misspecification: Application to propensity score methods with complex survey data , author=. Computational statistics & data analysis , volume=. 2018 , publisher=
2018
-
[43]
The American Journal of Clinical Nutrition , volume=
Critical data at the crossroads: the National Health and Nutrition Examination Survey faces growing challenges , author=. The American Journal of Clinical Nutrition , volume=. 2023 , publisher=
2023
-
[44]
BMC global and public health , volume=
Analytic methodology for childhood predictor analyses for Wave 1 of the Global Flourishing Study , author=. BMC global and public health , volume=. 2025 , publisher=
2025
-
[45]
2011 , publisher=
Targeted learning: causal inference for observational and experimental data , author=. 2011 , publisher=
2011
-
[46]
International Statistical Review/Revue Internationale de Statistique , volume=
On the variances of asymptotically normal estimators from complex surveys , author=. International Statistical Review/Revue Internationale de Statistique , volume=. 1983 , publisher=
1983
-
[47]
Canadian Stata Users Group Meeting , volume=
Survey data analysis in Stata , author=. Canadian Stata Users Group Meeting , volume=
-
[48]
Journal of Causal Inference , volume=
A fundamental measure of treatment effect heterogeneity , author=. Journal of Causal Inference , volume=. 2021 , publisher=
2021
-
[49]
2017 , publisher=
Applied Survey Data Analysis , author=. 2017 , publisher=
2017
-
[50]
arXiv preprint arXiv:2106.10577 , year=
Choosing the causal estimand for propensity score analysis of observational studies , author=. arXiv preprint arXiv:2106.10577 , year=
-
[51]
2010 , publisher=
Complex Surveys: A Guide to Analysis Using R , author=. 2010 , publisher=
2010
-
[52]
Stat , volume=
K-fold cross-validation for complex sample surveys , author=. Stat , volume=. 2022 , publisher=
2022
-
[53]
Pharmacoepidemiology and Drug Safety , volume=
How Effective Are Machine Learning and Doubly Robust Estimators in Incorporating High-Dimensional Proxies to Reduce Residual Confounding? , author=. Pharmacoepidemiology and Drug Safety , volume=. 2025 , publisher=
2025
-
[54]
American Journal of Epidemiology , volume=
Invited commentary: demystifying statistical inference when using machine learning in causal research , author=. American Journal of Epidemiology , volume=. 2023 , publisher=
2023
-
[55]
American Journal of Epidemiology , volume=
Challenges in obtaining valid causal effect estimates with machine learning algorithms , author=. American Journal of Epidemiology , volume=. 2023 , publisher=
2023
-
[56]
Statistical Science , volume=
Demystifying Double Robustness: A Comparison of Alternative Strategies for Estimating a Population Mean from Incomplete Data , author=. Statistical Science , volume=
-
[57]
Statistics in medicine , volume=
Using simulation studies to evaluate statistical methods , author=. Statistics in medicine , volume=. 2019 , publisher=
2019
-
[58]
Biostatistics , volume=
Two-Stage TMLE to reduce bias and improve efficiency in cluster randomized trials , author=. Biostatistics , volume=. 2023 , publisher=
2023
-
[59]
Clinical Trials , pages=
Causal inference in randomized trials with partial clustering , author=. Clinical Trials , pages=. 2025 , publisher=
2025
-
[60]
Statistical Methods in Medical Research , volume=
A new approach to hierarchical data analysis: Targeted maximum likelihood estimation for the causal effect of a cluster-level exposure , author=. Statistical Methods in Medical Research , volume=. 2019 , publisher=
2019
-
[61]
The Annals of Statistics , volume=
Inference from stratified samples: properties of the linearization, jackknife and balanced repeated replication methods , author=. The Annals of Statistics , volume=. 1981 , publisher=
1981
-
[62]
Journal of the American statistical Association , volume=
Estimation of regression coefficients when some regressors are not always observed , author=. Journal of the American statistical Association , volume=. 1994 , publisher=
1994
-
[63]
Annals of statistics , volume=
Weighted likelihood estimation under two-phase sampling , author=. Annals of statistics , volume=. 2013 , publisher=
2013
-
[64]
Scandinavian Journal of Statistics , volume=
Weighted likelihood for semiparametric models and two-phase stratified samples, with application to Cox regression , author=. Scandinavian Journal of Statistics , volume=. 2007 , publisher=
2007
-
[65]
The Econometrics Journal , volume=
Double/debiased machine learning for treatment and structural parameters , author=. The Econometrics Journal , volume=. 2018 , publisher=
2018
-
[66]
The Annals of Statistics , volume=
On the two-phase framework for joint model and design-based inference , author=. The Annals of Statistics , volume=. 2005 , publisher=
2005
-
[67]
Journal of Business & Economic Statistics , volume=
Multiway cluster robust double/debiased machine learning , author=. Journal of Business & Economic Statistics , volume=. 2022 , publisher=
2022
-
[68]
Targeted Learning: Causal Inference for Observational and Experimental Data , editor=
Cross-validated targeted minimum-loss-based estimation , author=. Targeted Learning: Causal Inference for Observational and Experimental Data , editor=. 2011 , publisher=
2011
-
[69]
Handbook of Statistical Methods for Precision Medicine , pages=
Semiparametric doubly robust targeted double machine learning: a review , author=. Handbook of Statistical Methods for Precision Medicine , pages=. 2024 , publisher=
2024
-
[70]
The Annals of Mathematical Statistics , volume=
Asymptotic theory of rejective sampling with varying probabilities from a finite population , author=. The Annals of Mathematical Statistics , volume=. 1964 , publisher=
1964
-
[71]
Econometrica , volume=
On the role of the propensity score in efficient semiparametric estimation of average treatment effects , author=. Econometrica , volume=. 1998 , publisher=
1998
-
[72]
International Statistical Review/Revue Internationale de Statistique , pages=
The role of sampling weights when modeling survey data , author=. International Statistical Review/Revue Internationale de Statistique , pages=. 1993 , publisher=
1993
-
[73]
On the use of cross-fitting in causal machine learning with correlated units
On the use of cross-fitting in causal machine learning with correlated units , author=. arXiv preprint arXiv:2601.10899 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Machine learning methods for finite population parameter estimation in survey sampling
Machine learning methods for finite population parameter estimation in survey sampling , author=. arXiv preprint arXiv:2604.01160 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Changepoint Detection in Complex Models: Cross-Fitting Is Needed
Changepoint Detection in Complex Models: Cross-Fitting Is Needed , author=. arXiv preprint arXiv:2411.07874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
P. C. Austin, N. Jembere, and M. Chiu. Propensity score matching and complex surveys. Statistical methods in medical research, 27 0 (4): 0 1240--1257, 2018
2018
-
[77]
L. B. Balzer, W. Zheng, M. J. van der Laan, and M. L. Petersen. A new approach to hierarchical data analysis: Targeted maximum likelihood estimation for the causal effect of a cluster-level exposure. Statistical Methods in Medical Research, 28 0 (6): 0 1761--1780, 2019. doi:10.1177/0962280218774936
-
[78]
L. B. Balzer, M. van der Laan, J. Ayieko, M. Kamya, G. Chamie, J. Schwab, D. V. Havlir, and M. L. Petersen. Two-stage tmle to reduce bias and improve efficiency in cluster randomized trials. Biostatistics, 24 0 (2): 0 502--517, 2023. doi:10.1093/biostatistics/kxab043
-
[79]
D. A. Binder. On the variances of asymptotically normal estimators from complex surveys. International Statistical Review/Revue Internationale de Statistique, 51 0 (3): 0 279--292, 1983
1983
-
[80]
N. E. Breslow and J. A. Wellner. Weighted likelihood for semiparametric models and two-phase stratified samples, with application to cox regression. Scandinavian Journal of Statistics, 34 0 (1): 0 86--102, 2007
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.