Beyond Compilation: Evaluating Faithful Natural-Language-to-Lean Statement Formalization
Pith reviewed 2026-07-01 00:54 UTC · model grok-4.3
The pith
Natural-language-to-Lean formalization requires more than compilation, as agents reach 89.5 percent compilation yet only 60.5 percent consensus faithfulness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
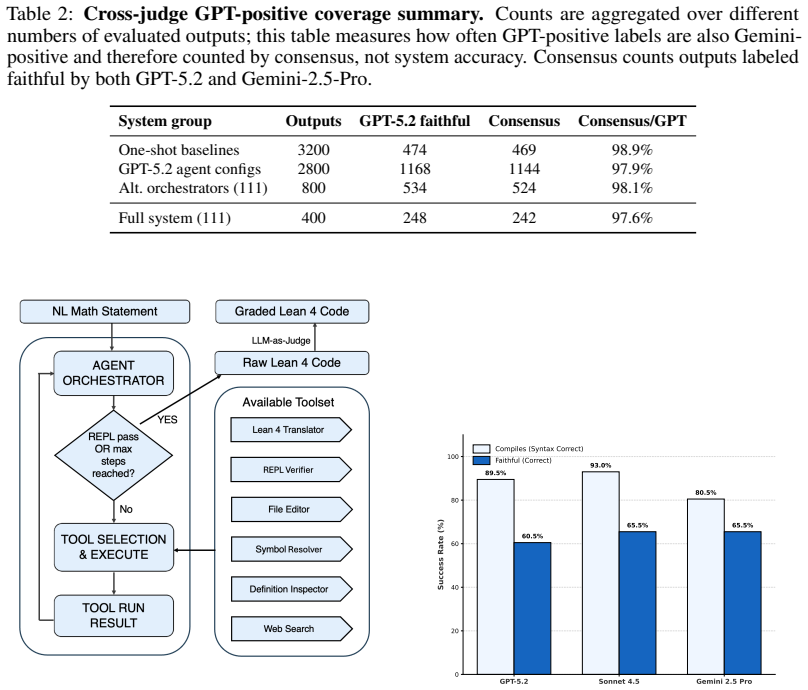
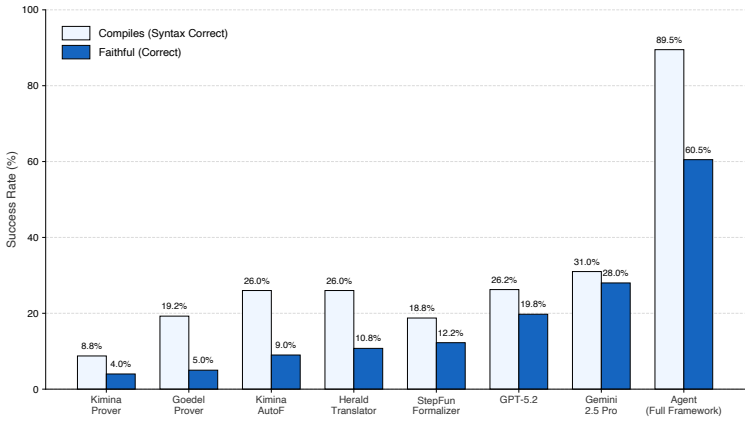
A complete tool-augmented agent reaches 89.5 percent compilation success but only 60.5 percent consensus faithfulness on the benchmark, creating a 29-point gap of compile-pass yet consensus-unfaithful statements. Targeted human audits confirm that 96.0 percent of consensus-positive cases are human-confirmed faithful while 82.4 percent of compile-pass consensus-negative cases are human-confirmed semantic failures. Existing one-shot formalizer models and prover-oriented Lean models remain low under this metric, and the three interventions (drafting, search, feedback) play distinct roles, with elaboration feedback boosting validity most while also enlarging the semantic-failure bucket.
What carries the argument
The consensus faithfulness metric produced by Lean compilation, cross-model semantic judging, and human expert calibration on the 400-entry graduate benchmark.
If this is right
- Elaboration feedback is the largest single contributor to compilation validity but also increases the size of the compile-pass semantic-failure bucket.
- Mathlib and context search mainly improve grounding and selectivity rather than raw compilation rate.
- Fine-tuned expert drafting becomes largely substitutable once elaboration feedback and search are available in the pipeline.
- Formal validity, proof-oriented Lean competence, and faithful statement generation are distinct capabilities that should be measured and reported separately.
- Current one-shot formalizer models and prover-oriented Lean models score low on the faithfulness metric.
Where Pith is reading between the lines
- Future formalization pipelines may need explicit semantic-alignment stages beyond compilation or proof-search feedback.
- The same compilation-faithfulness gap is likely to appear when translating to other systems such as Coq or Isabelle.
- Reducing reliance on human calibration may be possible if cross-model agreement continues to track expert judgment at scale.
Load-bearing premise
Cross-model semantic judging together with human expert calibration correctly separates faithful formalizations from compile-pass but semantically altered ones.
What would settle it
A large-scale human audit of the compile-pass consensus-negative cases that finds substantially more than 17.6 percent are actually faithful to the source statement.
Figures
read the original abstract
Theorem-proving benchmarks evaluate proof search against fixed formal statements, but natural-language-to-Lean formalization must generate the formal statement itself. In this setting, compilation is only a validity check: a Lean declaration may type-check while omitting hypotheses, changing domains, or expressing a vacuous claim. We study faithful statement formalization as both an evaluation problem and a bottleneck-attribution problem. On a 400-entry graduate-level benchmark spanning real analysis, complex analysis, topology, and algebra, our protocol combines Lean compilation, cross-model semantic judging, and human expert calibration. The resulting picture is different from compile-rate evaluation: a full tool-augmented agent reaches 89.5% compilation but only 60.5% consensus faithfulness, exposing a 29.0-point compile-pass but consensus-unfaithful gap. Targeted human audits support the metric as a conservative decision boundary: across available case-level audits, 96.0% of consensus-positive outputs are human-confirmed faithful, while 82.4% of compile-pass consensus-negative outputs are human-confirmed semantic failures. Under this metric, existing one-shot formalizer models and prover-oriented Lean models remain low, suggesting that formal validity, proof-oriented Lean competence, and faithful statement generation should be reported separately. We then use a full $2^3$ factorial design to decompose three recurring interventions in formalization pipelines: parametric expert drafting, Mathlib/context search, and Lean elaboration feedback. Elaboration feedback is the largest validity intervention, but it also exposes a larger compile-pass semantic-failure bucket; search mainly improves grounding and selectivity; and fine-tuned drafting is largely substitutable in this tool stack once feedback and grounding are available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that compilation success alone is insufficient to evaluate natural-language-to-Lean statement formalization, as valid Lean declarations can still omit hypotheses, alter domains, or produce vacuous claims. On a 400-entry graduate-level benchmark spanning real analysis, complex analysis, topology, and algebra, a tool-augmented agent reaches 89.5% compilation but only 60.5% consensus faithfulness (a 29-point gap) when using Lean compilation, cross-model semantic judging, and human expert calibration. Targeted audits show 96% human confirmation on consensus-positive cases and 82.4% confirmation of semantic failure on compile-pass consensus-negative cases. A 2^3 factorial design decomposes the effects of parametric expert drafting, Mathlib/context search, and Lean elaboration feedback, finding elaboration feedback strongest for validity but also increasing the compile-pass semantic-failure bucket.
Significance. If the faithfulness metric holds, the work shows that formal validity, proof-oriented Lean competence, and faithful statement generation must be reported separately, with implications for theorem-proving benchmark design. Credit is due for grounding evaluation in an external Lean compiler, independent model judges, human calibration, and a full factorial design that attributes contributions of drafting, search, and feedback without fitted parameters. The 400-entry benchmark size supports the scale of the claims.
major comments (2)
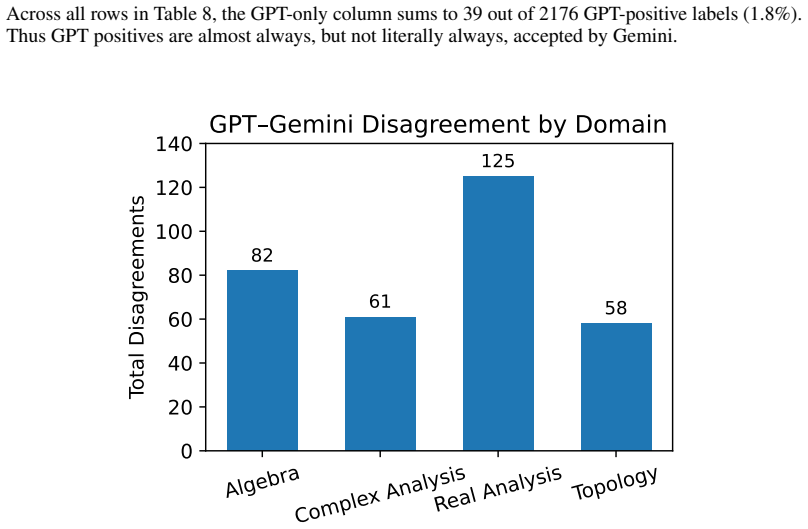
- [Evaluation protocol and human audits] The 29-point compilation-vs-faithfulness gap rests on the cross-model consensus metric being a reliable proxy for faithfulness. The description of targeted human audits (reporting 96.0% confirmation on consensus-positive cases and 82.4% on compile-pass consensus-negative cases) does not specify the selection criteria or whether the audited subset was drawn randomly from the 400 entries; without this, the confirmation rates may not generalize, weakening the central claim that the metric is a conservative decision boundary.
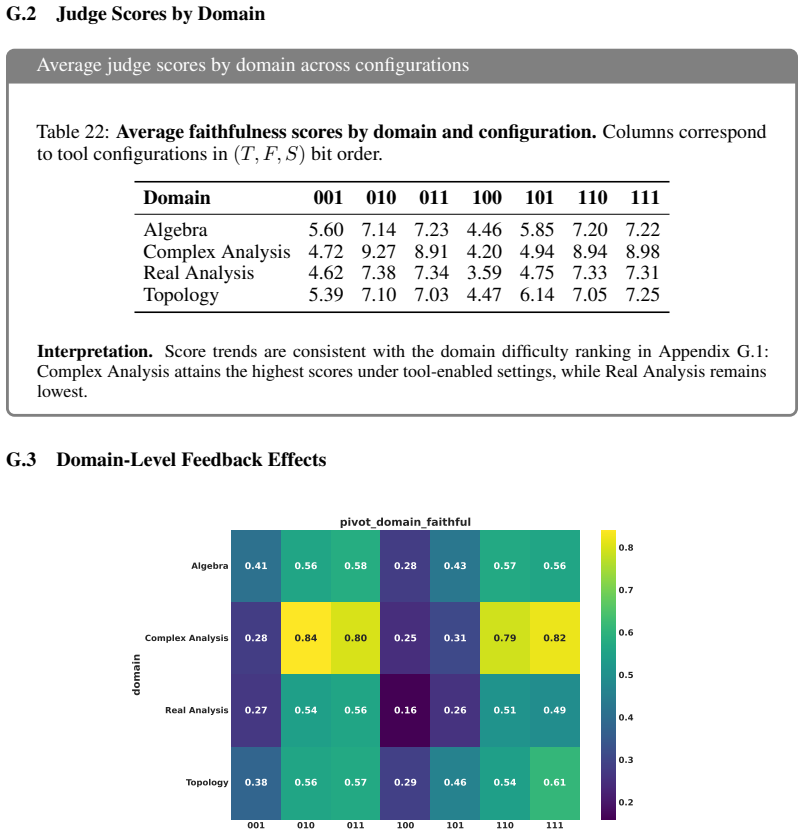
- [Evaluation protocol] The abstract and evaluation section provide no details on how cross-model semantic consensus is computed (e.g., voting threshold, prompt templates, or handling of disagreements), inter-rater reliability among model judges, or statistical tests on the factorial results; these omissions are load-bearing because the 60.5% faithfulness figure and the 2^3 decomposition both depend on the stability of the consensus procedure.
minor comments (1)
- [Abstract] The abstract refers to 'parametric expert drafting' without a brief parenthetical definition; the factorial section should make the three factors explicit on first use.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments both concern transparency in the evaluation protocol. We agree that additional details are needed and will expand the manuscript accordingly in revision. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Evaluation protocol and human audits] The 29-point compilation-vs-faithfulness gap rests on the cross-model consensus metric being a reliable proxy for faithfulness. The description of targeted human audits (reporting 96.0% confirmation on consensus-positive cases and 82.4% on compile-pass consensus-negative cases) does not specify the selection criteria or whether the audited subset was drawn randomly from the 400 entries; without this, the confirmation rates may not generalize, weakening the central claim that the metric is a conservative decision boundary.
Authors: The manuscript already characterizes the audits as 'targeted' and reports results only 'across available case-level audits,' which indicates they were not a random sample. Audits were allocated according to expert reviewer availability and prioritized cases with decisive consensus signals to calibrate the metric boundary. We acknowledge that explicit selection criteria and the non-random nature should be stated more clearly. In revision we will add a paragraph detailing the criteria (availability-constrained, consensus-boundary focus) while retaining the reported confirmation rates as supporting evidence rather than a claim of statistical generalization. revision: yes
-
Referee: [Evaluation protocol] The abstract and evaluation section provide no details on how cross-model semantic consensus is computed (e.g., voting threshold, prompt templates, or handling of disagreements), inter-rater reliability among model judges, or statistical tests on the factorial results; these omissions are load-bearing because the 60.5% faithfulness figure and the 2^3 decomposition both depend on the stability of the consensus procedure.
Authors: We agree the current text is insufficiently detailed on these implementation choices. The full manuscript mentions cross-model judging but omits the precise voting rule, prompt wording, disagreement resolution, inter-rater statistics, and statistical tests for the factorial design. In the revised version we will insert a new subsection that specifies the consensus rule (at least two of three models), provides the prompt templates, reports inter-rater agreement, and includes ANOVA results for the 2^3 design. These additions will not change the numerical findings but will make the protocol fully reproducible. revision: yes
Circularity Check
No circularity; evaluation chain relies on external Lean compiler, independent cross-model judges, and human experts
full rationale
The paper defines faithfulness via compilation plus cross-model semantic consensus, then validates the boundary with targeted human audits (96% confirmation on positives, 82.4% on negatives). None of these steps reduce to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations; the metric is constructed from independent external components (Lean, separate LLMs, human experts) whose outputs are not tautological with the inputs. The 2^3 factorial decomposition of interventions is likewise an experimental design, not a self-referential fit. No enumerated circularity pattern applies.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 400-entry benchmark spanning real analysis, complex analysis, topology, and algebra is representative of the domains where faithful formalization matters
- domain assumption Cross-model semantic judging plus human calibration provides a reliable and conservative measure of faithfulness
Reference graph
Works this paper leans on
-
[1]
Basic Analysis: Introduction to Real Analysis , howpublished =
Ji. Basic Analysis: Introduction to Real Analysis , howpublished =
-
[2]
Guide to Cultivating Complex Analysis: Working the Complex Field , howpublished =
Ji. Guide to Cultivating Complex Analysis: Working the Complex Field , howpublished =
-
[3]
Benjamin McKay , title =
-
[4]
Doty , title =
Stephen R. Doty , title =
-
[5]
Automated Deduction -- CADE 28 , series =
de Moura, Leonardo and Ullrich, Sebastian , title =. Automated Deduction -- CADE 28 , series =. 2021 , doi =
2021
-
[6]
Castelvecchi, Davide , journal=
-
[7]
1995 , note =
Stuart Russell and Peter Norvig , title =. 1995 , note =
1995
-
[8]
International Conference on Learning Representations (ICLR) , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. International Conference on Learning Representations (ICLR) , year =
-
[9]
The Lean Mathematical Library , booktitle =. 2020 , pages =. doi:10.1145/3372885.3373824 , note =
-
[10]
Lean Copilot: Large Language Models as Copilots for Theorem Proving in Lean , author=
-
[11]
Advances in Neural Information Processing Systems , volume=
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
arXiv preprint arXiv:2506.19923 , year=
Prover Agent: An Agent-based Framework for Formal Mathematical Proofs , author=. arXiv preprint arXiv:2506.19923 , year=
-
[13]
ACM Transactions on Software Engineering and Methodology , volume=
LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision, and the Road Ahead , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2025 , publisher=
2025
-
[14]
IJCAI , year=
Large Language Model Based Multi-agents: A Survey of Progress and Challenges , author=. IJCAI , year=
-
[15]
2025 , url =
FineLeanCorpus: A Large-Scale, High-Quality Lean 4 Formalization Dataset , author =. 2025 , url =
2025
-
[16]
CoRR , year=
TheoremLlama: Transforming General-Purpose LLMs into Lean4 Experts , author=. CoRR , year=
-
[17]
arXiv preprint arXiv:2507.06181 , year =
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization , author =. arXiv preprint arXiv:2507.06181 , year =
-
[18]
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models , author =. arXiv preprint arXiv:2410.07985 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning , author =. arXiv preprint arXiv:2504.11456 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proceedings Symposium on Automatic Demonstration (Versailles, France, December 1968) , editor =
The Mathematical Language AUTOMATH, its Usage, and Some of its Extensions , author =. Proceedings Symposium on Automatic Demonstration (Versailles, France, December 1968) , editor =. 1970 , doi =
1968
-
[21]
A Survey of the Project AUTOMATH , author =. To H. B. Curry: Essays in Combinatory Logic, Lambda Calculus and Formalism , editor =
-
[22]
2024 , publisher =
Bulletin of the American Mathematical Society , journal =. 2024 , publisher =
2024
-
[23]
Nature , volume=
Solving olympiad geometry without human demonstrations , author=. Nature , volume=. 2024 , publisher=
2024
-
[24]
Missing undergraduate mathematics in
-
[25]
2024 , volume =
Bulletin of the American Mathematical Society, New Series, Volume 61, Number 2 , publisher =. 2024 , volume =
2024
-
[26]
arXiv preprint arXiv:2506.05614 , year=
Which Prompting Technique Should I Use? An Empirical Investigation of Prompting Techniques for Software Engineering Tasks , author=. arXiv preprint arXiv:2506.05614 , year=
-
[27]
When more is less: Understanding chain-of-thought length in
Wu, Yuyang and Wang, Yifei and Ye, Ziyu and Du, Tianqi and Jegelka, Stefanie and Wang, Yisen , journal=. When more is less: Understanding chain-of-thought length in
-
[28]
What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
Yang, Chenyang and Shi, Yike and Ma, Qianou and Liu, Michael Xieyang and K. What Prompts Don't Say: Understanding and Managing Underspecification in. arXiv preprint arXiv:2505.13360 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
ICLR , year=
miniF2F: a cross-system benchmark for formal Olympiad-level mathematics , author=. ICLR , year=
-
[30]
Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition , author=. arXiv preprint arXiv:2504.21801 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Kimina-prover preview: Towards large formal reasoning models with reinforcement learning , author=. arXiv preprint arXiv:2504.11354 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
arXiv preprint arXiv:2302.12433 , year=
Proofnet: Autoformalizing and formally proving undergraduate-level mathematics , author=. arXiv preprint arXiv:2302.12433 , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Lean workbook: A large-scale lean problem set formalized from natural language math problems , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Process-driven autoformalization in lean 4
Process-Driven Autoformalization in Lean 4 , author=. arXiv preprint arXiv:2406.01940 , year=
-
[35]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =
A Semantic Search Engine for Mathlib4 , author =. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =. 2024 , publisher =. doi:10.18653/v1/2024.findings-emnlp.470 , url =
-
[36]
The Thirteenth International Conference on Learning Representations , year=
Herald: A Natural Language Annotated Lean 4 Dataset , author=. The Thirteenth International Conference on Learning Representations , year=
-
[37]
The Thirteenth International Conference on Learning Representations , year =
FormalAlign: Automated Alignment Evaluation for Autoformalization , author =. The Thirteenth International Conference on Learning Representations , year =
-
[38]
How well do
Lee, Ayeong and Che, Ethan and Peng, Tianyi , journal=. How well do
-
[39]
arXiv preprint arXiv:2505.23486 , year=
Autoformalization in the Era of Large Language Models: A Survey , author=. arXiv preprint arXiv:2505.23486 , year=
-
[40]
Proceedings of ICLR 2025 (Spotlight) , year =
Rethinking and Improving Autoformalization: Towards a Faithful Metric and a Dependency Retrieval-based Approach , author =. Proceedings of ICLR 2025 (Spotlight) , year =
2025
-
[41]
Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction
Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction , author =. arXiv preprint arXiv:2508.03613 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
StepFun-Formalizer: Unlocking the Autoformalization Potential of LLMs Through Knowledge-Reasoning Fusion , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2026 , doi =
2026
-
[43]
An investigation of prompt variations for zero-shot
Sun, Shuoqi and Zhuang, Shengyao and Wang, Shuai and Zuccon, Guido , booktitle=. An investigation of prompt variations for zero-shot. 2025 , organization=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.