TactX: Learning Shared Tactile Representations Across Diverse Sensors
Pith reviewed 2026-07-01 05:21 UTC · model grok-4.3
The pith
TactX learns a shared latent space across tactile sensors of different types, enabling zero-shot policy transfer between them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
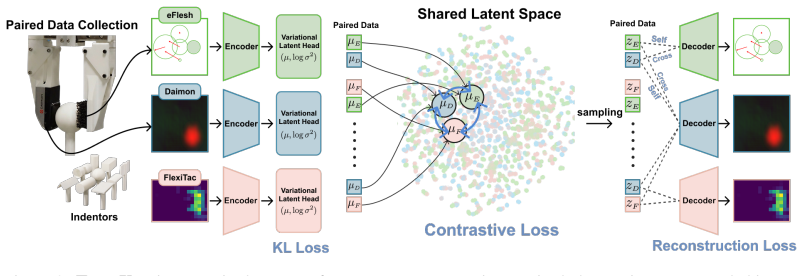
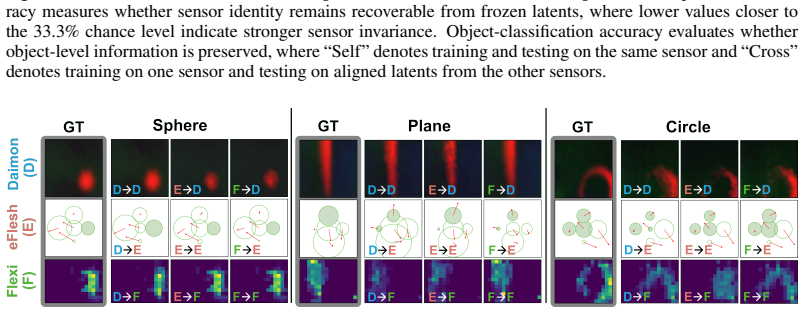
TactX maps heterogeneous tactile observations into a shared latent space through modality-specific encoders trained on paired contact data. Such paired interactions provide a natural alignment signal across modalities, and the encoders are jointly trained across all sensor pairs, inducing a consistent latent space for all sensor types. Our experiments show that TactX aligns tactile representations across sensors while preserving object-level contact information. Policies trained with one sensor transfer zero-shot to physically distinct sensors through the shared latent, improving the average success rate from 27.5% for vision-only policy to 45.9% on four contact-rich manipulation tasks.
What carries the argument
modality-specific encoders jointly trained on paired contact data to induce a consistent latent space across resistive, magnetic, and vision-based sensors
If this is right
- Policies trained on data from one tactile sensor can be deployed on different sensors without retraining.
- Success rates on pick-and-place, plug insertion, board wiping, and object reorientation tasks increase to an average of 45.9%.
- The latent space supports both alignment across sensors and preservation of object contact details.
- Manipulation policies become less dependent on specific tactile hardware.
Where Pith is reading between the lines
- Hardware choices for robots could become more flexible if sensors can be swapped without policy changes.
- Collecting paired contact data might be a scalable way to align new sensor types in the future.
- The approach could extend to other sensing modalities beyond tactile if similar pairing is possible.
Load-bearing premise
Paired contact interactions supply a sufficient natural alignment signal to induce a consistent latent space across all three transduction modalities while preserving object-level contact information.
What would settle it
Zero-shot transfer experiments yielding success rates no higher than the 27.5% vision-only baseline on the manipulation tasks would indicate the shared latent does not enable effective cross-sensor policy use.
Figures




read the original abstract
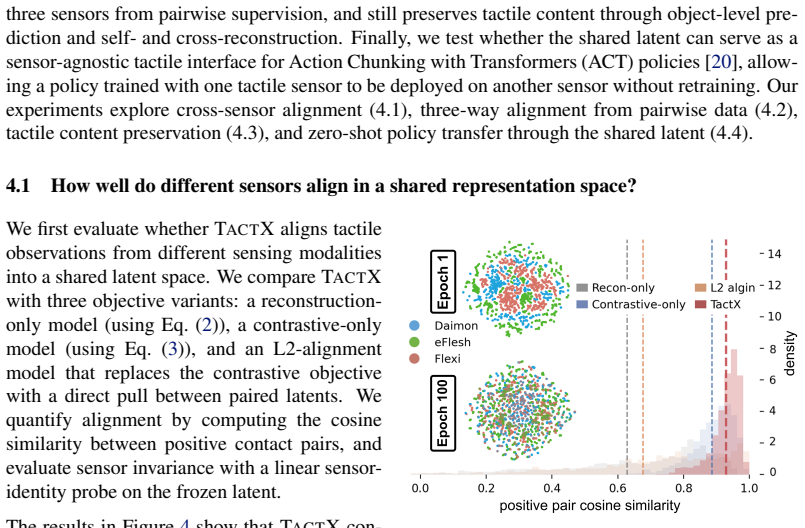
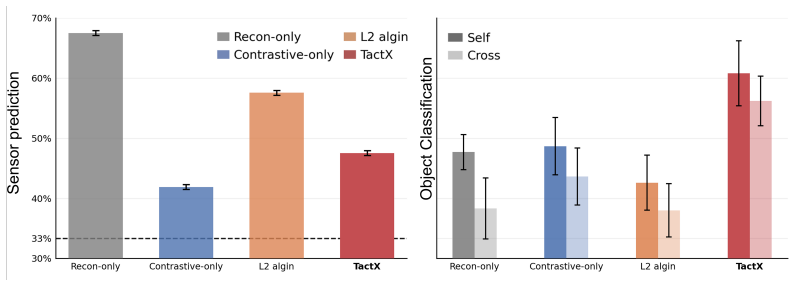
Tactile sensors provide critical information for contact-rich manipulation, yet tactile representations and policies remain tightly coupled to each specific sensor, limiting transferability across robots and hardware platforms. We propose TactX, a framework for learning a transferable tactile representation across sensors spanning three fundamentally different transduction modalities: resistive, magnetic, and vision-based. TactX maps heterogeneous tactile observations into a shared latent space through modality-specific encoders trained on paired contact data. Such paired interactions provide a natural alignment signal across modalities, and the encoders are jointly trained across all sensor pairs, inducing a consistent latent space for all sensor types. Our experiments show that TactX aligns tactile representations across sensors while preserving object-level contact information, as evidenced by sensor-identity prediction and object classification in the learned latent space. We evaluate TactX on four contact-rich manipulation tasks: pick-and-place, plug insertion, board wiping, and object reorientation, and show that policies trained with one sensor transfer zero-shot to physically distinct sensors through the shared latent. This improves the average success rate from 27.5% for vision-only policy to 45.9%, providing a step toward sensor-agnostic tactile manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TactX, a framework that learns a shared latent space for tactile representations across three transduction modalities (resistive, magnetic, vision-based) by training modality-specific encoders jointly on paired contact interactions. It claims this alignment preserves object-level contact information (verified via sensor-identity and object classification) and enables zero-shot policy transfer across sensors on four contact-rich tasks, raising average success from 27.5% (vision-only baseline) to 45.9%.
Significance. If the zero-shot transfer result holds under rigorous controls, the work would address a practical barrier in contact-rich manipulation by decoupling policies from specific sensor hardware, potentially enabling more reusable tactile skills across robot platforms.
major comments (2)
- [Method description (alignment signal)] The central zero-shot transfer claim rests on the assumption that joint training on paired contact tuples alone induces functionally interchangeable latents across modalities with non-overlapping spatial support, noise spectra, and dynamic range. No cycle-consistency, invariance, or distribution-matching term is described that would enforce this equivalence outside the paired set; without such a mechanism the policy (trained only on one sensor's latents) can encounter out-of-distribution inputs from a new sensor.
- [Experiments (success-rate results)] The reported improvement from 27.5% to 45.9% is presented without accompanying details on trial counts, statistical tests, variance across seeds, or ablations that isolate the contribution of the shared latent versus other factors (e.g., sensor-specific fine-tuning or task-specific data). These omissions are load-bearing for the transfer claim.
minor comments (2)
- [Abstract / Method] The abstract and method sections would benefit from an explicit statement of the loss function(s) used for joint encoder training and the precise definition of 'paired contact tuples' (e.g., how temporal and spatial alignment is performed across modalities).
- [Experiments] Figure captions and table headers should clarify whether the reported success rates are means over multiple runs and whether the vision-only baseline uses the same policy architecture as the TactX variants.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Method description (alignment signal)] The central zero-shot transfer claim rests on the assumption that joint training on paired contact tuples alone induces functionally interchangeable latents across modalities with non-overlapping spatial support, noise spectra, and dynamic range. No cycle-consistency, invariance, or distribution-matching term is described that would enforce this equivalence outside the paired set; without such a mechanism the policy (trained only on one sensor's latents) can encounter out-of-distribution inputs from a new sensor.
Authors: Paired contact tuples correspond to identical physical interactions observed by different sensors, supplying direct supervision that maps each modality's reading of the same event into a common latent. Joint optimization of all modality-specific encoders across every sensor pair further constrains the latent space to be consistent, as any deviation would increase the joint loss. The manuscript already demonstrates that this produces latents preserving object-level contact information via the reported sensor-identity and object-classification probes. The zero-shot policy transfer experiments on four tasks provide empirical evidence that the resulting representations are interchangeable in practice; no explicit cycle-consistency term is required because the multi-pair paired supervision itself enforces the necessary alignment. revision: no
-
Referee: [Experiments (success-rate results)] The reported improvement from 27.5% to 45.9% is presented without accompanying details on trial counts, statistical tests, variance across seeds, or ablations that isolate the contribution of the shared latent versus other factors (e.g., sensor-specific fine-tuning or task-specific data). These omissions are load-bearing for the transfer claim.
Authors: We agree that the current manuscript omits these experimental details. In the revision we will report the exact number of trials per task and sensor combination, include standard deviations across random seeds, add appropriate statistical tests, and provide ablations that isolate the contribution of the shared latent from other factors such as task-specific data or sensor-specific fine-tuning. revision: yes
Circularity Check
No circularity: alignment induced by external paired data, not internal definitions
full rationale
The provided abstract and context contain no equations, fitted parameters, or self-citations. The shared latent space is induced by joint training of modality-specific encoders on externally collected paired contact tuples, which constitute an independent alignment signal rather than a quantity defined in terms of the latent itself. No load-bearing step reduces to a self-definition, a renamed prediction, or an imported uniqueness theorem. The zero-shot transfer claim is evaluated against external manipulation benchmarks, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. Calandra, A. Owens, D. Jayaraman, J. Lin, W. Yuan, J. Malik, E. H. Adelson, and S. Levine. More than a feeling: Learning to grasp and regrasp using vision and touch.IEEE Robotics and Automation Letters, 3(4):3300–3307, Oct. 2018. ISSN 2377-3774. doi:10.1109/lra.2018. 2852779. URLhttp://dx.doi.org/10.1109/LRA.2018.2852779
- [2]
-
[3]
Palenicek, T
D. Palenicek, T. Gruner, T. Schneider, A. B¨ohm, J. Lenz, I. Pfenning, E. Kr¨amer, and J. Peters. Learning tactile insertion in the real world, 2024. URLhttps://arxiv.org/abs/2405. 00383
2024
- [4]
- [5]
-
[6]
J. Zhao, Y . Ma, L. Wang, and E. H. Adelson. Transferable tactile transformers for representa- tion learning across diverse sensors and tasks, 2024. URLhttps://arxiv.org/abs/2406. 13640
2024
- [7]
-
[8]
C. Higuera, A. Sharma, C. K. Bodduluri, T. Fan, P. Lancaster, M. Kalakrishnan, M. Kaess, B. Boots, M. Lambeta, T. Wu, and M. Mukadam. Sparsh: Self-supervised touch representa- tions for vision-based tactile sensing, 2024. URLhttps://arxiv.org/abs/2410.24090
-
[9]
Rodriguez, Y
S. Rodriguez, Y . Dou, M. Oller, A. Owens, and N. Fazeli. Cross-sensor touch generation,
- [10]
-
[11]
W. Yuan, S. Dong, and E. H. Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors (Basel, Switzerland), 17, 2017. URLhttps://api. semanticscholar.org/CorpusID:3474913
2017
-
[12]
M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V . R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer, D. Jayaraman, and R. Calandra. Digit: A novel design for a low- cost compact high-resolution tactile sensor with application to in-hand manipulation.IEEE Robotics and Automation Letters, 5(3):3838–3845, 2020. ISSN 2377-3774. doi:10.1109/lra. 20...
work page doi:10.1109/lra 2020
-
[13]
B. Ward-Cherrier, N. Pestell, L. Cramphorn, B. Winstone, M. Giannaccini, J. Rossiter, and N. Lepora. The tactip family: Soft optical tactile sensors with 3d-printed biomimetic mor- phologies.Soft Robotics, 5, 01 2018. doi:10.1089/soro.2017.0052
- [14]
-
[15]
T. Tomo, A. Schmitz, W. Wong, H. Kristanto, S. Somlor, J. Hwang, L. Jamone, and S. Sugano. Covering a robot fingertip with uskin: A soft electronic skin with distributed 3-axis force sensitive elements for robot hands.IEEE Robotics and Automation Letters, PP:1–1, 08 2017. doi:10.1109/LRA.2017.2734965. 9
-
[16]
R. Bhirangi, T. Hellebrekers, C. Majidi, and A. Gupta. Reskin: versatile, replaceable, lasting tactile skins, 2022. URLhttps://arxiv.org/abs/2111.00071
-
[17]
V . Pattabiraman, Z. Huang, D. Panozzo, D. Zorin, L. Pinto, and R. Bhirangi. eflesh: Highly customizable magnetic touch sensing using cut-cell microstructures, 2025. URLhttps:// arxiv.org/abs/2506.09994
-
[18]
FlexiTac: A Low-Cost, Open-Source, Scalable Tactile Sensing Solution for Robotic Systems
B. Huang and Y . Li. Flexitac: A low-cost, open-source, scalable tactile sensing solution for robotic systems, 2026. URLhttps://arxiv.org/abs/2604.28156
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
H. Khamis, R. Albero, M. Salerno, A. Shah Idil, and A. Loizou. Papillarray: An incipient slip sensor for dexterous robotic or prosthetic manipulation – design and prototype validation. Sensors and Actuators A: Physical, 270, 12 2017. doi:10.1016/j.sna.2017.12.058
-
[20]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y . Li, and O. Vinyals. Representation learning with contrastive predictive coding, 2019. URLhttps://arxiv.org/abs/1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[21]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware, 2023. URLhttps://arxiv.org/abs/2304.13705
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [22]
- [23]
- [24]
- [25]
- [26]
- [27]
-
[28]
F. R. Hogan, M. Bauza, O. Canal, E. Donlon, and A. Rodriguez. Tactile regrasp: Grasp adjustments via simulated tactile transformations, 2018. URLhttps://arxiv.org/abs/ 1803.01940
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
GelSlim: A High-Resolution, Compact, Robust, and Calibrated Tactile-sensing Finger
E. Donlon, S. Dong, M. Liu, J. Li, E. Adelson, and A. Rodriguez. Gelslim: A high-resolution, compact, robust, and calibrated tactile-sensing finger, 2018. URLhttps://arxiv.org/abs/ 1803.00628
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
DM-Tac W: High-resolution vision-based tactile sensor.https://www
Daimon Robotics. DM-Tac W: High-resolution vision-based tactile sensor.https://www. dmrobot.com/en/, 2025. Accessed: 2026-05-28
2025
-
[31]
Soft-bubble: A highly compliant dense geometry tactile sensor for robot manipulation
A. Alspach, K. Hashimoto, N. Kuppuswamy, and R. Tedrake. Soft-bubble: A highly compliant dense geometry tactile sensor for robot manipulation, 2019. URLhttps://arxiv.org/abs/ 1904.02252
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [32]
-
[33]
R. Bhirangi, V . Pattabiraman, E. Erciyes, Y . Cao, T. Hellebrekers, and L. Pinto. Anyskin: Plug- and-play skin sensing for robotic touch, 2024. URLhttps://arxiv.org/abs/2409.08276. 10
-
[34]
N. Wettels, V . Santos, R. Johansson, and G. Loeb. Biomimetic tactile sensor array.Advanced Robotics, 22:829–849, 08 2008. doi:10.1163/156855308X314533
- [35]
-
[36]
Zhang, D.-G
K. Zhang, D.-G. Kim, E. T. Chang, H.-H. Liang, Z. He, K. Lampo, P. Wu, I. Kymissis, and M. Ciocarlie. Vibecheck: Using active acoustic tactile sensing for contact-rich manipulation,
-
[37]
URLhttps://arxiv.org/abs/2504.15535
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
M. A. Lee, Y . Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks, 2019. URLhttps://arxiv.org/abs/1810.10191
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [39]
-
[40]
C. Higuera, A. Sharma, T. Fan, C. K. Bodduluri, B. Boots, M. Kaess, M. Lambeta, T. Wu, Z. Liu, F. R. Hogan, and M. Mukadam. Tactile beyond pixels: Multisensory touch representa- tions for robot manipulation, 2025. URLhttps://arxiv.org/abs/2506.14754
- [41]
-
[42]
TacO: Benchmarking Tactile Sensors for Object Manipulation
A. Zorin, Z. Si, M. Park, J. Park, A. Buynitsky, S. Bhadang, T. Park, S. J. Yoon, Y .-L. Park, O. Kroemer, Z. Temel, M. T. Tolley, S. Yi, and X. Wang. Taco: Benchmarking tactile sensors for object manipulation, 2026. URLhttps://arxiv.org/abs/2605.21976
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [43]
- [44]
- [45]
-
[46]
A. Dastider, H. Fang, and M. Lin. Cross-embodiment robotic manipulation synthesis via guided demonstrations through cyclevae and human behavior transformer, 2025. URLhttps: //arxiv.org/abs/2503.08622
-
[47]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions, 2025. URLhttps://arxiv.org/abs/2505. 06111
2025
-
[48]
Sensor-Invariant Tactile Representation
H. Gupta, Y . Mo, S. Jin, and W. Yuan. Sensor-invariant tactile representation, 2025. URL https://arxiv.org/abs/2502.19638
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [49]
-
[50]
S. Rodriguez, Y . Dou, W. van den Bogert, M. Oller, K. So, A. Owens, and N. Fazeli. Con- trastive touch-to-touch pretraining, 2024. URLhttps://arxiv.org/abs/2410.11834. 11
- [51]
- [52]
- [53]
- [54]
- [55]
-
[56]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations, 2020. URLhttps://arxiv.org/abs/2002.05709
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[57]
P. Wu, Y . Shentu, Z. Yi, X. Lin, and P. Abbeel. Gello: A general, low-cost, and intuitive tele- operation framework for robot manipulators, 2024. URLhttps://arxiv.org/abs/2309. 13037. 12 A Data Collection Details Sensors.To prevent too much visual change the eFlesh housing is 3D-printed in black TPU and the FlexiTac surface is covered with black anti-sli...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.