CLIMB: Centroid-Based Hierarchical Memory for Online Continual Self-Supervised Learning
Pith reviewed 2026-07-01 06:11 UTC · model grok-4.3
The pith
CLIMB maintains a bounded hierarchical centroid memory with distillation to learn stable representations from unlabeled data streams without task boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CLIMB achieves superior performance in OCSSL by maintaining a hierarchical centroid-based memory of bounded total images that clusters similar images into centroids. These centroids provide hard-to-discriminate examples for contrastive learning and ensure coverage of the observed data distributions. Knowledge distillation on replayed examples limits representation drift. This combination outperforms existing methods on Split CIFAR-100, Split ImageNet-100, standard benchmarks, and irregular task distributions.
What carries the argument
A hierarchical centroid-based memory that groups similar images into centroids within a fixed total image bound, paired with knowledge distillation on replayed examples to constrain representation drift.
If this is right
- CLIMB outperforms state-of-the-art OCSSL methods on Split CIFAR-100 and Split ImageNet-100 under standard benchmarks.
- The method also outperforms baselines on a new protocol with irregular task distributions.
- The bounded memory still supplies both hard contrastive examples and distribution coverage through centroid grouping.
- Knowledge distillation on replayed examples limits representation drift during online learning.
Where Pith is reading between the lines
- Centroid hierarchies may reduce memory requirements in other self-supervised continual learning settings beyond the tested image benchmarks.
- The dual use of structure exploitation and regularization could apply to supervised continual learning or other contrastive variants.
- Testing the approach on larger-scale or real-world streaming data would reveal whether the memory bound scales without losing coverage.
- The irregular task protocol suggests that robustness to uneven arrivals is a key property worth measuring in future continual learning work.
Load-bearing premise
Grouping images into centroids will simultaneously supply hard-to-discriminate examples for contrastive learning and cover the diversity of observed distributions while knowledge distillation on replayed examples sufficiently limits representation drift under the stated memory bound.
What would settle it
On the irregular task distribution protocol, if CLIMB shows no performance gain over baselines or exhibits higher representation drift despite the memory bound, the central claim would be falsified.
Figures



read the original abstract
Online Continual Self-Supervised Learning (OCSSL) aims to learn representations from a continuous stream of unlabeled data, without knowledge of task boundaries and under memory constraints. Existing methods rely either on replay buffers that exploit latent space structure, or on regularization alone. We present CLIMB (Continual Learning with Intelligent Memory Bank), which combines both simultaneously. Our method introduces a hierarchical centroid-based memory, bounded in total number of stored images, combined with knowledge distillation on replayed examples to limit representation drift. The memory groups similar images into centroids, providing hard-to-discriminate examples for contrastive learning while covering the diversity of observed distributions. Experiments on Split CIFAR-100 and Split ImageNet-100, on standard benchmarks from the state-of-the-art as well as a new protocol with irregular task distributions show that CLIMB outperforms state-of-the-art OCSSL methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLIMB for online continual self-supervised learning (OCSSL). It proposes a hierarchical centroid-based memory bank (bounded in total stored images) that groups similar images into centroids to supply hard negatives for contrastive learning while covering distribution diversity, combined with knowledge distillation on replayed examples to limit representation drift. The central claim is that this outperforms state-of-the-art OCSSL methods on Split CIFAR-100 and Split ImageNet-100 under both standard benchmarks and a new protocol with irregular task distributions.
Significance. If the empirical claims hold with supporting quantitative evidence, the work would advance OCSSL by demonstrating a practical integration of replay-based and regularization-based strategies under strict memory constraints. The introduction of an irregular task distribution protocol is a constructive addition for evaluating robustness beyond standard sequential setups. The design directly targets the tension between hard-negative mining and distribution coverage, which is a recurring challenge in memory-bounded continual contrastive learning.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments: The manuscript asserts outperformance on multiple benchmarks (Split CIFAR-100, Split ImageNet-100, standard and irregular protocols) but supplies no quantitative results, error bars, ablation details, or description of baseline implementations. This is load-bearing for the central claim, as the paper's contribution rests entirely on these empirical comparisons; without them the data cannot be verified to support the stated superiority.
- [Method] Method (hierarchical centroid memory): The design assumes that grouping into centroids simultaneously (a) yields hard-to-discriminate examples for contrastive learning, (b) covers the diversity of observed distributions, and (c) allows KD on replay to bound drift, all under a fixed memory-size bound. No quantitative analysis, ablation on centroid count vs. memory allocation, or verification that these three requirements are jointly satisfied (rather than traded off) is provided, leaving the least-secured link of the headline claim untested.
minor comments (2)
- Clarify the exact memory budget (total images) and how the hierarchy is constructed and updated in the online stream; notation for centroids and levels should be defined before first use.
- Add a table or figure summarizing the new irregular-task protocol (task lengths, arrival order statistics) so readers can reproduce the evaluation setting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical presentation and analysis. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments: The manuscript asserts outperformance on multiple benchmarks (Split CIFAR-100, Split ImageNet-100, standard and irregular protocols) but supplies no quantitative results, error bars, ablation details, or description of baseline implementations. This is load-bearing for the central claim, as the paper's contribution rests entirely on these empirical comparisons; without them the data cannot be verified to support the stated superiority.
Authors: We agree that the abstract as written does not include quantitative results or error bars, and that the provided manuscript text lacks explicit ablation details and baseline implementation descriptions. The full paper contains experimental tables in Section 4, but to directly address this concern we will revise the abstract to report key metrics with standard deviations and expand the experiments section with additional ablation tables and baseline details. revision: yes
-
Referee: [Method] Method (hierarchical centroid memory): The design assumes that grouping into centroids simultaneously (a) yields hard-to-discriminate examples for contrastive learning, (b) covers the diversity of observed distributions, and (c) allows KD on replay to bound drift, all under a fixed memory-size bound. No quantitative analysis, ablation on centroid count vs. memory allocation, or verification that these three requirements are jointly satisfied (rather than traded off) is provided, leaving the least-secured link of the headline claim untested.
Authors: We acknowledge that the current manuscript does not provide quantitative ablations on centroid count versus memory allocation or explicit verification that the three design goals are jointly satisfied rather than traded off. In the revision we will add these analyses, including targeted experiments that measure hard-negative quality, distribution coverage, and drift reduction as functions of centroid granularity under the fixed memory bound. revision: yes
Circularity Check
No circularity detected; method design and empirical claims are self-contained without reduction to inputs
full rationale
The paper presents CLIMB as a novel combination of hierarchical centroid-based memory and knowledge distillation for OCSSL, with claims of outperformance on Split CIFAR-100 and Split ImageNet-100 under standard and irregular protocols. No equations, fitted parameters, or derivation steps are visible that reduce a prediction to a self-defined quantity or rely on load-bearing self-citations. The centroid grouping is introduced as a design choice to address hard negatives and diversity simultaneously, not derived from prior results by the same authors. The memory bound and distillation are stated constraints and techniques, not circularly justified. This is a standard empirical methods paper with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A memory bank bounded in total number of stored images is a hard constraint that must be respected while still covering observed data diversity.
invented entities (1)
-
hierarchical centroid-based memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Guide: Guidance- based incremental learning with diffusion models
Bartosz Cywi´nski, Kamil Deja, Tomasz Trzci´nski, Bartłomiej Twardowski, and Łukasz Kuci´nski. Guide: Guidance- based incremental learning with diffusion models. InECAI 2025, pp. 3614–3621. IOS Press,
2025
-
[2]
IEEE. doi: 10.1109/CVPR52688.2022. 00940. 10 Published at 5th Conference on Lifelong Learning Agents (CoLLAs), 2026 Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning.Trans- actions on Machine Learning Research,
-
[3]
ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas.1611835114. Hyunseo Koh, Dahyun Kim, Jung-Woo Ha, and Jonghyun Choi. Online continual learning on class incremental blurry task configuration with anytime inference. InICLR,
-
[4]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 2001–2010,
2001
-
[5]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Unsupervised progressive learning and the STAM architecture.arXiv preprint arXiv:1904.02021,
James Smith, Cameron Taylor, Seth Baer, and Constantine Dovrolis. Unsupervised progressive learning and the STAM architecture.arXiv preprint arXiv:1904.02021,
-
[7]
SCALE: Online Self-Supervised Lifelong Learning without Prior Knowledge
11 Published at 5th Conference on Lifelong Learning Agents (CoLLAs), 2026 Xiaofan Yu, Yunhui Guo, Sicun Gao, and Tajana Rosing. SCALE: Online Self-Supervised Lifelong Learning without Prior Knowledge. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Work- shops (CVPRW), pp. 2484–2495, Vancouver, BC, Canada, June
2026
-
[8]
IEEE. ISBN 979-8-3503-0249-3. doi: 10.1109/CVPRW59228.2023.00247. Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. InInternational conference on machine learning, pp. 3987–3995. Pmlr,
-
[9]
TheLandKexperiments do not require coupling adjustments. Memory architecture parameters (Table 4).Performance increases monotonically withNup to the reference value of 2500, beyond which it levels off, suggesting thatN= 2500is sufficient for the memory to maintain adequate stream coverage, noting that the remaining hyperparameters were also tuned at this ...
2026
-
[10]
D GLOBALPRUNINGSTRATEGYABLATION Table 6 compares two strategies for the global pruning step triggered when the total number of stored images exceeds N
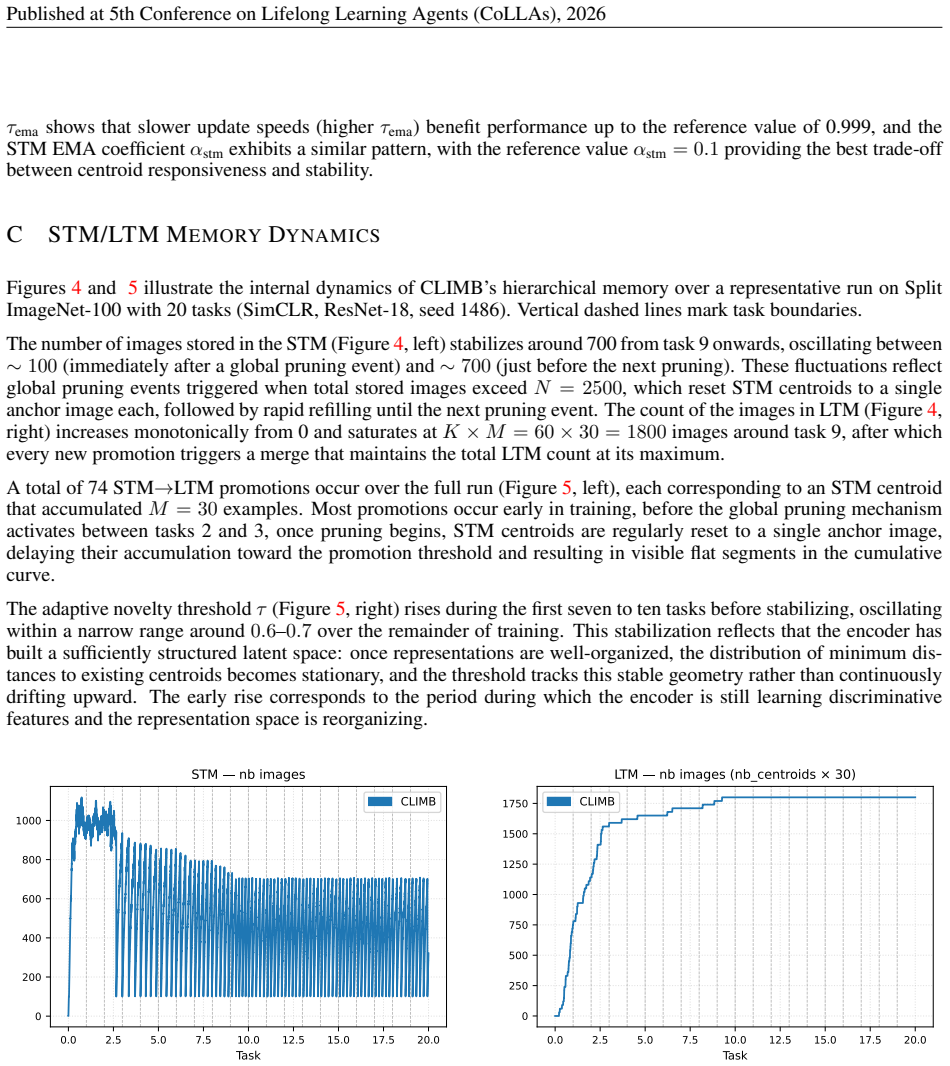
CLIMB Figure 4: Number of images stored in the STM (left) and LTM (right) as a function of task. D GLOBALPRUNINGSTRATEGYABLATION Table 6 compares two strategies for the global pruning step triggered when the total number of stored images exceeds N. TheAnchorstrategy, used by default in CLIMB, deletes all STM examples except one anchor image per centroid, ...
2026
-
[11]
Table 7: Memory diversity metrics at end of training on Split ImageNet-100 (20 tasks)
as a measure of global memory diversity, the uniformity metric of Wang & Isola (2020) as a measure of coverage of the unit hypersphere, and an Inter/Intra ratio measuring the semantic separability of stored examples. Table 7: Memory diversity metrics at end of training on Split ImageNet-100 (20 tasks). All buffers operate under capacityN=
2020
-
[12]
Intuitively, VS can be read as the effective number of distinct elements in the buffer, ranging from1when all embeddings are identical tonwhen all are mutually orthogonal
Metric CLIMB MinRed Reservoir FIFO Stored images (end of training) 2121 2500 2500 2500 Vendi score (Friedman & Dieng, 2023)(↑)43.1 35.353.329.2 Uniformity (Wang & Isola, 2020)(↓)-3.550 -3.582-3.624-3.419 Intra-cluster dist(↓)0.2640.453±0.003 0.324±0.002 0.288±0.002 Inter/Intra ratio(↑)3.7962.212±0.017 3.101±0.020 3.485±0.036 Linear probe accuracy(↑)0.5100...
2023
-
[13]
Hyperparameters for CLIMB were selected via grid search on each dataset independently, yielding lr= 0.2andλ= 0.1in both cases
as the base SSL method on Split CIFAR-100 and Split ImageNet-100 respectively. Hyperparameters for CLIMB were selected via grid search on each dataset independently, yielding lr= 0.2andλ= 0.1in both cases. Hyperparameters for all baselines correspond to their best-performing configurations. On Split CIFAR-100, all methods remain far below the i.i.d. upper...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.