CDR-Bench: Evaluating Faithful Execution of Compositional, Order-Sensitive Data Refinement Recipes
Pith reviewed 2026-07-01 05:53 UTC · model grok-4.3
The pith
Current LLMs cannot faithfully execute compositional order-sensitive data refinement recipes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
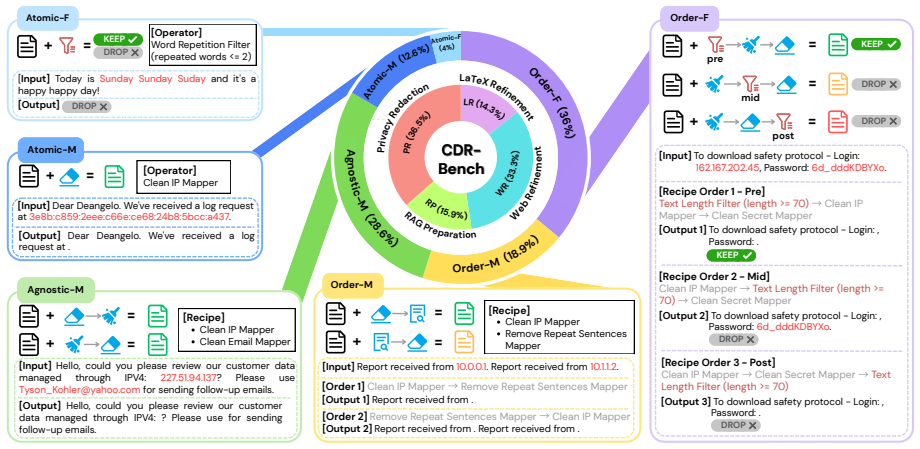
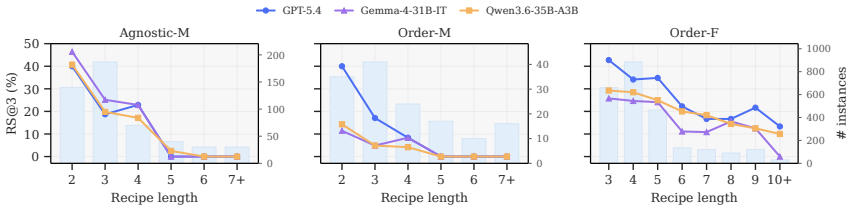
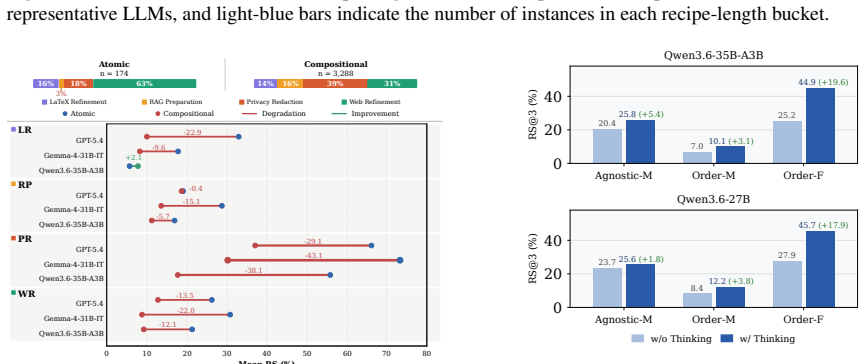
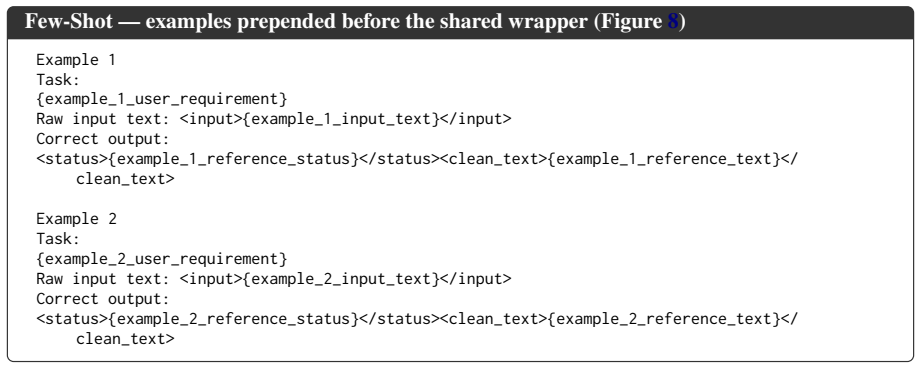
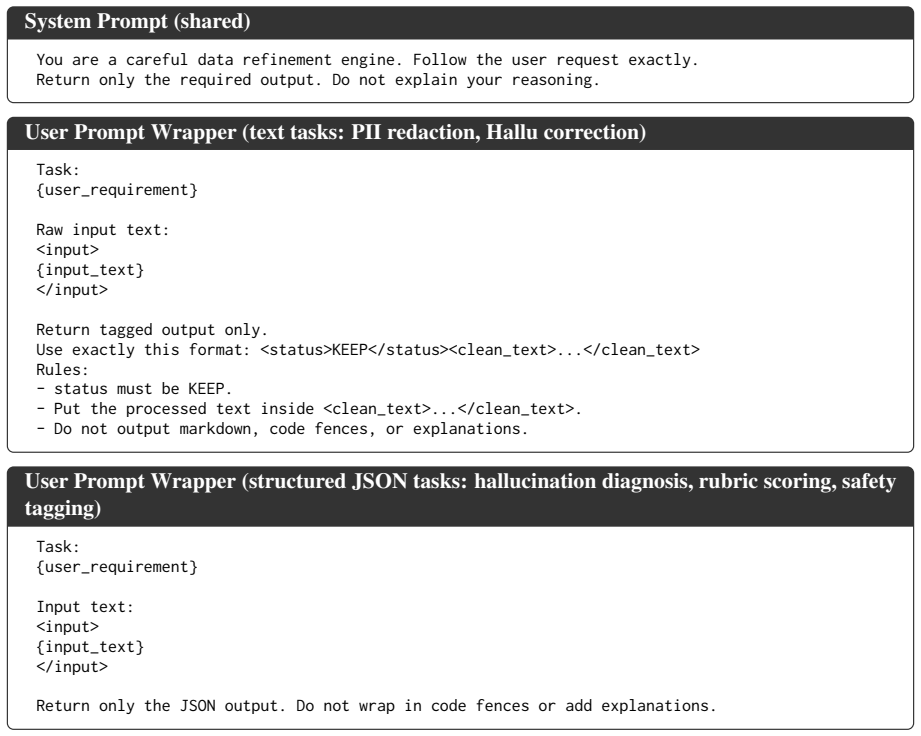
CDR-Bench measures whether LLMs can execute compositional, order-sensitive data refinement recipes over evolving text states. The benchmark contains 3,462 tasks spanning four domains and 29 operators, scored exactly against deterministic references in atomic, order-agnostic, and order-sensitive conditions. Experiments reveal that performance degrades sharply once tasks become compositional and collapses further when operator order is consequential, demonstrating that current models lack the procedural faithfulness required for reliable data refinement.
What carries the argument
CDR-Bench, a benchmark of 3,462 tasks and 29 operators that evaluates models in atomic, order-agnostic, and order-sensitive settings using deterministic reference outputs for exact scoring.
If this is right
- LLMs cannot be trusted to run data-refinement pipelines when the sequence of operators affects the outcome.
- Any application that depends on faithful execution of ordered text transformations will encounter systematic failures with present models.
- Evaluation protocols for LLMs must include explicit order-sensitive compositional tests to surface these limitations.
- Progress on procedural faithfulness will require new training signals or architectures that track state evolution across ordered steps.
Where Pith is reading between the lines
- The observed failures may stem from an inability to maintain an internal model of how each operator changes the current text state.
- Hybrid systems that pair LLMs with symbolic state trackers could mitigate the order-sensitivity problem without retraining the entire model.
- Similar order-sensitivity gaps are likely to appear in other procedural domains such as workflow automation or iterative data cleaning.
Load-bearing premise
The 3,462 tasks and 29 operators, together with their deterministic reference outputs, represent the compositional and order-sensitive data refinement problems that arise in real applications.
What would settle it
An LLM that scores near ceiling on the order-sensitive subset of CDR-Bench while also succeeding on held-out real-world multi-step refinement workflows would falsify the reported pattern of collapse.
Figures













read the original abstract
Data refinement involves executing multi-step recipes over evolving text states, where both composition and execution order of processing operators determine the outcome. While existing benchmarks either isolate text editing or entangle it with code and tool execution, it remains unclear whether LLMs can directly and faithfully execute these compositional, order-sensitive data refinement recipes. To fill this gap, we introduce CDR-Bench, a comprehensive benchmark featuring 3,462 high-quality tasks spanning four real-world data refinement domains and 29 distinct operators. Our benchmark evaluates models across atomic, order-agnostic, and order-sensitive settings, leveraging deterministic reference outputs to enable exact evaluation. Experiments on 10+ state-of-the-art LLMs reveal consistent failure patterns: performance degrades sharply in compositional settings, and order-sensitive recipe success collapses. These findings underline that current LLMs lack the procedural faithfulness required for reliable compositional data refinement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CDR-Bench, a benchmark of 3,462 tasks spanning four real-world data refinement domains and 29 operators. It evaluates LLMs across atomic, order-agnostic, and order-sensitive regimes using deterministic reference outputs for exact-match evaluation. Experiments on 10+ state-of-the-art LLMs show sharp performance degradation in compositional settings and collapse in order-sensitive recipes, supporting the claim that current LLMs lack procedural faithfulness for reliable compositional data refinement.
Significance. If the task construction and deterministic references hold, this benchmark provides a clear, reproducible way to isolate the effects of composition and execution order on LLM procedural execution. The explicit separation of order-agnostic vs. order-sensitive regimes and the scale (3,462 tasks, 29 operators) are strengths that enable falsifiable measurements of faithfulness; the work directly supports targeted improvements in handling multi-step text-state transformations.
minor comments (3)
- [§3.1] §3.1: The construction of the 29 operators is described in prose; a compact table enumerating each operator, its domain, arity, and whether it is order-sensitive would improve readability and allow direct cross-reference with the experimental results.
- [Table 4] Table 4 (results by domain): The exact-match metric is used throughout, but the caption does not state whether partial credit or token-level overlap was considered as a secondary metric; adding this clarification would strengthen the presentation of the collapse in order-sensitive settings.
- [§5] §5: The discussion of failure patterns references 'consistent' degradation but does not include per-model variance or statistical significance tests on the reported drops; a brief note on whether differences exceed run-to-run variation would be helpful.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of CDR-Bench and the recommendation for minor revision. We appreciate the acknowledgment that the benchmark's separation of atomic, order-agnostic, and order-sensitive regimes, along with its scale and deterministic references, enables clear measurements of procedural faithfulness in LLMs.
Circularity Check
No significant circularity: empirical benchmark evaluation
full rationale
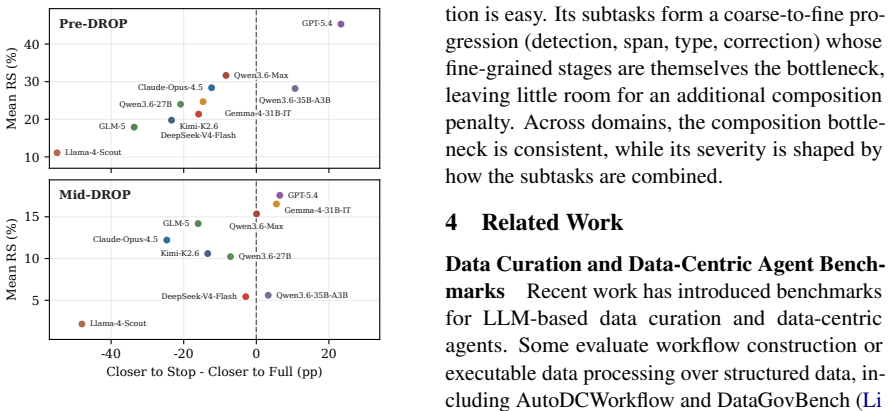
The paper introduces CDR-Bench as a new dataset of 3462 tasks across 29 operators and reports experimental results on LLMs in atomic, order-agnostic, and order-sensitive regimes. All central claims are direct empirical observations (performance degradation patterns) obtained by running existing models against deterministic reference outputs. No equations, fitted parameters, uniqueness theorems, or ansatzes are present; the benchmark construction and evaluation protocol are described explicitly without reducing any reported result to a self-referential definition or prior self-citation. The derivation chain is therefore self-contained as standard benchmark construction plus measurement.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Deterministic reference outputs enable exact evaluation of LLM execution faithfulness
- domain assumption The selected 29 operators and four domains are representative of real-world compositional data refinement
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Scaling Laws of Synthetic Data for Language Models , author=. 2025 , eprint=
2025
-
[2]
2026 , eprint=
Tackling the Inherent Difficulty of Noise Filtering in RAG , author=. 2026 , eprint=
2026
-
[3]
2024 , eprint=
Developing Retrieval Augmented Generation (RAG) based LLM Systems from PDFs: An Experience Report , author=. 2024 , eprint=
2024
-
[4]
2025 , eprint=
PRvL: Quantifying the Capabilities and Risks of Large Language Models for PII Redaction , author=. 2025 , eprint=
2025
-
[5]
2024 , eprint=
The Empirical Impact of Data Sanitization on Language Models , author=. 2024 , eprint=
2024
-
[6]
2021 , eprint=
A Survey on Data Cleaning Methods for Improved Machine Learning Model Performance , author=. 2021 , eprint=
2021
-
[7]
2019 , eprint=
Preprocessing Methods and Pipelines of Data Mining: An Overview , author=. 2019 , eprint=
2019
-
[8]
SIGMOD , year=
Data-Juicer: A One-Stop Data Processing System for Large Language Models , author=. SIGMOD , year=
-
[9]
NeurIPS , year=
Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for and with Foundation Models , author=. NeurIPS , year=
-
[10]
2025 , eprint=
AutoDCWorkflow: LLM-based Data Cleaning Workflow Auto-Generation and Benchmark , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
DCA-Bench: A Benchmark for Dataset Curation Agents , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
DataGovBench: Benchmarking LLM Agents for Real-World Data Governance Workflows , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
DAComp: Benchmarking Data Agents across the Full Data Intelligence Lifecycle , author=. 2025 , eprint=
2025
-
[14]
2026 , eprint=
KramaBench: A Benchmark for AI Systems on Data-to-Insight Pipelines over Data Lakes , author=. 2026 , eprint=
2026
-
[15]
OpenPII 1M: Multilingual PII Masking Dataset (19 Labels, 23 Languages) , year =
-
[16]
Pil \'a n, Ildik \'o and Lison, Pierre and vrelid, Lilja and Papadopoulou, Anthi and S \'a nchez, David and Batet, Montserrat. The Text Anonymization Benchmark ( TAB ): A Dedicated Corpus and Evaluation Framework for Text Anonymization. Computational Linguistics. 2022. doi:10.1162/coli_a_00458
-
[17]
RAGT ruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models
Niu, Cheng and Wu, Yuanhao and Zhu, Juno and Xu, Siliang and Shum, KaShun and Zhong, Randy and Song, Juntong and Zhang, Tong. RAGT ruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v...
-
[18]
2024 , eprint=
Fine-grained Hallucination Detection and Editing for Language Models , author=. 2024 , eprint=
2024
-
[19]
Dziri, Nouha and Kamalloo, Ehsan and Milton, Sivan and Zaiane, Osmar and Yu, Mo and Ponti, Edoardo M. and Reddy, Siva. F aith D ial: A Faithful Benchmark for Information-Seeking Dialogue. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00529
-
[20]
2022 , eprint=
MAVEN-ERE: A Unified Large-scale Dataset for Event Coreference, Temporal, Causal, and Subevent Relation Extraction , author=. 2022 , eprint=
2022
-
[21]
2023 , eprint=
CoEdIT: Text Editing by Task-Specific Instruction Tuning , author=. 2023 , eprint=
2023
-
[22]
2026 , eprint=
Bridging the Editing Gap in LLMs: FineEdit for Precise and Targeted Text Modifications , author=. 2026 , eprint=
2026
-
[23]
2025 , eprint=
HyperEdit: Unlocking Instruction-based Text Editing in LLMs via Hypernetworks , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
EdiText: Controllable Coarse-to-Fine Text Editing with Diffusion Language Models , author=. 2025 , eprint=
2025
-
[25]
2022 , eprint=
EditEval: An Instruction-Based Benchmark for Text Improvements , author=. 2022 , eprint=
2022
-
[26]
2024 , eprint=
Large Language Models as Data Preprocessors , author=. 2024 , eprint=
2024
-
[27]
Jellyfish: Instruction-Tuning Local Large Language Models for Data Preprocessing
Zhang, Haochen and Dong, Yuyang and Xiao, Chuan and Oyamada, Masafumi. Jellyfish: Instruction-Tuning Local Large Language Models for Data Preprocessing. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.497
-
[28]
2024 , eprint=
RetClean: Retrieval-Based Data Cleaning Using Foundation Models and Data Lakes , author=. 2024 , eprint=
2024
-
[29]
2024 , eprint=
LLMClean: Context-Aware Tabular Data Cleaning via LLM-Generated OFDs , author=. 2024 , eprint=
2024
-
[30]
2024 , eprint=
SketchFill: Sketch-Guided Code Generation for Imputing Derived Missing Values , author=. 2024 , eprint=
2024
-
[31]
2023 , eprint=
ChatPipe: Orchestrating Data Preparation Program by Optimizing Human-ChatGPT Interactions , author=. 2023 , eprint=
2023
-
[32]
2024 , eprint=
SEED: Domain-Specific Data Curation With Large Language Models , author=. 2024 , eprint=
2024
-
[33]
2025 , eprint=
AutoPrep: Natural Language Question-Aware Data Preparation with a Multi-Agent Framework , author=. 2025 , eprint=
2025
-
[34]
arxiv-latex-5T , year =
-
[35]
Efficient Attentions for Long Document Summarization
Huang, Luyang and Cao, Shuyang and Parulian, Nikolaus and Ji, Heng and Wang, Lu. Efficient Attentions for Long Document Summarization. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.112
-
[36]
DocPII: Contextual Redaction Benchmark Dataset , year =
-
[37]
ai4privacy/pii-masking-200k dataset , year =
-
[38]
ai4privacy/pii-masking-400k dataset , year =
-
[39]
2025 , publisher =
Amy Steier and Andre Manoel and Alexa Haushalter and Maarten Van Segbroeck , title =. 2025 , publisher =
2025
-
[40]
2024 , eprint=
XATU: A Fine-grained Instruction-based Benchmark for Explainable Text Updates , author=. 2024 , eprint=
2024
-
[41]
2016 , eprint=
SQuAD: 100,000+ Questions for Machine Comprehension of Text , author=. 2016 , eprint=
2016
-
[42]
Soviet Physics Doklady , volume =
Binary codes capable of correcting deletions, insertions, and reversals , author =. Soviet Physics Doklady , volume =
-
[43]
Optimizing Statistical Machine Translation for Text Simplification
Xu, Wei and Napoles, Courtney and Pavlick, Ellie and Chen, Quanze and Callison-Burch, Chris. Optimizing Statistical Machine Translation for Text Simplification. Transactions of the Association for Computational Linguistics. 2016. doi:10.1162/tacl_a_00107
-
[44]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[45]
2026 , howpublished =
GPT-5.4 Model Documentation , author =. 2026 , howpublished =
2026
-
[46]
2026 , howpublished =
GPT-5.5 Model Documentation , author =. 2026 , howpublished =
2026
-
[47]
2026 , howpublished =
Our most intelligent open models, built from Gemini 3 research and technology to maximize intelligence-per-parameter , author =. 2026 , howpublished =
2026
-
[48]
2026 , howpublished =
Gemini 3.1 Pro Preview Model Documentation , author =. 2026 , howpublished =
2026
-
[49]
2026 , eprint=
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
2026
-
[50]
2025 , howpublished =
Introducing Claude Opus 4.5 , author =. 2025 , howpublished =
2025
-
[51]
2025 , howpublished =
Introducing Claude Opus 4.6 , author =. 2025 , howpublished =
2025
-
[52]
2026 , howpublished =
Introducing Claude Opus 4.7 , author =. 2026 , howpublished =
2026
-
[53]
2026 , howpublished =
Introducing Claude Sonnet 4.6 , author =. 2026 , howpublished =
2026
-
[54]
2026 , howpublished =
Kimi K2.6 Tech Blog: Advancing Open-Source Coding , author =. 2026 , howpublished =
2026
-
[55]
2025 , howpublished =
The Llama 4 herd: The beginning of a new era of natively multimodal intelligence , author =. 2025 , howpublished =
2025
-
[56]
AEGIS 2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails
Ghosh, Shaona and Varshney, Prasoon and Sreedhar, Makesh Narsimhan and Padmakumar, Aishwarya and Rebedea, Traian and Varghese, Jibin Rajan and Parisien, Christopher. AEGIS 2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com...
-
[57]
2024 , eprint=
HelpSteer2: Open-source dataset for training top-performing reward models , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.