Which Tokens Matter? Adaptive Token Selection for RLVR with the Relative Surprisal Index
Pith reviewed 2026-07-01 05:24 UTC · model grok-4.3
The pith
Relative Surprisal Index couples token entropy and probability to filter useful positions during RLVR, raising accuracy 2-3 points over GRPO.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
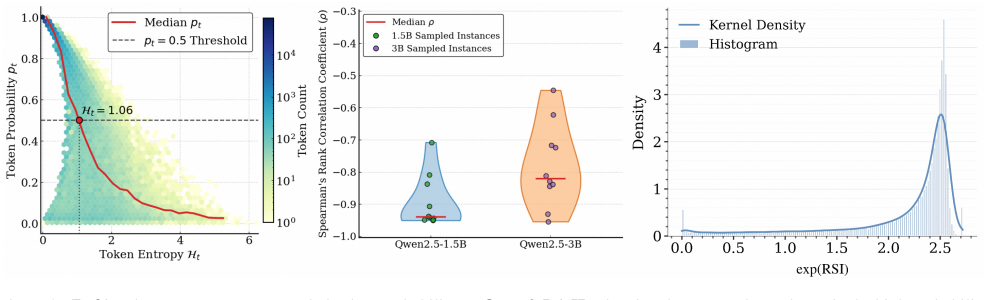
The Relative Surprisal Index is an information-theoretic quantity that naturally couples a token's entropy with the probability of the actually selected token. Under mild conditions RSI equals the local ratio between the first-order variation of the logit-gradient norm and the variation of predictive entropy produced by a perturbation at the selected logit. RSI Selection retains only those tokens whose RSI lies inside a stable interval, simultaneously removing redundant low-surprisal tokens and unstable high-surprisal tokens; this rule produces the reported accuracy gains on AIME and AMC.
What carries the argument
The Relative Surprisal Index (RSI), an information-theoretic metric that couples token entropy with the probability of the selected token and tracks the ratio of first-order changes in logit-gradient norm to predictive entropy.
If this is right
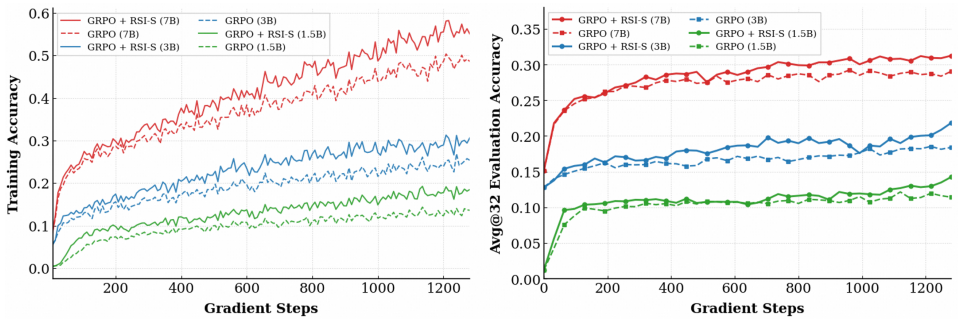
- RSI-S improves avg@32 accuracy by 2-3 percentage points over GRPO on AIME and AMC for Qwen2.5 models of 1.5 B, 3 B and 7 B parameters.
- RSI-S simultaneously discards redundant low-surprisal tokens and unstable high-surprisal tail tokens.
- The single RSI rule reconciles the earlier high-entropy prioritization view with the low-probability avoidance view.
- Gradient updates become more stable because extreme-RSI tokens are excluded from the loss.
Where Pith is reading between the lines
- If the stable RSI interval proves insensitive to model size, the same filter could be applied unchanged to much larger models without retuning.
- The metric may be useful in other RL settings that lack verifiable rewards, such as preference optimization, provided an analogous notion of surprisal can be defined.
- Dynamic per-layer or per-step RSI thresholds could further reduce the number of tokens that must be evaluated during each update.
Load-bearing premise
A single fixed RSI interval can reliably separate useful tokens from both redundant low-surprisal and unstable high-surprisal tokens across model scales and tasks without task-specific tuning.
What would settle it
Applying the same RSI interval to a new model family or a different verifiable-reward benchmark and finding zero or negative accuracy change relative to GRPO.
Figures


read the original abstract
Reinforcement learning (RL) has become a powerful tool for propelling Large Language Models (LLMs) beyond imitation-based training towards more robust reasoning capabilities. Among existing approaches, RL with Verifiable Rewards (RLVR) has emerged as a pivotal paradigm for advancing LLM reasoning. Despite its empirical success, recent studies have offered different insights. One line of inquiry advocates prioritizing high-entropy token positions during training, while another perspective cautions against allowing low-probability tokens to dominate gradient updates. Notably, although high-entropy tokens are usually correlated with low probability, both paradigms empirically yield substantial performance gains. In this work, we argue that evaluating sampled-token probability or entropy in isolation is insufficient to capture the policy optimization dynamics. To resolve this tension, we introduce the Relative Surprisal Index (RSI), a principled, information-theoretic metric that naturally couples the token's entropy with the probability of the selected token. We show that, under mild conditions, RSI is related to the local ratio between the first-order variations of the logit-gradient norm and predictive entropy under a selected-logit perturbation. Building on RSI, we propose RSI Selection (RSI-S), an entropy-adaptive token filtering method that retains tokens within a stable RSI interval. RSI-S successfully reconciles previous contradictory paradigms and filters out both redundant low-surprisal tokens and unstable high-surprisal tail tokens. Empirical evaluations show that RSI-S achieves higher avg@32 accuracy across different model scales (Qwen2.5-1.5B, 3B, and 7B) on AIME and AMC benchmarks: RSI-S improves avg@32 accuracy by 2--3 percentage points over GRPO. Overall, RSI offers a promising perspective for RLVR improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Relative Surprisal Index (RSI), an information-theoretic metric coupling token entropy with the probability of the sampled token, to resolve tensions between high-entropy prioritization and avoidance of low-probability tokens in RLVR for LLMs. It shows that under mild conditions RSI equals the local ratio of first-order variations in logit-gradient norm to predictive entropy under selected-logit perturbation. RSI-S applies this by retaining tokens inside one fixed stable RSI interval, filtering both low-surprisal redundancy and high-surprisal instability. Experiments report that RSI-S yields 2–3 percentage point gains in avg@32 accuracy over GRPO on AIME and AMC for Qwen2.5-1.5B/3B/7B models.
Significance. If the claimed relation holds without circularity and the fixed-interval gains prove robust, the work supplies a principled reconciliation of two prior RLVR paradigms and a practical token filter that improves reasoning performance across scales. The cross-model evaluation on standard math benchmarks is a positive feature; reproducible code or machine-checked derivations would further strengthen it.
major comments (3)
- [§3] §3 (theoretical development): the statement that RSI is 'related to the local ratio between the first-order variations of the logit-gradient norm and predictive entropy' under mild conditions is load-bearing for the claim of a non-circular, principled metric, yet the manuscript provides neither the explicit mild conditions nor the derivation steps that would allow verification that RSI does not reduce to a fitted threshold.
- [§4.3] §4.3 and experimental tables: the central empirical claim that one fixed RSI interval succeeds for all three model scales (1.5B–7B) and both AIME/AMC without per-scale retuning rests on the assumption that entropy distributions (hence RSI ranges) remain stable; no ablation varying the interval bounds or reporting entropy statistics per model is shown, so the reported 2–3 pp avg@32 gains cannot be assessed for generality.
- [Experimental results] Experimental results section: the 2–3 pp improvement over GRPO is presented without error bars, standard deviations across seeds, or statistical significance tests; because the gains are the primary evidence for RSI-S superiority, this omission directly affects confidence in the cross-scale claim.
minor comments (2)
- [Abstract] Abstract and §2: the phrase 'mild conditions' is used without a forward reference to the precise assumptions listed later; adding the reference would improve readability.
- [Notation] Notation: ensure the RSI formula is defined with all symbols (including any normalization constants) at first use rather than relying on later equations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. Below we provide point-by-point responses to the major comments, indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§3] §3 (theoretical development): the statement that RSI is 'related to the local ratio between the first-order variations of the logit-gradient norm and predictive entropy' under mild conditions is load-bearing for the claim of a non-circular, principled metric, yet the manuscript provides neither the explicit mild conditions nor the derivation steps that would allow verification that RSI does not reduce to a fitted threshold.
Authors: We agree that the explicit mild conditions and derivation steps must be provided to substantiate the non-circular, principled nature of RSI. In the revised manuscript we will expand §3 with the complete derivation, stating the mild conditions (small logit perturbations, local smoothness of the entropy function, and first-order Taylor expansion validity) and showing step-by-step that RSI equals the indicated local ratio of gradient-norm variation to entropy variation. This addition will allow direct verification and remove any ambiguity about circularity or ad-hoc fitting. revision: yes
-
Referee: [§4.3] §4.3 and experimental tables: the central empirical claim that one fixed RSI interval succeeds for all three model scales (1.5B–7B) and both AIME/AMC without per-scale retuning rests on the assumption that entropy distributions (hence RSI ranges) remain stable; no ablation varying the interval bounds or reporting entropy statistics per model is shown, so the reported 2–3 pp avg@32 gains cannot be assessed for generality.
Authors: We acknowledge that additional evidence on cross-scale stability is required. In the revision we will report per-model entropy statistics (mean, variance, and RSI distribution histograms) and include an ablation table that varies the RSI interval bounds while measuring performance on AIME/AMC for each scale. These additions will directly test and support the claim that a single fixed interval generalizes without per-scale retuning. revision: yes
-
Referee: Experimental results section: the 2–3 pp improvement over GRPO is presented without error bars, standard deviations across seeds, or statistical significance tests; because the gains are the primary evidence for RSI-S superiority, this omission directly affects confidence in the cross-scale claim.
Authors: We agree that the lack of variability measures and significance testing weakens confidence in the reported gains. We will rerun the key experiments with at least three independent seeds, add standard deviations and error bars to all tables, and include paired statistical significance tests (e.g., t-tests) comparing RSI-S against GRPO. These changes will be incorporated into the revised experimental results section. revision: yes
Circularity Check
No circularity: RSI introduced as independent information-theoretic metric
full rationale
The abstract presents RSI as a new principled metric that couples token entropy with selected-token probability, derives its relation to logit-gradient-norm and entropy variations under mild conditions, and then builds RSI-S as a filtering method retaining tokens in a stable RSI interval. No equations, self-citations, or fitted parameters are shown that would make the metric or the interval selection reduce to the inputs by construction. The claimed reconciliation of prior paradigms and the 2-3pp empirical gains are presented as consequences of the new metric rather than tautological renamings or self-referential fits. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
-
[3]
arXiv preprint arXiv:2505.12346 , year =
Minghan Chen, Guikun Chen, Wenguan Wang, and Yi Yang. Seed-grpo: Semantic entropy enhanced grpo for uncertainty-aware policy optimization.arXiv preprint arXiv:2505.12346, 2025
-
[4]
Xingwu Chen, Tianle Li, and Difan Zou. Reshaping reason- ing in llms: A theoretical analysis of rl training dynamics through pattern selection.arXiv preprint arXiv:2506.04695, 2025
-
[5]
Does reinforcement learn- ing really incentivize reasoning capacity in llms beyond the base model?Advances in Neural Information Processing Systems, 38:57654–57689, 2026
Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learn- ing really incentivize reasoning capacity in llms beyond the base model?Advances in Neural Information Processing Systems, 38:57654–57689, 2026
2026
-
[6]
Sft memorizes, rl generalizes: A comparative study of foundation model post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training. InForty-second In- ternational Conference on Machine Learning, 2025
2025
-
[7]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforce- ment learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Zhezheng Hao, Hong Wang, Haoyang Liu, Jian Luo, Jiarui Yu, Hande Dong, Qiang Lin, Can Wang, and Jiawei Chen. Rethinking entropy interventions in rlvr: An entropy change perspective.arXiv preprint arXiv:2510.10150, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning
Maggie Huan, Yuetai Li, Tuney Zheng, Xiaoyu Xu, Seun- gone Kim, Minxin Du, Radha Poovendran, Graham Neubig, and Xiang Yue. Does math reasoning improve general llm capabilities? understanding transferability of llm reasoning. arXiv preprint arXiv:2507.00432, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu- Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward-decoupled normalization policy optimiza- tion for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Understand- ing r1-zero-like training: A critical perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understand- ing r1-zero-like training: A critical perspective. InSecond Conference on Language Modeling, 2025
2025
-
[12]
Generalization of rlvr using causal reasoning as a testbed.arXiv preprint arXiv:2512.20760, 2025
Brian Lu, Hongyu Zhao, Shuo Sun, Hao Peng, Rui Ding, and Hongyuan Mei. Generalization of rlvr using causal reasoning as a testbed.arXiv preprint arXiv:2512.20760, 2025
-
[13]
Gmts: Gradient magnitude-based token selection improves rlvr training for llm reasoning, 2026
Outongyi Lv, Yuanwei Zhang, et al. Gmts: Gradient magnitude-based token selection improves rlvr training for llm reasoning, 2026
2026
-
[14]
Chiyu Ma, Shuo Yang, Kexin Huang, Jinda Lu, Haoming Meng, Shangshang Wang, Bolin Ding, Soroush V osoughi, Guoyin Wang, and Jingren Zhou. Fipo: Eliciting deep rea- soning with future-kl influenced policy optimization.arXiv preprint arXiv:2603.19835, 2026
-
[15]
Sparse but critical: A token-level analysis of distributional shifts in rlvr fine-tuning of llms
Haoming Meng, Kexin Huang, Shaohang Wei, Chiyu Ma, Shuo Yang, Xue Wang, Guoyin Wang, Bolin Ding, and Jin- gren Zhou. Sparse but critical: A token-level analysis of distributional shifts in rlvr fine-tuning of llms. InThe Four- teenth International Conference on Learning Representa- tions, 2026
2026
-
[16]
Training language models to follow instructions with human feedback.Ad- vances in neural information processing systems, 35:27730– 27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Ad- vances in neural information processing systems, 35:27730– 27744, 2022
2022
-
[17]
Improving language understanding by gen- erative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by gen- erative pre-training. 2018
2018
-
[18]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junx- iao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Zhihong Shao, Yuxiang Luo, Chengda Lu, ZZ Ren, Jiewen Hu, Tian Ye, Zhibin Gou, Shirong Ma, and Xiaokang Zhang. Deepseekmath-v2: Towards self-verifiable mathe- matical reasoning.arXiv preprint arXiv:2511.22570, 2025
-
[21]
Rethinking sample polarity in reinforcement learning with verifiable rewards
Xinyu Tang, Yuliang Zhan, Zhixun Li, Wayne Xin Zhao, Zhenduo Zhang, Zujie Wen, Zhiqiang Zhang, and Jun Zhou. Rethinking sample polarity in reinforcement learning with verifiable rewards. InProceedings of the 64th Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2928–2954, 2026
2026
-
[22]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Shumin Wang, Yuexiang Xie, Wenhao Zhang, Yuchang Sun, Yanxi Chen, Yaliang Li, and Yanyong Zhang. On the en- tropy dynamics in reinforcement fine-tuning of large lan- guage models.arXiv preprint arXiv:2602.03392, 2026
-
[24]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shix- uan Liu, Rui Lu, Kai Dang, Xiong-Hui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.Advances in Neural Information Processing Systems, 38:115452–115486, 2026
2026
-
[25]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[26]
Reasoning or memorization? unreliable results of reinforcement learning due to data contamination
Mingqi Wu, Zhihao Zhang, Qiaole Dong, Zhiheng Xi, Jun Zhao, Senjie Jin, Xiaoran Fan, Yuhao Zhou, Huijie Lv, Ming Zhang, et al. Reasoning or memorization? unreliable results of reinforcement learning due to data contamination. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 33944–33952, 2026
2026
-
[27]
Xi, Z., Guo, X., Nan, Y ., Zhou, E., et al
Zhiheng Xi, Xin Guo, Yang Nan, Enyu Zhou, Junrui Shen, Wenxiang Chen, Jiaqi Liu, Jixuan Huang, Zhihao Zhang, Honglin Guo, et al. Bapo: Stabilizing off-policy reinforce- ment learning for llms via balanced policy optimization with adaptive clipping.arXiv preprint arXiv:2510.18927, 2025
-
[28]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Do not let low- probability tokens over-dominate in rl for llms
Zhihe Yang, Xufang Luo, Zilong Wang, Dongqi Han, Zhiyuan He, Dongsheng Li, and Yunjian Xu. Do not let low- probability tokens over-dominate in rl for llms. In2nd AI for Math Workshop@ ICML, 2025
2025
-
[30]
Future-KL Regularized GRPO: Process-Level Credit Assignment from $f$-Divergence Regularization
Jiarui Yao, Ruida Wang, et al. Future-kl regularized grpo: Process-level credit assignment from f-divergence regular- ization.arXiv preprint arXiv:2601.10201, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Dapo: An open-source llm reinforce- ment learning system at scale.Advances in Neural Informa- tion Processing Systems, 38:113222–113244, 2026
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforce- ment learning system at scale.Advances in Neural Informa- tion Processing Systems, 38:113222–113244, 2026
2026
-
[32]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
EDGE-GRPO: entropy-driven GRPO with guided error correction for advantage diversity
Xingjian Zhang, Siwei Wen, Wenjun Wu, and Lei Huang. Edge-grpo: Entropy-driven grpo with guided error correction for advantage diversity.arXiv preprint arXiv:2507.21848, 2025
-
[34]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
The surprising effectiveness of negative reinforcement in llm reasoning.Advances in Neural Information Processing Systems, 38:126546–126573, 2026
Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng. The surprising effectiveness of negative reinforcement in llm reasoning.Advances in Neural Information Processing Systems, 38:126546–126573, 2026
2026
-
[36]
Appendix A All experiments are conducted with random seed fixed to 0unless otherwise specified
Appendix 6.1. Appendix A All experiments are conducted with random seed fixed to 0unless otherwise specified. For thePBexperiments, we directly follow the released implementation of Yang et al. [29]. For theEBexperiments, we port the key micro-batch processing routine from Wang et al. [24] into our EasyR1- based training pipeline, which enables token-leve...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.