Is Natural Always Appropriate? Investigating Naturalness and Appropriateness Across Different Domains for TTS Evaluation
Pith reviewed 2026-07-01 03:28 UTC · model grok-4.3
The pith
Appropriateness of TTS speech varies independently of naturalness across domains such as reading versus acting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Listener ratings of appropriateness for identical TTS outputs change with the expected domain while naturalness ratings do not track the same changes; systems perform best when the domain is reading and struggle when the domain requires expressive or stylized delivery, and naturalness metrics systematically penalize stylization while favoring spontaneity.
What carries the argument
Side-by-side listener ratings of naturalness versus appropriateness collected for the same five TTS systems across the five target domains.
If this is right
- Appropriateness can be optimized for one domain only at the cost of appropriateness in another domain.
- Current systems reach their highest appropriateness when used for reading but fall short for actor, animated-character, or spontaneous-speaker roles.
- Naturalness scores alone will undervalue stylized speech and overvalue spontaneous speech.
- Universal evaluation protocols leave measurable blind spots once domains become more expressive.
Where Pith is reading between the lines
- TTS developers may need separate models or fine-tuning pipelines for each broad usage class rather than a single general model.
- Evaluation protocols could shift from one overall score to a small set of domain-specific test batteries.
- Future work might test whether training objectives that directly target appropriateness per domain close the observed gaps.
Load-bearing premise
The five selected domains and five systems represent the range of real uses, and listener ratings capture genuine perceptual differences without order or rater-pool bias.
What would settle it
A controlled test in which the same TTS outputs receive statistically identical appropriateness scores across all five domains, or in which naturalness and appropriateness ratings remain tightly correlated in every domain.
Figures


read the original abstract
Text-to-speech (TTS) evaluation is an open challenge. While the primary target was "naturalness," recent fidelity gains shifted focus toward "appropriateness" and whether speech is correct for its context. In this work, we examine how perception changes when the expected downstream use varies. We measure the appropriateness and human-likeness of five SOTA TTS systems across five domains: AI assistant, reader, actor, animated character, and spontaneous speaker. Results show appropriateness varies across domains independently of naturalness. While systems shine at reading, expressive domains remain challenging, and optimizing for one can degrade others. Furthermore, naturalness scores tend to penalize stylized speech while rewarding spontaneity. Finally, our study also highlights blind spots in one-size-fits-all evaluation metrics across more expressive domains. We demonstrate that TTS performance is not "solved" but depends on the target domain, requiring context-aware evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a listening study comparing five SOTA TTS systems on five domains (AI assistant, reader, actor, animated character, spontaneous speaker). It claims that appropriateness ratings vary across domains independently of naturalness ratings, that systems perform best on reading-style tasks while expressive domains remain difficult, that optimizing for one domain can degrade performance in others, and that standard naturalness metrics penalize stylized speech while rewarding spontaneity. The work concludes that one-size-fits-all TTS evaluation metrics have blind spots and that domain-aware evaluation is required.
Significance. If the empirical patterns hold after proper statistical controls, the study provides concrete evidence that current naturalness-centric evaluation practices are insufficient for downstream TTS applications and that appropriateness is not reducible to naturalness. This could motivate development of context-sensitive metrics and domain-adapted synthesis methods.
major comments (2)
- [Abstract] Abstract and results sections: the claim that 'optimizing for one can degrade others' is not supported by the experimental design. The study evaluates five fixed SOTA systems without any domain-specific fine-tuning, adaptation, ablation, or optimization experiments that would demonstrate trade-offs; observed differences may simply reflect pre-existing system specializations rather than optimization effects.
- [Abstract / Methods] Methods and results: the abstract states headline findings but supplies no participant counts, statistical tests, raw data, exclusion criteria, or inter-rater reliability measures. These omissions leave the central empirical claims (domain-independent variation of appropriateness, differential system performance) without verifiable support.
minor comments (1)
- [Introduction / Discussion] The five chosen domains and systems are presented without explicit justification of representativeness for real downstream uses; a brief rationale or limitations paragraph would strengthen the generalizability discussion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below, acknowledging where the experimental design limits certain interpretations and clarifying where the manuscript already provides supporting details.
read point-by-point responses
-
Referee: [Abstract] Abstract and results sections: the claim that 'optimizing for one can degrade others' is not supported by the experimental design. The study evaluates five fixed SOTA systems without any domain-specific fine-tuning, adaptation, ablation, or optimization experiments that would demonstrate trade-offs; observed differences may simply reflect pre-existing system specializations rather than optimization effects.
Authors: We agree that the experimental design evaluates five fixed systems and does not include optimization, fine-tuning, or ablation studies, so direct evidence of optimization-induced trade-offs is not present. The observed domain-specific performance patterns may reflect pre-existing system characteristics. We will revise the abstract and discussion to replace the phrase with wording that accurately describes the results, such as 'systems exhibit substantial performance variation across domains, with no single system excelling universally.' revision: yes
-
Referee: [Abstract / Methods] Methods and results: the abstract states headline findings but supplies no participant counts, statistical tests, raw data, exclusion criteria, or inter-rater reliability measures. These omissions leave the central empirical claims (domain-independent variation of appropriateness, differential system performance) without verifiable support.
Authors: The full manuscript reports participant counts, statistical tests, exclusion criteria, and inter-rater reliability in the Methods section, with corresponding results and analyses in the Results section. The abstract provides a concise summary of findings and is not intended to contain all methodological details; the central claims are supported by the analyses presented in the body of the paper. revision: no
Circularity Check
No circularity: purely empirical listening study
full rationale
The paper is an empirical user study that collects and analyzes human ratings of naturalness and appropriateness for five TTS systems across five domains. It contains no equations, derivations, fitted parameters, predictions, or ansatzes that could reduce results to inputs by construction. No self-citations serve as load-bearing uniqueness theorems or imported ansatzes. All claims rest on direct experimental data from listener evaluations, with no reduction of outputs to prior fitted values or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human listeners provide reliable ratings of speech naturalness and appropriateness via subjective tests
Reference graph
Works this paper leans on
-
[1]
Introduction Text-to-speech is fundamentally a one-to-many problem: the same sentence can be spoken in countless ways while remaining intelligible. Prosody, pacing, and delivery vary naturally de- pending on the situation, the speaker’s intent, and the audience. Consequently, good synthesis depends entirely on delivery and performance style. A voice perfe...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
convincing- ness
Methodology 2.1. Perception Study Design To evaluate the perception of appropriatness of synthetic speech across domains, we conduct a perceptual study. We design the listening test using a Gradio interface hosted on Prolific [20]12. We recruited 150 native English speakers (95% approval rating) via Prolific, split into 6 sessions of 25 participants. We c...
-
[3]
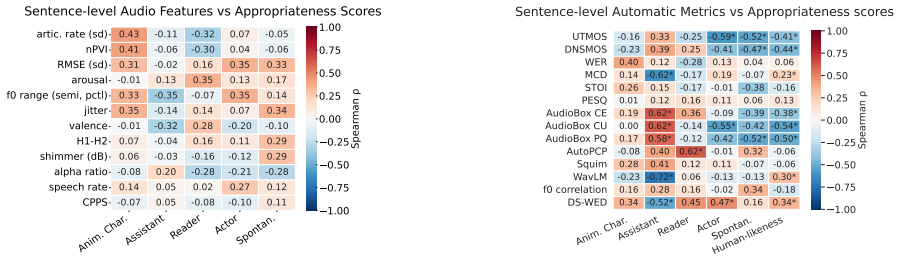
Appropriateness Across Domains Figure 1 shows the distributed score for each persona across the TTS and all tasks
Results 3.1. Appropriateness Across Domains Figure 1 shows the distributed score for each persona across the TTS and all tasks. The results show that while most systems achieve high appropriateness scores for reading or AI assistant roles, for some contexts like spontaneous conversation, actor, and animated character personas remain more challenging. Spec...
-
[4]
Discussion & Limitations This study demonstrates that speech evaluation is inherently domain-dependent. Listener judgments for the same utterance shift based on the framed scenario, showing that perceived qual- ity depends as much on situational expectations as the acoustic signal itself. Our findings confirm that human-likeness and ap- propriateness are ...
-
[5]
appearing human-like
Conclusion In light of the recent improvement in TTS performance, the question of quantifying progress has become more pertinent than ever. Most works focus onnaturalness, a term which is usu- ally equated with “appearing human-like”, in colloquial terms. Yet, our listening experiments show that theappropriateness of a response is context and application-...
-
[6]
Any generated content was reviewed and edited by authors who maintain full responsibility for the final content
Generative AI Use Disclosure Generative AI was used to edit and polish drafts made by the authors. Any generated content was reviewed and edited by authors who maintain full responsibility for the final content
-
[7]
An overview of affective speech synthesis and conversion in the deep learning era,
A. Triantafyllopouloset al., “An overview of affective speech synthesis and conversion in the deep learning era,”Proceedings of the IEEE, vol. 111, no. 10, pp. 1355–1381, 2023
2023
-
[8]
Speech synthesis evaluation—state-of-the-art assessment and suggestion for a novel research program,
P. Wagneret al., “Speech synthesis evaluation—state-of-the-art assessment and suggestion for a novel research program,” inPro- ceedings of the 10th Speech Synthesis Workshop (SSW10), 2019
2019
-
[9]
A multi-dimensional evalua- tion of the 2025 blizzard challenge,
S. Shirali-Shahreza and G. Penn, “A multi-dimensional evalua- tion of the 2025 blizzard challenge,” inof the Speech Synthesis Workshop, 2025, pp. 209–214
2025
-
[10]
The limits of the mean opinion score for speech synthesis evaluation,
S. Le Magueret al., “The limits of the mean opinion score for speech synthesis evaluation,”Computer Speech & Language, vol. 84, p. 101577, 2024
2024
-
[11]
Refining the evaluation of speech synthesis: A summary of the blizzard challenge 2023,
O. Perrotinet al., “Refining the evaluation of speech synthesis: A summary of the blizzard challenge 2023,”Computer Speech & Language, vol. 90, p. 101747, 2025
2023
-
[12]
Assessing the impact of contextual framing on subjective tts quality,
J. Edlundet al., “Assessing the impact of contextual framing on subjective tts quality,” inInterspeech. ISCA-International Speech Communication Association, 2024, pp. 1205–1209
2024
-
[13]
Better replacement for tts nat- uralness evaluation,
S. Shirali-Shahreza and G. Penn, “Better replacement for tts nat- uralness evaluation,” in12th Speech Synthesis Workshop (SSW) 2023, 2023
2023
-
[14]
A review on subjective and objective evaluation of synthetic speech,
E. Cooperet al., “A review on subjective and objective evaluation of synthetic speech,”Acoustical Science and Technology, vol. 45, 04 2024
2024
-
[15]
Ttsds-text-to-speech distribution score,
C. Minixhoferet al., “Ttsds-text-to-speech distribution score,” in 2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 766–773
2024
-
[16]
Ttsds2: Robust objective evaluation for human-quality synthetic speech,
——, “Ttsds2: Robust objective evaluation for human-quality synthetic speech,” inThe 13th Speech Synthesis Workshop. In- ternational Speech Communication Association (ISCA), 2025, pp. 68–75
2025
-
[17]
Speechrole: A large-scale dataset and bench- mark for evaluating speech role-playing agents,
C. Jianget al., “Speechrole: A large-scale dataset and bench- mark for evaluating speech role-playing agents,”arXiv preprint arXiv:2508.02013, 2025
-
[18]
Speech-drame: A framework for human-aligned benchmarks in speech role-play,
J. Shiet al., “Speech-drame: A framework for human-aligned benchmarks in speech role-play,”arXiv preprint arXiv:2511.01261, 2025
-
[19]
K. Huanget al., “Instructttseval: Benchmarking complex natural- language instruction following in text-to-speech systems,”arXiv preprint arXiv:2506.16381, 2025
-
[20]
EmergentTTS-eval: Evaluating TTS models on complex prosodic, expressiveness, and linguistic challenges us- ing model-as-a-judge,
R. R. Mankuet al., “EmergentTTS-eval: Evaluating TTS models on complex prosodic, expressiveness, and linguistic challenges us- ing model-as-a-judge,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[21]
arXiv preprint arXiv:2402.08093 , year=
M. Łajszczaket al., “Base tts: Lessons from building a billion- parameter text-to-speech model on 100k hours of data,”arXiv preprint arXiv:2402.08093, 2024
-
[22]
What is Naturalness?
A. Pandey, S. Le Maguer, and N. Harte, “What is Naturalness?” in 13th edition of the Speech Synthesis Workshop, 2025, pp. 215–221
2025
-
[23]
Rating naturalness in speech synthesis: The effect of style and expectation,
R. Dallet al., “Rating naturalness in speech synthesis: The effect of style and expectation,” inSpeech Prosody 2014, 2014
2014
-
[24]
Effect of speech dialect on speech naturalness ratings: A systematic replication of martin, haroldson, and triden (1984),
L. S. Mackeyet al., “Effect of speech dialect on speech naturalness ratings: A systematic replication of martin, haroldson, and triden (1984),”Journal of Speech, Language, and Hearing Research, vol. 40, no. 2, pp. 349–360, 1997
1984
-
[25]
Y . Leeet al., “P2va: Converting persona descriptions into voice attributes for fair and controllable text-to-speech,”arXiv preprint arXiv:2505.17093, 2025
-
[26]
Prolific research,
“Prolific research,” [Online; accessed 2026-03-04]. [Online]. Available: https://researcher-help.prolific.com/en/
2026
-
[27]
Computational Narrative Understanding for Expressive Text-to-Speech
G. Michelet al., “Libriquote: A speech dataset of fictional char- acter utterances for expressive zero-shot speech synthesis,”arXiv preprint arXiv:2509.04072, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Building naturalistic emotionally bal- anced speech corpus by retrieving emotional speech from existing podcast recordings,
R. Lotfian and C. Busso, “Building naturalistic emotionally bal- anced speech corpus by retrieving emotional speech from existing podcast recordings,”IEEE Transactions on Affective Computing, vol. 10, no. 4, pp. 471–483, 2017
2017
-
[29]
MELD: A multimodal multi-party dataset for emotion recognition in conversations,
S. Poriaet al., “MELD: A multimodal multi-party dataset for emotion recognition in conversations,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M`arquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul. 2019, pp. 527–536
2019
-
[30]
taresh18/animevox · datasets at hugging face,
“taresh18/animevox · datasets at hugging face,” 7 2025, [Online; accessed 2026-03-04]. [Online]. Available: https: //huggingface.co/datasets/taresh18/AnimeV ox
2025
-
[31]
The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,
F. Eybenet al., “The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,”IEEE trans- actions on affective computing, vol. 7, no. 2, pp. 190–202, 2015
2015
-
[32]
Opensmile: the munich versatile and fast open-source audio feature extractor,
F. Eyben, M. W¨ollmer, and B. Schuller, “Opensmile: the munich versatile and fast open-source audio feature extractor,” inProceed- ings of the 18th ACM international conference on Multimedia, 2010, pp. 1459–1462
2010
-
[33]
T. Fenget al., “V ox-profile: A speech foundation model benchmark for characterizing diverse speaker and speech traits,”arXiv preprint arXiv:2505.14648, 2025
-
[34]
The t05 system for the VoiceMOS Challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech,
K. Babaet al., “The t05 system for the VoiceMOS Challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech,” inIEEE Spoken Language Technology Workshop (SLT), 2024, pp. 818–824
2024
-
[35]
Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,
C. K. Reddyet al., “Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” inICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6493–6497
2021
-
[36]
Torchaudio-squim: Reference-less speech quality and intelligibility measures in torchaudio,
A. Kumaret al., “Torchaudio-squim: Reference-less speech quality and intelligibility measures in torchaudio,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[37]
Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,
A. W. Rixet al., “Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in2001 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221), vol. 2. IEEE, 2001, pp. 749–752
2001
-
[38]
Mel-cepstral distance measure for objective speech quality assessment,
R. Kubichek, “Mel-cepstral distance measure for objective speech quality assessment,” inProceedings of IEEE Pacific Rim Confer- ence on Communications Computers and Signal Processing, vol. 1, 1993, pp. 125–128 vol.1
1993
-
[39]
An algorithm for intelligibility prediction of time–frequency weighted noisy speech,
C. H. Taalet al., “An algorithm for intelligibility prediction of time–frequency weighted noisy speech,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2125– 2136, 2011
2011
-
[40]
Swiftf0: Fast and accurate monophonic pitch detec- tion,
L. Nieradzik, “Swiftf0: Fast and accurate monophonic pitch detec- tion,”arXiv preprint arXiv:2508.18440, 2025
-
[41]
L. Barraultet al., “Seamless: Multilingual expressive and stream- ing speech translation,”arXiv preprint arXiv:2312.05187, 2023
-
[42]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chenet al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[43]
Audiobox: Unified audio generation with natural language prompts
A. Vyaset al., “Audiobox: Unified audio generation with natural language prompts,”arXiv preprint arXiv:2312.15821, 2023
-
[44]
nvidia/parakeet-tdt-0.6b-v2 · hugging face,
“nvidia/parakeet-tdt-0.6b-v2 · hugging face,” 8 2025, [Online; accessed 2026-03-05]. [Online]. Available: https://huggingface.co /nvidia/parakeet-tdt-0.6b-v2
2025
-
[45]
Measuring prosody diversity in zero-shot tts: A new metric, benchmark, and exploration,
Y . Yanget al., “Measuring prosody diversity in zero-shot tts: A new metric, benchmark, and exploration,”arXiv preprint arXiv:2509.19928, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.