Play Like Champions: Counterfactual Feedback Generation in Latent Space
Pith reviewed 2026-07-02 19:39 UTC · model grok-4.3
The pith
A guided variational autoencoder trained on professional StarCraft replays generates counterfactual traversals from losing to winning player profiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Latent Maps of Performance, a framework for counterfactual path generation in a learned representation space. Training a Guided Variational Autoencoder on 23,305 professional StarCraft II replays enables traversals between losing and winning gameplay profiles. Four strategies—linear interpolation, iterative optimal transport, density-regularized gradient ascent, and neural flow matching—generate multi-step improvement trajectories that remain grounded in expert behavior while moving profiles toward winning configurations. Feedback is extracted at multiple granularities to support players at different stages.
What carries the argument
Guided Variational Autoencoder whose latent space supports four traversal strategies to produce grounded improvement trajectories from losing to winning profiles.
If this is right
- Players obtain multi-step trajectories that stay consistent with expert behavior.
- Feedback can be provided at different granularities depending on the player's current stage.
- Different path-finding methods exhibit a measurable trade-off in the quality of generated trajectories.
- Player improvement is modeled as algorithmic recourse inside the learned representation space.
Where Pith is reading between the lines
- The same latent-space approach could be tested on other games with large expert replay datasets to check if the four strategies generalize.
- A direct experiment would compare win-rate lift when amateurs train against the generated paths versus standard coaching methods.
- The framework might connect to existing sports-science championship models by treating replay data as a stand-in for performance metrics.
Load-bearing premise
The latent space learned only from professional replays supports traversals that correspond to genuine, achievable improvement when applied to amateur profiles.
What would settle it
Whether amateur players who follow the generated paths in actual matches achieve higher win rates than a control group using the same replays without the paths.
Figures

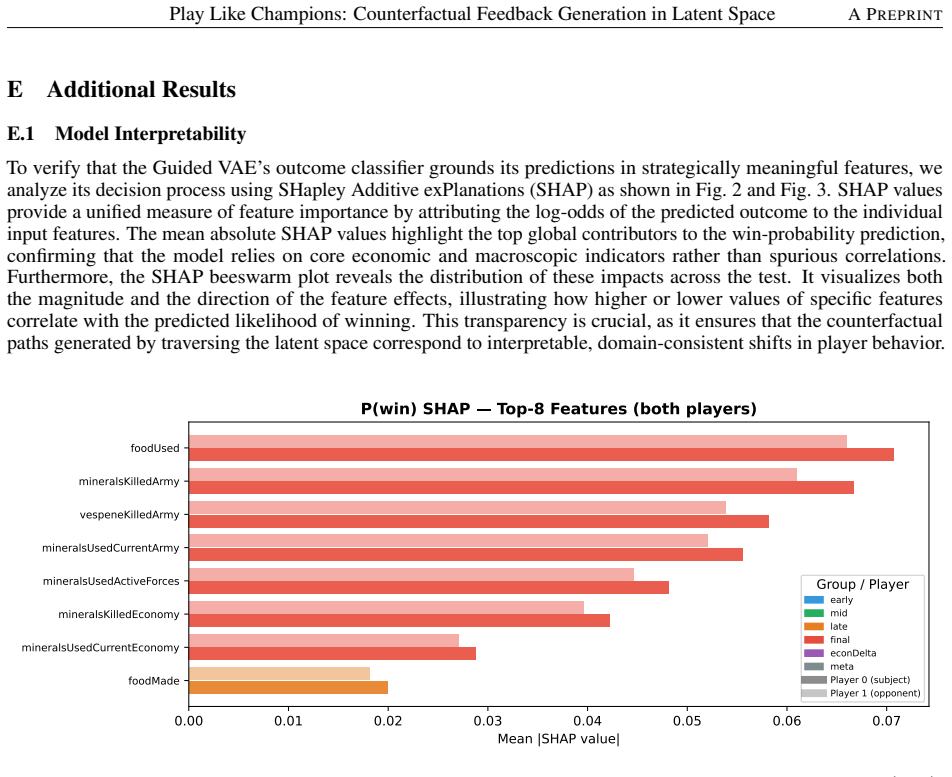
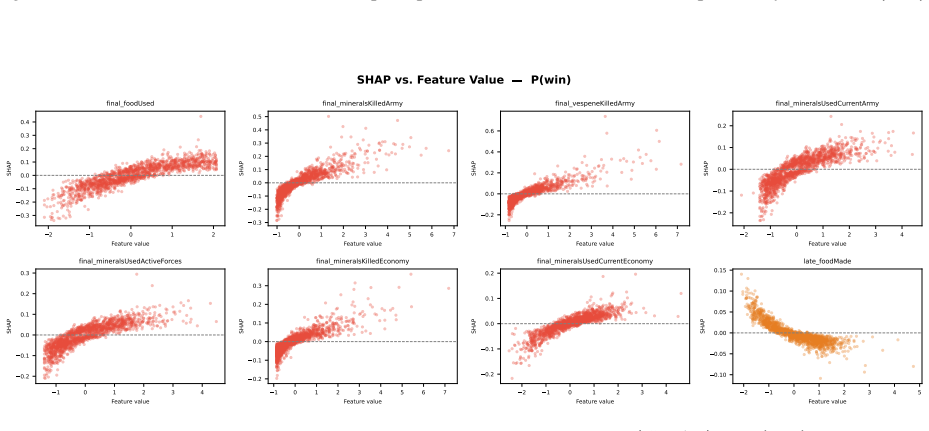
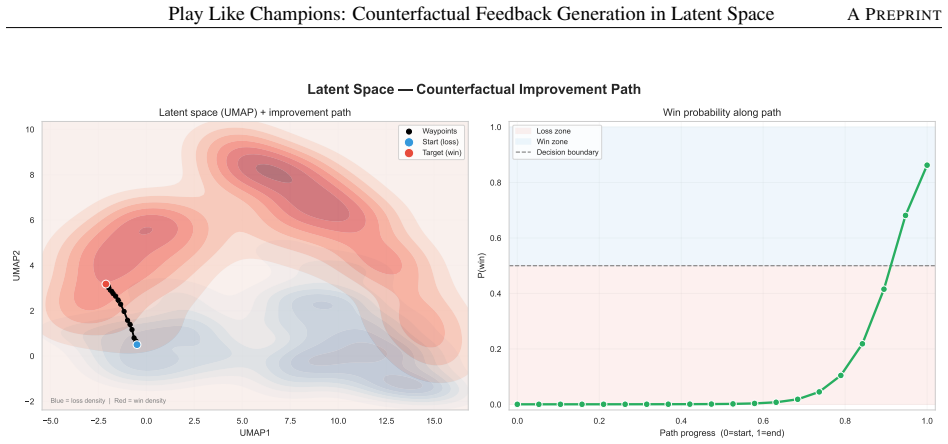

read the original abstract
Recent advances in reinforcement learning have produced superhuman agents across a wide range of competitive games. As a byproduct, researchers have begun studying how these agents play, extracting behavioral representations, analyzing decision structure, and modeling the latent geometry of expert performance. However, this growing body of work has overwhelmingly focused on defeating human players rather than providing feedback, leaving a critical gap in creating model solutions to improve human players. Unlike chess and Go, where AI has become integral to player training, real-time strategy (RTS) games lack principled frameworks for translating expert knowledge into actionable feedback. We introduce Latent Maps of Performance, a framework for counterfactual path generation. We focus on StarCraft~II data to model player improvement as an algorithmic recourse within a learned representation space. As inspiration for our work, we have looked at the championship model used in sports science. We trained a Guided Variational Autoencoder model on 23,305 professional tournament replays, enabling counterfactual traversal between losing and winning gameplay profiles. To fulfill our goal, we have devised and verified four traversal strategies on out-of-distribution (OOD) data randomly sampled from a dataset of amateur replays, namely linear interpolation, iterative optimal transport, density-regularized gradient ascent, and neural flow matching, each designed to generate multi-step improvement trajectories that remain grounded in observed expert behavior while moving a player's profile toward winning configurations. Feedback is extracted at multiple granularities to support players at different stages of improvement. Finally, we conclude that there is a trade-off between the path-finding methods we employ and hope that future research will focus on developing model solutions for human improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'Latent Maps of Performance', a framework for counterfactual path generation in StarCraft II. It trains a Guided Variational Autoencoder on 23,305 professional tournament replays to learn a latent representation of gameplay profiles, then devises and applies four traversal strategies (linear interpolation, iterative optimal transport, density-regularized gradient ascent, and neural flow matching) on out-of-distribution amateur replays to generate multi-step trajectories from losing to winning configurations, with feedback extracted at multiple granularities.
Significance. If the central claim holds, the work could address a gap in using superhuman AI for human improvement rather than defeat in RTS games by providing principled counterfactual feedback grounded in expert data. The explicit separation of professional training data from amateur OOD test data avoids circularity and supports falsifiable evaluation. The multi-method comparison and multi-granularity feedback are constructive elements.
major comments (1)
- [Abstract] Abstract: The claim that the four traversal strategies were 'devised and verified' on OOD amateur replays supplies no quantitative results (e.g., win-rate delta, correlation with actual progression, or human expert ratings), no description of the verification procedure, and no metrics showing that endpoints correspond to better play rather than latent artifacts. This is load-bearing for the central claim that traversals produce genuine improvement grounded in observed expert behavior.
minor comments (1)
- [Abstract] Abstract: The notation 'StarCraft~II' is a likely LaTeX artifact and should be rendered as 'StarCraft II'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the framework to address a gap in using expert data for human improvement in RTS games. We agree that the abstract requires strengthening to better support its claims about verification.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the four traversal strategies were 'devised and verified' on OOD amateur replays supplies no quantitative results (e.g., win-rate delta, correlation with actual progression, or human expert ratings), no description of the verification procedure, and no metrics showing that endpoints correspond to better play rather than latent artifacts. This is load-bearing for the central claim that traversals produce genuine improvement grounded in observed expert behavior.
Authors: We agree that the abstract as written does not include the requested quantitative results or verification details, which weakens the presentation of the central claim. The full manuscript contains multi-method evaluations on OOD amateur replays, including win-rate deltas between start and end points, density-based checks against expert distributions, and comparisons showing that generated endpoints align with winning professional profiles rather than interpolation artifacts. To address the referee's concern directly, we will revise the abstract to include summary quantitative metrics (e.g., average win-rate improvement and correlation with expert progression) and a concise description of the verification procedure, making the load-bearing claim explicit and falsifiable. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper trains a Guided VAE exclusively on 23,305 professional replays and evaluates four traversal strategies on separate amateur OOD replays. No equations, fitted parameters, or results are shown to reduce to their own inputs by construction; the verification step uses external amateur data rather than re-deriving quantities from the pro-trained model itself. No self-citations appear as load-bearing premises, no uniqueness theorems are imported from prior author work, and no ansatz or renaming patterns are invoked. The derivation chain remains self-contained against the described external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
StarCraft II: A New Challenge for Reinforcement Learning
O. Vinyals, T. Ewalds, S. Bartunov, P. Georgiev, A. S. Vezhnevets, M. Yeo, A. Makhzani, H. Küttler, J. Agapiou, J. Schrittwieser, J. Quan, S. Gaffney, S. Petersen, K. Simonyan, T. Schaul, H. van Hasselt, D. Silver, T. Lillicrap, K. Calderone, P. Keet, A. Brunasso, D. Lawrence, A. Ekermo, J. Repp, and R. Tsing, “Starcraft ii: A new challenge for reinforcem...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Alphastar unplugged: Large-scale offline reinforcement learning,
M. Mathieu, S. Ozair, S. Srinivasan, C. Gulcehre, S. Zhang, R. Jiang, T. L. Paine, R. Powell, K. ˙Zołna, J. Schrittwieser, D. Choi, P. Georgiev, D. Toyama, A. Huang, R. Ring, I. Babuschkin, T. Ewalds, M. Bordbar, S. Henderson, S. G. Colmenarejo, A. van den Oord, W. M. Czarnecki, N. de Freitas, and O. Vinyals, “Alphastar unplugged: Large-scale offline rein...
-
[3]
Video game telemetry as a critical tool in the study of complex skill learning,
J. J. Thompson, M. R. Blair, L. Chen, and A. J. Henrey, “Video game telemetry as a critical tool in the study of complex skill learning,”PLOS ONE, vol. 8, no. 9, pp. 1–12, 09 2013. [Online]. Available: https://doi.org/10.1371/journal.pone.0075129 (Cited on page: 1)
-
[4]
Sc2egset: Starcraft ii esport replay and game-state dataset,
A. Białecki, N. Jakubowska, P. Dobrowolski, P. Białecki, L. Krupi´nski, A. Szczap, R. Białecki, and J. Gajewski, “Sc2egset: Starcraft ii esport replay and game-state dataset,”Scientific Data, vol. 10, no. 1, p. 600, Sep 2023. [Online]. Available: https://doi.org/10.1038/s41597-023-02510-7 (Cited on pages: 1, 3)
-
[5]
Carefully structured compression: Efficiently managing starcraft ii data,
B. Ferenczi, R. Newbury, M. Burke, and T. Drummond, “Carefully structured compression: Efficiently managing starcraft ii data,” 2024. [Online]. Available: https://arxiv.org/abs/2410.08659 (Cited on page: 1)
-
[6]
Live feedback for training through real-time data visualizations: A study with league of legends,
F. Rijnders, G. Wallner, and R. Bernhaupt, “Live feedback for training through real-time data visualizations: A study with league of legends,”Proc. ACM Hum.-Comput. Interact., vol. 6, no. CHI PLAY , oct 2022. [Online]. Available: https://doi.org/10.1145/3549506 (Cited on page: 1)
-
[7]
sc2replaystats,
A. Martin, “sc2replaystats,” https://sc2replaystats.com/, 2012, acessed: 2026.04.28. (Cited on pages: 1, 3)
2012
-
[8]
REPLAYMAN — SC2 Replay Analysis & Management – replayman.com,
B. Dibbell, “REPLAYMAN — SC2 Replay Analysis & Management – replayman.com,” https://replayman.com/, 2026, [Accessed 28-04-2026]. (Cited on page: 1)
2026
-
[9]
Real-time dashboards to support esports spectating,
S. Charleer, K. Gerling, F. Gutiérrez, H. Cauwenbergh, B. Luycx, and K. Verbert, “Real-time dashboards to support esports spectating,” inProceedings of the 2018 Annual Symposium on Computer-Human Interaction in Play, ser. CHI PLAY ’18. New York, NY , USA: Association for Computing Machinery, 2018, pp. 59–71. [Online]. Available: https://doi.org/10.1145/32...
-
[10]
Visualizations for retrospective analysis of battles in team-based combat games: A user study,
G. Wallner and S. Kriglstein, “Visualizations for retrospective analysis of battles in team-based combat games: A user study,” inProceedings of the 2016 Annual Symposium on Computer-Human Interaction in Play, ser. CHI PLAY ’16. New York, NY , USA: Association for Computing Machinery, 2016, pp. 22–32. [Online]. Available: https://doi.org/10.1145/2967934.29...
-
[11]
ggviz: Accelerating large-scale esports game analysis,
P. Xenopoulos, J. a. Rulff, and C. Silva, “ggviz: Accelerating large-scale esports game analysis,”Proc. ACM Hum.-Comput. Interact., vol. 6, no. CHI PLAY , oct 2022. [Online]. Available: https://doi.org/10.1145/3549501 (Cited on page: 2)
-
[12]
N. Shaker, J. Togelius, and M. J. Nelson,Procedural Content Generation in Games. Springer International Publishing, 2016. [Online]. Available: http://dx.doi.org/10.1007/978-3-319-42716-4 (Cited on page: 2)
-
[13]
F.a.c.u.l.: Language-based interaction with ai companions in gaming,
W. Wei, S. Yang, Q. Zhou, R. Liu, X. Zhang, Y . Yuan, Y . Jiang, Y . Luo, H. Wang, T. Wang, P. Jin, W. Liu, Z. Zhao, X. Jin, and E. S. Liu, “F.a.c.u.l.: Language-based interaction with ai companions in gaming,” 2025. [Online]. Available: https://arxiv.org/abs/2511.13112 (Cited on page: 2)
-
[14]
A. Sestini, J. Bergdahl, J.-P. Barrette-LaPierre, F. Fuchs, B. Chen, M. Jones, and L. Gisslén, “Human-like goalkeeping in a realistic football simulation: a sample-efficient reinforcement learning approach,” 2025. [Online]. Available: https://arxiv.org/abs/2510.23216 (Cited on page: 2)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Using reinforcement learning for load testing of video games,
R. Tufano, S. Scalabrino, L. Pascarella, E. Aghajani, R. Oliveto, and G. Bavota, “Using reinforcement learning for load testing of video games,” inProceedings of the 44th International Conference on Software Engineering, ser. ICSE ’22. New York, NY , USA: Association for Computing Machinery, 2022, pp. 2303–2314. [Online]. Available: https://doi.org/10.114...
-
[16]
Dax: Data-driven audience experiences in esports,
A. V . Kokkinakis, S. Demediuk, I. Nölle, O. Olarewaju, S. Patra, J. Robertson, P. York, A. P. Pedrassoli Chitayat, A. Coates, D. Slawson, P. Hughes, N. Hardie, B. Kirman, J. Hook, A. Drachen, M. F. Ursu, and F. Block, “Dax: Data-driven audience experiences in esports,” inProceedings of the 2020 ACM International Conference on Interactive Media Experience...
-
[17]
Newton: GPU-accelerated physics simulation for robotics and simulation research,
The Newton Contributors, “Newton: GPU-accelerated physics simulation for robotics and simulation research,” apr 2025. [Online]. Available: https://github.com/newton-physics/newton (Cited on page: 2)
2025
-
[18]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Muñoz, X. Yao, R. Zurbrügg, N. Rudin, L. Wawrzyniak, M. Rakhsha, A. Denzler, E. Heiden, A. Borovicka, O. Ahmed, I. Akinola, A. Anwar, M. T. Carlson, J. Y . Feng, A. Garg, R. Gasoto, L. Gulich, Y . Guo, M. Gussert, A. Hansen, M. Kulkarni, C. Li, W. Liu, V . Makoviychuk, G. Malczyk, H. Ma...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Champion-level drone racing using deep reinforcement learning,
E. Kaufmann, L. Bauersfeld, A. Loquercio, M. Müller, V . Koltun, and D. Scaramuzza, “Champion-level drone racing using deep reinforcement learning,”Nature, vol. 620, no. 7976, pp. 982–987, Aug 2023. [Online]. Available: https://doi.org/10.1038/s41586-023-06419-4 (Cited on page: 2)
-
[20]
A sim-to-real deep learning-based framework for autonomous nano-drone racing,
L. Lamberti, E. Cereda, G. Abbate, L. Bellone, V . J. K. Morinigo, M. Barci´s, A. Barci´s, A. Giusti, F. Conti, and D. Palossi, “A sim-to-real deep learning-based framework for autonomous nano-drone racing,”IEEE Robotics and Automation Letters, vol. 9, no. 2, pp. 1899–1906, 2024. (Cited on page: 2)
1906
-
[21]
Learning coordinated badminton skills for legged manipulators,
Y . Ma, A. Cramariuc, F. Farshidian, and M. Hutter, “Learning coordinated badminton skills for legged manipulators,”Science Robotics, vol. 10, no. 102, may 2025. [Online]. Available: http://dx.doi.org/10.1126/scirobotics.adu3922 (Cited on page: 2)
-
[22]
Humanoid Whole-Body Badminton via Multi-Stage Reinforcement Learning
C. Liu, L. Jiang, Y . Wang, K. Yao, J. Fu, and X. Ren, “Humanoid whole-body badminton via multi-stage reinforcement learning,” 2026. [Online]. Available: https://arxiv.org/abs/2511.11218 (Cited on page: 2)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Outplaying elite table tennis players with an autonomous robot,
P. Dürr, M. El Gheche, G. J. Maeda, N. Mukai, N. Takahashi, S. Heusser, H. Sahloul, Y . Saraiji, P. Adodin, Y . Bi, S. Blakeman, C. Conti, D. Fuentes Hitos, Y . Hu, F. Khadivar, R. Kreiser, L. Martinez, F. Schilling, R. Tapiador Morales, G. Torrente, M. Ynocente Castro, L. Abecassis, A. Giammarino, Y .-T. Huang, Y . Nagel, A. Scotti, A. Sigrist, T. Silva,...
-
[24]
A call for deeper collaboration between robotics and game development,
I. Leite, W. Ahlberg, A. Pereira, A. Sestini, L. Gisslén, and K. Tollmar, “A call for deeper collaboration between robotics and game development,” in2025 IEEE Conference on Games (CoG), 2025, pp. 1–8. (Cited on page: 2)
2025
-
[25]
D. J. Hancock, A. M. Rymal, and D. M. Ste-Marie, “A triadic comparison of the use of observational learning amongst team sport athletes, coaches, and officials,”Psychology of Sport and Exercise, vol. 12, no. 3, pp. 236–241, 2011. [Online]. Available: https://doi.org/10.1016/j.psychsport.2010.11.002 (Cited on page: 2)
-
[26]
Soza´nski, J
H. Soza´nski, J. Sadowski, and J. Czerwi´nski,Podstawy Teorii i Technologii Treningu Sportowego. Akademia Wychowania Fizycznego Józefa Piłsudskiego Filia w Białej Podlaskiej, 2015, vol. 2. (Cited on page: 2)
2015
-
[27]
Aligning superhuman ai with human behavior: Chess as a model system,
R. McIlroy-Young, S. Sen, J. Kleinberg, and A. Anderson, “Aligning superhuman ai with human behavior: Chess as a model system,” inProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD ’20. New York, NY , USA: Association for Computing Machinery, 2020, pp. 1677–1687. [Online]. Available: https://doi.org/...
-
[28]
Training with ai: Evidence from chess computers,
F. Gaessler and H. Piezunka, “Training with ai: Evidence from chess computers,”Strategic Management Journal, vol. 44, no. 11, pp. 2724–2750, 2023. [Online]. Available: https://doi.org/10.1002/smj.3512 No citations
-
[29]
Computers and chess masters: The role of ai in transforming elite human performance,
M. Bilali ´c, M. Graf, and N. Vaci, “Computers and chess masters: The role of ai in transforming elite human performance,”British Journal of Psychology, vol. 117, no. 2, pp. 585–609, 2026. [Online]. Available: https://doi.org/10.1111/bjop.12750 (Cited on page: 2)
-
[30]
Sadler and N
M. Sadler and N. Regan,Game Changer: AlphaZero’s Groundbreaking Chess Strategies and the Promise of AI. Alkmaar, Netherlands: New In Chess, 2019. (Cited on page: 2)
2019
-
[31]
How ai-based training affected the performance of professional go players,
J. Kang, J. S. Yoon, and B. Lee, “How ai-based training affected the performance of professional go players,” in Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, ser. CHI ’22. New York, NY , 10 Play Like Champions: Counterfactual Feedback Generation in Latent SpaceA PREPRINT USA: Association for Computing Machinery, 2022. [Onl...
-
[32]
M. Shin, J. Kim, and M. Kim, “Human learning from artificial intelligence: Evidence from human go players’ decisions after alphago,” inCogSci 2021 - The 43rd Annual Meeting of the Cognitive Science Society, 07 2021. [Online]. Available: https://doi.org/10.5281/zenodo.5095146 (Cited on page: 2)
-
[33]
Grandmaster level in StarCraft II using multi-agent reinforcement learning,
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgievet al., “Grandmaster level in StarCraft II using multi-agent reinforcement learning,”Nature, vol. 575, no. 7782, pp. 350–354, 2019. (Cited on page: 2)
2019
-
[34]
The starcraft multi-agent challenge,
M. Samvelyan, T. Rashid, C. S. de Witt, G. Farquhar, N. Nardelli, T. G. J. Rudner, C.-M. Hung, P. H. S. Torr, J. Foerster, and S. Whiteson, “The starcraft multi-agent challenge,” 2019. [Online]. Available: https://arxiv.org/abs/1902.04043 (Cited on page: 2)
-
[35]
Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning,
B. Ellis, J. Cook, S. Moalla, M. Samvelyan, M. Sun, A. Mahajan, J. N. Foerster, and S. Whiteson, “Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning,” 2023. [Online]. Available: https://arxiv.org/abs/2212.07489 (Cited on page: 2)
-
[36]
Player skill modeling in StarCraft II,
T. Avontuur, P. Spronck, and M. van Zaanen, “Player skill modeling in StarCraft II,” inProceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, vol. 9, no. 1, 2013, pp. 2–8. (Cited on page: 2)
2013
-
[37]
StarCraft winner prediction,
S. Bowman, D. Lux, R. Vidal, and A. Drachen, “StarCraft winner prediction,” inProceedings of the 16th International Conference on the Foundations of Digital Games, 2021. (Cited on page: 2)
2021
-
[38]
Auto-Encoding Variational Bayes
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” 2022. [Online]. Available: https: //arxiv.org/abs/1312.6114 (Cited on page: 2)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
β-V AE: Learning basic visual concepts with a constrained variational framework,
I. Higgins, L. Matthey, A. Pal, C. P. Burgess, X. Glorot, M. M. Botvinick, S. Mohamed, and A. Lerchner, “β-V AE: Learning basic visual concepts with a constrained variational framework,” inProceedings of the 5th International Conference on Learning Representations, Toulon, France, 2017. [Online]. Available: https://openreview.net/forum?id=Sy2fzU9gl (Cited...
2017
-
[40]
Guided variational autoencoder for disentanglement learning,
Z. Ding, Y . Xu, W. Xu, G. Parmar, Y . Yang, M. Welling, and Z. Tu, “Guided variational autoencoder for disentanglement learning,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 7917–7926. (Cited on pages: 2, 3, 3)
2020
-
[41]
Disentangled skill representations for predictive human modeling,
M. L. Schrum, S. Srivatsa, D. E. Gopinath, G. Rosman, and T. L. Chen, “Disentangled skill representations for predictive human modeling,” inICLR 2026 Conference Withdrawn Submission, 2025, withdrawn from ICLR
2026
-
[42]
Available: https://openreview.net/forum?id=rwvTTjcuHv (Cited on page: 2)
[Online]. Available: https://openreview.net/forum?id=rwvTTjcuHv (Cited on page: 2)
-
[43]
Optimal transport maps for distribution preserving operations on latent spaces of generative models,
E. Korkmaz, O. Anil Koyejo, and P. Smyth, “Optimal transport maps for distribution preserving operations on latent spaces of generative models,” inICLR Workshop on Deep Generative Models for Highly Structured Data,
-
[44]
Available: https://openreview.net/forum?id=BklCusRct7 (Cited on page: 2)
[Online]. Available: https://openreview.net/forum?id=BklCusRct7 (Cited on page: 2)
-
[45]
Latent traversals in generative models as potential flows,
Y . Song, A. Keller, N. Sebe, and M. Welling, “Latent traversals in generative models as potential flows,” in Proceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023. (Cited on page: 3)
2023
-
[46]
Outcome-guided counterfactuals from a jointly trained generative latent space,
E. Yeh, P. Sequeira, J. Hostetler, and M. Gervasio, “Outcome-guided counterfactuals from a jointly trained generative latent space,” inExplainable Artificial Intelligence (xAI 2023), ser. Communications in Computer and Information Science. Springer, 2023, pp. 449–469. [Online]. Available: https://arxiv.org/abs/2207.07710 (Cited on page: 3)
-
[47]
Counterfactual explanations as interventions in latent space,
R. Crupi, A. Castelnovo, D. Regoli, and B. S. M. Gonzalez, “Counterfactual explanations as interventions in latent space,”Data Mining and Knowledge Discovery, vol. 38, pp. 2733–2769, 2022. (Cited on page: 3, 3)
2022
-
[48]
Data-driven driver training via counterfactual and language-based guidance in racing scenarios,
J. Bae, H. Nam, K. Ryu, J. Lee, J. Kim, H. Chun, J. Han, and J. Choi, “Data-driven driver training via counterfactual and language-based guidance in racing scenarios,”IEEE Access, vol. 13, pp. 170 181–170 199, 2025. (Cited on page: 3)
2025
-
[49]
Counterfactual explanations via Riemannian latent space traversal,
P. Pegios, A. Feragen, A. A. Hansen, and G. Arvanitidis, “Counterfactual explanations via Riemannian latent space traversal,”arXiv preprint arXiv:2411.02259, 2024. [Online]. Available: https://arxiv.org/abs/2411.02259 (Cited on page: 3)
-
[50]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” 2017. [Online]. Available: https://arxiv.org/abs/1412.6980 (Cited on page: 3)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[51]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations, 2019. [Online]. Available: https://openreview.net/forum?id=Bkg6RiCqY7 (Cited on page: 3). 11 Play Like Champions: Counterfactual Feedback Generation in Latent SpaceA PREPRINT A StarCraft II Game Description Before diving deeper it ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.