SEFORA: Student Essays with Feedback Corpus and LLM Feedback Evaluation Framework
Pith reviewed 2026-07-02 18:45 UTC · model grok-4.3
The pith
LLMs match instructor feedback on student essays at no more than 0.4 F1 across 74 tests
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
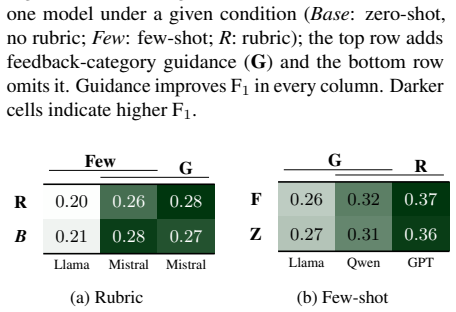
SEFORA supplies the first large public collection of authentic instructor inline feedback on multi-draft college writing together with prompts, rubrics, and scores, while UniMatch provides a reference-based metric that segments generated feedback, scores unit-level semantic correspondence against instructor-derived criteria, and applies optimal matching to produce interpretable F1 scores; experiments across LLMs show maximum performance of 0.4 F1, revealing systematic difficulty identifying prioritized feedback and degradation as models generate longer responses.
What carries the argument
UniMatch, a reference-based evaluation framework that segments feedback into units, scores their semantic correspondence under instructor-derived criteria, and aligns them via optimal matching to yield precision, recall, and F1
If this is right
- Current LLMs cannot yet produce feedback that aligns with instructor priorities at usable levels.
- Automated writing support at classroom scale will require new methods beyond existing generation approaches.
- Models need explicit training signals for identifying high-priority feedback points rather than maximizing volume.
- Performance limits appear tied to output length, implying constraints on how much feedback any single model response can reliably deliver.
- The SEFORA corpus now supplies a public benchmark for measuring future progress on instructor-aligned feedback generation.
Where Pith is reading between the lines
- The 0.4 F1 ceiling could serve as a practical threshold for deciding when human review remains necessary in deployed writing tools.
- UniMatch's matching procedure might be extended to other open-ended instructional tasks such as code review or lab report comments.
- If the gold-standard annotations prove stable across institutions, the corpus could support supervised fine-tuning experiments that target priority detection specifically.
- The observed length degradation suggests testing whether shorter, targeted prompts or multi-turn interaction improve alignment without increasing total output.
Load-bearing premise
The collected instructor annotations in SEFORA form a reliable gold standard for the feedback that should be given in actual classrooms.
What would settle it
An LLM configuration that achieves F1 above 0.4 on held-out SEFORA data under the same segmentation and matching procedure, or evidence that different instructors assign substantially different priority annotations to the same drafts.
Figures













read the original abstract
Effective writing feedback is among the strongest drivers of student learning, yet producing it at scale is labor-intensive. LLMs offer a natural path to scaling writing support, but two gaps stand in the way: few public corpora capture how instructors actually deliver feedback in real classrooms, and no reliable method measures whether generated feedback aligns with what an instructor would write. We address both. SEFORA is a public corpus pairing instructor inline feedback with assignment prompts, rubrics, scores, and multi-draft revisions across various college writing genres, comprising 564 drafts and 8,240 instructor annotations. UniMatch is a reference-based evaluation framework for open-ended generation: it segments feedback into feedback units, scores their semantic correspondence under instructor-derived criteria, and aligns them via optimal matching to yield interpretable precision, recall, and F1. Across 74 experimental configurations spanning multiple LLMs, no setting exceeds 0.4 F1. UniMatch reveals that models struggle to identify the feedback instructors would prioritize, and performance degrades as models generate more.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SEFORA, a corpus of 564 student drafts with 8,240 instructor feedback annotations across college writing genres, and UniMatch, a reference-based evaluation framework that segments feedback units, scores semantic correspondence under instructor-derived criteria, and applies optimal matching to compute precision, recall, and F1. Across 74 LLM configurations, no setting exceeds 0.4 F1; the framework is used to argue that models struggle to identify prioritized instructor feedback and that performance degrades with more generated feedback.
Significance. If the SEFORA annotations prove reliable and UniMatch tracks human judgments of alignment, the work supplies a public resource for studying real instructor feedback and demonstrates a concrete performance ceiling for current LLMs on this task, which could usefully direct research toward better alignment with instructor priorities. The public corpus itself is a clear asset for the community.
major comments (3)
- [Abstract / Corpus Construction] Abstract and Corpus Construction section: the description of the 8,240 annotations supplies no collection protocol details or inter-annotator agreement statistics, which are load-bearing for treating the annotations as a reliable gold standard against which the 0.4 F1 ceiling is measured.
- [UniMatch Framework] UniMatch Framework section: no validation study is reported that correlates UniMatch scores (segmentation + semantic scoring + optimal matching) with human judgments of feedback alignment, leaving open whether the low F1 values reflect model behavior or a mismatch in the evaluation procedure itself.
- [Results] Results section (74 configurations): the claim that no setting exceeds 0.4 F1 and that performance degrades with more generated feedback lacks reported statistical significance tests or confidence intervals, making it impossible to assess whether the ceiling is robust or an artifact of sampling.
minor comments (1)
- [UniMatch Framework] Notation for feedback units and matching criteria could be clarified with an explicit example in the UniMatch section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Corpus Construction] Abstract and Corpus Construction section: the description of the 8,240 annotations supplies no collection protocol details or inter-annotator agreement statistics, which are load-bearing for treating the annotations as a reliable gold standard against which the 0.4 F1 ceiling is measured.
Authors: We agree that additional protocol details are required. The revised Corpus Construction section will include a complete description of the data collection process, instructor recruitment, course contexts, assignment types, and annotation guidelines. Because each draft received feedback from only its own course instructor as part of normal teaching, multiple independent annotations per item do not exist and conventional IAA statistics cannot be computed. We will state this limitation explicitly and discuss its implications for the gold-standard status of the annotations. revision: yes
-
Referee: [UniMatch Framework] UniMatch Framework section: no validation study is reported that correlates UniMatch scores (segmentation + semantic scoring + optimal matching) with human judgments of feedback alignment, leaving open whether the low F1 values reflect model behavior or a mismatch in the evaluation procedure itself.
Authors: We recognize that an explicit correlation study between UniMatch scores and human alignment judgments would increase confidence in the metric. The present work prioritizes introducing the framework and applying it at scale; a dedicated validation study was outside the original scope. In revision we will expand the UniMatch section with a detailed rationale for each component (segmentation rules, instructor-derived semantic criteria, and optimal matching) and will add an explicit limitations paragraph noting the absence of direct human correlation data. A small-scale validation pilot could be added if the editor considers it essential for acceptance. revision: partial
-
Referee: [Results] Results section (74 configurations): the claim that no setting exceeds 0.4 F1 and that performance degrades with more generated feedback lacks reported statistical significance tests or confidence intervals, making it impossible to assess whether the ceiling is robust or an artifact of sampling.
Authors: We agree that statistical support is needed. The revised Results section will report 95% bootstrap confidence intervals around all F1 scores and will include appropriate non-parametric tests (e.g., Wilcoxon signed-rank with correction) to evaluate whether observed differences across the 74 configurations, including the degradation trend with feedback volume, are statistically significant. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's central results consist of F1 scores obtained by running UniMatch on LLM outputs against the externally collected SEFORA corpus of 8,240 instructor annotations. UniMatch performs segmentation, semantic scoring under instructor-derived criteria, and optimal matching to produce precision/recall/F1; these steps are defined procedurally and applied to independent human data rather than being fitted to or defined in terms of the target LLM performance. No equations, self-citations, or ansatzes are shown that would reduce the reported maximum F1 ≤ 0.4 to a tautology or fitted input. The evaluation chain remains externally anchored to the human-annotated benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Instructor annotations collected for SEFORA accurately reflect real classroom feedback priorities
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2006.14799 , year=
Evaluation of text generation: A survey.arXiv preprint arXiv:2006.14799. Tuhin Chakrabarty, Philippe Laban, Divyansh Agar- wal, Smaranda Muresan, and Chien-Sheng Wu. 2024. Art or artifice? large language models and the false promise of creativity. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1–34. Scott A Crossley,...
-
[2]
Building a large annotated corpus of learner english: The nus corpus of learner english. InPro- ceedings of the eighth workshop on innovative use of NLP for building educational applications, pages 22–31. Daniel Deutsch, Rotem Dror, and Dan Roth. 2022. On the limitations of reference-free evaluations of gen- erated text. InProceedings of the 2022 Conferen...
-
[3]
ACM Transactions on Computing Education (TOCE), 19(1):1–43
A systematic literature review of automated feedback generation for programming exercises. ACM Transactions on Computing Education (TOCE), 19(1):1–43. Avraham N Kluger and Angelo DeNisi. 1996. The effects of feedback interventions on performance: a historical review, a meta-analysis, and a preliminary feedback intervention theory.Psychological bulletin, 1...
1996
-
[4]
i really need feedback to learn:
Cityu corpus of essay drafts of english lan- guage learners: a corpus of textual revision in second language writing.Language Resources and Evalua- tion, 49(3):659–683. Jiaqi Li, Ming Liu, Bing Qin, and Ting Liu. 2022. A survey of discourse parsing.Frontiers of Computer Science, 16(5):165329. Jiwei Li, Rumeng Li, and Eduard Hovy. 2014. Recur- sive deep mo...
2022
-
[5]
How not to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 2122–2132. Xiaoqiang Luo. 2005. On coreference resolution perfor- mance metrics. InProceedings of human language technology confere...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
InProceedings of the 9th international workshop on semantic evaluation (SemEval 2015), pages 1–11
Semeval-2015 task 1: Paraphrase and seman- tic similarity in twitter (pit). InProceedings of the 9th international workshop on semantic evaluation (SemEval 2015), pages 1–11. Yu-Chun Grace Yen, Joy O Kim, and Brian P Bailey
2015
-
[7]
BERTScore: Evaluating Text Generation with BERT
Decipher: an interactive visualization tool for interpreting unstructured design feedback from multiple providers. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems, pages 1–13. Weizhe Yuan, Graham Neubig, and Pengfei Liu. 2021. Bartscore: Evaluating generated text as text gener- ation.Advances in neural information processing...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Extracts every character in the box
Body text extraction Deterministic. Extracts every character in the box
-
[9]
Highlight anchoring Quads → covered text → matched span; comment stored
-
[10]
Color recovery Local render→HEX→named color
-
[11]
Sticky-note anchoring Coordinate-radius context → located in body → injected
-
[12]
Paragraph structure Inferred from inter-block spacing (visual cues)
-
[13]
Semantic content of instructor feedback on a student-written paragraph:
Identifier removal Positional headers/footers; regex metadata; human- checked. Figure 9: Stages of the deterministic PDF parsing pipeline (§A.3). Each annotated submission is converted to a unified JSON representation preserving paragraph segmentation and annotation anchoring. C Feedback Unit Similarity Pipeline C.1 Automatic similarity metrics. In our ex...
2002
-
[14]
Consider varying your transitions between sentences (e.g., instead of using “and”, try using words like however, meanwhile, etc.)$
-
[15]
newly waxed floors
What does the phrase “newly waxed floors” mean? Is it necessary to describe the floor in such detail?$ Sample 3: Your vivid descriptions set the stage beautifully. Keep focusing on using sensory details to engage readers further.$ Great job showing how the simple drill captured your interest. Consider expanding on why it resonated with you specifically.$ ...
2025
-
[16]
Identify the SINGLE most important feedback focus in the TARGET PARAGRAPH
-
[17]
Determine which ONE feedback category best matches that focus
-
[18]
### Feedback Categories ### Choose exactly ONE category based on the feedback focus you identify
Write ONE short piece of constructive feedback that reflects that focus. ### Feedback Categories ### Choose exactly ONE category based on the feedback focus you identify. - Task Constraints: Feedback about how the writing aligns with the assignment or rubric. - Concepts: Feedback that supports understanding or development of a key concept. - Elaboration: ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.