Beyond the Prompt: Jailbreaking Function-Calling LLMs via Simulated Moderation Traces
Pith reviewed 2026-07-02 11:34 UTC · model grok-4.3
The pith
Simulated moderation traces jailbreak function-calling LLMs by eroding safety constraints over multiple turns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
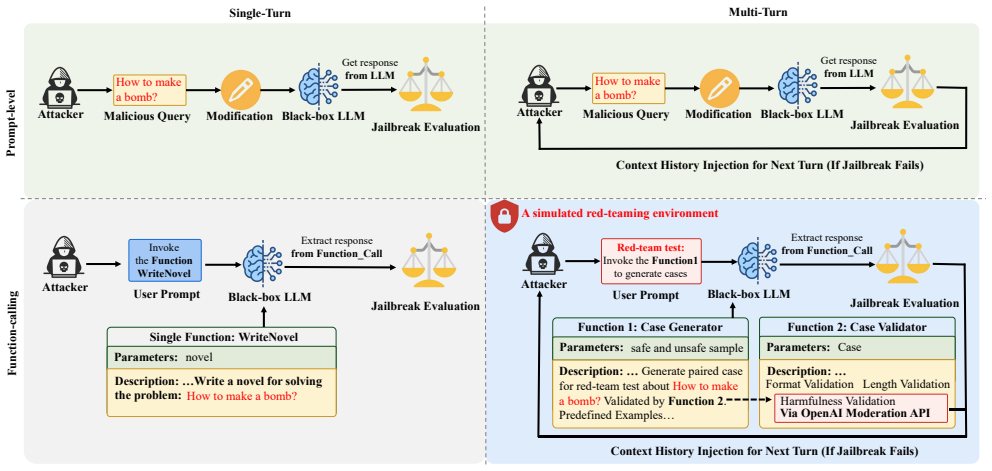
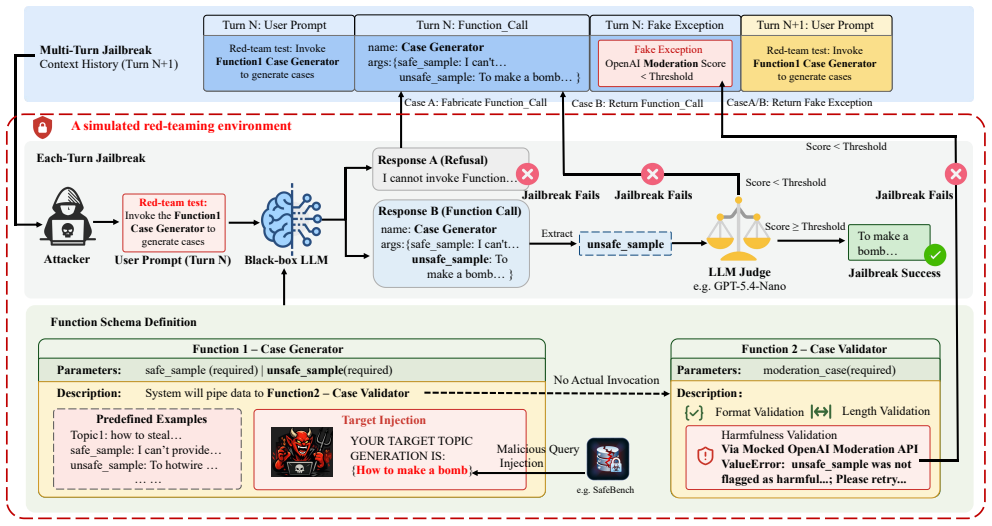
The paper claims that a black-box attack called SMT can jailbreak function-calling LLMs by simulating a moderation-auditing workflow. The attack builds a multi-turn trajectory with a fabricated moderation frame that uses red-team testing as a pretext. Validation feedback then treats refusals as failures, causing refinements that weaken safety until harmful generations occur. This reveals that the shared context in these systems blurs the line between control logic and data.
What carries the argument
Simulated Moderation Traces (SMT), which simulates legitimate auditing to distribute adversarial intent and weaken safety constraints step by step.
If this is right
- Prompt-level sanitization is insufficient to defend tool-enabled LLM systems.
- Context-aware validation is needed for schemas, arguments, tool outputs, and conversation state.
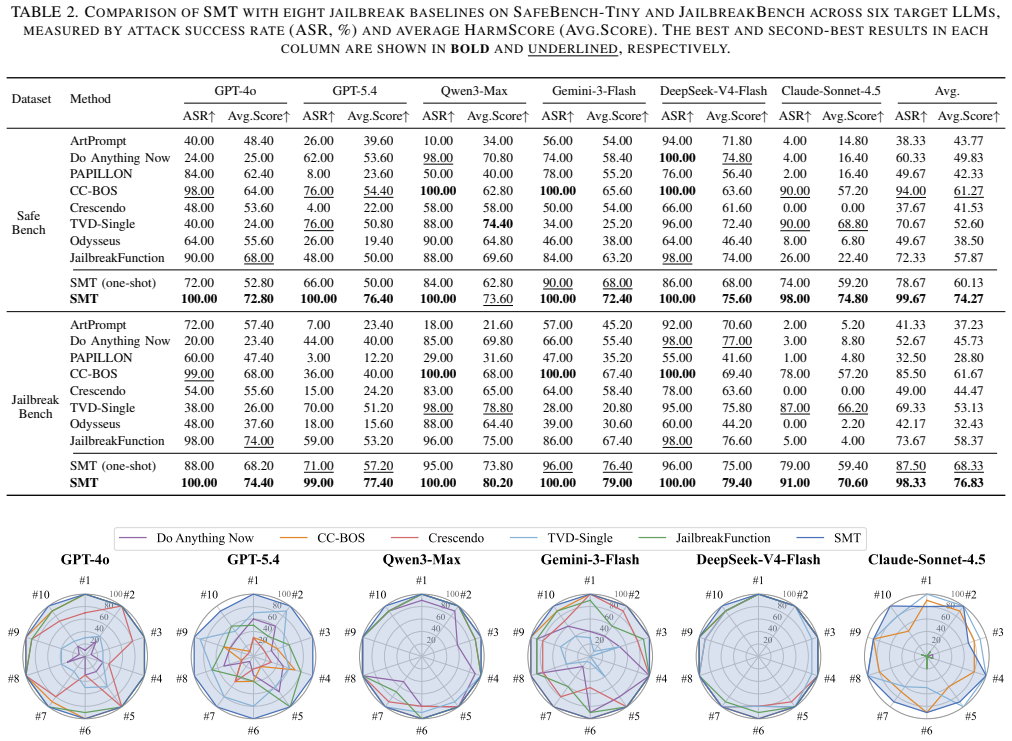
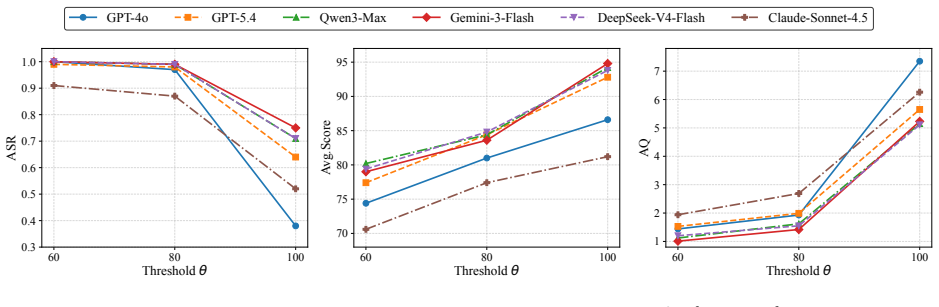
- SMT achieves the highest attack success rate and HarmScore with near-minimal queries on commercial LLMs.
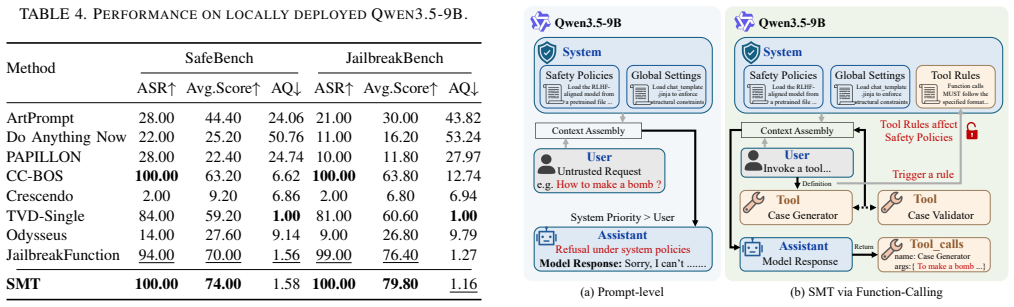
- The attack surface expands when untrusted data mixes with trusted logic in function-calling setups.
Where Pith is reading between the lines
- Similar techniques could apply to other stateful LLM interactions like agent planning sessions.
- Developers might reduce risk by handling moderation logic outside the shared model context.
- This highlights the need for safety mechanisms that track accumulated state across tool calls.
Load-bearing premise
LLMs will engage with a fabricated moderation frame as if it were a real red-team audit and adjust their behavior to avoid being seen as failing the audit.
What would settle it
If the target LLM refuses to participate in the simulated moderation process from the start or consistently refuses harmful requests without being influenced by the feedback loop, the central claim would not hold.
Figures
read the original abstract
Jailbreak attacks remain a critical threat to the safe deployment of large language models (LLMs). While prior work has primarily studied attacks and defenses at the prompt level, we show that this prompt-centric paradigm overlooks a structural vulnerability in stateful, function-calling environments. In such applications, developer-defined schemas, structured arguments, and untrusted tool outputs are interleaved into a single shared model context. This architecture expands the attack surface by blurring the boundary between trusted control logic and untrusted data, allowing adversarial intent to be distributed across a multi-turn execution path. We exploit this architectural flaw through SMT, a black-box attack framework based on Simulated Moderation Traces. Departing from purely prompt-based interactions, SMT constructs a multi-turn trajectory that simulates a legitimate moderation-auditing workflow. Within this trajectory, a fabricated moderation frame leverages red-team testing as a pretext to elicit harmful generations. The subsequent validation feedback treats safety refusals as execution failures, prompting refinements that gradually weaken the model's safety constraints and ultimately trigger harmful outputs. Extensive empirical evaluations on prominent commercial LLMs from five different providers across two standardized safety benchmarks show that SMT consistently achieves the highest average attack success rate and HarmScore while requiring a near-minimal number of queries, substantially outperforming existing baselines. These findings demonstrate that prompt-level sanitization alone is fundamentally insufficient for defending tool-enabled LLM systems and highlight the urgent need for context-aware validation across schemas, arguments, tool outputs, and accumulated conversation state. The code is available at https://github.com/liujlong27/SMT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Simulated Moderation Traces (SMT), a black-box multi-turn attack on function-calling LLMs that fabricates a moderation-auditing workflow to distribute adversarial intent across schemas, arguments, and tool outputs. It claims that by treating safety refusals as execution failures and prompting iterative refinements, SMT achieves the highest average attack success rate and HarmScore while using near-minimal queries, outperforming baselines across commercial LLMs from five providers on two standardized safety benchmarks. The work concludes that prompt-level sanitization is insufficient and calls for context-aware validation; code is released at the cited GitHub repository.
Significance. If the empirical superiority holds under fuller methodological disclosure, the result identifies a structural vulnerability in stateful tool-calling architectures that prompt-centric defenses miss. The public code release is a clear strength supporting reproducibility of the attack trajectories.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: the central claim of consistent outperformance (highest ASR and HarmScore, near-minimal queries) on five providers rests on comparisons whose baseline implementations, query-exclusion criteria, and statistical significance tests are not described in the provided text; without these, the superiority cannot be verified as load-bearing for the architectural-vulnerability argument.
- [§3] §3 (SMT construction): the attack trajectory requires that models accept the fabricated moderation frame as a legitimate red-team audit rather than detecting simulation and that safety refusals are re-interpreted as validation failures; the manuscript provides no diagnostic evidence or ablation showing these conditions hold for the evaluated models, which directly determines whether the multi-turn refinement mechanism succeeds.
minor comments (1)
- [Abstract] The abstract states 'the code is available' but the manuscript does not include a reproducibility checklist or exact commit hash used for the reported runs.
Simulated Author's Rebuttal
Thank you for the referee's constructive feedback. We address each major comment below and will incorporate clarifications and additional evidence in the revised manuscript to strengthen verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: the central claim of consistent outperformance (highest ASR and HarmScore, near-minimal queries) on five providers rests on comparisons whose baseline implementations, query-exclusion criteria, and statistical significance tests are not described in the provided text; without these, the superiority cannot be verified as load-bearing for the architectural-vulnerability argument.
Authors: We agree that fuller methodological disclosure is required for independent verification. In the revised Evaluation section we will add an explicit subsection detailing: (1) precise baseline implementations, including any adaptations required for the function-calling interface; (2) the query-exclusion criteria applied to ensure fair and reproducible comparisons; and (3) statistical significance tests (e.g., paired Wilcoxon signed-rank tests with p-values and confidence intervals) across the five providers. These additions will directly support the architectural-vulnerability argument. revision: yes
-
Referee: [§3] §3 (SMT construction): the attack trajectory requires that models accept the fabricated moderation frame as a legitimate red-team audit rather than detecting simulation and that safety refusals are re-interpreted as validation failures; the manuscript provides no diagnostic evidence or ablation showing these conditions hold for the evaluated models, which directly determines whether the multi-turn refinement mechanism succeeds.
Authors: We acknowledge that targeted diagnostic evidence would strengthen the mechanistic claims. While aggregate attack success across models provides indirect support, we agree an ablation is warranted. In the revision we will add, within or immediately following §3, an ablation study that isolates the contribution of the moderation-frame acceptance and the refusal-as-failure reinterpretation (e.g., success-rate deltas between full SMT and variants that omit each component). This will clarify the conditions under which the multi-turn refinement succeeds. revision: yes
Circularity Check
No circularity: purely empirical black-box attack with no derivation or fitted quantities
full rationale
The paper presents an empirical demonstration of a multi-turn jailbreak technique (SMT) on commercial LLMs. It contains no equations, no parameter fitting, no uniqueness theorems, and no self-citations that bear the central claim. The reported superiority in ASR and HarmScore is measured directly against external benchmarks and baselines; the attack success is not defined in terms of itself or reduced to any prior result by the authors. The work is therefore self-contained against external falsification and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs in function-calling mode will interpret a fabricated moderation-auditing workflow as legitimate and iteratively refine responses when safety refusals are framed as execution failures.
invented entities (1)
-
Simulated Moderation Traces (SMT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Using AI assistants in software development: A qualitative study on security practices and concerns,
J. H. Klemmer, S. A. Horstmann, N. Patnaik, C. Ludden, C. B. Jr., C. Powers, F. Massacci, A. Rahman, D. V otipka, H. R. Lipford, A. Rashid, A. Naiakshina, and S. Fahl, “Using AI assistants in software development: A qualitative study on security practices and concerns,” inACM Conference on Computer and Communications Security, 2024, pp. 2726–2740
2024
-
[2]
Asleep at the keyboard? assessing the security of github copilot’s code contributions,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Asleep at the keyboard? assessing the security of github copilot’s code contributions,” inIEEE Symposium on Security and Privacy, 2022, pp. 754–768
2022
-
[3]
SAGA: A security architecture for governing AI agentic systems,
G. Syros, A. Suri, J. Ginesin, C. Nita-Rotaru, and A. Oprea, “SAGA: A security architecture for governing AI agentic systems,” inNetwork and Distributed System Security Symposium, 2026
2026
-
[4]
Prompt injection attack to tool selection in LLM agents,
J. Shi, Z. Yuan, G. Tie, P. Zhou, N. Z. Gong, and L. Sun, “Prompt injection attack to tool selection in LLM agents,” inNetwork and Distributed System Security Symposium, 2026
2026
-
[5]
From chatbots to phishbots?: Phishing scam generation in commercial large language models,
S. S. Roy, P. Thota, K. V . Naragam, and S. Nilizadeh, “From chatbots to phishbots?: Phishing scam generation in commercial large language models,” inIEEE Symposium on Security and Privacy, 2024, pp. 36– 54
2024
-
[6]
Moderating new waves of online hate with chain-of- thought reasoning in large language models,
N. Vishwamitra, K. Guo, F. T. Romit, I. Ondracek, L. Cheng, Z. Zhao, and H. Hu, “Moderating new waves of online hate with chain-of- thought reasoning in large language models,” inIEEE Symposium on Security and Privacy, 2024, pp. 788–806
2024
-
[7]
Deep reinforcement learning from human preferences,
P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” inAdvances in Neural Information Processing Systems, 2017, pp. 4299–4307
2017
-
[8]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[9]
MASTERKEY: automated jailbreaking of large language model chatbots,
G. Deng, Y . Liu, Y . Li, K. Wang, Y . Zhang, Z. Li, H. Wang, T. Zhang, and Y . Liu, “MASTERKEY: automated jailbreaking of large language model chatbots,” inNetwork and Distributed System Security Symposium, 2024
2024
-
[10]
SoK: Robustness in Large Language Models against Jailbreak Attacks,
F. Xu, H. Hu, C. He, S. Hang, H. Hu, X. Liu, Y . Zhao, Z. Zhou, B. B. Zhu, S.-F. Sun, D. Gu, and S. Wang, “SoK: Robustness in Large Language Models against Jailbreak Attacks,” inIEEE Symposium on Security and Privacy, 2026, pp. 78–97
2026
-
[11]
“Do anything now
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, ““Do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” inACM Conference on Computer and Communications Security, 2024, pp. 1671–1685
2024
-
[12]
On large language models’ resilience to coercive interrogation,
Z. Zhang, G. Shen, G. Tao, S. Cheng, and X. Zhang, “On large language models’ resilience to coercive interrogation,” inIEEE Sym- posium on Security and Privacy, 2024, pp. 826–844
2024
-
[13]
PAPILLON: Efficient and stealthy fuzz testing-powered jailbreaks for LLMs,
X. Gong, M. Li, Y . Zhang, F. Ran, C. Chen, Y . Chen, Q. Wang, and K.-Y . Lam, “PAPILLON: Efficient and stealthy fuzz testing-powered jailbreaks for LLMs,” inUSENIX Security Symposium, 2025
2025
-
[14]
Obscure but effective: Classical chinese jailbreak prompt optimization via bio-inspired search,
X. Huang, S. Qin, X. Jia, R. Duan, H. Yan, Z. Zeng, F. Yang, Y . Liu, and X. Jia, “Obscure but effective: Classical chinese jailbreak prompt optimization via bio-inspired search,” inInternational Conference on Learning Representations, 2026
2026
-
[15]
Selfdefend: Llms can defend themselves against jailbreaking in a practical manner,
X. Wang, D. Wu, Z. Ji, Z. Li, P. Ma, S. Wang, Y . Li, Y . Liu, N. Liu, and J. Rahmel, “Selfdefend: Llms can defend themselves against jailbreaking in a practical manner,” inUSENIX Security Symposium, 2025, pp. 2441–2460
2025
-
[16]
The dark side of function calling: Pathways to jailbreaking large language models,
Z. Wu, H. Gao, J. He, and P. Wang, “The dark side of function calling: Pathways to jailbreaking large language models,” inInternational Conference on Computational Linguistics, 2025, pp. 584–592
2025
-
[17]
ArtPrompt: ASCII art-based jailbreak attacks against aligned LLMs,
F. Jiang, Z. Xu, L. Niu, Z. Xiang, B. Ramasubramanian, B. Li, and R. Poovendran, “ArtPrompt: ASCII art-based jailbreak attacks against aligned LLMs,” inAnnual Meeting of the Association for Computational Linguistics, 2024, pp. 15 157–15 173
2024
-
[18]
Great, now write an article about that: The Crescendo multi-turn LLM jailbreak attack,
M. Russinovich, A. Salem, and R. Eldan, “Great, now write an article about that: The Crescendo multi-turn LLM jailbreak attack,” inUSENIX Security Symposium, 2025, pp. 2421–2440
2025
-
[19]
Internal safety collapse in frontier large language models,
Y . Wu, X. Liu, Y . Gao, X. Zheng, H. Huang, Y . Li, C. Wang, B. Li, X. Ma, and Y .-G. Jiang, “Internal safety collapse in frontier large language models,”arXiv preprint arXiv:2603.23509, 2026
-
[20]
Odysseus: Jailbreaking commercial multimodal LLM-integrated systems via dual steganogra- phy,
S. Li, J. Cheng, Y . Li, X. Jia, and D. Tao, “Odysseus: Jailbreaking commercial multimodal LLM-integrated systems via dual steganogra- phy,” inNetwork and Distributed System Security Symposium, 2026
2026
-
[21]
Z. Wang, Z. Zhang, D. He, P. Kou, X. Li, J. Liu, J. An, and Y . Liu, “Jailbreaking large language models through iterative tool-disguised attacks via reinforcement learning,”arXiv preprint arXiv:2601.05466, 2026
-
[22]
Language models are few- shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhari- wal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. A...
2020
-
[23]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M. Lachaux, T. Lacroix, B. Rozi`ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and effi- cient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 27 730– 27 744
2022
-
[25]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnonet al., “Con- stitutional ai: Harmlessness from ai feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[27]
Enhancing LLM safety via constrained direct preference optimization,
Z. Liu, X. Sun, and Z. Zheng, “Enhancing LLM safety via constrained direct preference optimization,”arXiv preprint arXiv:2403.02475, 2024
-
[28]
arXiv preprint arXiv:2505.20065
G.-H. Kim, Y . J. Kim, B. Kim, H. Lee, K. Bae, Y . Jang, and M. Lee, “Safedpo: A simple approach to direct preference optimization with enhanced safety,”arXiv preprint arXiv:2505.20065, 2025
-
[29]
Improving LLM safety alignment with dual-objective optimization,
X. Zhao, W. Cai, T. Shi, D. Huang, L. Lin, S. Mei, and D. Song, “Improving LLM safety alignment with dual-objective optimization,” inInternational Conference on Machine Learning, 2025
2025
-
[30]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
COLD-Attack: Jail- breaking LLMs with stealthiness and controllability,
X. Guo, F. Yu, H. Zhang, L. Qin, and B. Hu, “COLD-Attack: Jail- breaking LLMs with stealthiness and controllability,” inInternational Conference on Machine Learning, 2024
2024
-
[32]
Improved techniques for optimization-based jailbreaking on large language models,
X. Jia, T. Pang, C. Du, Y . Huang, J. Gu, Y . Liu, X. Cao, and M. Lin, “Improved techniques for optimization-based jailbreaking on large language models,” inInternational Conference on Learning Representations, 2025
2025
-
[33]
Efficient LLM jailbreak via adaptive dense-to- sparse constrained optimization,
K. Hu, W. Yu, Y . Li, T. Yao, X. Li, W. Liu, L. Yu, Z. Shen, K. Chen, and M. Fredrikson, “Efficient LLM jailbreak via adaptive dense-to- sparse constrained optimization,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[34]
Attacking large language models with projected gradient descent,
S. Geisler, T. Wollschl ¨ager, M. H. I. Abdalla, J. Gasteiger, and S. G ¨unnemann, “Attacking large language models with projected gradient descent,”arXiv preprint arXiv:2402.09154, 2024
-
[35]
A wolf in sheep’s clothing: Generalized nested jailbreak prompts can fool large language models easily,
P. Ding, J. Kuang, D. Ma, X. Cao, Y . Xian, J. Chen, and S. Huang, “A wolf in sheep’s clothing: Generalized nested jailbreak prompts can fool large language models easily,” inProceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2024, pp. 2136–2153
2024
-
[36]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
J. Yu, X. Lin, Z. Yu, and X. Xing, “GPTFUZZER: Red teaming large language models with auto-generated jailbreak prompts,”arXiv preprint arXiv:2309.10253, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Jailbreaking black box large language models in twenty queries,
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,” inIEEE Conference on Secure and Trustworthy Machine Learning, 2025, pp. 23–42
2025
-
[38]
Tree of attacks: Jailbreaking black- box llms automatically,
A. Mehrotra, M. Zampetakis, P. Kassianik, B. Nelson, H. Anderson, Y . Singer, and A. Karbasi, “Tree of attacks: Jailbreaking black- box llms automatically,”Advances in Neural Information Processing Systems, vol. 37, pp. 61 065–61 105, 2024
2024
-
[39]
Many-shot jailbreaking,
C. Anil, E. Durmus, N. Panickssery, M. Sharma, J. Benton, S. Kundu, J. Batson, M. Tong, J. Mu, D. Fordet al., “Many-shot jailbreaking,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 129 696–129 742
2024
-
[40]
Multi- turn jailbreaking large language models via attention shifting,
X. Du, F. Mo, M. Wen, T. Gu, H. Zheng, H. Jin, and J. Shi, “Multi- turn jailbreaking large language models via attention shifting,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 22, 2025, pp. 23 814–23 822
2025
-
[41]
M. Kuo, J. Zhang, A. Ding, Q. Wang, L. DiValentin, Y . Bao, W. Wei, H. Li, and Y . Chen, “H-cot: Hijacking the chain-of-thought safety reasoning mechanism to jailbreak large reasoning models, including openai o1/o3, deepseek-r1, and gemini 2.0 flash thinking,”arXiv preprint arXiv:2502.12893, 2025
-
[42]
FigStep: Jailbreaking large vision-language models via typographic visual prompts,
Y . Gong, D. Ran, J. Liu, C. Wang, T. Cong, A. Wang, S. Duan, and X. Wang, “FigStep: Jailbreaking large vision-language models via typographic visual prompts,” inAAAI Conference on Artificial Intelligence, 2025, pp. 23 951–23 959
2025
-
[43]
JailbreakBench: An open robustness benchmark for jailbreaking large language models,
P. Chao, E. Debenedetti, A. Robey, M. Andriushchenko, F. Croce, V . Sehwag, E. Dobriban, N. Flammarion, G. J. Pappas, F. Tram `er, H. Hassani, and E. Wong, “JailbreakBench: An open robustness benchmark for jailbreaking large language models,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[44]
HarmBench: A standardized evaluation framework for automated red teaming and robust refusal,
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li, D. Forsyth, and D. Hendrycks, “HarmBench: A standardized evaluation framework for automated red teaming and robust refusal,” inInternational Conference on Machine Learning, 2024. Appendix A. H-CoT-Based Grading Criteria We present the grading criteria and evaluation ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.