Phantom References: Hallucinated Citations That Survive Peer Review at Top-Tier Conferences
Pith reviewed 2026-07-02 01:58 UTC · model grok-4.3
The pith
Peer review at top conferences lets hallucinated citations enter the record at rates of one in twenty papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
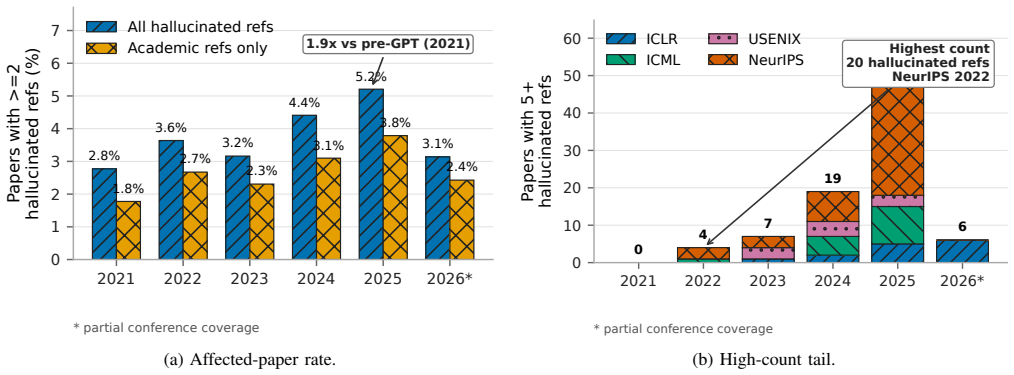
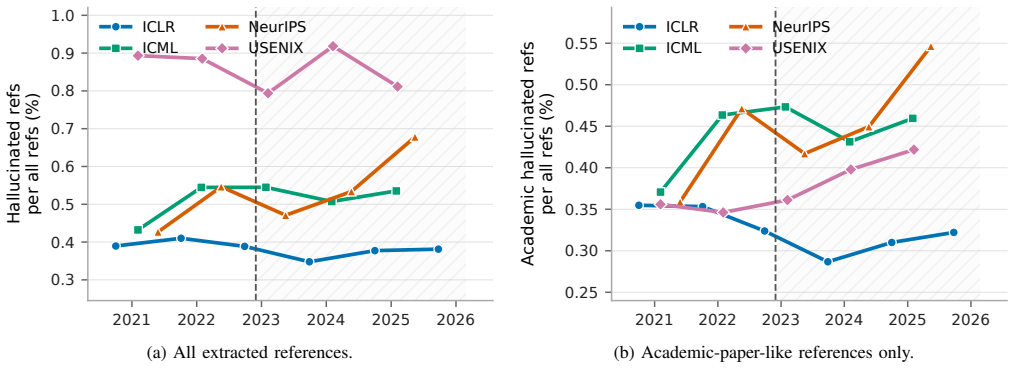
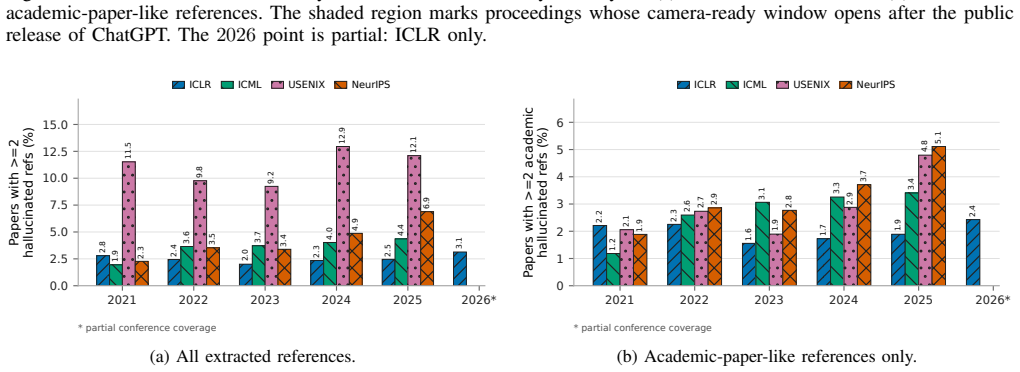
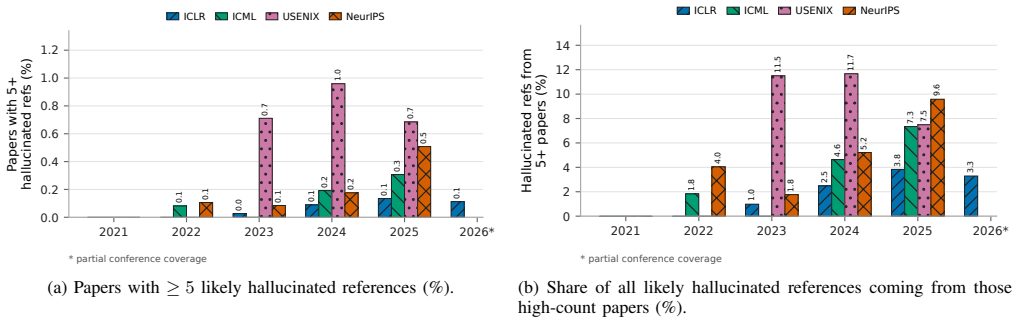
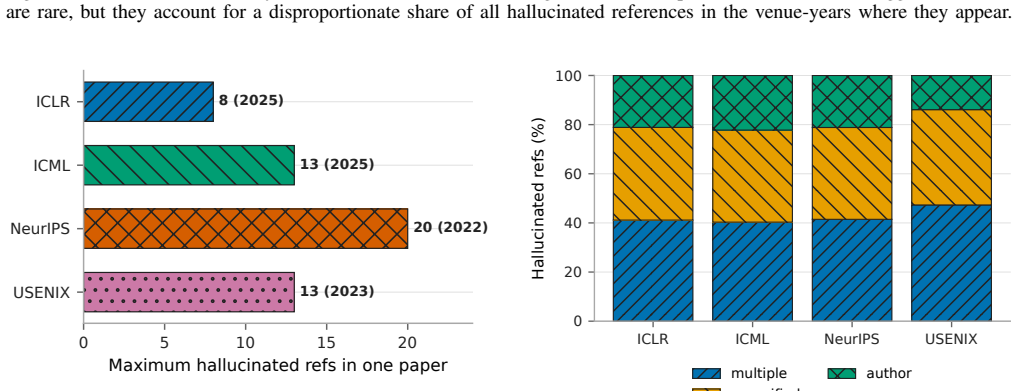
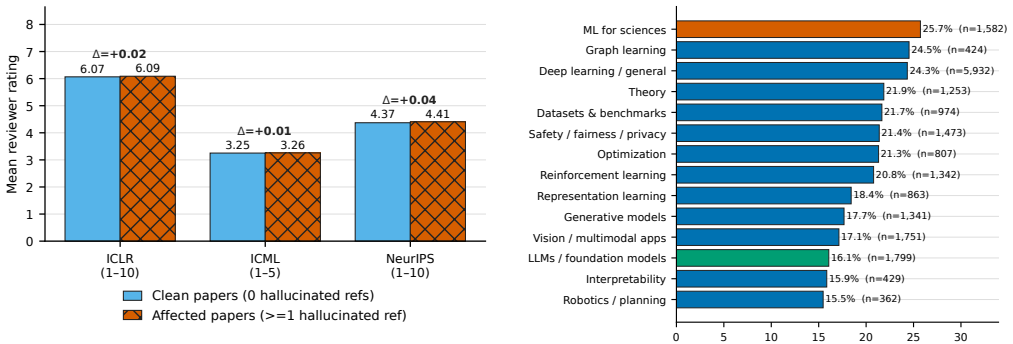
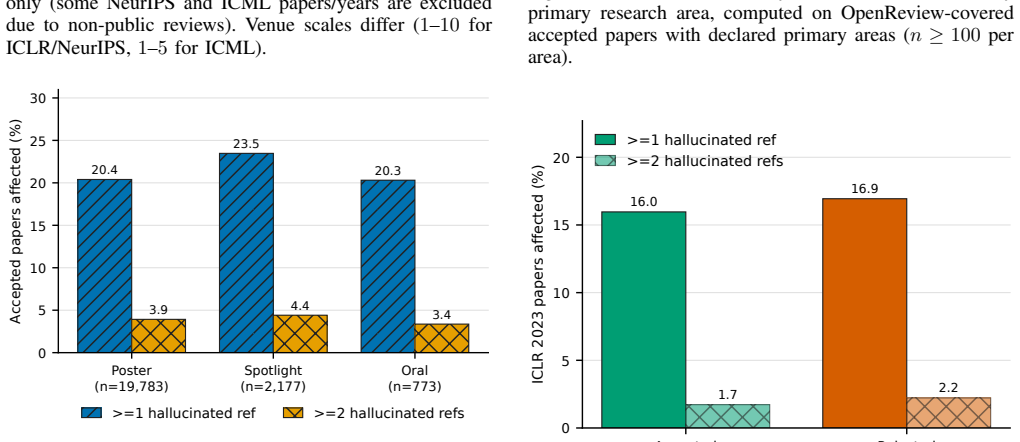
Hallucinated citations have entered the archival record. While reference-level rates are usually below 1%, proceedings are large enough that paper-level failures are visible: in 2025, roughly one in twenty NeurIPS and USENIX Security papers contains at least two likely hallucinated academic-paper-like references under our strict definition limited to non-existent works and substantial author-list mismatches. Post-ChatGPT increases appear in several venues, including papers with five or more failures in one bibliography and cases even among award-winning papers.
What carries the argument
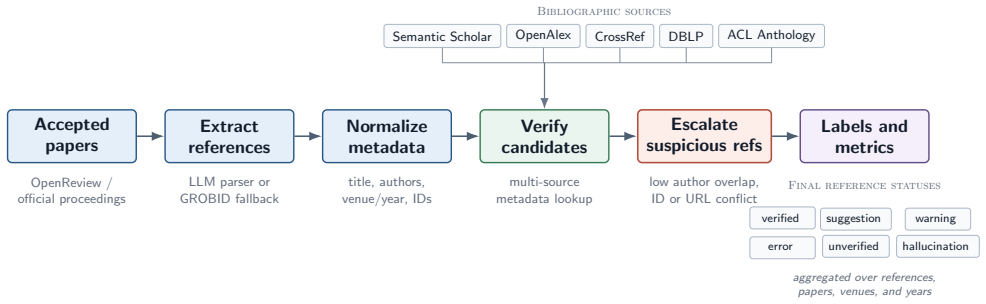
RefChecker, a verification pipeline that resolves bibliography entries against multiple bibliographic sources and escalates unresolved cases to web-search re-verification.
If this is right
- Post-ChatGPT increases in hallucinated citations appear across several venues.
- A visible tail of papers contains five or more hallucinated references within a single bibliography.
- Even award-winning papers contain likely hallucinated citations.
- Citation auditing at scale remains inexpensive at roughly four cents per paper.
Where Pith is reading between the lines
- Conferences could require automated citation scans as part of the camera-ready submission workflow.
- Persistent phantom references may gradually degrade the reliability of citation networks used for literature search and impact measurement.
- The same verification approach could be applied to journal articles and preprints outside the four venues studied here.
Load-bearing premise
RefChecker's combination of multi-source lookup and web-search escalation flags only genuine non-existent works or major author mismatches without systematic false positives caused by database gaps or name variants.
What would settle it
A complete manual check of every reference flagged by RefChecker that finds all of them actually exist with matching author lists would show the reported hallucination rates are artifacts of the tool rather than real errors in the papers.
Figures

read the original abstract
Large language models can generate polished scientific text that includes unsupported claims, allowing hallucinations to enter the archival record. Assessing this risk via technical statements is difficult and often requires expert judgment, but citations provide a more auditable surface: a reference either resolves to a real scholarly work with compatible authorship, or it does not. We measure citation hallucination in peer-reviewed proceedings using a conservative definition limited to identity-level failures: non-existent works and substantial author-list mismatches. We explicitly exclude ordinary bibliographic drift (e.g., venue/year differences, publication-status updates, minor name variants). To audit citations at scale, we build RefChecker, a verification pipeline that resolves bibliography entries against multiple bibliographic sources and escalates unresolved cases to web-search re-verification. We apply RefChecker to accepted camera-ready papers from ICLR, ICML, NeurIPS, and USENIX Security. Hallucinated citations have entered the archival record. While reference-level rates are usually below 1%, proceedings are large enough that paper-level failures are visible: in 2025, roughly one in twenty NeurIPS and USENIX Security papers contains at least two likely hallucinated academic-paper-like references under our strict definition. We also observe post-ChatGPT increases in several venues, including a tail of papers with 5+ failures in a single bibliography, and likely hallucinated citations even among award-winning papers. These results suggest peer review alone does not reliably enforce citation integrity, yet auditing is tractable (about 0.04$ per paper in one venue-scale scan). We open-source RefChecker for routine, reproducible citation verification before publication (https://github.com/markrussinovich/refchecker).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical measurement of citation hallucinations in peer-reviewed conference papers, using a conservative definition restricted to non-existent works and major author-list mismatches. It introduces RefChecker, a multi-source bibliographic resolution pipeline with web-search escalation, applies it to camera-ready papers from ICLR, ICML, NeurIPS, and USENIX Security, and finds reference-level rates typically below 1% but paper-level rates in which roughly one in twenty NeurIPS and USENIX Security papers contain at least two hallucinated references in 2025, with post-ChatGPT increases and occurrences even in award-winning papers. The tool is released open-source.
Significance. If the reported rates are accurate, the work provides concrete evidence that citation hallucinations have entered the archival record at top venues and that peer review alone does not reliably prevent them. The conservative definition, multi-source verification approach, low per-paper cost, and open-sourcing of RefChecker are explicit strengths that support reproducibility and routine pre-publication checks.
major comments (2)
- [RefChecker pipeline description] Section describing RefChecker (methods): the central paper-level claim (one in twenty NeurIPS/USENIX papers contain ≥2 hallucinated references) rests on the assumption that the multi-source + web-search pipeline produces negligible false positives from database gaps or name variants, yet no precision/recall figures, inter-annotator agreement on a validation set, or manual audit of flagged cases are reported. This directly affects the reliability of both reference-level and paper-level statistics.
- [Results on temporal trends] Results section on temporal trends: the reported post-ChatGPT increases and the tail of papers with 5+ failures are presented without specifying the exact year cutoffs, sample sizes per year, or any statistical test for the change; this weakens the strength of the trend claim relative to the headline rate.
minor comments (2)
- [Abstract] The abstract states the 1-in-20 figure for NeurIPS and USENIX Security but does not clarify whether the same rate holds for ICLR and ICML or why those venues are omitted from the headline statistic.
- [Conclusion / availability statement] The open-source repository link is given, but the manuscript does not include a brief reproducibility note on how to run the pipeline on a new bibliography.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [RefChecker pipeline description] Section describing RefChecker (methods): the central paper-level claim (one in twenty NeurIPS/USENIX papers contain ≥2 hallucinated references) rests on the assumption that the multi-source + web-search pipeline produces negligible false positives from database gaps or name variants, yet no precision/recall figures, inter-annotator agreement on a validation set, or manual audit of flagged cases are reported. This directly affects the reliability of both reference-level and paper-level statistics.
Authors: We agree that the absence of formal validation metrics limits the strength of the reliability claims. Although the pipeline employs conservative multi-source resolution followed by web-search escalation specifically to reduce false positives from gaps or variants, the manuscript does not report precision/recall or inter-annotator agreement. We will add a dedicated validation subsection reporting results from a manual audit of a random sample of flagged references (including precision estimates and agreement between two independent annotators). revision: yes
-
Referee: [Results on temporal trends] Results section on temporal trends: the reported post-ChatGPT increases and the tail of papers with 5+ failures are presented without specifying the exact year cutoffs, sample sizes per year, or any statistical test for the change; this weakens the strength of the trend claim relative to the headline rate.
Authors: We concur that the temporal trends section requires additional detail to support the claims. The current text does not specify exact year boundaries, per-year sample sizes, or statistical tests. In revision we will define the pre-/post-ChatGPT split explicitly (e.g., 2022 and earlier versus 2023–2025), report venue-specific sample sizes for each year, and include appropriate statistical tests (e.g., chi-squared or Fisher’s exact) for the observed increases. revision: yes
Circularity Check
Pure empirical measurement study; no derivations or self-referential predictions
full rationale
The paper measures hallucinated citations via direct application of RefChecker to external bibliographic databases and web search on accepted papers from ICLR/ICML/NeurIPS/USENIX. No equations, fitted parameters, predictions of related quantities, or load-bearing self-citations appear in the derivation chain. Central claims rest on counts from independent sources, not on any reduction to the paper's own inputs or prior author work. This is the expected non-finding for a measurement study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bibliographic databases and web search provide reliable ground truth for existence and authorship of scholarly works.
Reference graph
Works this paper leans on
-
[1]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Comput. Surv., vol. 55, no. 12, Mar
-
[2]
Available: https://doi.org/10.1145/3571730
[Online]. Available: https://doi.org/10.1145/3571730
-
[3]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Trans. Inf. Syst., vol. 43, no. 2, Jan. 2025. [Online]. Available: https://doi.org/10.1145/3703155
-
[4]
Siren’s song in the AI ocean: A survey on hallucination in large language models,
Y . Zhang, Y . Li, L. Cui, D. Cai, L. Liu, T. Fu, X. Huang, E. Zhao, Y . Zhang, Y . Chen, L. Wang, A. T. Luu, W. Bi, F. Shi, and S. Shi, “Siren’s song in the AI ocean: A survey on hallucination in large language models,”Computational Linguistics, vol. 51, no. 4, pp. 1373–1418, Dec. 2025. [Online]. Available: https://aclanthology.org/2025.cl-4.9/
2025
-
[5]
Mata v. Avianca, Inc., no. 1:22-cv-01461 (PKC),
United States District Court, Southern District of New York, “Mata v. Avianca, Inc., no. 1:22-cv-01461 (PKC),” 2023
2023
-
[6]
We have a package for you! a comprehensive analysis of package hallucinations by code generating llms,
J. Spracklen, R. Wijewickrama, A. N. Sakib, A. Maiti, B. Viswanath, and M. Jadliwala, “We have a package for you! a comprehensive analysis of package hallucinations by code generating llms,” inPro- ceedings of the 34th USENIX Conference on Security Symposium, ser. SEC ’25. USA: USENIX Association, 2025
2025
-
[7]
Mapping the increasing use of llms in scientific papers,
W. Liang, Y . Zhang, Z. Wu, H. Lepp, W. Ji, X. Zhao, H. Cao, S. Liu, S. He, Z. Huang, D. Yang, C. Potts, C. D. Manning, and J. Y . Zou, “Mapping the increasing use of llms in scientific papers,”
-
[8]
Available: https://arxiv.org/abs/2404.01268
[Online]. Available: https://arxiv.org/abs/2404.01268
-
[9]
Fabrication and errors in the bibliographic citations generated by chatgpt,
W. Walters and E. Wilder, “Fabrication and errors in the bibliographic citations generated by chatgpt,”Scientific Reports, vol. 13, p. article 14045, 09 2023
2023
-
[10]
BibTeX Citation Hallucinations in Scientific Publishing Agents: Evaluation and Mitigation
D. Rao and C. Callison-Burch, “Bibtex citation hallucinations in scientific publishing agents: Evaluation and mitigation,” 2026. [Online]. Available: https://arxiv.org/abs/2604.03159
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
ICLR 2026 response to LLM- generated papers and reviews,
ICLR 2026 Program Chairs, “ICLR 2026 response to LLM- generated papers and reviews,” https://blog.iclr.cc/2025/11/19/ iclr-2026-response-to-llm-generated-papers-and-reviews/, Nov. 2025, iCLR Blog; accessed 2026-06-12
2026
-
[12]
ICML 2026 peer review ethics,
ICML 2026 Program Chairs, “ICML 2026 peer review ethics,” https:// icml.cc/Conferences/2026/PeerReviewEthics, 2026, revised 2026-01- 24; accessed 2026-06-12
2026
-
[13]
GPTZero finds over 50 new hallucinations in ICLR 2026 submissions,
P. Esau, N. Shmatko, A. Adam, and A. Cui, “GPTZero finds over 50 new hallucinations in ICLR 2026 submissions,” https://gptzero.me/ news/iclr-2026/, Dec. 2025
2026
-
[14]
LLM hallucinations in the wild: Large-scale evidence from non-existent citations
Z. Zhao, Y . Wang, T. Stuart, M. D. Vaan, P. Ginsparg, and Y . Yin, “Llm hallucinations in the wild: Large-scale evidence from non-existent citations,” 2026. [Online]. Available: https: //arxiv.org/abs/2605.07723
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
GhostCite: A Large-Scale Analysis of Citation Validity in the Age of Large Language Models
Z. Xu, Y . Qiu, L. Sun, F. Miao, F. Wu, X. Li, X. Wang, H. Lu, Z. Zhang, Y . Hu, J. Li, L. Jin, F. Zhang, R. Luo, X. Liu, Y . Li, and J. Liu, “Ghostcite: A large-scale analysis of citation validity in the age of large language models,” 2026. [Online]. Available: https://arxiv.org/abs/2602.06718
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
S. Ansari, “Compound deception in elite peer review: A failure mode taxonomy of 100 fabricated citations at neurips 2025,” 2026. [Online]. Available: https://arxiv.org/abs/2602.05930
-
[17]
Y . Sakai, H. Kamigaito, and T. Watanabe, “Hallucitation matters: Revealing the impact of hallucinated references with 300 hallucinated papers in acl conferences,” 2026. [Online]. Available: https: //arxiv.org/abs/2601.18724
-
[18]
GPTZero finds 100 new hallucinations in NeurIPS 2025 accepted papers,
N. Shmatko, A. Adam, P. Esau, A. Cui, and E. Tian, “GPTZero finds 100 new hallucinations in NeurIPS 2025 accepted papers,” https:// gptzero.me/news/neurips/, 2026
2025
-
[19]
M. Naser, “How llms cite and why it matters: A cross-model audit of reference fabrication in ai-assisted academic writing and methods to detect phantom citations,” 2026. [Online]. Available: https://arxiv.org/abs/2603.03299
-
[20]
Do language models know when they’re hallucinating references?
A. Agrawal, M. Suzgun, L. Mackey, and A. T. Kalai, “Do language models know when they’re hallucinating references?” inFindings of the Association for Computational Linguistics: EACL 2024, 2024
2024
-
[21]
K. Shi, W. Sun, Z. Zhang, L. Sun, N. V . Chawla, and Y . Ye, “Citeaudit: You cited it, but did you read it? a benchmark for verifying scientific references in the llm era,” 2026. [Online]. Available: https://arxiv.org/abs/2602.23452
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
TruthfulQA: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “TruthfulQA: Measuring how models mimic human falsehoods,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 3214–3252. [Online]. Availa...
2022
-
[23]
HaluEval: A large-scale hallucination evaluation benchmark for large language models,
J. Li, X. Cheng, X. Zhao, J.-Y . Nie, and J.-R. Wen, “HaluEval: A large-scale hallucination evaluation benchmark for large language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 6449–6464. [Online...
2023
-
[24]
FActScore: Fine- grained atomic evaluation of factual precision in long form text generation,
S. Min, K. Krishna, X. Lyu, M. Lewis, W.-t. Yih, P. Koh, M. Iyyer, L. Zettlemoyer, and H. Hajishirzi, “FActScore: Fine- grained atomic evaluation of factual precision in long form text generation,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Com...
2023
-
[25]
On faithfulness and factuality in abstractive summarization,
J. Maynez, S. Narayan, B. Bohnet, and R. McDonald, “On faithfulness and factuality in abstractive summarization,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational Linguistics, Jul. 2020, pp. 1906–1919. [Online]. Availa...
2020
-
[26]
Sources of hallucination by large language models on inference tasks,
N. McKenna, T. Li, L. Cheng, M. Hosseini, M. Johnson, and M. Steedman, “Sources of hallucination by large language models on inference tasks,” inFindings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 2758–2774. [Online]. Available: h...
2023
-
[27]
Measuring attribution in natural language generation models,
H. Rashkin, V . Nikolaev, M. Lamm, L. Aroyo, M. Collins, D. Das, S. Petrov, G. S. Tomar, I. Turc, and D. Reitter, “Measuring attribution in natural language generation models,”Computational Linguistics, vol. 49, no. 4, pp. 777–840, Dec. 2023. [Online]. Available: https://aclanthology.org/2023.cl-4.2/
2023
-
[28]
Evaluating verifiability in generative search engines,
N. Liu, T. Zhang, and P. Liang, “Evaluating verifiability in generative search engines,” inFindings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 7001–7025. [Online]. Available: https://aclanthology.org/2023.findings-emnlp.467/
2023
-
[29]
Enabling large language models to generate text with citations,
T. Gao, H. Yen, J. Yu, and D. Chen, “Enabling large language models to generate text with citations,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 6465–6488. [Online]. Available: https://aclanthology.org/...
2023
-
[30]
LongCite: Enabling LLMs to generate fine-grained citations in long-context QA,
J. Zhang, Y . Bai, X. Lv, W. Gu, D. Liu, M. Zou, S. Cao, L. Hou, Y . Dong, L. Feng, and J. Li, “LongCite: Enabling LLMs to generate fine-grained citations in long-context QA,” inFindings of the Association for Computational Linguistics: ACL 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Computational Lingui...
2025
-
[31]
FEVER: a large-scale dataset for fact extraction and VERification,
J. Thorne, A. Vlachos, C. Christodoulopoulos, and A. Mittal, “FEVER: a large-scale dataset for fact extraction and VERification,” inProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), M. Walker, H. Ji, and A. Stent, Eds. New Orleans, Louisia...
2018
-
[32]
A watermark for large language models,
J. Kirchenbauer, J. Geiping, Y . Wen, J. Katz, I. Miers, and T. Goldstein, “A watermark for large language models,” in Proceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23–29 Jul 2023, pp. 17 ...
2023
-
[33]
De- tectgpt: zero-shot machine-generated text detection using probability curvature,
E. Mitchell, Y . Lee, A. Khazatsky, C. D. Manning, and C. Finn, “De- tectgpt: zero-shot machine-generated text detection using probability curvature,” inProceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.