LeVLJEPA: End-to-End Vision-Language Pretraining Without Negatives
Pith reviewed 2026-07-02 14:07 UTC · model grok-4.3
The pith
Non-contrastive cross-modal prediction produces stronger dense vision-language features than contrastive methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
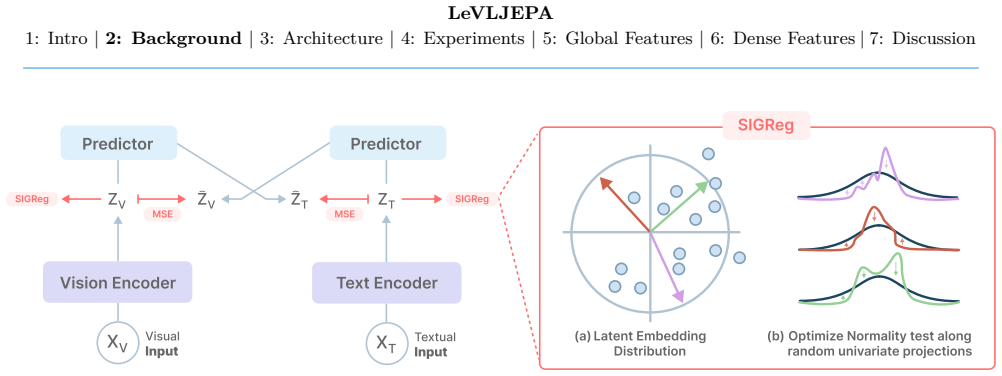
LeVLJEPA shows that vision-language representations can be learned end-to-end through cross-modal prediction with stop-gradient targets and per-modality distributional regularization alone, without negatives or contrastive terms, and that the resulting encoder yields stronger dense semantic features than contrastive baselines when used as a frozen vision-language-model backbone on GQA, VQAv2, POPE, and semantic segmentation.
What carries the argument
Cross-modal prediction with stop-gradient targets and per-modality distributional regularization, which replaces negative sampling by enabling stable non-contrastive training through direct prediction and intra-modality distribution control.
If this is right
- The encoder supplies better inputs for dense prediction systems that consume the full grid of patch tokens rather than a single pooled embedding.
- Non-contrastive pretraining can replace contrastive objectives in vision-language settings while remaining stable at large scale without momentum encoders or teacher-student schedules.
- Performance advantages concentrate on dense readouts such as segmentation and VQA rather than global tasks like linear probing.
- The approach demonstrates that explicit contrast is not required to prevent collapse in multimodal pretraining.
Where Pith is reading between the lines
- The same prediction-plus-regularization pattern might apply to other modality pairs beyond vision and language.
- Removing the distributional regularization term could be tested to isolate whether prediction alone suffices.
- This setup could reduce training complexity in large multimodal models by dropping the need for negative sampling infrastructure.
Load-bearing premise
Cross-modal prediction with stop-gradient targets plus per-modality distributional regularization is enough to learn useful representations without any contrastive signal or negative sampling.
What would settle it
A controlled comparison at identical large scale and architecture where LeVLJEPA produces weaker features than contrastive baselines on dense tasks such as semantic segmentation or VQA.
Figures
read the original abstract
Vision-language pretraining remains dominated by contrastive objectives, whereas vision-only self-supervised learning has largely adopted non-contrastive methods. At the same time, the role of vision-language encoders has shifted: they are increasingly deployed not as zero-shot classifiers but as the frozen visual backbone of vision-language models and dense prediction systems, which consume the full grid of patch tokens rather than a single pooled embedding. We introduce LeVLJEPA, the first fully non-contrastive end-to-end vision-language pretraining method. LeVLJEPA learns through cross-modal prediction with stop-gradient targets and per-modality distributional regularization, without negatives, temperature, momentum encoder, or teacher-student schedule, and trains stably at large scale. We find that the resulting encoder provides markedly stronger dense semantic features for downstream use: as a frozen vision-language-model backbone, LeVLJEPA is the strongest of the evaluated encoders across GQA, VQAv2, and POPE under two distinct language models, and outperforms contrastive baselines on semantic segmentation, while remaining on par on global readouts such as linear probing. These results establish non-contrastive pretraining as an effective means of producing dense semantic vision features.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LeVLJEPA, the first fully non-contrastive end-to-end vision-language pretraining method. It learns via cross-modal prediction using stop-gradient targets and per-modality distributional regularization, without negatives, temperature, momentum encoder, or teacher-student schedule. The resulting encoder is evaluated as a frozen backbone in vision-language models on GQA, VQAv2, and POPE (strongest among evaluated encoders under two language models), on semantic segmentation (outperforms contrastive baselines), and on global readouts such as linear probing (on par with baselines). The central claim is that this approach produces markedly stronger dense semantic features and establishes non-contrastive pretraining as effective for such use cases.
Significance. If the empirical results hold, the work demonstrates that a simple non-contrastive objective suffices for high-quality dense vision-language representations at scale, removing the need for contrastive machinery. This is a substantive contribution given the shift toward using VL encoders as frozen backbones for dense prediction rather than zero-shot classification. The method is coherent and internally consistent per the full text, with no hidden contrastive terms or scaling instabilities identified.
minor comments (3)
- [§4] §4 (Experiments): the main result tables would benefit from reporting standard deviations over multiple runs or seeds to substantiate the 'strongest' and 'outperforms' claims across GQA/VQAv2/POPE and segmentation.
- [§3.2] §3.2 (Method): the per-modality distributional regularization term is described at a high level; an explicit equation or pseudocode would clarify how it interacts with the cross-modal prediction loss without introducing implicit negatives.
- [Figure 2] Figure 2 / Table 1: axis labels and legend entries for the segmentation and linear-probing comparisons should explicitly name the contrastive baselines (e.g., CLIP, SigLIP) for direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation for minor revision. No major comments are listed in the report.
Circularity Check
No significant circularity identified
full rationale
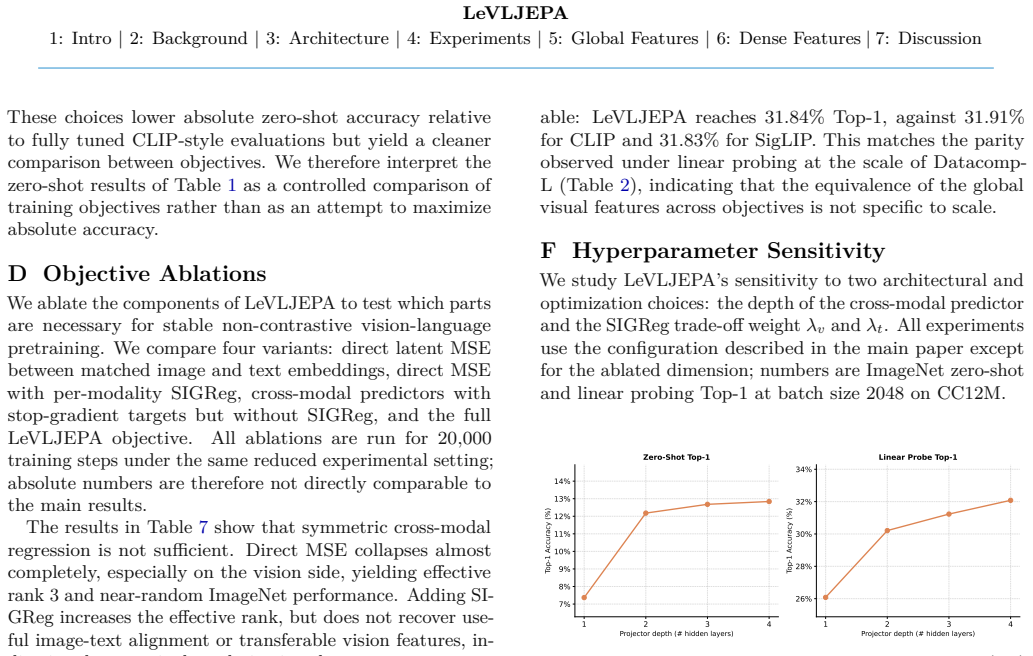
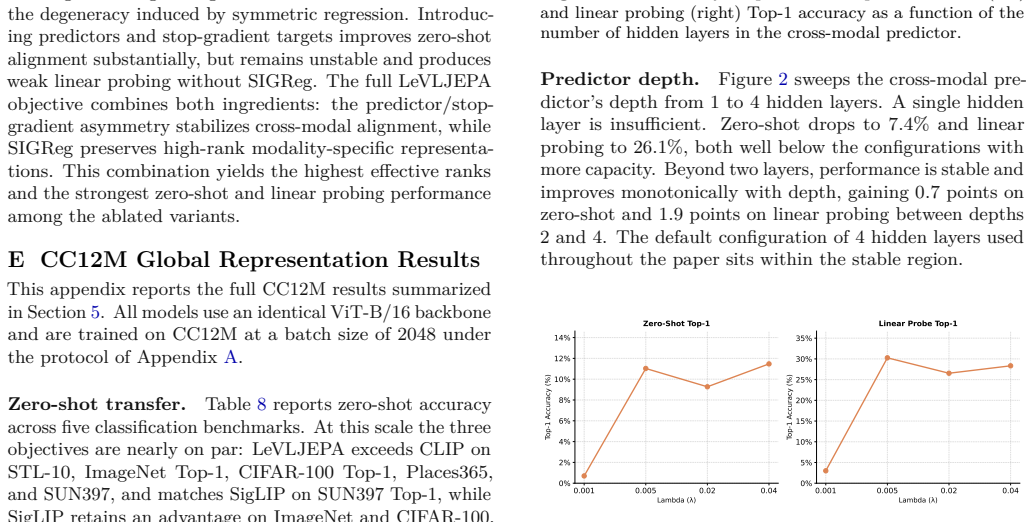
The paper presents an empirical non-contrastive pretraining method (cross-modal prediction with stop-gradient targets and per-modality distributional regularization) and reports downstream task results on GQA, VQAv2, POPE, and segmentation. No derivation chain, equations, or first-principles claims are present that reduce by construction to fitted parameters, self-citations, or renamed inputs. The method is described as novel without invoking load-bearing uniqueness theorems or ansatzes from prior self-work. This is a standard empirical contribution whose central claims rest on experimental outcomes rather than definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning from images with a joint-embedding predictive architec- ture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architec- ture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619– 15629, 2023
2023
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization, 2016. URL https:// arxiv.org/abs/1607.06450
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
Randall Balestriero and Yann LeCun. Lejepa: Prov- able and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
stable-pretraining- v1: Foundation model research made simple.arXiv preprint arXiv:2511.19484, 2025
Randall Balestriero, Hugues Van Assel, Sami BuGhanem, and Lucas Maes. stable-pretraining- v1: Foundation model research made simple.arXiv preprint arXiv:2511.19484, 2025
-
[5]
Coco-stuff: Thing and stuff classes in context
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1209–1218, 2018
2018
-
[6]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 9650–9660, 2021
2021
-
[7]
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3558– 3568, 2021
2021
-
[8]
Delong Chen, Mustafa Shukor, Theo Moutakanni, Willy Chung, Jade Yu, Tejaswi Kasarla, Yejin Bang, Allen Bolourchi, Yann LeCun, and Pascale Fung. Vl- jepa: Joint embedding predictive architecture for vision-language.arXiv preprint arXiv:2512.10942, 2025
-
[9]
A Simple Framework for Contrastive Learning of Visual Representations
TingChen, SimonKornblith, MohammadNorouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations, 2020. URLhttps: //arxiv.org/abs/2002.05709
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[10]
Exploring simple siamese representation learning
Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750–15758, 2021
2021
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
Datacomp: In search of the next generation of multimodal datasets.Advances in Neu- ral Information Processing Systems, 36:27092–27112, 2023
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. Datacomp: In search of the next generation of multimodal datasets.Advances in Neu- ral Information Processing Systems, 36:27092–27112, 2023
2023
-
[14]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
2017
-
[15]
Bootstrap your own latent-a new approach to self-supervised learning.Ad- vances in neural information processing systems, 33: 21271–21284, 2020
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mo- hammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Ad- vances in neural information processing systems, 33: 21271–21284, 2020
2020
-
[16]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
2019
-
[17]
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Openclip, July2021. URLhttps://doi.org/ 10.5281/zenodo.5143773. If you use this software, please cite it as below
-
[18]
Language-driven representation learning for robotics.arXiv preprint arXiv:2302.12766, 2023
Siddharth Karamcheti, Suraj Nair, Annie S Chen, Thomas Kollar, Chelsea Finn, Dorsa Sadigh, and Percy Liang. Language-driven representation learning for robotics.arXiv preprint arXiv:2302.12766, 2023
-
[19]
Evaluating object hallucina- tion in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucina- tion in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
2023
-
[20]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 9 LeVLJEPA 1: Intro | 2: Background | 3: Architecture | 4: Experiments | 5: Global Features | 6: Dense Features |7: Discussion
2023
-
[21]
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. Leworldmodel: Sta- ble end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
S. Maji, J. Kannala, E. Rahtu, M. Blaschko, and A. Vedaldi. Fine-grained visual classification of aircraft. Technical report, 2013
2013
-
[23]
Language models are unsupervised multitask learners.OpenAI blog, 1 (8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1 (8):9, 2019
2019
-
[24]
Learning transferable visual models from natural lan- guage supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural lan- guage supervision. InInternational conference on ma- chine learning, pages 8748–8763. PmLR, 2021
2021
-
[25]
Denseclip: Language-guided dense predic- tion with context-aware prompting
Yongming Rao, Wenliang Zhao, Guangyi Chen, Yan- song Tang, Zheng Zhu, Guan Huang, Jie Zhou, and Jiwen Lu. Denseclip: Language-guided dense predic- tion with context-aware prompting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18082–18091, 2022
2022
-
[26]
Cli- port: What and where pathways for robotic manipula- tion
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cli- port: What and where pathways for robotic manipula- tion. InConference on robot learning, pages 894–906. PMLR, 2022
2022
-
[27]
Kai Xiao, Logan Engstrom, Andrew Ilyas, and Alek- sander Madry. Noise or signal: The role of image backgrounds in object recognition.arXiv preprint arXiv:2006.09994, 2020
-
[28]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 11975– 11986, 2023
2023
-
[29]
Places: A 10 million im- age database for scene recognition.IEEE transactions on pattern analysis and machine intelligence, 40(6): 1452–1464, 2017
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million im- age database for scene recognition.IEEE transactions on pattern analysis and machine intelligence, 40(6): 1452–1464, 2017
2017
-
[30]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641, 2017. 10 LeVLJEPA 1: Intro | 2: Background | 3: Architecture | 4: Experiments | 5: Global Features | 6: Dense Features | 7: Discussion ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.