Pano2World: End-to-End 3D Generation via Unified Multi-View Sequences
Pith reviewed 2026-07-02 13:50 UTC · model grok-4.3
The pith
Pano2World converts a single indoor panorama directly into a persistent 3D Gaussian scene for free-viewpoint exploration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
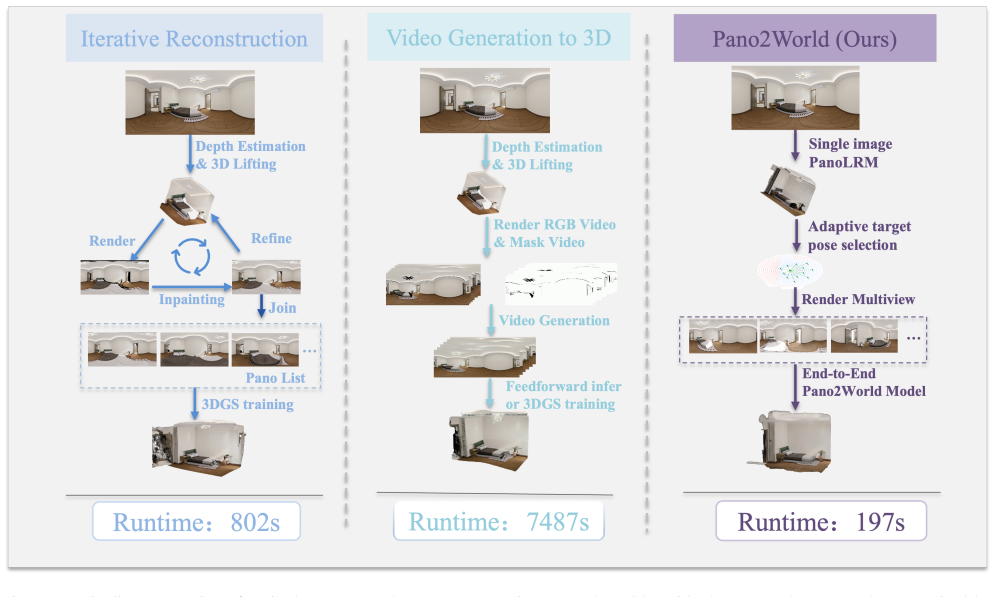
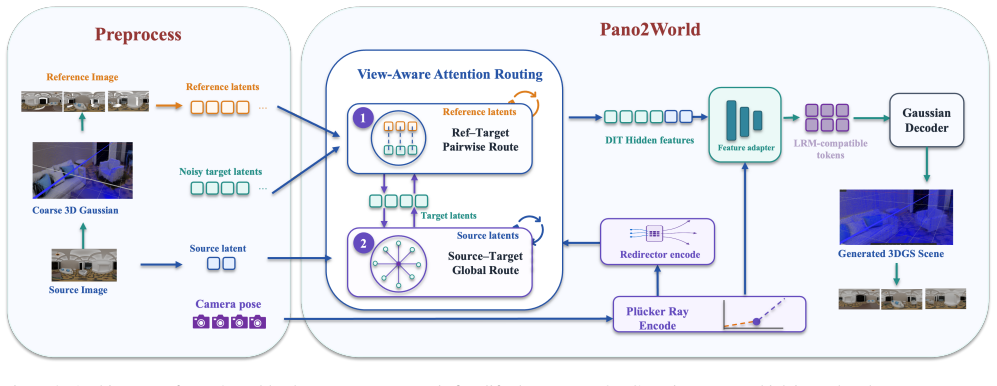
Pano2World takes a single indoor panorama as input and directly outputs a persistent, explorable 3D Gaussian scene. It first reconstructs a coarse 3D Gaussian proxy and renders it at adaptively sampled nearby poses to obtain geometrically aligned guidance panoramas. A panoramic diffusion model then jointly denoises all target views via View-Aware Attention Routing, where each target view receives geometric constraints from its guidance panorama and global semantic guidance from the source panorama. To avoid information loss from VAE decoding, the Latent Feature Adapter distills the hidden features into a scene latent that decodes to the final 3D Gaussian scene.
What carries the argument
View-Aware Attention Routing in the panoramic diffusion model, which supplies each target view with both geometric guidance from rendered proxy panoramas and semantic guidance from the source, combined with the Latent Feature Adapter that bridges multi-view features directly to 3D Gaussians.
If this is right
- Direct output of 3D scene avoids progressive error accumulation from iterative pipelines.
- Joint denoising with attention routing enforces cross-view consistency naturally.
- Outperforms prior methods on multi-position panoramic novel-view synthesis benchmarks.
- The approach supports true free-viewpoint navigation from a single capture.
Where Pith is reading between the lines
- Similar guidance mechanisms could improve consistency in other multi-view generation tasks beyond panoramas.
- If the coarse proxy is accurate enough, the method might generalize to dynamic scenes with minimal changes.
- Integration with real-time rendering engines would allow immediate exploration after capture.
- The latent distillation step suggests efficiency gains over pixel-space decoding in 3D generation pipelines.
Load-bearing premise
That the guidance panoramas rendered from the coarse 3D Gaussian proxy provide sufficient geometric alignment for the View-Aware Attention Routing to enforce consistency without needing additional post-processing.
What would settle it
Generating a scene where novel views from unsampled positions exhibit geometric inconsistencies or blurring that cannot be explained by the input panorama alone.
Figures

read the original abstract
A single panorama captures the full visual sphere from one camera center, yet confines users to looking around in place without enabling true scene exploration. Converting a single panorama into a persistent, renderable 3D representation for free-viewpoint navigation has attracted growing interest; existing methods either adopt iterative per-view completion that propagates inpainting results to update the underlying geometry, leading to progressive error accumulation and cumbersome multi-step pipelines, or leverage the temporal consistency priors of video generation models, yet the continuous-trajectory constraint intrinsic to such models limits their flexibility in covering scenes from multiple directions simultaneously. We present Pano2World, which takes a single indoor panorama as input and directly outputs a persistent, explorable 3D Gaussian scene. Given the source panorama, Pano2World first reconstructs a coarse 3D Gaussian proxy and renders it at adaptively sampled nearby poses to obtain geometrically aligned guidance panoramas; a panoramic diffusion model then jointly denoises all target views via View-Aware Attention Routing, where each target view simultaneously receives geometric constraints from its corresponding guidance panorama and global semantic guidance from the source panorama, naturally enforcing cross-view consistency. To avoid the information loss incurred by decoding the multi-view hidden features formed during joint denoising back to the pixel domain via VAE, we introduce Latent Feature Adapter, a geometry-aware bridge module that directly distills these hidden features into a scene latent, subsequently decoded into the final 3D Gaussian scene. Experiments demonstrate that Pano2World significantly outperforms existing methods on the multi-position panoramic novel-view synthesis benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Pano2World, a method that converts a single indoor panorama into a persistent, explorable 3D Gaussian scene for free-viewpoint navigation. It reconstructs a coarse 3D Gaussian proxy from the input, renders geometrically aligned guidance panoramas at adaptively sampled nearby poses, employs a panoramic diffusion model that jointly denoises target views using View-Aware Attention Routing (injecting geometric constraints from guidance panoramas and semantic guidance from the source), and introduces a Latent Feature Adapter to distill multi-view hidden features directly into a scene latent decoded to the final 3D Gaussians, avoiding VAE decoding losses. The central claim is that this end-to-end pipeline significantly outperforms prior iterative or video-based methods on the multi-position panoramic novel-view synthesis benchmark without post-processing or iterative refinement.
Significance. If the quantitative results and ablations hold, the work would offer a meaningful advance in single-image 3D scene generation by providing a direct, non-iterative pipeline that leverages proxy guidance and attention routing for cross-view consistency while preserving information via latent distillation. The View-Aware Attention Routing and Latent Feature Adapter are potentially reusable technical contributions for multi-view diffusion models in 3D reconstruction tasks.
major comments (2)
- [Abstract] Abstract: the claim of 'significantly outperforming existing methods on the multi-position panoramic novel-view synthesis benchmark' is presented without any quantitative metrics, tables, error bars, or ablation results, preventing verification of the central performance claim.
- [Abstract] Method overview (Abstract): the pipeline rests on the assumption that the coarse 3D Gaussian proxy produces guidance panoramas whose geometric constraints, when routed via View-Aware Attention Routing, suffice to enforce cross-view consistency without refinement; no details are given on proxy reconstruction (e.g., depth accuracy or method), and no ablation is referenced showing that degrading or removing the proxy collapses consistency.
minor comments (1)
- [Abstract] Abstract: the specific benchmark name is referenced without citation or description, which would aid evaluation context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will make targeted revisions to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'significantly outperforming existing methods on the multi-position panoramic novel-view synthesis benchmark' is presented without any quantitative metrics, tables, error bars, or ablation results, preventing verification of the central performance claim.
Authors: The abstract serves as a concise overview; the full manuscript provides the requested verification through detailed quantitative tables, metrics (PSNR, SSIM, LPIPS), error bars from repeated runs, and ablation studies in Section 4. To enable direct verification from the abstract, we will revise it to include the key reported performance gains (e.g., specific PSNR improvements over baselines). revision: yes
-
Referee: [Abstract] Method overview (Abstract): the pipeline rests on the assumption that the coarse 3D Gaussian proxy produces guidance panoramas whose geometric constraints, when routed via View-Aware Attention Routing, suffice to enforce cross-view consistency without refinement; no details are given on proxy reconstruction (e.g., depth accuracy or method), and no ablation is referenced showing that degrading or removing the proxy collapses consistency.
Authors: Abstract length limits preclude full technical details, which appear in Section 3.1 (proxy reconstruction via depth estimation from the panorama, with reported accuracy characteristics) and Section 4 (ablations on proxy guidance and View-Aware Attention Routing, showing consistency degradation when removed). We will revise the abstract to briefly note the proxy method and explicitly cite the ablation study demonstrating its necessity for cross-view consistency. revision: yes
Circularity Check
No circularity: forward pipeline from panorama to 3D Gaussians
full rationale
The paper describes a forward architectural pipeline (single panorama -> coarse proxy reconstruction -> guidance panorama rendering at sampled poses -> View-Aware Attention Routing in panoramic diffusion -> Latent Feature Adapter distilling to scene latent -> final 3D Gaussian output) with no equations, fitted parameters renamed as predictions, or self-citations that reduce any claimed result to its inputs by construction. All steps are presented as independent modules whose sufficiency is an empirical claim, not a definitional equivalence. This is self-contained against external benchmarks and matches the default non-circular outcome.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
3d-front: 3d furnished rooms with layouts and semantics
Huan Fu, Bowen Cai, Lin Gao, Lingxiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Bin- qiang Zhao, and Hao Zhang. 3d-front: 3d furnished rooms with layouts and semantics. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2021. 6
2021
-
[2]
Srinivasan, Jonathan T
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul P. Srinivasan, Jonathan T. Barron, and Ben Poole. CAT3D: Create any- thing in 3d with multi-view diffusion models. InNeurIPS,
-
[3]
Monouni: A uni- fied vehicle and infrastructure-side monocular 3d object de- tection network with sufficient depth clues
Jinrang Jia, Zhenjia Li, and Yifeng Shi. Monouni: A uni- fied vehicle and infrastructure-side monocular 3d object de- tection network with sufficient depth clues. InAdvances in Neural Information Processing Systems, pages 11703– 11715, 2023. 1
2023
-
[4]
PanoWorld: A Generative Spatial World Model for Consistent Whole-House Panorama Synthesis
Jinrang Jia, Zhenjia Li, Yijiang Hu, and Yifeng Shi. Panoworld: A generative spatial world model for con- sistent whole-house panorama synthesis.arXiv preprint arXiv:2605.17916, 2026. 2, 3, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
You only gaussian once: Controllable 3d gaussian splatting for ultra-densely sampled scenes, 2026
Jinrang Jia, Zhenjia Li, and Yifeng Shi. You only gaussian once: Controllable 3d gaussian splatting for ultra-densely sampled scenes, 2026. 1, 3
2026
-
[6]
CubeDiff: Repurposing diffusion-based image models for panorama generation
Nikolai Kalischek, Michael Oechsle, Fabian Manhardt, Philipp Henzler, Konrad Schindler, and Federico Tombari. CubeDiff: Repurposing diffusion-based image models for panorama generation. InICLR, 2025. 3
2025
-
[7]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4):139:1–139:14, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4):139:1–139:14, 2023. 1, 2
2023
-
[8]
Realsee3d: A large- scale multi-view rgb-d dataset of indoor scenes (version 1.0),
Linyuan Li, Yan Wu, Xi Li, Lingli Wang, Tong Rao, Jie Zhou, Cihui Pan, and Xinchen Hui. Realsee3d: A large- scale multi-view rgb-d dataset of indoor scenes (version 1.0),
-
[9]
Era3D: High-resolution multiview diffusion using efficient row-wise attention
Peng Li, Yuan Liu, Xiaoxiao Long, Feihu Zhang, Cheng Lin, Mengfei Li, Xingqun Qi, Shanghang Zhang, Wenhan Luo, Ping Tan, Wenping Wang, Qifeng Liu, and Yike Guo. Era3D: High-resolution multiview diffusion using efficient row-wise attention. InNeurIPS, 2024. 3
2024
-
[10]
Aoming Liu, Zhong Li, Zhang Chen, Nannan Li, Yi Xu, and Bryan A. Plummer. PanoFree: Tuning-free holistic multi- view image generation with cross-view self-guidance. In ECCV, 2024. 3
2024
-
[11]
Atten- tiongs: Towards initialization-free 3d gaussian splatting via structural attention, 2025
Ziao Liu, Zhenjia Li, Yifeng Shi, and Xiangang Li. Atten- tiongs: Towards initialization-free 3d gaussian splatting via structural attention, 2025. 3
2025
-
[12]
Byeongjun Park, Byung-Hoon Kim, Hyungjin Chung, and Jong Chul Ye. ReDirector: Creating any-length video retakes with rotary camera encoding.arXiv preprint arXiv:2511.19827, 2025. 4
-
[13]
Pano2Room: Novel view synthesis from a single indoor panorama
Guo Pu, Yiming Zhao, and Zhouhui Lian. Pano2Room: Novel view synthesis from a single indoor panorama. InSIG- GRAPH Asia, 2024. 1, 3, 7
2024
-
[14]
GEN3C: 3d-informed world-consistent video generation with precise camera con- trol
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Mueller, Alexan- der Keller, Sanja Fidler, and Jun Gao. GEN3C: 3d-informed world-consistent video generation with precise camera con- trol. InCVPR, 2025. 3
2025
-
[15]
MVDiffusion++: A dense high- resolution multi-view diffusion model for single or sparse- view 3d object reconstruction
Shitao Tang, Jiacheng Chen, Dilin Wang, Chengzhou Tang, Fuyang Zhang, Yuchen Fan, Vikas Chandra, Yasutaka Fu- rukawa, and Rakesh Ranjan. MVDiffusion++: A dense high- resolution multi-view diffusion model for single or sparse- view 3d object reconstruction. InECCV, 2024. 3
2024
-
[16]
HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
Team HY-World, Chenjie Cao, Xuhui Zuo, Zhenwei Wang, Yisu Zhang, Junta Wu, Zhenyang Liu, Yuning Gong, Yang Liu, Bo Yuan, Chao Zhang, Coopers Li, Dongyuan Guo, Fan Yang, Haiyu Zhang, Hang Cao, Jianchen Zhu, Jiaxin Lin, Jie Xiao, Jihong Zhang, Junlin Yu, Lei Wang, Lifu Wang, Lilin Wang, Linus, Minghui Chen, Peng He, Penghao Zhao, Qi Chen, Rui Chen, Rui Shao...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Artifactworld: Scaling 3d gaussian splatting artifact restoration via video generation models, 2026
Xinliang Wang, Yifeng Shi, and Zhenyu Wu. Artifactworld: Scaling 3d gaussian splatting artifact restoration via video generation models, 2026. 3
2026
-
[18]
Zun Wang, Han Lin, Jaehong Yoon, Jaemin Cho, Yue Zhang, and Mohit Bansal. AnchorWeave: World-consistent video generation with retrieved local spatial memories.arXiv preprint arXiv:2602.14941, 2026. 3
-
[19]
Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
Tong Wu, Shuai Yang, Ryan Po, Yinghao Xu, Ziwei Liu, Dahua Lin, and Gordon Wetzstein. Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284,
-
[20]
Adapt- splat: Adapting vision foundation models for feed-forward 3d gaussian splatting, 2026
Mingwei Xing, Xinliang Wang, and Yifeng Shi. Adapt- splat: Adapting vision foundation models for feed-forward 3d gaussian splatting, 2026. 1
2026
-
[21]
Tian-Xing Xu, Xiangjun Gao, Wenbo Hu, Xiaoyu Li, Song- Hai Zhang, and Ying Shan. GeometryCrafter: Consistent geometry estimation for open-world videos with diffusion priors.arXiv preprint arXiv:2504.01016, 2025. 3
-
[22]
Matrix-3d: Omnidirectional explorable 3d world generation,
Zhongqi Yang, Wenhang Ge, Yuqi Li, Jiaqi Chen, Haoyuan Li, Mengyin An, Fei Kang, Hua Xue, Baixin Xu, Yuyang Yin, Eric Li, Yang Liu, Yikai Wang, Hao-Xiang Guo, and Yahui Zhou. Matrix-3d: Omnidirectional explorable 3d world generation.arXiv preprint arXiv:2508.08086, 2025. 1, 7
-
[23]
Runmao Yao, Junsheng Zhou, Zhen Dong, and Yu-Shen Liu. AnchoredDream: Zero-shot 360-degree indoor scene gener- ation from a single view via geometric grounding.arXiv preprint arXiv:2601.16532, 2026. 3
-
[24]
DiffPano: Scalable and con- sistent text to panorama generation with spherical epipolar- aware diffusion
Weicai Ye, Chenhao Ji, Zheng Chen, Junyao Gao, Xiaoshui Huang, Song-Hai Zhang, Wanli Ouyang, Tong He, Cairong Zhao, and Guofeng Zhang. DiffPano: Scalable and con- sistent text to panorama generation with spherical epipolar- aware diffusion. InNeurIPS, 2024. 3
2024
-
[25]
Freeman, and Jiajun Wu
Hong-Xing Yu, Haoyi Duan, Charles Herrmann, William T. Freeman, and Jiajun Wu. WonderWorld: Interactive 3d scene generation from a single image. InCVPR, 2025. 3
2025
-
[26]
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Tra- jectoryCrafter: Redirecting camera trajectory for monoc- 9 ular videos via diffusion models.arXiv preprint arXiv:2503.05638, 2025. 3
-
[27]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. ViewCrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Cheng Zhang, Qianyi Wu, Camilo Cruz Gambardella, Xi- aoshui Huang, Dinh Phung, Wanli Ouyang, and Jianfei Cai. Taming stable diffusion for text to 360-degree panorama im- age generation.arXiv preprint arXiv:2404.07949, 2024. 3
-
[29]
Efros, Eli Shecht- man, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, 2018. 6
2018
-
[30]
Yisu Zhang, Chenjie Cao, Tengfei Wang, Xuhui Zuo, Junta Wu, Jianke Zhu, and Chunchao Guo. WorldStereo: Bridging camera-guided video generation and scene re- construction via 3d geometric memories.arXiv preprint arXiv:2603.02049, 2026. 7 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.