Graph-Native Reinforcement Learning Enables Traceable Scientific Hypothesis Generation through Conceptual Recombination
Pith reviewed 2026-07-02 12:25 UTC · model grok-4.3
The pith
Graph-PRefLexOR organizes reasoning into explicit phases via graph-native reinforcement learning, producing more traceable hypotheses than base models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
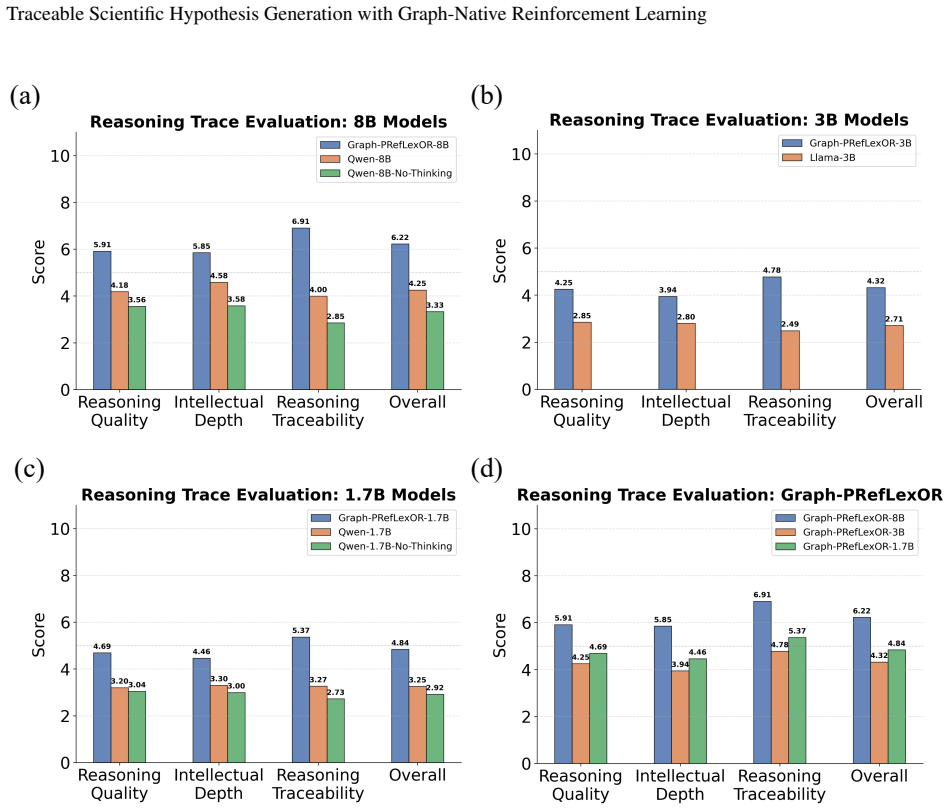
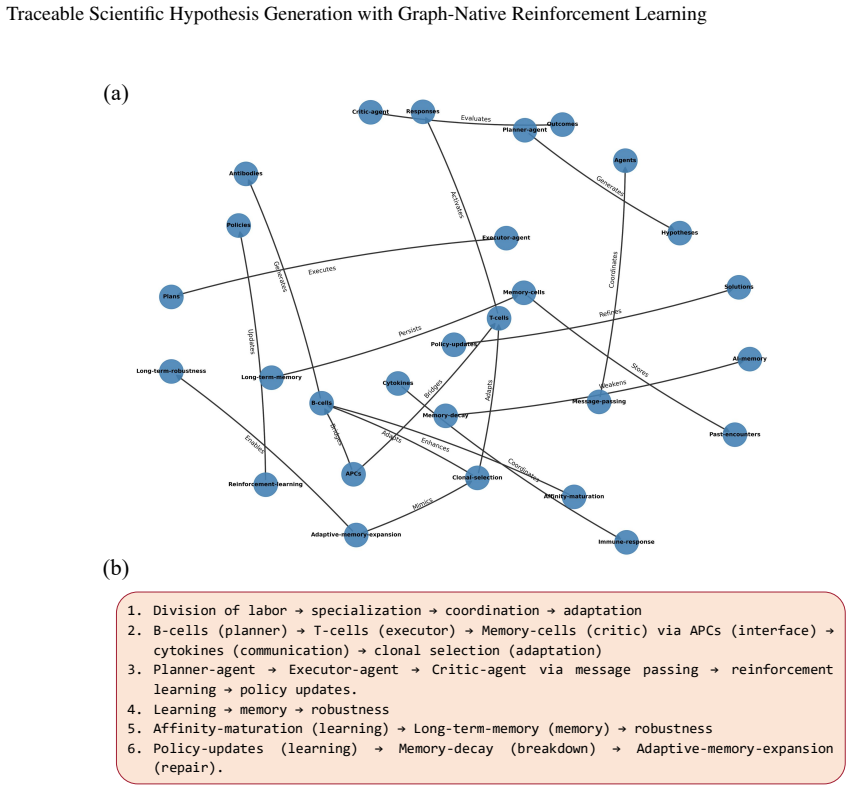
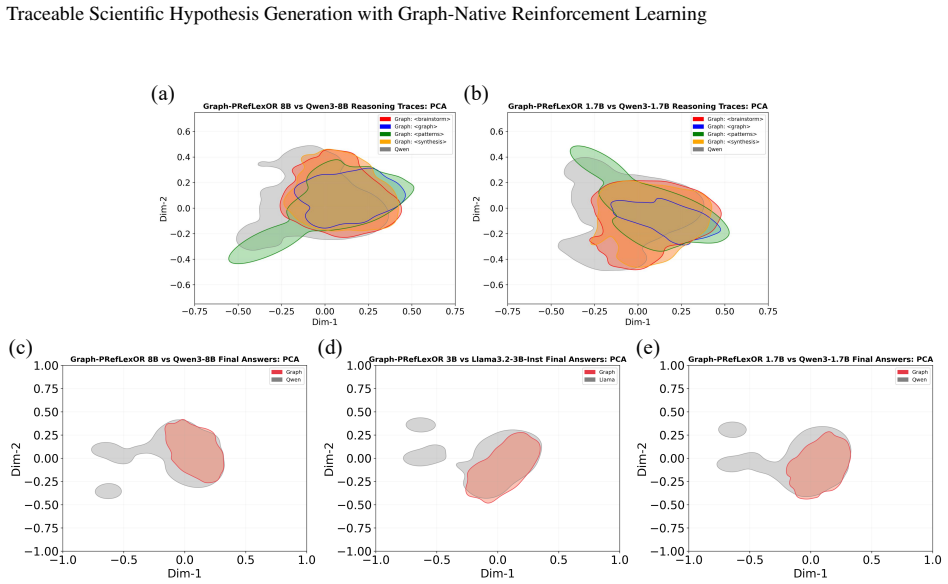
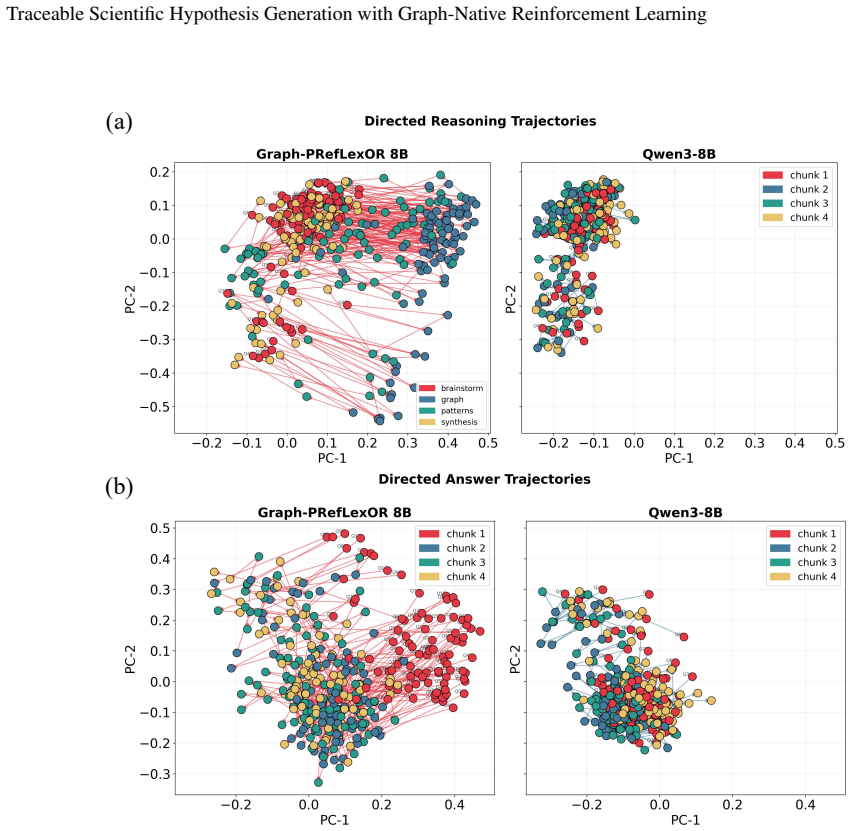
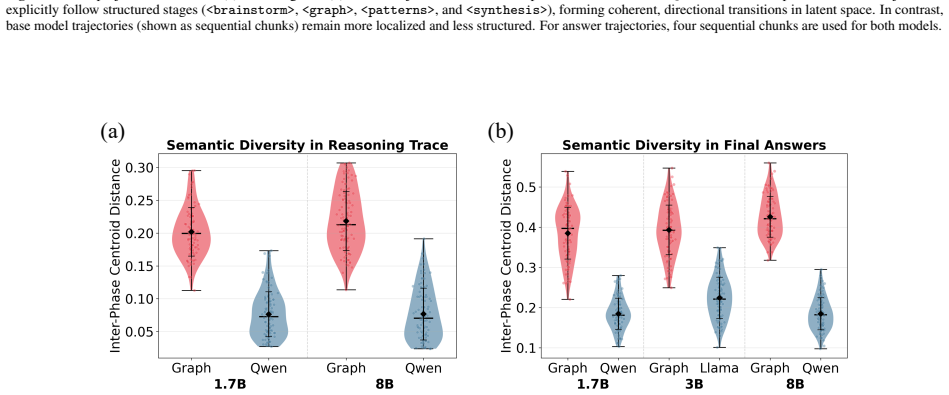
Graph-PRefLexOR links neural language generation with symbolic relational structure by organizing reasoning into explicit phases for mechanism exploration, graph construction, pattern extraction, and hypothesis synthesis. This design enables causal connections to be constructed, inspected, and reused, resulting in 40-65% improvements over base models on 100 open-ended materials questions, with the largest gains in reasoning traceability, broader semantic exploration, and stronger alignment between intermediate reasoning and final answers.
What carries the argument
Graph-PRefLexOR, the graph-native reasoning model fine-tuned with Group Relative Policy Optimization (GRPO) to enforce phased reasoning that connects language outputs to symbolic graphs for inspection and recombination.
If this is right
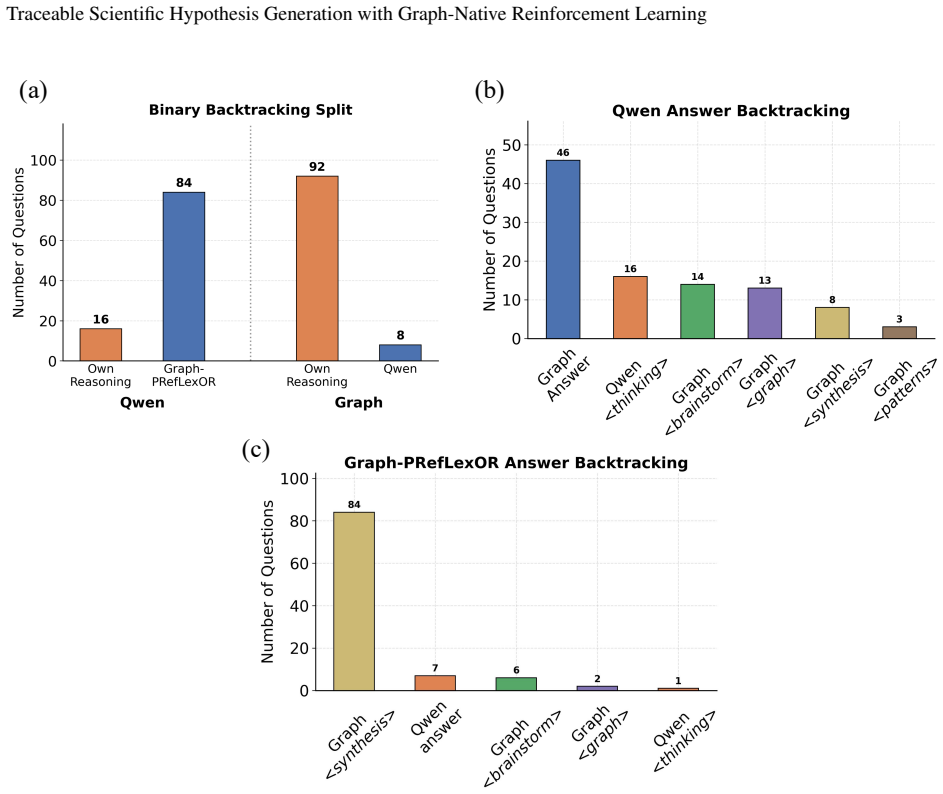
- Reasoning steps become inspectable, so users can trace how intermediate graphs support or contradict the final hypothesis.
- Semantic diversity roughly doubles, allowing the model to explore a wider set of conceptual combinations within the same domain.
- Additional test-time compute increases long-range recombination rather than simply widening the covered semantic space.
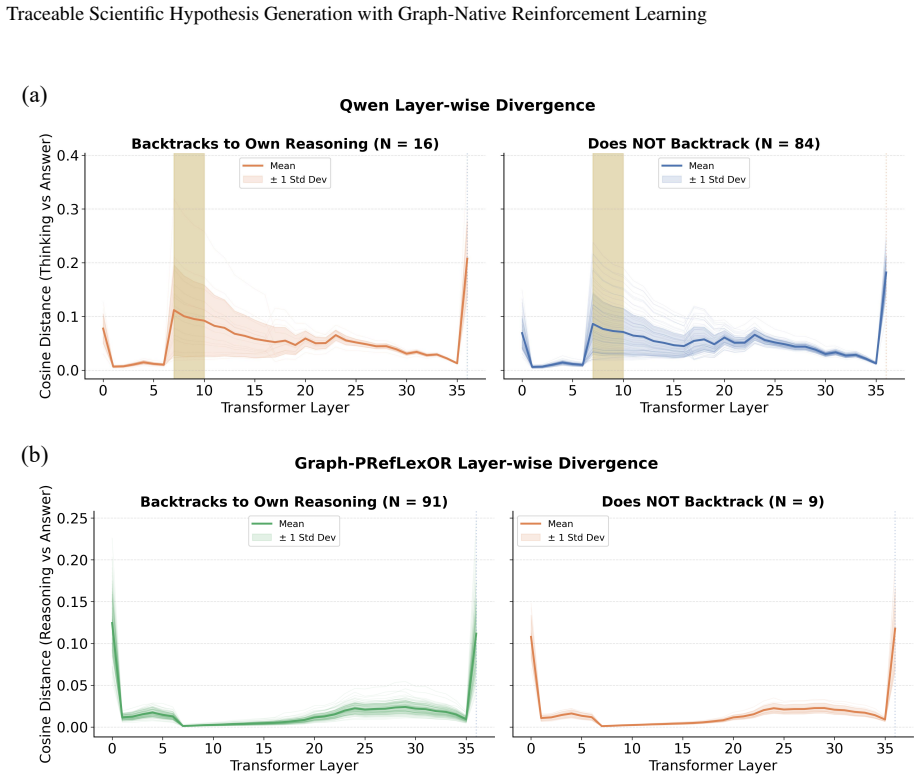
- Hidden-state analyses show tighter coupling between the phased reasoning layers and the generated answer.
Where Pith is reading between the lines
- The same phased graph structure could be adapted to hypothesis generation in chemistry or biology where causal mechanisms are also central.
- If the graph-construction phase can be made fully automatic from raw text, the method might scale to larger corpora without extra human annotation.
- The bounded semantic space implies the model excels at recombining known concepts but may still require external novelty injection to propose truly paradigm-shifting ideas.
Load-bearing premise
The 100 questions drawn from existing literature are enough to measure scientific validity and that the reported gains in traceability stem specifically from the graph-native phased structure.
What would settle it
An expert panel rates traceability and scientific validity on the same 100 questions for both Graph-PRefLexOR and base models trained to the same compute budget but without the explicit graph-phased structure; if the gap disappears, the central claim is false.
Figures













read the original abstract
Accelerating materials discovery requires AI systems that can generate scientifically valid hypotheses through multi-step, domain-grounded reasoning. Standard large language models often produce fluent but weakly traceable responses to open-ended materials design problems, making it difficult to determine whether final answers are supported by coherent intermediate reasoning. We develop Graph-PRefLexOR, a family of graph-native reasoning models fine-tuned with Group Relative Policy Optimization (GRPO) to organize reasoning into explicit phases for mechanism exploration, graph construction, pattern extraction, and hypothesis synthesis. This design links neural language generation with symbolic relational structure, enabling causal connections to be constructed, inspected, and reused. On 100 open-ended questions from materials science and mechanics literature, Graph-PRefLexOR achieves 40-65% improvements over corresponding base models, with the largest gains in reasoning traceability. Embedding analyses show broader semantic exploration and approximately 2-3 times greater semantic diversity than baselines. Semantic backtracking and layer-wise hidden-state analyses further show stronger alignment between structured reasoning and final answers. Finally, test-time graph expansion reveals that additional compute primarily increases long-range conceptual recombination within a bounded semantic space, rather than simply expanding semantic coverage. These results establish graph-native reinforcement learning as a pathway toward interpretable AI systems for scientific hypothesis generation in materials design and other scientific applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Graph-PRefLexOR, a family of graph-native reasoning models fine-tuned with Group Relative Policy Optimization (GRPO) that structures reasoning into explicit phases (mechanism exploration, graph construction, pattern extraction, hypothesis synthesis) to link neural generation with symbolic relational structure for traceable hypothesis generation in materials science. On 100 open-ended questions from the literature, it claims 40-65% improvements over base models (largest in traceability), ~2-3x greater semantic diversity, stronger reasoning-answer alignment via semantic backtracking and hidden-state analyses, and that test-time graph expansion increases long-range recombination within a bounded space.
Significance. If the performance gains can be shown to arise specifically from the graph-native phased structure (rather than GRPO, data curation, or context length), the approach would offer a concrete mechanism for improving interpretability and traceability in LLM-based scientific reasoning, with potential applicability beyond materials design.
major comments (3)
- [Evaluation / Results] Evaluation section (100-question benchmark): the headline 40-65% gains and traceability improvements are reported without ablations that hold training data, compute budget, and base model fixed while removing only the graph-construction / symbolic-recombination components; comparisons appear limited to 'corresponding base models' without non-graph GRPO or standard SFT controls, so it is impossible to attribute gains to the graph-native structure as claimed.
- [Methods] Methods / Experimental setup: no definition is provided for how 'reasoning traceability' was quantified (e.g., the precise metric, inter-annotator protocol, or automated proxy used for the largest reported gains), nor are statistical tests or question-selection criteria described, leaving the central performance claims without visible supporting evidence.
- [Semantic analyses] § on semantic analyses: the claims of 'broader semantic exploration' and 'approximately 2-3 times greater semantic diversity' rest on embedding analyses whose construction (distance metric, embedding model, normalization) is not specified, preventing verification that these quantities are independent of the training process itself.
minor comments (2)
- [Abstract] Abstract and introduction use 'traceable' and 'interpretable' interchangeably without a crisp operational distinction.
- [Figures] Figure captions for the layer-wise hidden-state and test-time expansion plots should explicitly state the number of runs and error bars.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and empirical rigor.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation section (100-question benchmark): the headline 40-65% gains and traceability improvements are reported without ablations that hold training data, compute budget, and base model fixed while removing only the graph-construction / symbolic-recombination components; comparisons appear limited to 'corresponding base models' without non-graph GRPO or standard SFT controls, so it is impossible to attribute gains to the graph-native structure as claimed.
Authors: We agree that the current comparisons to base models do not fully isolate the graph-construction and symbolic-recombination components from GRPO or data effects. To strengthen attribution, we will add the requested ablations in the revision, holding training data, compute budget, and base model fixed while including non-graph GRPO and standard SFT controls. revision: yes
-
Referee: [Methods] Methods / Experimental setup: no definition is provided for how 'reasoning traceability' was quantified (e.g., the precise metric, inter-annotator protocol, or automated proxy used for the largest reported gains), nor are statistical tests or question-selection criteria described, leaving the central performance claims without visible supporting evidence.
Authors: We will expand the Methods section in the revision to define the reasoning traceability metric (including the automated proxy and human validation protocol with inter-annotator agreement), report the statistical tests used, and detail the question-selection criteria from the literature. revision: yes
-
Referee: [Semantic analyses] § on semantic analyses: the claims of 'broader semantic exploration' and 'approximately 2-3 times greater semantic diversity' rest on embedding analyses whose construction (distance metric, embedding model, normalization) is not specified, preventing verification that these quantities are independent of the training process itself.
Authors: We will specify the full construction of the embedding analyses in the revision, including the embedding model, distance metric, normalization steps, and controls to confirm independence from the training process. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The abstract and provided text describe an empirical method (Graph-PRefLexOR with GRPO) and report performance gains on an external benchmark of 100 literature questions. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations are present that would reduce the claimed improvements to quantities defined by the training process itself. The evaluation is presented as an independent test set, making the result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=
Real-time segmentation of on-line handwritten arabic script , author=. Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=. 2014 , organization=
2014
-
[2]
Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=
Fast classification of handwritten on-line Arabic characters , author=. Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=. 2014 , organization=
2014
-
[3]
Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks with Existing Applications , author=. arXiv preprint arXiv:1804.09028 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Advanced Intelligent Discovery , author =
In. Advanced Intelligent Discovery , author =. 2025 , pages =. doi:10.1002/aidi.202500006 , abstract =
-
[5]
Buehler, Markus J. , month = may, year =. npj Artificial Intelligence , publisher =. doi:10.1038/s44387-025-00003-z , abstract =
-
[6]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388
-
[7]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , month = apr, year =. doi:10.48550/arXiv.2402.03300 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300
-
[8]
ACM Computing Surveys , author =
Knowledge. ACM Computing Surveys , author =. 2022 , note =. doi:10.1145/3447772 , abstract =
-
[9]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , month = dec, year =. Judging. doi:10.48550/arXiv.2306.05685 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685
-
[10]
Vera, Henrique Schechter and Dua, Sahil and Zhang, Biao and Salz, Daniel and Mullins, Ryan and Panyam, Sindhu Raghuram and Smoot, Sara and Naim, Iftekhar and Zou, Joe and Chen, Feiyang and Cer, Daniel and Lisak, Alice and Choi, Min and Gonzalez, Lucas and Sanseviero, Omar and Cameron, Glenn and Ballantyne, Ian and Black, Kat and Chen, Kaifeng and Wang, We...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.20354
-
[11]
WIREs Computational Statistics , author =
Principal component analysis , volume =. WIREs Computational Statistics , author =. 2010 , note =. doi:10.1002/wics.101 , abstract =
-
[12]
Scott, David W. , editor =. Multivariate. Handbook of. 2012 , keywords =. doi:10.1007/978-3-642-21551-3_19 , abstract =
-
[13]
2025 , howpublished =
Marker: Convert PDF to Markdown, JSON, and HTML , author =. 2025 , howpublished =
2025
-
[14]
2024 , howpublished =
GPT-4o mini Model , author =. 2024 , howpublished =
2024
-
[15]
2026 , howpublished =
GPT-5.5 Model , author =. 2026 , howpublished =
2026
-
[16]
Wang, Hanchen and Fu, Tianfan and Du, Yuanqi and Gao, Wenhao and Huang, Kexin and Liu, Ziming and Chandak, Payal and Liu, Shengchao and Van Katwyk, Peter and Deac, Andreea and Anandkumar, Anima and Bergen, Karianne and Gomes, Carla P. and Ho, Shirley and Kohli, Pushmeet and Lasenby, Joan and Leskovec, Jure and Liu, Tie-Yan and Manrai, Arjun and Marks, Deb...
-
[17]
Buehler, Markus J , month = sep, year =. Accelerating scientific discovery with generative knowledge extraction, graph-based representation, and multimodal intelligent graph reasoning , volume =. Machine Learning: Science and Technology , publisher =. doi:10.1088/2632-2153/ad7228 , abstract =
-
[18]
and Kanhaiya, Krishan and Bockstaller, Michael R
Nepal, Dhriti and Kang, Saewon and Adstedt, Katarina M. and Kanhaiya, Krishan and Bockstaller, Michael R. and Brinson, L. Catherine and Buehler, Markus J. and Coveney, Peter V. and Dayal, Kaushik and El-Awady, Jaafar A. and Henderson, Luke C. and Kaplan, David L. and Keten, Sinan and Kotov, Nicholas A. and Schatz, George C. and Vignolini, Silvia and Vollr...
-
[19]
Wegst, Ulrike G. K. and Bai, Hao and Saiz, Eduardo and Tomsia, Antoni P. and Ritchie, Robert O. , month = jan, year =. Bioinspired structural materials , volume =. Nature Materials , publisher =. doi:10.1038/nmat4089 , abstract =
-
[20]
, year =
Swanson, Don R. , year =. Undiscovered. The Library Quarterly: Information, Community, Policy , publisher =
-
[21]
Attention is
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, Ł ukasz and Polosukhin, Illia , year =. Attention is. Advances in
-
[22]
Advances in Neural Information Processing Systems , author =
Language. Advances in Neural Information Processing Systems , author =. 2020 , pages =
2020
-
[23]
Zhao, Wayne Xin and Zhou, Kun and Li, Junyi and Tang, Tianyi and Wang, Xiaolei and Hou, Yupeng and Min, Yingqian and Zhang, Beichen and Zhang, Junjie and Dong, Zican and Du, Yifan and Yang, Chen and Chen, Yushuo and Chen, Zhipeng and Jiang, Jinhao and Ren, Ruiyang and Li, Yifan and Tang, Xinyu and Liu, Zikang and Liu, Peiyu and Nie, Jian-Yun and Wen, Ji-R...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.18223
-
[24]
Zhang, Yanbo and Khan, Sumeer A. and Mahmud, Adnan and Yang, Huck and Lavin, Alexander and Levin, Michael and Frey, Jeremy and Dunnmon, Jared and Evans, James and Bundy, Alan and Dzeroski, Saso and Tegner, Jesper and Zenil, Hector , month = aug, year =. Exploring the role of large language models in the scientific method: from hypothesis to discovery , vo...
-
[25]
Advanced Science , author =. 2024 , pages =. doi:10.1002/advs.202306724 , abstract =
-
[26]
Ghafarollahi, A. and Buehler, M. J. , month = jan, year =. doi:10.48550/arXiv.2402.04268 , abstract =
-
[27]
Lu, Chris and Lu, Cong and Lange, Robert Tjarko and Foerster, Jakob and Clune, Jeff and Ha, David , month = sep, year =. The. doi:10.48550/arXiv.2408.06292 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.06292
-
[28]
Hage, Tarjei Paule and Buehler, Markus J. , month = mar, year =. doi:10.48550/arXiv.2603.04124 , abstract =
-
[29]
doi:10.1115/1.4063843 , abstract =
Applied Mechanics Reviews , author =. doi:10.1115/1.4063843 , abstract =
-
[30]
Journal of the Mechanics and Physics of Solids , author =. 2023 , keywords =. doi:10.1016/j.jmps.2023.105454 , abstract =
-
[31]
Advanced Materials , author =. 2025 , pages =. doi:10.1002/adma.202413523 , abstract =
-
[32]
Ghafarollahi, Alireza and Buehler, Markus J. , month = apr, year =. Sparks:. doi:10.48550/arXiv.2504.19017 , abstract =
-
[33]
Advances in Neural Information Processing Systems , author =
Chain-of-. Advances in Neural Information Processing Systems , author =. 2022 , pages =
2022
-
[34]
doi:10.1088/3050-287X/ae61d1 , abstract =
AI for Science , author =. doi:10.1088/3050-287X/ae61d1 , abstract =
-
[36]
and Hage, Tarjei Paule and Hsu, Yu-Chuan and Buehler, Markus J
Stewart, Isabella A. and Hage, Tarjei Paule and Hsu, Yu-Chuan and Buehler, Markus J. , month = feb, year =. doi:10.48550/arXiv.2602.07491 , abstract =
-
[37]
Retrieval-
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and Küttler, Heinrich and Lewis, Mike and Yih, Wen-tau and Rocktäschel, Tim and Riedel, Sebastian and Kiela, Douwe , year =. Retrieval-. Advances in
-
[38]
and Marom, Lee and Pal, Subhadeep and Luu, Rachel K
Wang, Fiona Y. and Marom, Lee and Pal, Subhadeep and Luu, Rachel K. and Lu, Wei and Berkovich, Jaime A. and Buehler, Markus J. , month = mar, year =. Autonomous. doi:10.48550/arXiv.2603.14312 , abstract =
-
[39]
Venugopal, Vineeth and Olivetti, Elsa , month = feb, year =. Scientific Data , publisher =. doi:10.1038/s41597-024-03039-z , abstract =
-
[40]
Ghafarollahi, Alireza and Buehler, Markus J. , month = jan, year =. Automating alloy design and discovery with physics-aware multimodal multiagent. Proceedings of the National Academy of Sciences , publisher =. doi:10.1073/pnas.2414074122 , abstract =
-
[41]
Rapid and automated alloy design with graph neural network-powered large language model-driven multi-agent. MRS Bulletin , author =. 2025 , keywords =. doi:10.1557/s43577-025-00953-4 , abstract =
-
[42]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Yunfan and Xiong, Yun and Gao, Xinyu and Jia, Kangxiang and Pan, Jinliu and Bi, Yuxi and Dai, Yi and Sun, Jiawei and Wang, Meng and Wang, Haofen , month = mar, year =. Retrieval-. doi:10.48550/arXiv.2312.10997 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997
-
[43]
IEEE Transactions on Knowledge and Data Engineering , author =
Unifying. IEEE Transactions on Knowledge and Data Engineering , author =. 2024 , keywords =. doi:10.1109/TKDE.2024.3352100 , abstract =
-
[44]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting Latent Predictions from Transformers with the Tuned Lens. arXiv e-prints , keywords =. doi:10.48550/arXiv.2303.08112 , archivePrefix =. 2303.08112 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08112
-
[45]
How to use and interpret activation patching
How to use and interpret activation patching. arXiv e-prints , keywords =. doi:10.48550/arXiv.2404.15255 , archivePrefix =. 2404.15255 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.15255
-
[46]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv e-prints , keywords =. doi:10.48550/arXiv.2201.11903 , archivePrefix =. 2201.11903 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903
-
[47]
Measuring Faithfulness in Chain-of-Thought Reasoning
Measuring Faithfulness in Chain-of-Thought Reasoning. arXiv e-prints , keywords =. doi:10.48550/arXiv.2307.13702 , archivePrefix =. 2307.13702 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.13702
-
[48]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv e-prints , keywords =. doi:10.48550/arXiv.1908.10084 , archivePrefix =. 1908.10084 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1908.10084 1908
-
[49]
MTEB: Massive Text Embedding Benchmark
MTEB: Massive Text Embedding Benchmark. arXiv e-prints , keywords =. doi:10.48550/arXiv.2210.07316 , archivePrefix =. 2210.07316 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.07316
-
[50]
Right for the Right Reasons: Training Differentiable Models by Constraining their Explanations
Right for the Right Reasons: Training Differentiable Models by Constraining their Explanations. arXiv e-prints , keywords =. doi:10.48550/arXiv.1703.03717 , archivePrefix =. 1703.03717 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1703.03717
-
[51]
Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning. arXiv e-prints , keywords =. doi:10.48550/arXiv.2402.13950 , archivePrefix =. 2402.13950 , primaryClass =
-
[52]
A Primer in BERTology: What we know about how BERT works. arXiv e-prints , keywords =. doi:10.48550/arXiv.2002.12327 , archivePrefix =. 2002.12327 , primaryClass =
-
[53]
What Does BERT Look At? An Analysis of BERT's Attention
What Does BERT Look At? An Analysis of BERT's Attention. arXiv e-prints , keywords =. doi:10.48550/arXiv.1906.04341 , archivePrefix =. 1906.04341 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.04341 1906
-
[54]
BERT Rediscovers the Classical NLP Pipeline. arXiv e-prints , keywords =. doi:10.48550/arXiv.1905.05950 , archivePrefix =. 1905.05950 , primaryClass =
-
[55]
SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability. arXiv e-prints , keywords =. doi:10.48550/arXiv.1706.05806 , archivePrefix =. 1706.05806 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.05806
-
[56]
Similarity of Neural Network Representations Revisited
Similarity of Neural Network Representations Revisited. arXiv e-prints , keywords =. doi:10.48550/arXiv.1905.00414 , archivePrefix =. 1905.00414 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1905.00414 1905
-
[57]
LogitLens4LLMs: Extending Logit Lens Analysis to Modern Large Language Models. arXiv e-prints , keywords =. doi:10.48550/arXiv.2503.11667 , archivePrefix =. 2503.11667 , primaryClass =
-
[58]
Towards Automated Circuit Discovery for Mechanistic Interpretability. arXiv e-prints , keywords =. doi:10.48550/arXiv.2304.14997 , archivePrefix =. 2304.14997 , primaryClass =
-
[59]
On the Hardness of Faithful Chain-of-Thought Reasoning in Large Language Models. arXiv e-prints , keywords =. doi:10.48550/arXiv.2406.10625 , archivePrefix =. 2406.10625 , primaryClass =
-
[60]
Understanding intermediate layers using linear classifier probes
Understanding intermediate layers using linear classifier probes. arXiv e-prints , keywords =. doi:10.48550/arXiv.1610.01644 , archivePrefix =. 1610.01644 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1610.01644
-
[61]
Analysis Methods in Neural Language Processing: A Survey
Analysis Methods in Neural Language Processing: A Survey. arXiv e-prints , keywords =. doi:10.48550/arXiv.1812.08951 , archivePrefix =. 1812.08951 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1812.08951
-
[62]
2023 , eprint=
C-Pack: Packaged Resources To Advance General Chinese Embedding , author=. 2023 , eprint=
2023
-
[63]
C-Pack: Packed Resources For General Chinese Embeddings
C-Pack: Packed Resources For General Chinese Embeddings. arXiv e-prints , keywords =. doi:10.48550/arXiv.2309.07597 , archivePrefix =. 2309.07597 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.07597
-
[64]
2024 , eprint=
ORPO: Monolithic Preference Optimization without Reference Model , author=. 2024 , eprint=
2024
-
[65]
Proceedings of the 29th Symposium on Operating Systems Principles (SOSP) , year =
Efficient Memory Management for Large Language Model Serving with PagedAttention , author =. Proceedings of the 29th Symposium on Operating Systems Principles (SOSP) , year =
-
[66]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
-
[67]
2019 , eprint=
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. 2019 , eprint=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.