Staleness-Learning Rate Scaling Laws for Asynchronous RLHF
Pith reviewed 2026-07-02 15:45 UTC · model grok-4.3
The pith
Stale rollouts create a per-step surrogate gradient bias of order S times eta in asynchronous RLHF.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
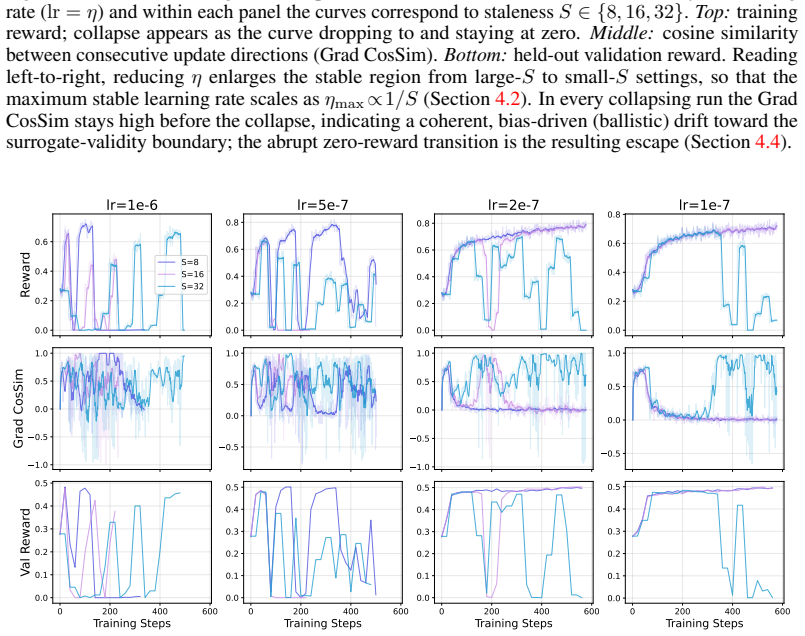
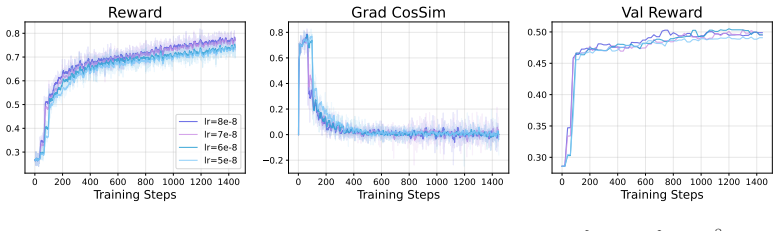
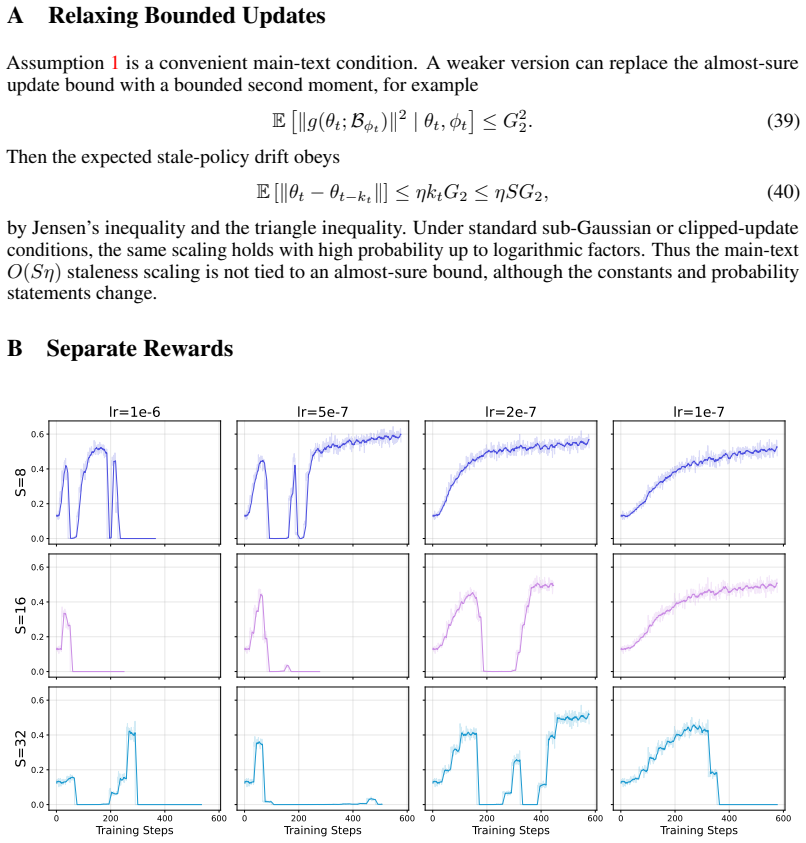
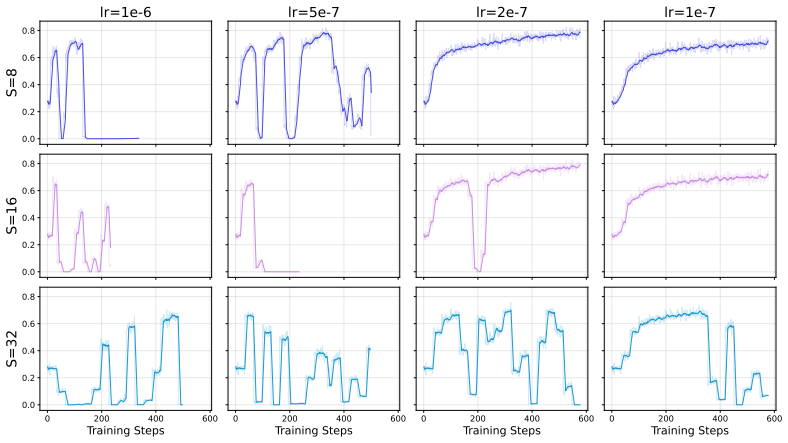
Under local boundedness, distributional smoothness, and behavior-policy smoothness, stale rollouts introduce a per-step surrogate-gradient bias of order O(S * eta), where S denotes the maximum rollout lag and eta denotes the learning rate. We further derive a conditional collapse-time scaling law that yields the stability condition eta << min{R_batch / (S * G_upd), R_crit / (T * G_upd)}, explaining why the maximum stable learning rate may appear weakly dependent on staleness in the horizon-limited regime.
What carries the argument
The O(S * eta) per-step surrogate-gradient bias arising from the difference between the learner's mapping and the true total derivative when rollouts are lagged by S steps.
If this is right
- Collapse time is governed by T * eta when within-cycle drift is below the batch clipping radius.
- Stability depends on S * eta when the stale-rollout constraint is active.
- The two-constraint condition allows the max stable eta to be chosen based on the active limit.
Where Pith is reading between the lines
- One could test the scaling by varying the number of parallel workers to change S and measuring collapse thresholds.
- The bias bound might suggest adaptive learning rate schedulers that account for current lag.
- Similar analysis could apply to other decoupled training setups in reinforcement learning.
Load-bearing premise
The distributions of states and actions change smoothly enough with each policy update that the effect of using lagged rollouts produces a bias linear in the lag and learning rate.
What would settle it
An experiment that varies S and eta independently while measuring the surrogate gradient error and the point at which training collapses would confirm or refute the O(S * eta) scaling and the min of the two stability thresholds.
Figures

read the original abstract
High-throughput RLHF systems often decouple rollout generation from policy optimization, leading to the use of stale rollouts during learner updates. In this work, we study the effect of such staleness in asynchronous GRPO. We make the behavior policy explicit in the GRPO surrogate objective and distinguish between the surrogate-gradient mapping used by the learner and the true total derivative of a distribution-dependent population objective. Under assumptions of local boundedness, distributional smoothness, and behavior-policy smoothness, we show that stale rollouts introduce a per-step surrogate-gradient bias of order O(S * eta), where S denotes the maximum rollout lag and eta denotes the learning rate. We further derive a conditional collapse-time scaling law: when within-cycle drift remains below a batch-level clipping radius, collapse is governed primarily by cumulative learner drift T * eta; when the stale-rollout constraint is active, stability instead depends explicitly on S * eta. This yields a two-constraint stability condition eta << min{R_batch / (S * G_upd), R_crit / (T * G_upd)}, explaining why the maximum stable learning rate may appear weakly dependent on staleness in the horizon-limited regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in asynchronous GRPO for RLHF, making the behavior policy explicit in the surrogate and distinguishing it from the true total derivative, stale rollouts induce a per-step surrogate-gradient bias of order O(S * eta) under assumptions of local boundedness, distributional smoothness, and behavior-policy smoothness. It further derives a conditional collapse-time scaling law, yielding the two-constraint stability condition eta << min{R_batch / (S * G_upd), R_crit / (T * G_upd)} that explains apparent weak dependence of the maximum stable learning rate on staleness in the horizon-limited regime.
Significance. If the three smoothness assumptions hold with reasonable constants in the relevant operating regimes, the work supplies a conditional theoretical scaling law that delineates when staleness versus cumulative learner drift governs stability. The explicit conditioning on the assumptions and the derivation directly from the GRPO surrogate (rather than an external fitted model) are strengths that could inform learning-rate selection in high-throughput asynchronous RLHF pipelines.
major comments (1)
- [Abstract] Abstract: the O(S * eta) bias bound and the resulting stability condition are derived under the three smoothness assumptions (local boundedness, distributional smoothness, behavior-policy smoothness), yet the abstract provides no quantification of the hidden constants or the regime in which the assumptions are expected to hold; this is load-bearing for assessing whether the conditional scaling law applies beyond the stated premises.
Simulated Author's Rebuttal
We thank the referee for the detailed reading and the constructive comment on the abstract. The observation is correct: while the abstract states the three smoothness assumptions, it does not indicate the scaling of the hidden constants or the operating regime in which the O(S * eta) bias and the two-constraint stability condition are expected to remain meaningful. We will revise the abstract to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: the O(S * eta) bias bound and the resulting stability condition are derived under the three smoothness assumptions (local boundedness, distributional smoothness, behavior-policy smoothness), yet the abstract provides no quantification of the hidden constants or the regime in which the assumptions are expected to hold; this is load-bearing for assessing whether the conditional scaling law applies beyond the stated premises.
Authors: We agree that the abstract should make the dependence on the hidden constants and the relevant regime more explicit. In the revised manuscript we will append a short clause to the abstract stating that the O(S * eta) bias constant is controlled by the local Lipschitz constants of the distributional and behavior-policy smoothness assumptions, and that the two-constraint stability condition eta << min{R_batch / (S * G_upd), R_crit / (T * G_upd)} is intended for the regime in which per-update drift remains small relative to the batch clipping radius R_batch. This addition will clarify applicability without altering the technical claims. revision: yes
Circularity Check
No significant circularity; derivation conditional on external assumptions
full rationale
The paper starts from the GRPO surrogate objective, makes the behavior policy explicit, and distinguishes the surrogate gradient from the true total derivative. It then invokes three external smoothness assumptions (local boundedness, distributional smoothness, behavior-policy smoothness) to bound the per-step bias as O(S * eta) and derive the two-constraint stability condition eta << min{R_batch / (S * G_upd), R_crit / (T * G_upd)}. No quantity is fitted inside the paper and then relabeled as a prediction; no self-citation chain supplies the load-bearing premises; the result is explicitly conditional rather than self-definitional. The derivation chain therefore remains self-contained once the stated assumptions are granted.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption local boundedness
- domain assumption distributional smoothness
- domain assumption behavior-policy smoothness
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Advances in Neural Information Processing Systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
arXiv preprint arXiv:2312.14925 , year=
A survey of reinforcement learning from human feedback , author=. arXiv preprint arXiv:2312.14925 , year=
-
[4]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Advances in Neural Information Processing Systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advances in Neural Information Processing Systems , volume=
Hogwild!: A lock-free approach to parallelizing stochastic gradient descent , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Advances in Neural Information Processing Systems , volume=
Distributed delayed stochastic optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Asynchronous parallel stochastic gradient for nonconvex optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14) , pages=
Scaling distributed machine learning with the parameter server , author=. 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14) , pages=
-
[12]
International Conference on Machine Learning , pages=
Distributed asynchronous optimization with unbounded delays: How slow can you go? , author=. International Conference on Machine Learning , pages=
-
[13]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[14]
Training Compute-Optimal Large Language Models
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
An Empirical Model of Large-Batch Training
An empirical model of large-batch training , author=. arXiv preprint arXiv:1812.06162 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
International Conference on Machine Learning , pages=
Trust region policy optimization , author=. International Conference on Machine Learning , pages=
-
[17]
International Conference on Machine Learning (ICML) , pages=
Asynchronous Methods for Deep Reinforcement Learning , author=. International Conference on Machine Learning (ICML) , pages=
-
[18]
Massively Parallel Methods for Deep Reinforcement Learning
Massively Parallel Methods for Deep Reinforcement Learning , author=. arXiv preprint arXiv:1507.04296 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Espeholt, Lasse and Soyer, Hubert and Munos, Remi and Simonyan, Karen and Mnih, Vlad and Ward, Tom and Doron, Yotam and Firoiu, Vlad and Harley, Tim and Dunning, Iain and Legg, Shane and Kavukcuoglu, Koray , booktitle=
-
[20]
International Conference on Learning Representations (ICLR) , year=
Distributed Prioritized Experience Replay , author=. International Conference on Learning Representations (ICLR) , year=
-
[21]
International Conference on Learning Representations (ICLR) , year=
Espeholt, Lasse and Marinier, Rapha. International Conference on Learning Representations (ICLR) , year=
-
[22]
International Conference on Learning Representations (ICLR) , year=
DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames , author=. International Conference on Learning Representations (ICLR) , year=
-
[23]
arXiv preprint arXiv:2310.00036 , year=
Cleanba: A Reproducible and Efficient Distributed Reinforcement Learning Platform , author=. arXiv preprint arXiv:2310.00036 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.