FurnitureVLA: Learning Long-Horizon Bimanual Furniture Assembly with Vision-Language-Action Model
Pith reviewed 2026-07-02 10:47 UTC · model grok-4.3
The pith
A vision-language-action model that jointly predicts actions and progress reaches 80 percent success on long-horizon bimanual furniture assembly
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
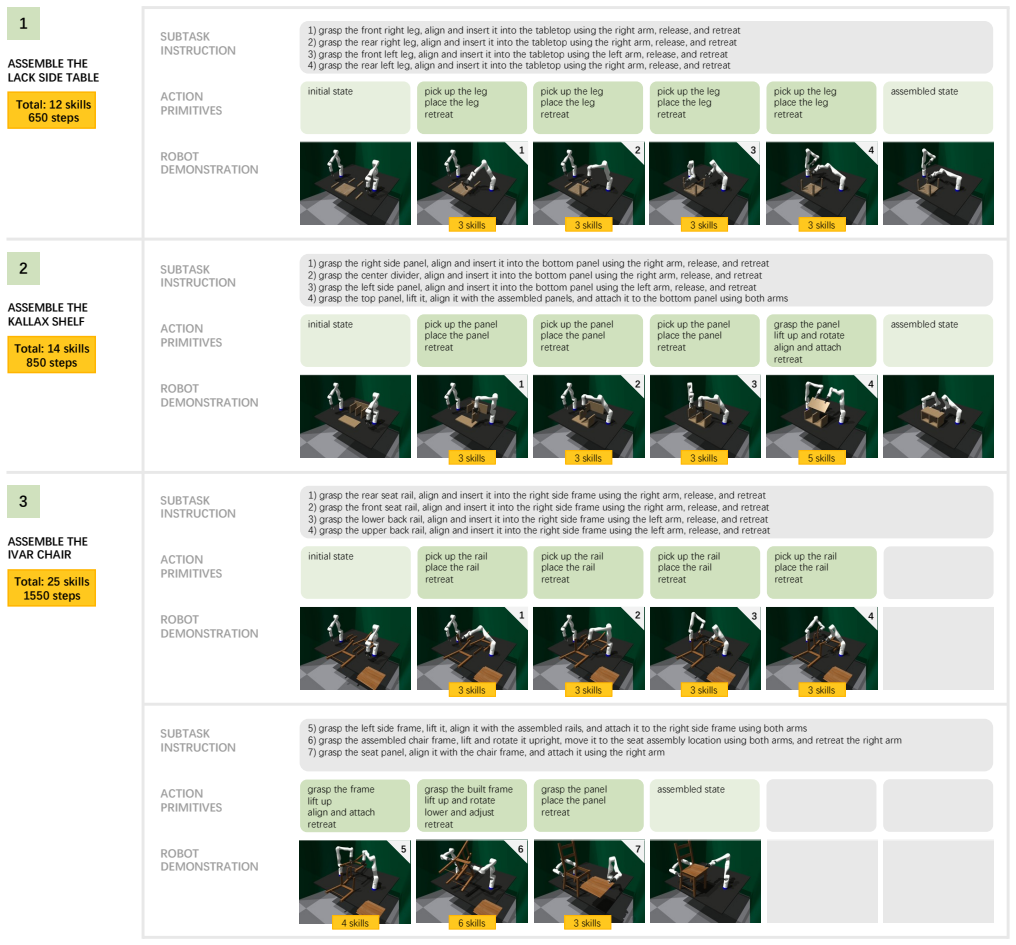
Finetuning a vision-language-action model on semantically grounded subtasks to jointly predict robot actions and a continuous progress signal allows automatic subtask transitions and reduces compounding errors during inference. The resulting system handles extreme long-horizon assembly with up to seven subtasks and 1550 control steps. It achieves 80 percent average simulation success across three furniture types, up from 48 percent for baselines, plus an extra 21 percent gain from perception and control design choices, and transfers to a real dual-arm Kinova Gen3 platform with only a 16 percent performance drop on the most difficult task.
What carries the argument
progress-enhanced VLA finetuned to jointly output actions and a continuous progress signal for each semantically grounded subtask
If this is right
- Automatic subtask transitions occur without separate segmentation or handoff logic.
- Compounding errors are reduced across sequences of up to 1550 control steps.
- Average simulation success reaches 80 percent across three different furniture types.
- Studied perception and control design factors deliver an additional 21 percent performance gain.
- Real-world transfer to the Kinova Gen3 platform incurs only a 16 percent drop on the hardest task.
Where Pith is reading between the lines
- The same joint action-plus-progress prediction could support recovery behaviors when small execution errors occur.
- The VR single-operator collection method may scale to gather data for other long-horizon bimanual tasks.
- Defining analogous progress signals for different domains could extend the approach beyond furniture assembly.
Load-bearing premise
The simulation pipeline and VR-collected demonstrations produce data whose distribution is close enough to real Kinova Gen3 execution that sim-to-real transfer remains reliable even after 1550 control steps.
What would settle it
Execute the trained model on the physical Kinova Gen3 robot for a complete furniture assembly sequence exceeding 1550 steps while introducing small visual or positional perturbations and check whether success on the hardest task falls below 64 percent.
Figures







read the original abstract
Current work on robot furniture assembly mostly focuses on toy-scale settings or single-arm manipulation. We introduce FurnitureVLA, the first systematic study of real-scale bimanual furniture assembly using Vision-Language-Action models (VLAs). We formalize the task, develop a scalable simulation pipeline for expert data generation and evaluation, and build a VR teleoperation system for single-operator bimanual control to collect high-quality real-world demonstrations. To address extreme long-horizon assembly with up to 7 subtasks and 1550 control steps, we propose a progress-enhanced VLA, finetuned on semantically grounded subtasks, that jointly predicts actions and a continuous progress signal, enabling automatic subtask transitions and reducing compounding errors during inference. We further study perception and control design factors that critically affect precision in real-scale assembly. FurnitureVLA improves average simulation success from 48% to 80% compared to baselines across three furniture types, with an additional 21% gain from our design factor study. We validate on a real Kinova Gen3 platform with only 16% drop on the hardest task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FurnitureVLA as the first systematic study of real-scale bimanual furniture assembly with VLAs. It formalizes the task (up to 7 subtasks, 1550 steps), builds a scalable sim pipeline and VR teleoperation system for data collection, and proposes a progress-enhanced VLA finetuned on semantically grounded subtasks that jointly predicts actions and a continuous progress signal to enable automatic transitions and reduce compounding errors. It reports average simulation success rising from 48% to 80% across three furniture types (plus 21% from design-factor study) and validates on a real Kinova Gen3 with a 16% drop on the hardest task.
Significance. If the reported gains and sim-to-real transfer hold under rigorous evaluation, the work would be significant as one of the first demonstrations of VLAs scaling to long-horizon, real-scale bimanual assembly with hardware validation. The joint action+progress formulation and design-factor analysis address practical challenges in compounding errors and precision that are load-bearing for this domain.
major comments (2)
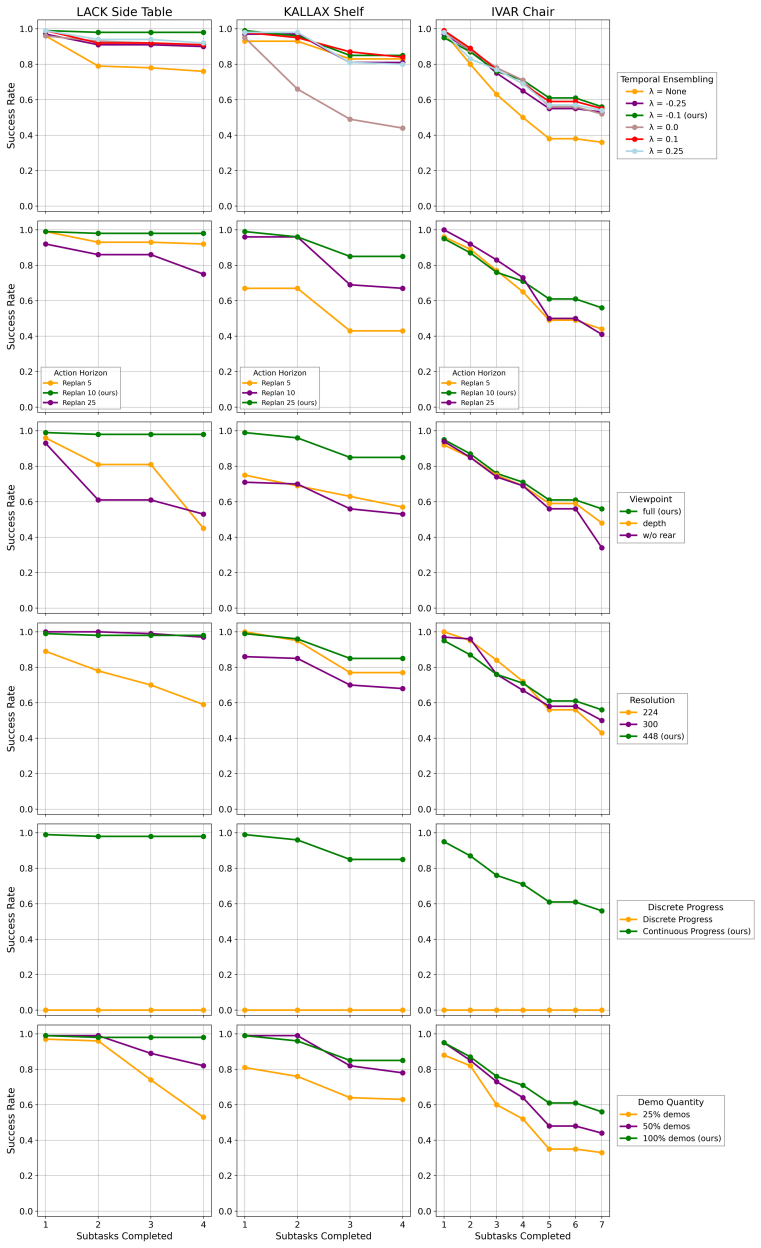
- [Abstract] Abstract: the central empirical claim (48% o 80% simulation success, 16% real drop) is presented without error bars, trial counts, baseline implementation details, data volumes, or ablation numbers isolating the progress signal's contribution; this prevents assessment of whether the result is robust or sensitive to post-hoc choices.
- [Abstract] Abstract (real-robot validation paragraph): the claim that sim-to-real transfer remains reliable after 1550 steps rests on the unquantified assumption that VR demonstrations and the simulation pipeline produce trajectories whose state, visual, and dynamics distributions match real Kinova Gen3 execution; no alignment metrics (state visitation divergence, progress-signal calibration error, or failure-mode breakdown) are supplied to support this.
minor comments (1)
- [Abstract] The abstract states 'an additional 21% gain from our design factor study' without indicating whether this is additive to the 80% or measured separately; clarify the exact comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that greater transparency on experimental details would strengthen the presentation and will revise the abstract accordingly while preserving its conciseness. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (48% o 80% simulation success, 16% real drop) is presented without error bars, trial counts, baseline implementation details, data volumes, or ablation numbers isolating the progress signal's contribution; this prevents assessment of whether the result is robust or sensitive to post-hoc choices.
Authors: The abstract is intentionally concise, but we acknowledge that key statistics would aid immediate assessment. The full manuscript reports these details in Section 4 (Experiments): error bars and trial counts (50 independent trials per furniture type), data volumes (Section 3.2), baseline implementations (Section 3), and ablations isolating the progress signal (Section 4.3, showing its isolated contribution). We will revise the abstract to include a brief qualifier such as "across 50 trials per task (with standard error)" and a parenthetical note on the ablation results. Full baseline code and hyperparameter details remain in the methods section due to space limits. revision: yes
-
Referee: [Abstract] Abstract (real-robot validation paragraph): the claim that sim-to-real transfer remains reliable after 1550 steps rests on the unquantified assumption that VR demonstrations and the simulation pipeline produce trajectories whose state, visual, and dynamics distributions match real Kinova Gen3 execution; no alignment metrics (state visitation divergence, progress-signal calibration error, or failure-mode breakdown) are supplied to support this.
Authors: Sections 3.1–3.2 describe the VR teleoperation and simulation pipeline explicitly engineered to match the Kinova Gen3 kinematics, visuals, and control interface. The primary evidence of transfer is the reported 16% performance drop on the hardest task (Section 4.4), which includes qualitative failure-mode analysis. We do not currently supply quantitative alignment metrics such as state visitation divergence or progress-signal calibration error. We will revise the abstract and/or real-robot subsection to explicitly acknowledge this assumption and add a short discussion of the design choices that support distributional similarity. Adding new quantitative metrics would require additional post-hoc analysis of existing trajectories. revision: partial
Circularity Check
No circularity: empirical VLA performance lift is self-contained
full rationale
The paper reports an empirical improvement (48% to 80% simulation success) from a progress-enhanced VLA trained on VR demonstrations and evaluated in simulation plus real hardware. No equations, fitted parameters, or derivation chain are presented that reduce a claimed prediction to its own inputs by construction. The central result is a measured performance delta on held-out tasks rather than a self-referential mathematical claim, and no load-bearing self-citation or uniqueness theorem is invoked in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation,
M. Heo, Y . Lee, D. Lee, and J. J. Lim, “Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation,” in Robotics: Science and Systems, 2023
2023
-
[2]
Generalize by touching: Tactile ensemble skill transfer for robotic furniture assembly,
H. Lin, R. Corcodel, and D. Zhao, “Generalize by touching: Tactile ensemble skill transfer for robotic furniture assembly,” inInternational Conference on Robotics and Automation, 2024
2024
-
[3]
JUICER: data- efficient imitation learning for robotic assembly,
L. Ankile, A. Simeonov, I. Shenfeld, and P. Agrawal, “JUICER: data- efficient imitation learning for robotic assembly,” inInternational Conference on Intelligent Robots and Systems, 2024
2024
-
[4]
Fabrica: Dual-arm assembly of general multi-part objects via integrated planning and learning,
Y . Tian, J. Jacob, Y . Huang, J. Zhao, E. Gu, P. Ma, A. Zhang, F. Javid, B. Romero, S. Chittaet al., “Fabrica: Dual-arm assembly of general multi-part objects via integrated planning and learning,” inConference on Robot Learning, 2025
2025
-
[5]
Efficient sim-to-real transfer of contact-rich manipulation skills with online admittance residual learning,
X. Zhang, C. Wang, L. Sun, Z. Wu, X. Zhu, and M. Tomizuka, “Efficient sim-to-real transfer of contact-rich manipulation skills with online admittance residual learning,” inConference on Robot Learning, 2023
2023
-
[6]
From imitation to refinement - residual rl for precise assembly,
L. Ankile, A. Simeonov, I. Shenfeld, M. Torne, and P. Agrawal, “From imitation to refinement - residual rl for precise assembly,” in International Conference on Robotics and Automation, 2025
2025
-
[7]
FORGE: force-guided exploration for robust contact-rich manipulation under uncertainty,
M. Noseworthy, B. Tang, B. Wen, A. Handa, C. C. Kessens, N. Roy, D. Fox, F. Ramos, Y . Narang, and I. Akinola, “FORGE: force-guided exploration for robust contact-rich manipulation under uncertainty,” Robotics and Automation Letters, 2025
2025
-
[8]
Vt-refine: Learning bimanual assembly with visuo-tactile feedback via simulation fine-tuning,
B. Huang, J. Xu, I. Akinola, W. Yang, B. Sundaralingam, R. O’Flaherty, D. Fox, X. Wang, A. Mousavian, Y . Chao, and Y . Li, “Vt-refine: Learning bimanual assembly with visuo-tactile feedback via simulation fine-tuning,” inConference on Robot Learning, 2025
2025
-
[9]
Mobile ALOHA: learning bimanual mobile manipulation using low-cost whole-body teleoperation,
Z. Fu, T. Z. Zhao, and C. Finn, “Mobile ALOHA: learning bimanual mobile manipulation using low-cost whole-body teleoperation,” in Conference on Robot Learning, 2024
2024
-
[10]
Robot- mover: Learning to move large objects from human demonstrations,
T. Li, J. Truong, J. Yang, A. Clegg, A. Rai, S. Ha, and X. Puig, “Robot- mover: Learning to move large objects from human demonstrations,” arXiv preprint arXiv:2502.05271, 2025
-
[11]
Openvla: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,” inConference on Robot Learning, 2024
2024
-
[12]
Gen-0: Embodied foundation models that scale with physical interaction,
Generalist AI Team, “Gen-0: Embodied foundation models that scale with physical interaction,” https://generalistai.com/blog/ nov-04-2025-GEN-0, 2025
2025
-
[13]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. J. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” in International Conference on Artificial Intelligence and Statistics, 2011
2011
-
[14]
BOSS: benchmark for observation space shift in long-horizon task,
Y . Yang, L. Zhao, M. Ding, G. Bertasius, and D. Szafir, “BOSS: benchmark for observation space shift in long-horizon task,”Robotics and Automation Letters, 2025
2025
-
[15]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inRobotics: Science and Systems, 2023
2023
-
[16]
Can robots assemble an IKEA chair?
X. Zhou and Q. Pham, “Can robots assemble an IKEA chair?”Science Robotics, 2018
2018
-
[17]
Manual2skill: Learning to read manuals and acquire robotic skills for furniture assembly using vision-language models,
C. Tie, S. Sun, J. Zhu, Y . Liu, J. Guo, Y . Hu, H. Chen, J. Chen, R. Wu, and L. Shao, “Manual2skill: Learning to read manuals and acquire robotic skills for furniture assembly using vision-language models,” in Robotics: Science and Systems, 2025
2025
-
[18]
Spatialpin: Enhancing spatial reasoning capabilities of vision-language models through prompting and interacting 3d priors,
C. Ma, K. Lu, T.-Y . Cheng, N. Trigoni, and A. Markham, “Spatialpin: Enhancing spatial reasoning capabilities of vision-language models through prompting and interacting 3d priors,” inNeural Information Processing Systems, 2024
2024
-
[19]
IKEA furniture assembly environ- ment for long-horizon complex manipulation tasks,
Y . Lee, E. S. Hu, and J. J. Lim, “IKEA furniture assembly environ- ment for long-horizon complex manipulation tasks,” inInternational Conference on Robotics and Automation, 2021
2021
-
[20]
Industreal: Transferring contact-rich assembly tasks from simulation to reality,
B. Tang, M. A. Lin, I. Akinola, A. Handa, G. S. Sukhatme, F. Ramos, D. Fox, and Y . Narang, “Industreal: Transferring contact-rich assembly tasks from simulation to reality,” inRobotics: Science and Systems, 2023
2023
-
[21]
DECAF: a discrete-event based collaborative human-robot framework for furniture assembly,
G. Giacomuzzo, M. Terreran, S. Jain, and D. Romeres, “DECAF: a discrete-event based collaborative human-robot framework for furniture assembly,” inInternational Conference on Intelligent Robots and Systems, 2024
2024
-
[22]
Arch: Hierarchical hybrid learning for long-horizon contact-rich robotic assembly,
J. Sun, A. Curtis, Y . You, Y . Xu, M. Koehle, Q. Chen, S. Huang, L. Guibas, S. Chitta, M. Schwageret al., “Arch: Hierarchical hybrid learning for long-horizon contact-rich robotic assembly,” inConference on Robot Learning, 2025
2025
-
[23]
Coopera: Continual open-ended human-robot assistance,
C. Ma, K. Lu, R. Desai, X. Puig, A. Markham, and N. Trigoni, “Coopera: Continual open-ended human-robot assistance,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[24]
Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation,
Y . Fan, P. Ding, S. Bai, X. Tong, Y . Zhu, H. Lu, F. Dai, W. Zhao, Y . Liu, S. Huang, Z. Fan, B. Chen, and D. Wang, “Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation,” inConference on Robot Learning, 2025
2025
-
[25]
R. Yang, Z. An, L. Zhou, and Y . Feng, “Seqvla: Sequential task execution for long-horizon manipulation with completion-aware vision- language-action model,”arXiv preprint arXiv:2509.14138, 2025
-
[26]
LiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies, 2026
Y . Yang, S. Cheng, Y . Fang, H. Bharadhwaj, M. Ding, G. Bertasius, and D. Szafir, “Lilo-vla: Compositional long-horizon manipulation via linked object-centric policies,”arXiv preprint arXiv:2602.21531, 2026
-
[27]
KitchenVLA: Iterative vision-language corrections for robotic execution of human tasks,
K. Lu, C. Ma, C. Hori, and D. Romeres, “KitchenVLA: Iterative vision-language corrections for robotic execution of human tasks,” inInternational Conference on Robotics and Automation Workshop Safe-VLM, 2025
2025
-
[28]
C. Ma, G. Yang, K. Lu, S. Xu, B. Byrne, N. Trigoni, and A. Markham, “Cyclevla: Proactive self-correcting vision-language-action models via subtask backtracking and minimum bayes risk decoding,”arXiv preprint arXiv:2601.02295, 2026
-
[29]
Robotic control via embodied chain-of-thought reasoning,
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine, “Robotic control via embodied chain-of-thought reasoning,” inConfer- ence on Robot Learning, 2024
2024
-
[30]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, “π0.5: a vision-language-action model with open- world generalization,”arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Hi robot: Open-ended instruction following with hierarchical vision-language-action models,
L. X. Shi, B. Ichter, M. R. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, A. Li-Bell, D. Driess, L. Groom, S. Levine, and C. Finn, “Hi robot: Open-ended instruction following with hierarchical vision-language-action models,” inInternational Conference on Machine Learning, 2025
2025
-
[32]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
GR00T Team, “GR00T N1: an open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Open x-embodiment: Robotic learning datasets and RT-X models : Open x-embodiment collaboration,
Open X-Embodiment Collaboration, “Open x-embodiment: Robotic learning datasets and RT-X models : Open x-embodiment collaboration,” inInternational Conference on Robotics and Automation, 2024
2024
-
[34]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Physical Intelligence, “Fast: Efficient action tokenization for vision- language-action models,”arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Roboarena: Distributed real-world evaluation of generalist robot policies,
P. Atreya, K. Pertsch, T. Lee, M. J. Kim, A. Jain, A. Kuramshin, C. Eppner, C. Neary, E. Hu, F. Ramoset al., “Roboarena: Distributed real-world evaluation of generalist robot policies,” inConference on Robot Learning, 2025
2025
-
[36]
Openpi comet: Competition solution for 2025 behavior challenge,
J. Bai, Y .-W. Chao, Q. Chen, J. Gu, M. J. Kim, Z. Li, X. Li, T.-Y . Lin, M.-Y . Liu, N. Maet al., “Openpi comet: Competition solution for 2025 behavior challenge,”arXiv preprint arXiv:2512.10071, 2025
-
[37]
Screwdriving gripper that mimics human two-handed assembly tasks,
S. Han, M. Choi, Y . Shin, G. Jang, D. Lee, J. Cho, J. Park, and J. Bae, “Screwdriving gripper that mimics human two-handed assembly tasks,” Robotics, 2022
2022
-
[38]
Robotic fastening with a manual screwdriver,
L. Tang and Y . Jia, “Robotic fastening with a manual screwdriver,” in International Conference on Robotics and Automation, 2023
2023
-
[39]
CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard, “CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,”Robotics and Automation Letters, 2022
2022
-
[40]
LIBERO: benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “LIBERO: benchmarking knowledge transfer for lifelong robot learning,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[41]
Robocasa: Large-scale simulation of everyday tasks for generalist robots,
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu, “Robocasa: Large-scale simulation of everyday tasks for generalist robots,” inRobotics: Science and Systems, 2024
2024
-
[42]
Isaac gym: High performance GPU based physics simulation for robot learning,
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State, “Isaac gym: High performance GPU based physics simulation for robot learning,” inNeurIPS Datasets and Benchmarks, 2021
2021
-
[43]
3d warehouse,
3D Warehouse, “3d warehouse,” https://3dwarehouse.sketchup.com/, 2026
2026
-
[44]
ambientcg,
ambientCG, “ambientcg,” https://ambientcg.com/, 2026
2026
-
[45]
Blender,
Blender Foundation, “Blender,” https://www.blender.org, 2025
2025
-
[46]
Quest2ros: An app to facilitate teleoperating robots,
M. C. Welle, N. Ingelhag, M. Lippi, M. Wozniak, A. Gasparri, and D. Kragic, “Quest2ros: An app to facilitate teleoperating robots,” in Workshop on VAM-HRI, 2024
2024
-
[47]
DROID: A large-scale in-the-wild robot manipulation dataset,
DROID Team, “DROID: A large-scale in-the-wild robot manipulation dataset,” inRobotics: Science and Systems, 2024. Appendix forFurnitureVLA LACK Side Table KALLAX Shelf IVAR Chair 1234 5 1234 5 1234 5 6 7
2024
-
[48]
Front right leg: 3.0 × 24.0 × 3.0 2) Rear right leg: 3.0 × 24.0 × 3.0 3) Front left leg: 3.0 × 24.0 × 3.0 4) Rear left leg: 3.0 × 24.0 × 3.0 5) Tabletop (base part): 33.0 × 33.0 × 3.0
-
[49]
Right side panel: 2.2 × 23.4 × 20.2 2) Center divider: 2.2 × 23.4 × 20.2 3) Left side panel: 2.2 × 23.4 × 20.2 4) Top panel: 45.9 × 2.2 × 23.4 5) Bottom panel (base part): 45.9 × 23.4 × 2.2
-
[50]
8:Furniture part taxonomy and geometric properties
Rear seat rail: 1.2 × 30.0 × 5.8 2) Front seat rail: 1.2 × 30.0 × 5.8 3) Lower back rail: 3.6 × 30.0 × 5.5 4) Upper back rail: 3.6 × 30.0 × 5.5 5) Left side frame: 44.6 × 95.0 × 4.2 6) Seat panel: 36.2 × 40.6 × 1.2 7) Right side frame (stage 1 base part): 44.6 × 95.0 × 4.2 1 234 5 13 24 5 67 435 12 WDHPart Dimensions (W ×D ×H, cm) Fig. 8:Furniture part ta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.