Risk Architecture for AI-Native Engineering Teams: An Organizational Framework for Agentic System Governance
Pith reviewed 2026-07-03 19:06 UTC · model grok-4.3
The pith
AI-native engineering teams suffer degraded risk coverage, with worst gaps at boundaries where probabilistic outputs meet deterministic systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
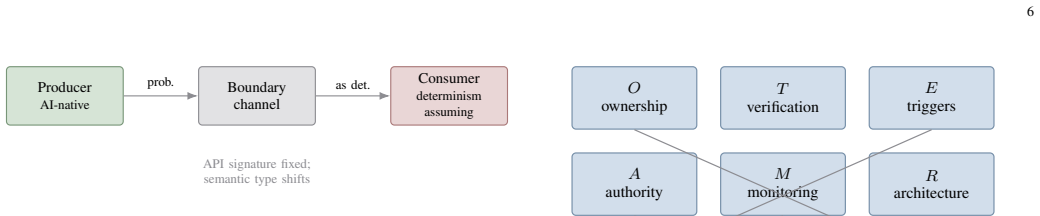
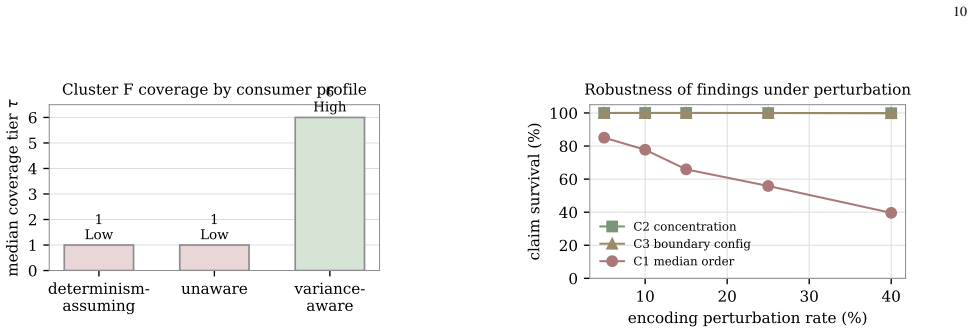
The paper claims that coverage of risk architectures degrades monotonically in the median and abruptly in the count of uncovered high-consequence failures as teams move from pure software engineering to AI-native operation. The most severe, least-covered failures arise at the organizational boundary where probabilistic outputs from agentic systems are consumed by determinism-assuming dependencies. These conclusions rest on a seven-dimension team profile, a six-cluster failure taxonomy, and a synthetic framework-adequacy methodology that scores detection, containment, and escalation performance against a defined scenario set, yielding derived rather than observed coverage claims.
What carries the argument
The seven-dimension profile distinguishing pure software-engineering, hybrid, and AI-native teams, together with the six-cluster failure-mode taxonomy that includes dependency-boundary determinism mismatch and the synthetic framework-adequacy methodology that scores detection, containment, and escalation.
If this is right
- Coverage degrades monotonically from pure software engineering to AI-native operation in median scores.
- Uncovered high-consequence failures increase abruptly only when teams reach the AI-native profile.
- The most severe gaps occur at organizational boundaries where probabilistic outputs meet deterministic dependencies.
- A previously unarticulated failure cluster, dependency-boundary determinism mismatch, accounts for a large share of the uncovered risk.
- The synthetic methodology produces derived coverage claims rather than observed ones for each team profile.
Where Pith is reading between the lines
- Organizations adopting AI-native practices may need to add explicit boundary-mapping roles and escalation paths that treat probabilistic outputs as a distinct input type.
- The framework could be tested by having real engineering teams apply the profiles and taxonomy to their own incident logs and compare results with the synthetic scores.
- Similar boundary mismatches may arise in other domains where probabilistic components integrate with legacy deterministic infrastructure.
Load-bearing premise
The synthetic framework-adequacy methodology produces valid coverage claims without empirical observation of actual team behavior or incidents.
What would settle it
An empirical study that tracks real incidents and near-misses in AI-native teams and compares observed coverage against the synthetic scores would falsify the central claim if the measured degradation pattern does not match the derived one.
Figures





read the original abstract
Engineering management research has produced mature frameworks for software risk: ownership by feature, escalation by severity, and assurance by test coverage. These frameworks implicitly assume deterministic behavior, discrete and auditable change events, and clear component-to-owner mappings. Teams that build and operate agentic AI systems violate all three assumptions at once: outputs are probabilistic, systems take autonomous multi-step actions, and the risk surface mutates silently between deployments. Existing AI risk literature addresses this from above (policy frameworks such as the NIST AI RMF and ISO/IEC 42001) or below (threat taxonomies such as OWASP's agentic AI guidance), but not at the layer where an engineering manager (EM) operates: roles, decision rights, and escalation structures. This paper contributes (i) a seven-dimension profile distinguishing pure software-engineering, hybrid, and AI-native teams; (ii) a six-cluster failure-mode taxonomy including a previously unarticulated cluster, dependency-boundary determinism mismatch; and (iii) a synthetic framework-adequacy methodology scoring how well each profile's risk architecture detects, contains, and escalates a defined scenario set. Because the object of study is framework adequacy rather than human behavior, the evaluation yields derived rather than observed coverage claims. Coverage degrades as teams move from pure software engineering to AI-native operation, monotonically in the median and abruptly in the count of uncovered, high-consequence failures appearing only at the AI-native step. The degradation concentrates in specific failure-mode categories, and the most severe, least-covered failures arise not inside AI-native teams but at the organizational boundary where their probabilistic outputs are consumed by determinism-assuming dependencies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a framework for governing risk in AI-native engineering teams. It defines seven team profiles ranging from pure software engineering to AI-native, introduces a six-cluster failure taxonomy with emphasis on a new 'dependency-boundary determinism mismatch' category, and applies a synthetic adequacy scoring method to show that risk coverage degrades as teams adopt more agentic AI systems, with the sharpest gaps at organizational boundaries between probabilistic AI outputs and deterministic dependencies. All claims are explicitly derived from the authors' taxonomy and scoring rather than from observed incidents.
Significance. If validated, the framework could bridge the gap between high-level AI risk policies (NIST, ISO) and operational engineering management by providing concrete structures for roles and escalations. The paper's transparency about its synthetic, derived nature is a positive feature, distinguishing it from overclaimed empirical studies. However, the absence of any empirical grounding means the specific degradation patterns remain untested hypotheses rather than demonstrated results.
major comments (3)
- [Abstract] Abstract: The central claim of monotonic median degradation and abrupt rise in uncovered high-consequence failures is derived solely from the synthetic scoring methodology; this makes the specific location of failures at determinism-mismatch boundaries a direct output of the taxonomy construction rather than an independent finding.
- [Methodology (synthetic framework-adequacy)] Methodology section: The adequacy scores for detection, containment, and escalation are assigned by the authors to hand-defined scenarios across profiles; without any cross-check against real incident logs or team audits, the resulting coverage claims cannot be distinguished from artifacts of the scoring rubric.
- [Failure-mode taxonomy] Failure-mode taxonomy: The novelty of the 'dependency-boundary determinism mismatch' cluster is asserted, but the manuscript provides no systematic comparison to existing taxonomies in OWASP agentic AI guidance or NIST AI RMF to establish that it is previously unarticulated.
minor comments (2)
- [Abstract] The phrase 'previously unarticulated cluster' should be supported by a brief literature pointer even in the abstract.
- [Throughout] Ensure consistent use of 'derived rather than observed' qualifier when stating coverage results to prevent misreading as empirical.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the paper's explicit synthetic character. We address each major comment point by point below, accepting the need for clarification on derived claims and committing to targeted revisions that strengthen transparency without altering the core synthetic methodology.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of monotonic median degradation and abrupt rise in uncovered high-consequence failures is derived solely from the synthetic scoring methodology; this makes the specific location of failures at determinism-mismatch boundaries a direct output of the taxonomy construction rather than an independent finding.
Authors: We agree that the claims are derived outputs of the taxonomy and scoring. The current abstract already states that 'the evaluation yields derived rather than observed coverage claims,' but we will revise it to more explicitly note that the concentration of uncovered failures at determinism-mismatch boundaries is a direct consequence of the hand-defined scenario set and rubric rather than an independent result. This change will prevent any misreading of the work as empirical. revision: yes
-
Referee: [Methodology (synthetic framework-adequacy)] Methodology section: The adequacy scores for detection, containment, and escalation are assigned by the authors to hand-defined scenarios across profiles; without any cross-check against real incident logs or team audits, the resulting coverage claims cannot be distinguished from artifacts of the scoring rubric.
Authors: The manuscript is designed as a synthetic exercise, with scores assigned by the authors to illustrate the framework; this is stated in both the abstract and methodology. We accept that the specific degradation patterns remain untested hypotheses. In revision we will add an explicit limitations paragraph in the methodology section that discusses the absence of external validation and the rationale for the synthetic approach, while preserving the illustrative scoring as the intended contribution. revision: partial
-
Referee: [Failure-mode taxonomy] Failure-mode taxonomy: The novelty of the 'dependency-boundary determinism mismatch' cluster is asserted, but the manuscript provides no systematic comparison to existing taxonomies in OWASP agentic AI guidance or NIST AI RMF to establish that it is previously unarticulated.
Authors: We will insert a new subsection (or table) in the related-work or taxonomy section that systematically maps each of our six clusters against the relevant categories in OWASP agentic AI guidance and the NIST AI RMF. This comparison will demonstrate that the organizational boundary focus of the dependency-boundary determinism mismatch cluster is not articulated in those sources, thereby supporting the novelty claim. revision: yes
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Traditional software risk frameworks assume deterministic behavior, discrete and auditable change events, and clear component-to-owner mappings.
Reference graph
Works this paper leans on
-
[1]
B. W. Boehm,Software Risk Management. IEEE Computer Society Press, 1989
1989
-
[2]
Forsgren, J
N. Forsgren, J. Humble, and G. Kim,Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations. IT Revolution Press, 2018
2018
-
[3]
How do committees invent?
M. E. Conway, “How do committees invent?”Datamation, vol. 14, no. 4, pp. 28–31, 1968
1968
-
[4]
Skelton and M
M. Skelton and M. Pais,Team Topologies: Organizing Business and Technology Teams for Fast Flow. IT Revolution Press, 2019. 13
2019
-
[5]
Artificial intelligence risk management framework (AI RMF 1.0),
National Institute of Standards and Technology, “Artificial intelligence risk management framework (AI RMF 1.0),” NIST, Tech. Rep., 2023
2023
-
[6]
International Organization for Standardization,ISO/IEC 42001:2023 Information technology—Artificial intelligence—Management system, ISO/IEC, 2023
2023
-
[7]
Regulation laying down harmonised rules on artificial intelligence (artificial intelligence act),
European Parliament and Council, “Regulation laying down harmonised rules on artificial intelligence (artificial intelligence act),” 2024
2024
-
[8]
OW ASP top 10 for LLM applications and agentic AI security guidance,
OW ASP Foundation, “OW ASP top 10 for LLM applications and agentic AI security guidance,” 2024–2025
2024
-
[9]
Taxonomies of AI risk,
Center for Long-Term Cybersecurity, “Taxonomies of AI risk,” UC Berkeley, Technical Reports, 2023–2025
2023
-
[10]
L. Bass, P. Clements, and R. Kazman,Software Architecture in Practice, 4th ed. Addison-Wesley, 2021
2021
-
[11]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection,” 2023, arXiv:2302.12173; AISec ’23
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
L. G. Iyer and R. Suresh Babu, “The gate is only as honest as its contracts: ContractGuard for the contract layer of risk-aware causal gating,” 2026, arXiv:2606.18550
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
L. G. Iyer and R. Suresh Babu, “Capability minimization as a safety primitive: Risk-aware causal gating for least-privilege LLM agents,” 2026, arXiv:2606.13884
-
[14]
ToolMenuBench: Benchmarking tool- menu filtering strategies for reliable and efficient LLM agents,
R. Suresh Babu and L. G. Iyer, “ToolMenuBench: Benchmarking tool- menu filtering strategies for reliable and efficient LLM agents,” 2026, arXiv:2606.15508
-
[15]
CVE-2025-32711: EchoLeak – AI command injection in Microsoft 365 Copilot enabling zero-click information disclosure,
MITRE / NIST National Vulnerability Database, “CVE-2025-32711: EchoLeak – AI command injection in Microsoft 365 Copilot enabling zero-click information disclosure,” https://nvd.nist.gov/vuln/detail/CVE- 2025-32711, 2025, microsoft Security Response Center advisory, CVSS 9.3 (Microsoft CNA); NVD base score 7.5; accessed 2026
2025
-
[16]
March 20 ChatGPT outage: here’s what happened,
OpenAI, “March 20 ChatGPT outage: here’s what happened,” https:// openai.com/index/march-20-chatgpt-outage/, 2023, vendor postmortem
2023
-
[17]
Garante per la protezione dei dati personali, “Provvedimento del 30 marzo 2023 [9870832]: limitation of processing imposed on OpenAI regarding ChatGPT,” https://www.gpdp.it/web/guest/home/docweb/-/ docweb-display/docweb/9870847, 2023, italian Data Protection Author- ity order, Doc-Web 9870847
-
[18]
Replit’s CEO apologizes after its AI coding tool deleted a company’s database,
L. Varanasi, “Replit’s CEO apologizes after its AI coding tool deleted a company’s database,” https://www.businessinsider.com/replit- ceo- apologizes- ai- coding- tool- delete- company- database- 2025- 7, 2025, business Insider
2025
-
[19]
How is ChatGPT’s behavior changing over time?
L. Chen, M. Zaharia, and J. Zou, “How is ChatGPT’s behavior changing over time?” 2023, arXiv:2307.09009; also Harvard Data Science Review
-
[20]
Moffatt v. Air Canada, 2024 BCCRT 149,
British Columbia Civil Resolution Tribunal, “Moffatt v. Air Canada, 2024 BCCRT 149,” https://decisions.civilresolutionbc.ca/crt/crtd/en/ item/525448/index.do, 2024, tribunal decision, 14 Feb. 2024; “separate legal entity” argument rejected, airline held liable (corroborated by BBC Travel, 23 Feb. 2024)
2024
-
[21]
Prygodicz v Commonwealth of Australia (No. 2) [2021] FCA 634,
Federal Court of Australia, “Prygodicz v Commonwealth of Australia (No. 2) [2021] FCA 634,” https://www.judgments.fedcourt.gov.au/ judgments/Judgments/fca/single/2021/2021fca0634, 2021, murphy J, 11 June 2021; approx. $1.76B in unlawful debts raised against∼433,000 people, settled for $112M (two distinct figures: total debts raised vs. settlement sum)
2021
-
[22]
Report of the Royal Commission into the Robodebt Scheme,
Royal Commission into the Robodebt Scheme, “Report of the Royal Commission into the Robodebt Scheme,” Commonwealth of Australia, Tech. Rep., 2023, https://robodebt.royalcommission.gov.au/publications/ report; tabled 7 July 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.