Towards Learning Representations of Policies in Two-Player Zero-Sum Imperfect-Information Games
Pith reviewed 2026-07-03 20:52 UTC · model grok-4.3
The pith
Policy embeddings from self-supervised learning on poker variants capture useful behavioral representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By generating datasets of policies for Kuhn and Leduc Poker, training embeddings with self-supervised methods, and measuring those embeddings on downstream tasks, the work shows that useful behavioral representations are present in the learned embeddings.
What carries the argument
Policy datasets created for a given game, paired with self-supervised embedding methods and downstream evaluation tasks that probe behavioral properties.
If this is right
- Embeddings trained this way can support tasks such as policy clustering or similarity search inside the same game.
- Simple self-supervised objectives suffice to extract behavioral signals from policy collections in small poker games.
- Systematic comparisons of different self-supervised techniques become feasible once policy datasets and evaluation tasks are standardized.
Where Pith is reading between the lines
- The same pipeline might scale to produce representations useful for opponent modeling in larger imperfect-information games.
- If the embeddings generalize across game variants, they could reduce the need to retrain policies from scratch when rules change slightly.
- Downstream tasks that test strategic properties could be added to check whether the embeddings encode equilibrium concepts rather than surface statistics.
Load-bearing premise
The chosen downstream tasks accurately measure whether the embeddings capture policy behavior relevant to the games.
What would settle it
Running the downstream tasks on the learned embeddings and finding performance indistinguishable from random vectors would falsify the presence of useful behavioral representations.
Figures


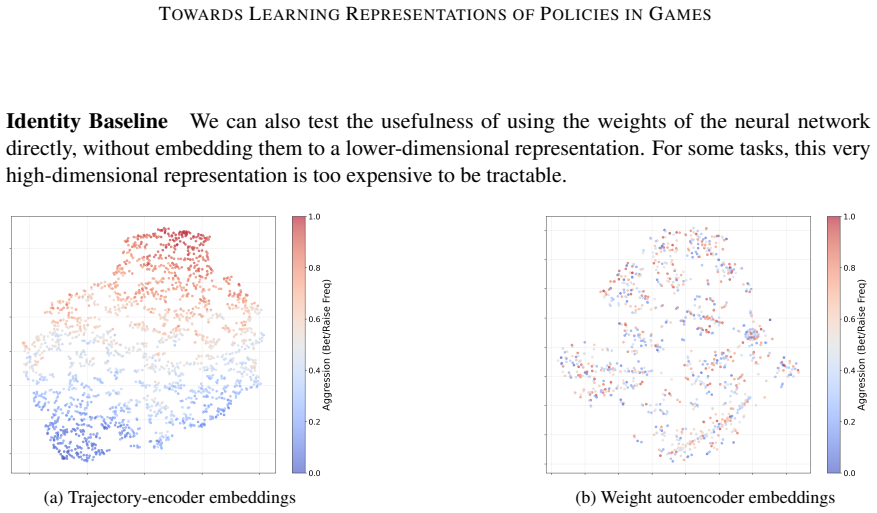
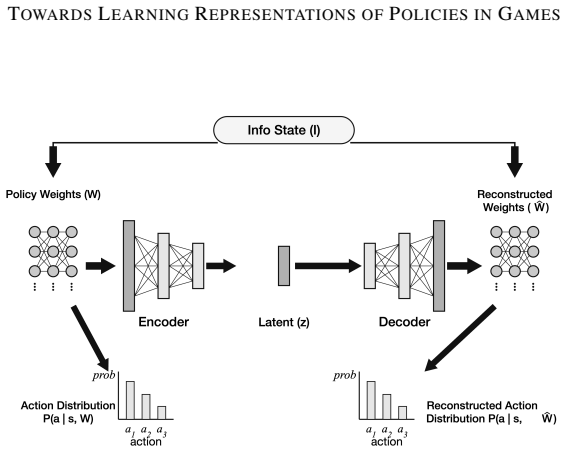
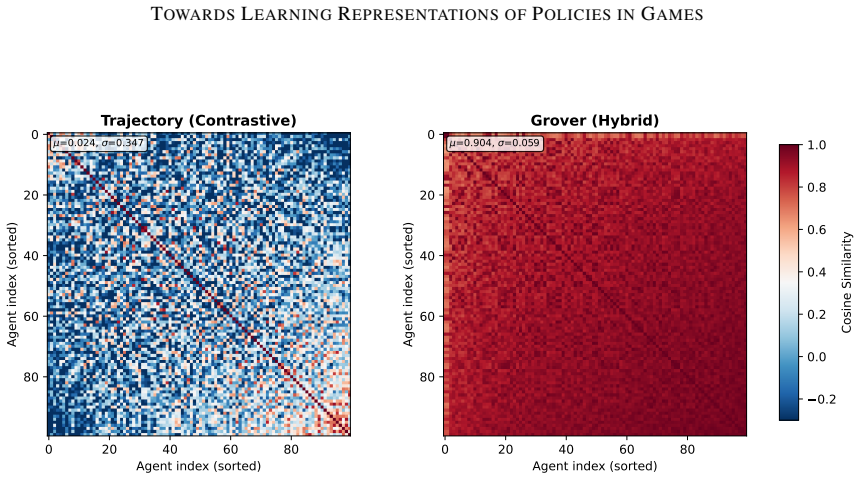
read the original abstract
We investigate the problem of learning useful policy representations (embeddings) in two-player zero-sum imperfect-information games. We make three contributions: First, we introduce methods of creating datasets of policies for a given game. Second, we propose methods to learn policy representations. Third, we introduce downstream tasks to evaluate the effectiveness of such representations. We evaluate each dataset method, embedding method, and downstream task on Kuhn and Leduc Poker. Although our methods are very basic, we demonstrate that useful behavioral representations are present in the learned embeddings. To our knowledge, this work is among the first to systematically compare self-supervised learning techniques for learning policy representations in games. Our code is available at https://github.com/VitamintK/ssl-project for others to extend.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates learning useful policy representations (embeddings) in two-player zero-sum imperfect-information games. It introduces methods for creating datasets of policies, proposes self-supervised techniques to learn embeddings, and defines downstream tasks to evaluate the representations. These are evaluated on Kuhn and Leduc Poker, with the claim that useful behavioral representations are present in the learned embeddings despite the basic nature of the methods. The work positions itself as among the first systematic comparisons of such techniques and provides public code.
Significance. If the central claim holds, the work would provide an early systematic comparison of self-supervised learning methods for policy representations in imperfect-information games, with the public code release serving as a concrete strength for reproducibility and community extension.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: The claim that 'useful behavioral representations are present in the learned embeddings' is asserted without any quantitative results, performance metrics, error bars, or specific outcomes from the downstream tasks on Kuhn and Leduc Poker. This absence makes it impossible to assess whether the embeddings capture policy behavior.
- [Evaluation section] Evaluation section: No description is given of how the downstream tasks are constructed, nor is there an argument that success on these tasks implies the embeddings capture equilibrium or exploitative policy behavior relevant to the games. Without this link, the demonstration reduces to showing that embeddings contain some signal passing the chosen proxies, which does not support the headline claim.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The comments highlight important gaps in the presentation of results and task definitions, which we will address through revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The claim that 'useful behavioral representations are present in the learned embeddings' is asserted without any quantitative results, performance metrics, error bars, or specific outcomes from the downstream tasks on Kuhn and Leduc Poker. This absence makes it impossible to assess whether the embeddings capture policy behavior.
Authors: We agree that the current version of the manuscript does not include specific quantitative results, performance metrics, or error bars to substantiate the claim in the abstract and evaluation sections. In the revision, we will add these details from the experiments on Kuhn and Leduc Poker to enable assessment of whether the embeddings capture policy behavior. revision: yes
-
Referee: [Evaluation section] Evaluation section: No description is given of how the downstream tasks are constructed, nor is there an argument that success on these tasks implies the embeddings capture equilibrium or exploitative policy behavior relevant to the games. Without this link, the demonstration reduces to showing that embeddings contain some signal passing the chosen proxies, which does not support the headline claim.
Authors: We acknowledge that the manuscript lacks a description of downstream task construction and an explicit argument connecting task performance to equilibrium or exploitative behaviors. We will revise the Evaluation section to include these elements, explaining the task construction and why success on the proxies supports the claim regarding policy representations. revision: yes
Circularity Check
No circularity; empirical methods evaluated on external benchmarks
full rationale
The paper introduces dataset creation methods, embedding learning techniques, and downstream evaluation tasks, then reports results on Kuhn and Leduc Poker. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps are present. The central claim rests on observed performance of the introduced methods rather than any reduction to inputs by construction. The evaluation uses standard game benchmarks independent of the paper's own fitted values.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Autonomous Agents Modelling Other Agents: A Comprehensive Survey and Open Problems
Stefano V . Albrecht and Peter Stone. Autonomous Agents Modelling Other Agents: A Com- prehensive Survey and Open Problems.Artificial Intelligence, 258:66–95, May 2018. ISSN 00043702. doi: 10.1016/j.artint.2018.01.002. URL http://arxiv.org/abs/1709. 08071. arXiv:1709.08071 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.artint.2018.01.002 2018
-
[2]
Combining Deep Rein- forcement Learning and Search for Imperfect-Information Games, November 2020
Noam Brown, Anton Bakhtin, Adam Lerer, and Qucheng Gong. Combining Deep Rein- forcement Learning and Search for Imperfect-Information Games, November 2020. URL http://arxiv.org/abs/2007.13544. arXiv:2007.13544 [cs]
-
[3]
Vinod Kumar Chauhan, Jiandong Zhou, Ping Lu, Soheila Molaei, and David A. Clifton. A Brief Review of Hypernetworks in Deep Learning.Artificial Intelligence Review, 57(9): 250, August 2024. ISSN 1573-7462. doi: 10.1007/s10462-024-10862-8. URL http: //arxiv.org/abs/2306.06955. arXiv:2306.06955 [cs]
-
[4]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
2020
-
[5]
Learning policy representations in multiagent systems
Aditya Grover, Maruan Al-Shedivat, Jayesh K Gupta, Yuri Burda, and Harrison Edwards. Learning policy representations in multiagent systems. InInternational Conference on Machine Learning, pages 1802–1811. PMLR, 2018
2018
-
[6]
David Ha, Andrew Dai, and Quoc V Le. Hypernetworks.arXiv preprint arXiv:1609.09106, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Opponent modeling in deep reinforcement learning
He He, Jordan Boyd-Graber, Kevin Kwok, and Hal Daum´e III. Opponent modeling in deep reinforcement learning. InInternational Conference on Machine Learning, pages 1804–1813. PMLR, 2016
2016
-
[8]
A simplified two-person poker.Contributions to the Theory of Games, 1: 97–103, 2016
Harold W Kuhn. A simplified two-person poker.Contributions to the Theory of Games, 1: 97–103, 2016
2016
-
[9]
A unified game-theoretic approach to multiagent reinforcement learning.Advances in neural information processing systems, 30, 2017
Marc Lanctot, Vinicius Zambaldi, Audrunas Gruslys, Angeliki Lazaridou, Karl Tuyls, Julien P´erolat, David Silver, and Thore Graepel. A unified game-theoretic approach to multiagent reinforcement learning.Advances in neural information processing systems, 30, 2017
2017
-
[10]
OpenSpiel: A Framework for Reinforcement Learning in Games.CoRR, abs/1908.09453, 2019
Marc Lanctot, Edward Lockhart, Jean-Baptiste Lespiau, Vinicius Zambaldi, Satyaki Upadhyay, Julien P´erolat, Sriram Srinivasan, Finbarr Timbers, Karl Tuyls, Shayegan Omidshafiei, Daniel Hennes, Dustin Morrill, Paul Muller, Timo Ewalds, Ryan Faulkner, J ´anos Kram´ar, Bart De Vylder, Brennan Saeta, James Bradbury, David Ding, Sebastian Borgeaud, Matthew Lai...
-
[11]
CURL: Contrastive unsupervised representations for reinforcement learning
Michael Laskin, Aravind Srinivas, and Pieter Abbeel. CURL: Contrastive unsupervised representations for reinforcement learning. InInternational Conference on Machine Learning, pages 5639–5650. PMLR, 2020
2020
-
[12]
Neupl: Neural population learning.arXiv preprint arXiv:2202.07415, 2022
Siqi Liu, Luke Marris, Daniel Hennes, Josh Merel, Nicolas Heess, and Thore Graepel. Neupl: Neural population learning.arXiv preprint arXiv:2202.07415, 2022
-
[13]
Siqi Liu, Luke Marris, Marc Lanctot, Georgios Piliouras, Joel Z. Leibo, and Nicolas Heess. Neural Population Learning beyond Symmetric Zero-sum Games, January 2024. URL https: //arxiv.org/abs/2401.05133v1
-
[14]
Trajectory diversity for zero-shot coordination
Andrei Lupu, Brandon Cui, Hengyuan Hu, and Jakob Foerster. Trajectory diversity for zero-shot coordination. InInternational Conference on Machine Learning, pages 7204–7213. PMLR, 2021
2021
-
[15]
Wenhao Ma, Yu-Cheng Chang, Jie Yang, Yu-Kai Wang, and Chin-Teng Lin. Con- trastive learning-based agent modeling for deep reinforcement learning.arXiv preprint arXiv:2401.00132, 2024
-
[16]
Learning Models of Individual Behavior in Chess
Reid McIlroy-Young, Russell Wang, Siddhartha Sen, Jon Kleinberg, and Ashton Ander- son. Learning Models of Individual Behavior in Chess. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1253–1263, August
-
[17]
URL http://arxiv.org/abs/2008.10086
doi: 10.1145/3534678.3539367. URL http://arxiv.org/abs/2008.10086. arXiv:2008.10086 [cs]
-
[18]
A Survey of Opponent Modeling in Adversarial Domains.Journal of Artificial Intelligence Research, 73:277–327, January 2022
Samer Nashed and Shlomo Zilberstein. A Survey of Opponent Modeling in Adversarial Domains.Journal of Artificial Intelligence Research, 73:277–327, January 2022. ISSN 1076-
2022
-
[19]
URL https://www.jair.org/index.php/jair/ article/view/12889
doi: 10.1613/jair.1.12889. URL https://www.jair.org/index.php/jair/ article/view/12889
-
[20]
Agent modelling under partial observability for deep reinforcement learning
Georgios Papoudakis, Filippos Christianos, and Stefano Albrecht. Agent modelling under partial observability for deep reinforcement learning. InAdvances in Neural Information Processing Systems, volume 34, pages 19210–19222, 2021
2021
-
[21]
Reevaluating Policy Gradient Methods for Imperfect-Information Games
Max Rudolph, Nathan Lichtle, Sobhan Mohammadpour, Alexandre Bayen, J Zico Kolter, Amy Zhang, Gabriele Farina, Eugene Vinitsky, and Samuel Sokota. Reevaluating policy gradient methods for imperfect-information games.arXiv preprint arXiv:2502.08938, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal Policy Optimization Algorithms, August 2017. URL http://arxiv.org/abs/1707. 06347. arXiv:1707.06347 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Solving Common-Payoff Games with Approximate Policy Iteration, January 2021
Samuel Sokota, Edward Lockhart, Finbarr Timbers, Elnaz Davoodi, Ryan D’Orazio, Neil Burch, Martin Schmid, Michael Bowling, and Marc Lanctot. Solving Common-Payoff Games with Approximate Policy Iteration, January 2021. URL http://arxiv.org/abs/2101. 04237. arXiv:2101.04237 [cs]. 9 TOWARDSLEARNINGREPRESENTATIONS OFPOLICIES INGAMES
-
[24]
Predicting neural network accuracy from weights
Thomas Unterthiner, Daniel Keysers, Sylvain Gelly, Olivier Bousquet, and Ilya Tolstikhin. Predicting neural network accuracy from weights. InarXiv preprint arXiv:2002.11448, 2020
-
[25]
TransAM: Transformer-based agent modeling for multi-agent systems via local trajectory encoding
Conor Wallace, Umer Siddique, and Yongcan Cao. TransAM: Transformer-based agent modeling for multi-agent systems via local trajectory encoding. InReinforcement Learning Conference, 2025
2025
-
[26]
liars_dice(numdice=1,dice_sides=4)
Annie Xie, Dylan P Losey, Ryan Tolsma, Chelsea Finn, and Dorsa Sadigh. Learning latent representations to influence multi-agent interaction. InConference on Robot Learning, pages 575–588. PMLR, 2020. 10 TOWARDSLEARNINGREPRESENTATIONS OFPOLICIES INGAMES Appendix A. Details on Randomly Initializing Policy Neural Networks Our layer initialization initializes...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.