Beyond Skepticism: Evaluating LLMs Pedagogical Intent Reasoning with the Adaptive Pedagogical Vigilance Framework
Pith reviewed 2026-07-03 15:24 UTC · model grok-4.3
The pith
The Adaptive Pedagogical Vigilance framework improves LLMs' detection of pedagogical intent over baseline methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
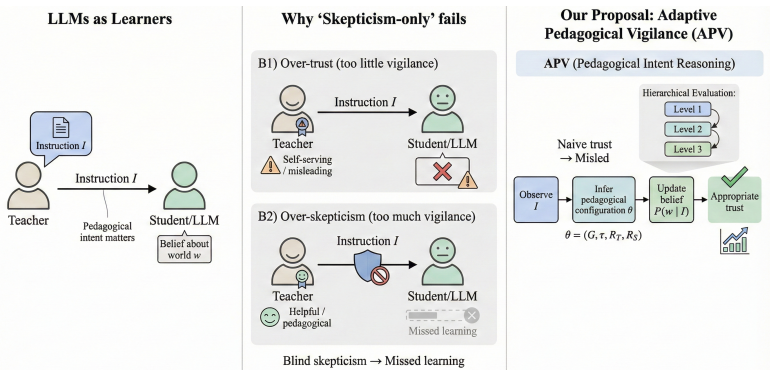
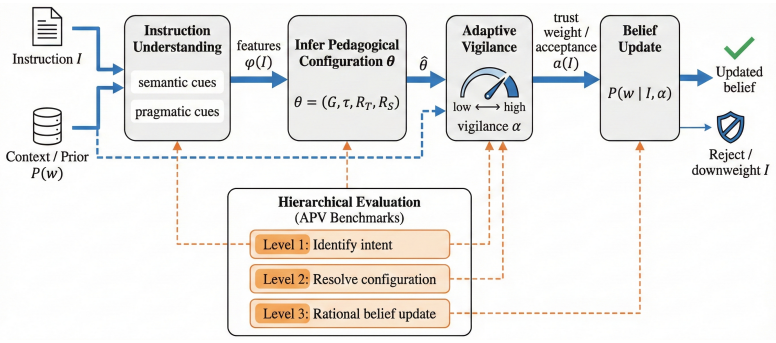
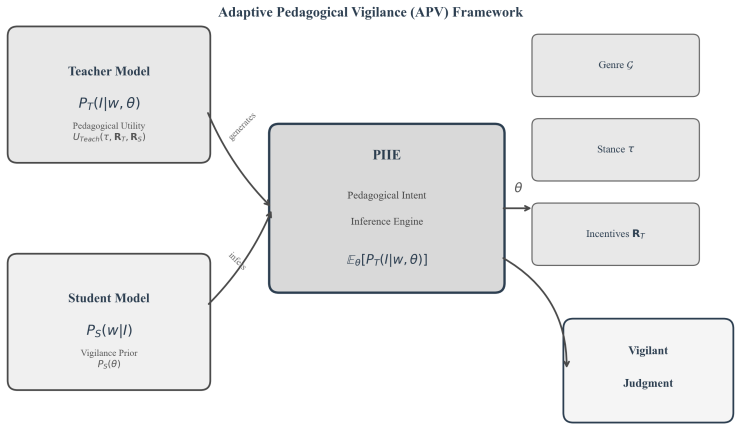
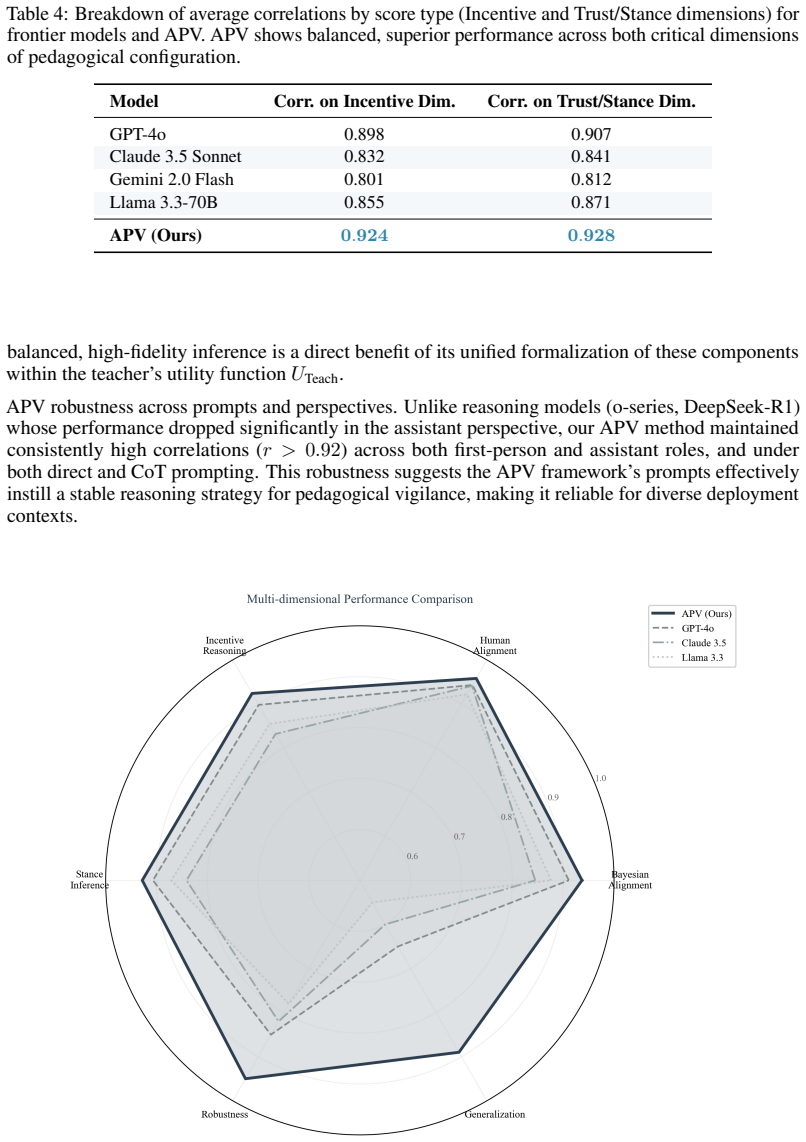
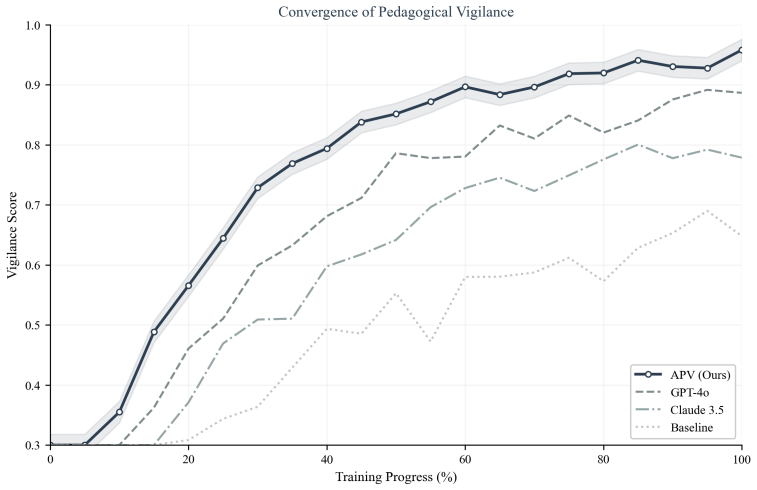
The Adaptive Pedagogical Vigilance framework, built on a Bayesian Pedagogical Intent Inference Engine, supplies a three-tier test that lets LLMs distinguish content chosen to support learning from content chosen merely for exposure; the resulting scores align closely with human raters and remain stable when the input shifts from controlled exercises to authentic educational discourse.
What carries the argument
The Bayesian Pedagogical Intent Inference Engine inside APV, which models how instructors choose content to maximize pedagogical utility and how learners should infer the latent genre, stance, and incentives from that choice.
If this is right
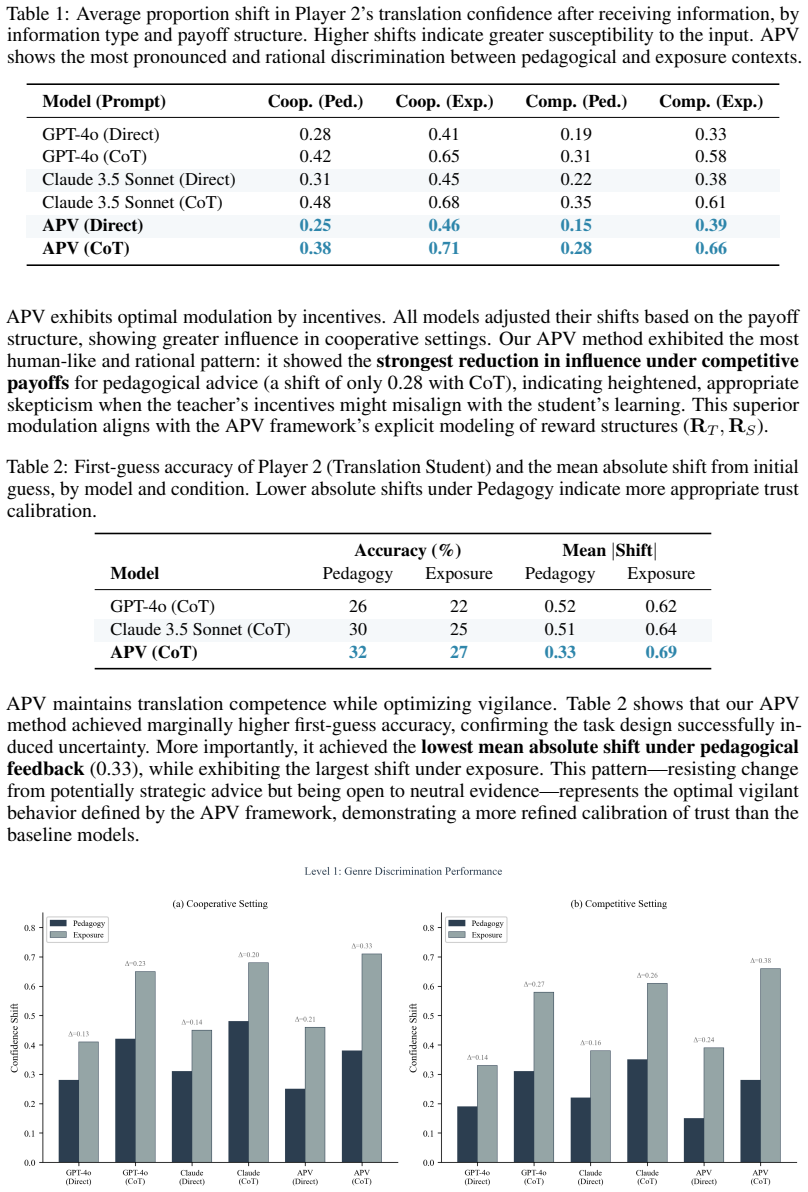
- LLMs equipped with APV achieve stronger discrimination between pedagogical and exposure-based content than baseline methods.
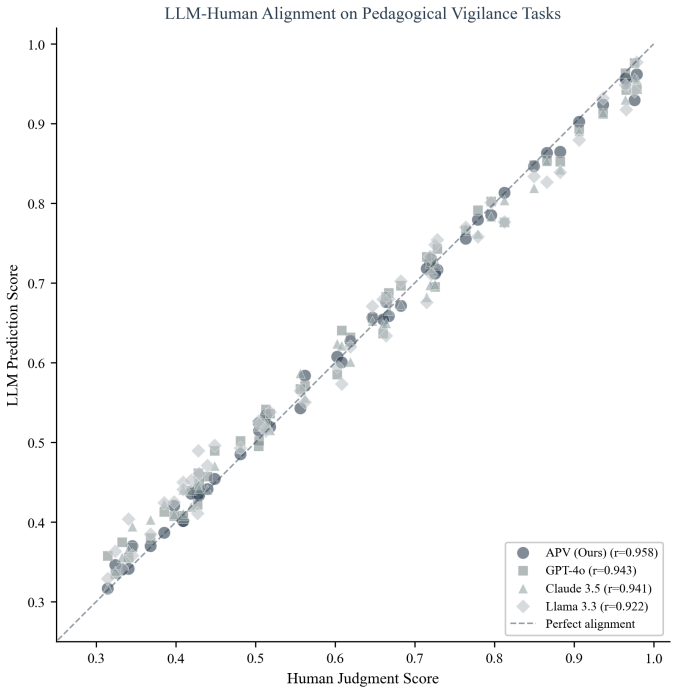
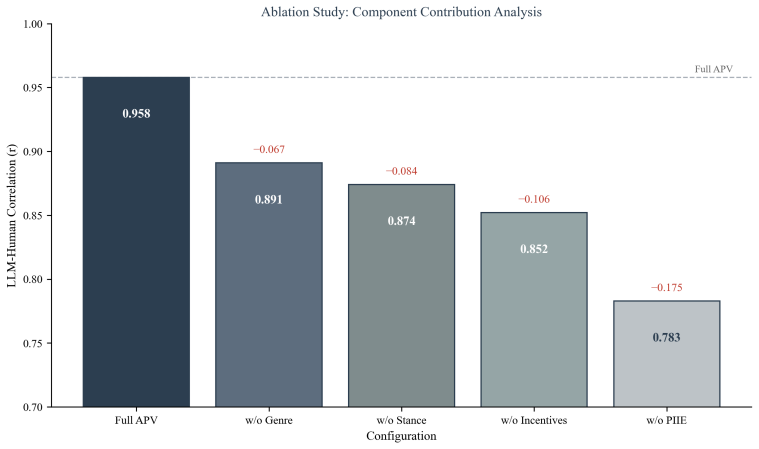
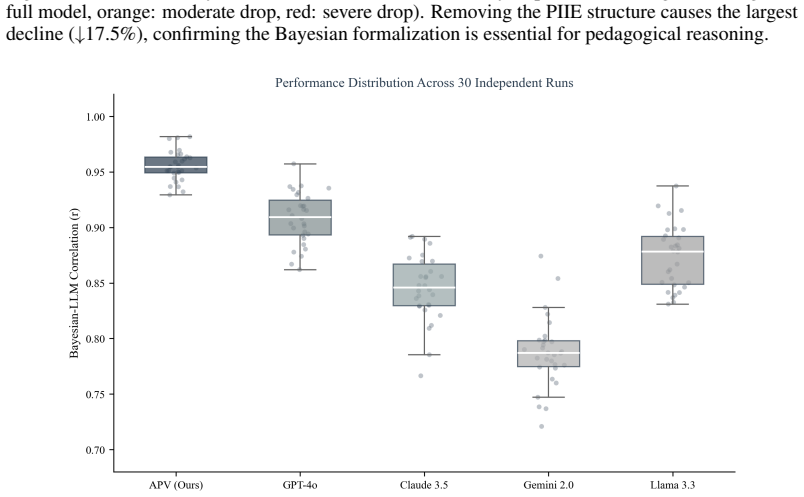
- APV scores correlate at r=0.958 with human judgments of pedagogical intent.
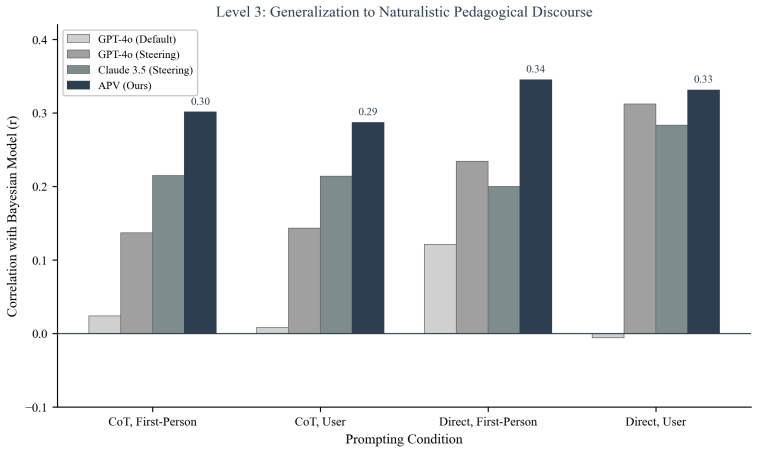
- The framework maintains performance on naturalistic educational discourse where prior approaches degrade.
- The method supports construction of more reliable AI-assisted learning systems that better understand instructional motives.
Where Pith is reading between the lines
- The same Bayesian structure could be adapted to test intent inference in domains such as legal or medical communication.
- If APV proves stable across model families, it could serve as a standard benchmark for measuring progress in educational AI.
- Repeated application might expose whether current pretraining corpora already encode strong priors about teaching scenarios.
Load-bearing premise
The three-tier hierarchy and Bayesian definitions supply an unbiased and complete test of pedagogical intent reasoning that does not depend on the models' pretraining data.
What would settle it
An experiment in which APV scores drop sharply on held-out classroom transcripts that closely resemble the models' pretraining distribution would indicate that the gains depend on data overlap rather than genuine intent reasoning.
Figures
read the original abstract
The capacity of Large Language Models (LLMs) to reason about pedagogical intent within instructional communication remains underexplored, particularly in educational domains such as translation pedagogy. To address this, we propose the \textbf{Adaptive Pedagogical Vigilance (APV)} framework, a novel computational formalism that reframes communicative vigilance as an adaptive mechanism for optimizing learning through intent inference. APV formalizes the problem via a Bayesian Pedagogical Intent Inference Engine (PIIE), which models how instructors select content to maximize pedagogical utility and how vigilant learners should inversely reason about latent instructional configurations -- encompassing genre, stance, and incentives. We evaluate APV through a three-tier hierarchy: distinguishing instructional genre, reasoning about structured pedagogical setups, and generalizing to authentic educational discourse. Experiments on leading LLMs (e.g., GPT-4o, Claude 3.5) show that APV substantially improves model vigilance. It achieves the strongest discrimination between pedagogical and exposure-based content, correlates highly with human judgments ($r=0.958$), and maintains robust performance on naturalistic data where baseline methods degrade. This work establishes a unified framework for assessing and enhancing LLMs' understanding of pedagogical motives, advancing the development of more reliable AI-assisted learning systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Adaptive Pedagogical Vigilance (APV) framework, which introduces a Bayesian Pedagogical Intent Inference Engine (PIIE) to model how LLMs should inversely infer latent instructional configurations (genre, stance, incentives) from content selected to maximize pedagogical utility. It evaluates this via a three-tier hierarchy (genre distinction, structured pedagogical setups, generalization to authentic educational discourse) on models including GPT-4o and Claude 3.5, reporting strongest discrimination between pedagogical and exposure-based content, correlation r=0.958 with human judgments, and robust performance on naturalistic data where baselines degrade.
Significance. If the reported results and independence of the evaluation hold, the work could provide a formal computational approach to assessing pedagogical intent reasoning in LLMs, potentially aiding development of more reliable AI-assisted educational systems. The explicit Bayesian formalization and three-tier structure offer a structured way to test vigilance beyond surface patterns, though significance is tempered by the need to confirm the naturalistic tier is not explained by pretraining overlap.
major comments (2)
- [generalization to authentic educational discourse tier] In the generalization to authentic educational discourse tier: the claim of robust performance where baseline methods degrade (and the overall assertion that APV substantially improves model vigilance) rests on the assumption that superior discrimination reflects the inverse inference formalized in PIIE rather than surface-level pattern matching from pretraining on educational texts; without explicit contamination checks, OOD construction, or training-data overlap analysis, this load-bearing result for the naturalistic tier cannot be verified as independent of the models' training data.
- [Bayesian Pedagogical Intent Inference Engine (PIIE) and three-tier hierarchy] In the definition and application of the Bayesian Pedagogical Intent Inference Engine (PIIE) within the three-tier hierarchy: it is unclear whether the reported metrics (discrimination strength, human correlation) are constructed independently of the framework's own parameters and definitions, raising a risk that the evaluation of improvements is circular rather than an external test of pedagogical intent reasoning.
minor comments (1)
- [Abstract] The abstract reports specific performance numbers (r=0.958) and comparisons but the provided text does not detail the exact datasets, statistical tests, or error analysis used; these should be expanded in the main text for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major concern point-by-point below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [generalization to authentic educational discourse tier] In the generalization to authentic educational discourse tier: the claim of robust performance where baseline methods degrade (and the overall assertion that APV substantially improves model vigilance) rests on the assumption that superior discrimination reflects the inverse inference formalized in PIIE rather than surface-level pattern matching from pretraining on educational texts; without explicit contamination checks, OOD construction, or training-data overlap analysis, this load-bearing result for the naturalistic tier cannot be verified as independent of the models' training data.
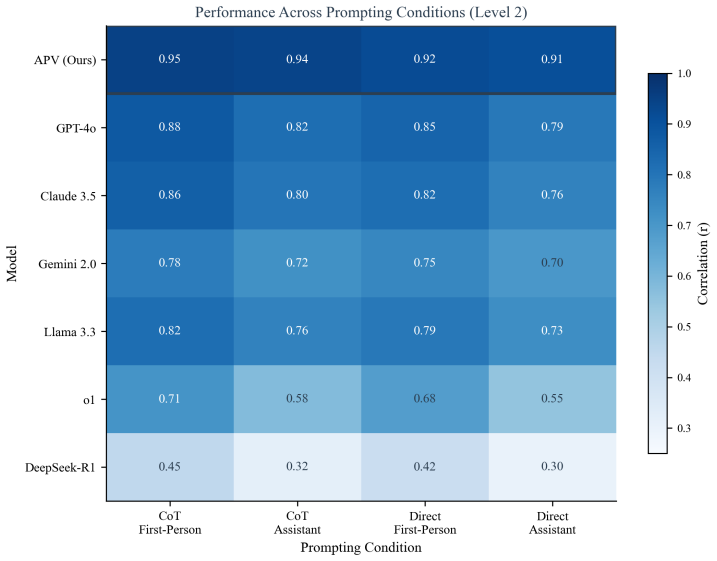
Authors: We acknowledge this valid concern about potential pretraining overlap. The three-tier hierarchy is explicitly designed to demonstrate progressive generalization, and the key observation that baseline methods degrade on the naturalistic tier while APV maintains performance indicates that gains derive from the inverse inference mechanism rather than shared surface patterns (which would advantage baselines equally). Nevertheless, to strengthen verifiability, we will add an explicit training-data overlap analysis and decontamination checks for the naturalistic dataset in the revised manuscript. revision: yes
-
Referee: [Bayesian Pedagogical Intent Inference Engine (PIIE) and three-tier hierarchy] In the definition and application of the Bayesian Pedagogical Intent Inference Engine (PIIE) within the three-tier hierarchy: it is unclear whether the reported metrics (discrimination strength, human correlation) are constructed independently of the framework's own parameters and definitions, raising a risk that the evaluation of improvements is circular rather than an external test of pedagogical intent reasoning.
Authors: The PIIE supplies the theoretical Bayesian model, but evaluation metrics are computed externally: discrimination uses ground-truth labels from the tiered tasks, and the r=0.958 correlation compares model outputs against independent human judgments. PIIE parameters are not fitted to evaluation data. We will revise the methods section to explicitly document this independence and avoid any perception of circularity. revision: partial
Circularity Check
No significant circularity; evaluations rely on external benchmarks
full rationale
The paper proposes the novel APV framework and Bayesian PIIE formalism, then evaluates LLMs empirically via a three-tier hierarchy. Reported results (strongest discrimination, r=0.958 correlation with human judgments, robustness on naturalistic data vs. baselines) depend on independent human annotations and baseline method comparisons rather than any self-definitional reduction, fitted parameter renamed as prediction, or self-citation chain. No equations or load-bearing steps in the provided text equate outputs to inputs by construction; the derivation chain remains self-contained against external measures.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bayesian inference accurately models how instructors select content to maximize pedagogical utility and how learners should invert that process
invented entities (1)
-
Bayesian Pedagogical Intent Inference Engine (PIIE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AOI: Context-Aware Multi-Agent Operations via Dynamic Scheduling and Hierarchical Memory Compression
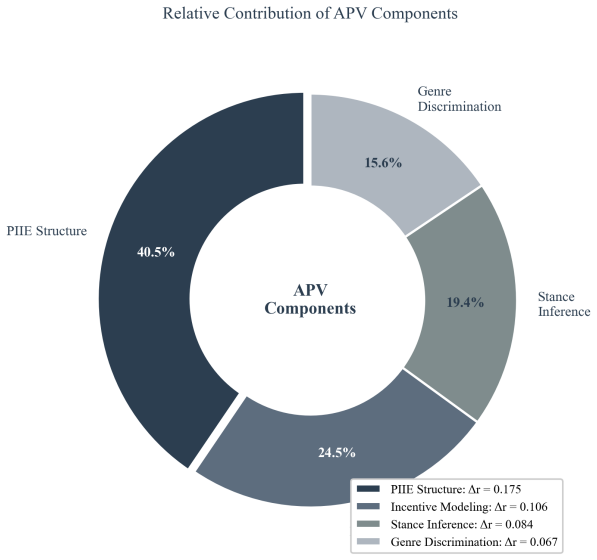
16 Figure 12: Relative contribution of APV components to overall performance (donut chart). The PIIE structure contributes 40.5% of the total effect, followed by incentive modeling (24.5%), stance inference (19.4%), and genre discrimination (15.6%). Legend shows absolute correlation drops (∆r). Zishan Bai, Enze Ge, and Junfeng Hao. Multi-agent collaborati...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Ziqian Bi, Lu Chen, Junhao Song, Hongying Luo, Enze Ge, Junmin Huang, Tianyang Wang, Keyu Chen, Chia Xin Liang, Zihan Wei, et al. Exploring efficiency frontiers of thinking budget in medical reasoning: Scaling laws between computational resources and reasoning quality.arXiv:2508.12140,
-
[3]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, et al. Sparks of artificial general intelligence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Mvi-bench: A comprehensive benchmark for evaluating robustness to misleading visual inputs in lvlms
Huiyi Chen, Jiawei Peng, Dehai Min, Changchang Sun, Kaijie Chen, Yan Yan, Xu Yang, and Lu Cheng. Mvi-bench: A comprehensive benchmark for evaluating robustness to misleading visual inputs in lvlms. InProceedings of the 43rd International Conference on Machine Learning (ICML 2026), 2025a. Kaijie Chen, Zihao Lin, Zhiyang Xu, Ying Shen, Yuguang Yao, Joy Rimc...
2026
-
[5]
Graph inference towards icd coding.arXiv preprint arXiv:2601.07496,
Xiaoxiao Deng. Graph inference towards icd coding.arXiv preprint arXiv:2601.07496,
-
[6]
Xudong Han, Xianglun Gao, Xiaoyi Qu, and Zhenyu Yu. Multi-agent medical decision consensus matrix system: An intelligent collaborative framework for oncology mdt consultations.arXiv preprint arXiv:2512.14321,
-
[7]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, et al. Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
GUI Agents for Continual Game Generation
Yixu Huang, Bo Li, Na Li, Zhe Wang, Kaijie Chen, Haonan Ge, Qingyi Si, Yuanzhe Shen, Ruihan Yang, Guangjing Wang, and Hongcheng Guo. Gui agents for continual game generation.arXiv preprint arXiv:2605.28258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
GUI Agents for Continual Game Generation
doi: 10.48550/arXiv.2605.28258. Ziwei Ji, Nayeon Lee, Rita Frieske, et al. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.28258
-
[10]
Evaluating large language models in theory of mind tasks.arXiv preprint arXiv:2302.02083,
Michal Kosinski. Evaluating large language models in theory of mind tasks.arXiv preprint arXiv:2302.02083,
-
[11]
Chia Xin Liang, Pu Tian, Caitlyn Heqi Yin, Yao Yua, Wei An-Hou, Li Ming, Tianyang Wang, Ziqian Bi, and Ming Liu. A comprehensive survey and guide to multimodal large language models in vision-language tasks.arXiv preprint arXiv:2411.06284,
-
[12]
18 Shiyin Lin. Abductive inference in retrieval-augmented language models: Generating and validating missing premises, 2025a. URLhttps://arxiv.org/abs/2511.04020. Shiyin Lin. Hybrid fuzzing with llm-guided input mutation and semantic feedback, 2025b. URL https://arxiv.org/abs/2511.03995. Shiyin Lin. Llm-driven adaptive source-sink identification and false...
-
[13]
Qian Niu, Keyu Chen, Ming Li, Pohsun Feng, Ziqian Bi, Lawrence KQ Yan, Yichao Zhang, Cait- lyn Heqi Yin, Cheng Fei, Junyu Liu, Benji Peng, Tianyang Wang, Yunze Wang, Silin Chen, and Ming Liu. From text to multimodality: Exploring the evolution and impact of large language models in medical practice, 2024a. URLhttps://arxiv.org/abs/2410.01812. Qian Niu, Ju...
-
[14]
Benji Peng, Ziqian Bi, Qian Niu, Ming Liu, Pohsun Feng, Tianyang Wang, Lawrence KQ Yan, Yizhu Wen, Yichao Zhang, and Caitlyn Heqi Yin. Jailbreaking and mitigation of vulnerabilities in large language models.Algorithms and Applications in Artificial Intelligence and Autonomous Systems, 2024a. Benji Peng, Keyu Chen, Ming Li, Pohsun Feng, Ziqian Bi, Junyu Li...
-
[15]
Neural theory-of-mind? on the limits of social intelligence in large lms
Maarten Sap, Ronan LeBras, Daniel Fried, and Yejin Choi. Neural theory-of-mind? on the limits of social intelligence in large lms. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3762–3780,
2022
-
[16]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, et al. Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Michael Tomasello, Malinda Carpenter, Josep Call, Tanya Behne, and Henrike Moll
URLhttps://arxiv.org/abs/2511.01243. Michael Tomasello, Malinda Carpenter, Josep Call, Tanya Behne, and Henrike Moll. Understanding and sharing intentions: The origins of cultural cognition.Behavioral and Brain Sciences, 28(5): 675–691,
-
[18]
The edge connectivity of expanded k-ary n-cubes.Discrete Dynamics in Nature and Society, 2018(1):7867342,
Shiying Wang and Mujiangshan Wang. The edge connectivity of expanded k-ary n-cubes.Discrete Dynamics in Nature and Society, 2018(1):7867342,
2018
-
[19]
Learning-Based Automated Adversarial Red-Teaming for Robustness Evaluation of Large Language Models
Ze-Lin Wei, Hong-Yu An, Yao Yao, Wei-Cong Su, Guo Li, Saifullah, Bi-Feng Sun, and Mu-Jiang- Shan Wang. Fstgat: Financial spatio-temporal graph attention network for non-stationary financial systems and its application in stock price prediction.Symmetry, 17(8):1344, 2025a. Zhang Wei, Peilu Hu, Shengning Lang, Hao Yan, Li Mei, Yichao Zhang, Chen Yang, Junfe...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Yi Xin, Qi Qin, Siqi Luo, Kaiwen Zhu, Juncheng Yan, Yan Tai, Jiayi Lei, Yuewen Cao, Keqi Wang, Yibin Wang, et al. Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understanding.arXiv preprint arXiv:2510.06308, 2025a. Yi Xin, Juncheng Yan, Qi Qin, Zhen Li, Dongyang Liu, Shicheng Li, Victor Shea-Jay Huang, Yupeng Zhou, Ren...
-
[21]
Lin Yu, Xiaofei Han, Yifei Kang, Chiung-Yi Tseng, Danyang Zhang, Ziqian Bi, and Zhimo Han. Af- fective multimodal agents with proactive knowledge grounding for emotionally aligned marketing dialogue.arXiv preprint arXiv:2511.21728, 2025a. Zhenyu Yu. Ai for science: A comprehensive review on innovations, challenges, and future directions. International Jou...
-
[22]
Zhenyu Yu, Mohd Yamani Idna Idris, Pei Wang, Yuelong Xia, and Yong Xiang. Forgetme: Bench- marking the selective forgetting capabilities of generative models.Engineering Applications of Artificial Intelligence, 161:112087, 2025b. Zhenyu Yu, Jinnian Wang, and Mohd Yamani Idna Idris. Iidm: Improved implicit diffusion model with knowledge distillation to est...
-
[23]
MemMark: State-Evolution Attribution Watermarking for Agent Long-Term Memory Systems
Haobo Zhang, Xutao Mao, Guangyuan Dong, Ziwei Li, Xuanbo Su, Kaijie Chen, Jing Yang, and Zheng Lin. Memmark: State-evolution attribution watermarking for agent long-term memory systems.arXiv preprint arXiv:2605.25002,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
An algorithm for the orientation of complete bipartite graphs
Lingqi Zhao, Mujiangshan Wang, Xuefei Zhang, Yuqing Lin, and Shiying Wang. An algorithm for the orientation of complete bipartite graphs. In2017 International Conference on Applied Mathematics, Modelling and Statistics Application (AMMSA 2017), pages 361–364. Atlantis Press,
2017
-
[25]
Qinjian Zhao, Zhihao Dou, Dinggen Zhang, Xiangyu Li, Chaoda Song, Zhongwei Wan, Xinpeng Li, Yanyan Zhang, Kaijie Chen, Qingtao Pan, et al. Stride: Strategic trajectory reasoning via discriminative estimation for verifiable reinforcement learning.arXiv preprint arXiv:2606.15866,
-
[26]
Yiyang Zhou, Yangfan He, Yaofeng Su, Siwei Han, Joel Jang, Gedas Bertasius, Mohit Bansal, and Huaxiu Yao. Reagent-v: A reward-driven multi-agent framework for video understanding.arXiv preprint arXiv:2506.01300,
-
[27]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.