Rethinking Complexity Metrics for LLM-Integrated Applications: Beyond Source Code
Pith reviewed 2026-07-03 14:10 UTC · model grok-4.3
The pith
Prompt complexity forms a distinct dimension in LLM-integrated applications that new structural metrics can measure independently of code size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
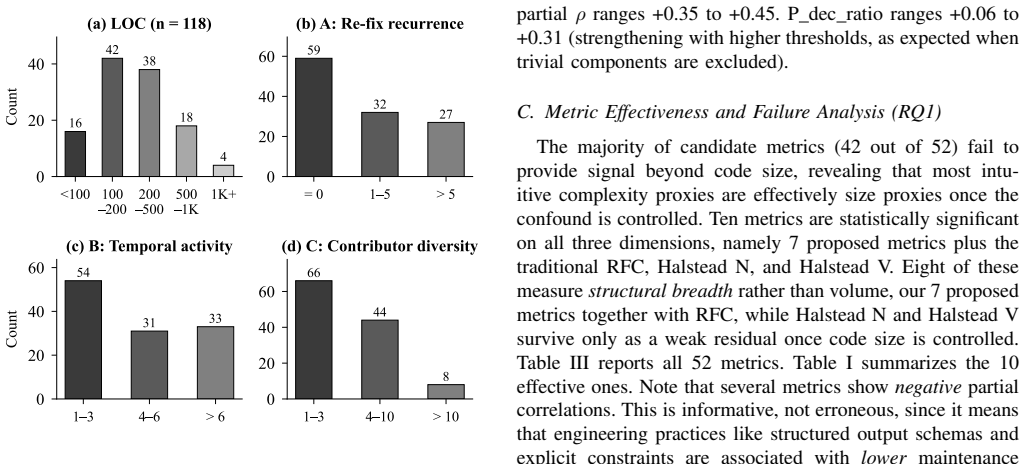
The paper establishes that complexity in LLM-integrated applications requires separate measurement of the prompt layer, which can be formalized as specifications of intended behavior. Using a new set of metrics that emphasize structural breadth—such as counting distinct LLM call sites, memory attributes, and prompt templates—rather than sheer size, the authors show these metrics predict maintenance activity independently of code size and outperform conventional code metrics. Prompt metrics remain significant even when code metrics are included, confirming prompt complexity as an independent factor.
What carries the argument
Prompt-as-Specification, a Hoare-logic-inspired formalism that interprets every prompt as a specification of intended behavior to generate metrics across 25 complexity dimensions for both prompts and code.
If this is right
- Seven new metrics that tally structurally distinct elements survive filtering and exceed the performance of conventional survivors.
- Prompt-layer metrics retain statistical significance even when the strongest code-level metric is added as a covariate.
- The two best-performing metrics continue to predict maintenance effort on 20 components from six held-out repositories.
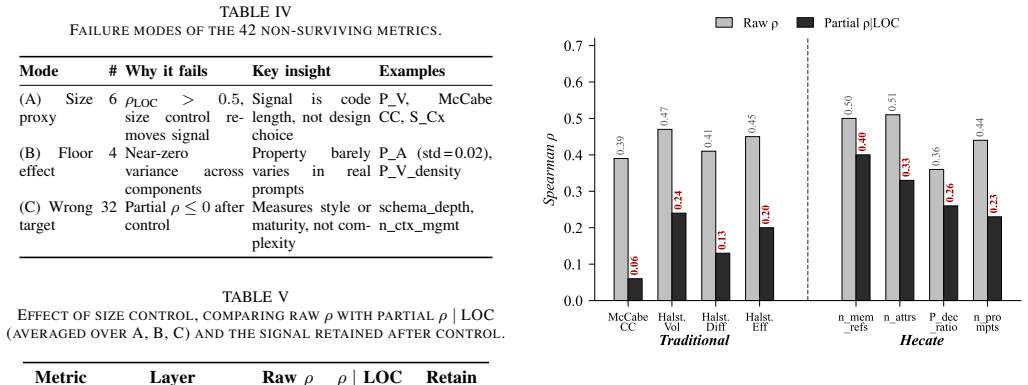
- RFC among conventional metrics shows a similar breadth-oriented character, while Halstead N and V survive only as a residual effect of size.
Where Pith is reading between the lines
- Development teams might track structural breadth in prompts during reviews to anticipate future maintenance effort.
- The approach could be adapted to measure complexity in other hybrid systems that combine natural language instructions with executable code.
- Automated checks based on these metrics might flag prompts with high numbers of distinct templates or call sites before deployment.
Load-bearing premise
Maintenance activity derived from version history serves as a valid empirical proxy for complexity.
What would settle it
If the top prompt-layer metrics lose their ability to predict maintenance activity on additional LLM-integrated applications after code size is controlled for, the claim that they capture an independent dimension would not hold.
Figures


read the original abstract
LLM-integrated applications blend natural language prompts with program code, and much of their runtime behavior originates in the prompt layer rather than in the code itself. Existing complexity metrics, however, operate solely at the code level and therefore overlook this behavioral logic entirely. We present HECATE, the first tool designed to assess complexity in both the prompt and code layers of such applications. Central to HECATE is Prompt-as-Specification, a Hoare-logic-inspired formalism that interprets every prompt as a specification of intended behavior. Grounded in 25 complexity dimensions identified across published taxonomies, the tool generates 52 candidate metrics. We assess each metric against 118 components collected from 18 open-source repositories, relying on maintenance activity derived from version history as an empirical proxy for complexity, and discard any metric that loses significance once code size is accounted for. Only ten metrics withstand this test. Seven belong to our newly introduced set; rather than measuring sheer volume, each tallies structurally distinct elements, such as LLM call sites, memory attributes, and prompt templates, an attribute we call structural breadth. Of the three surviving conventional metrics, RFC exhibits a similar breadth-oriented character, while Halstead N and V survive only as a residual effect of size; our top-performing metrics exceed all three. Crucially, the prompt-layer metrics retain significance even when the strongest code-level metric is added as a covariate, establishing prompt complexity as a dimension in its own right. A final validation on 20 components spanning six held-out repositories shows that the two best-performing metrics continue to predict maintenance effort, supporting their generalizability beyond the training set.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that conventional code-only complexity metrics miss the prompt layer in LLM-integrated applications. It introduces the HECATE tool and a Prompt-as-Specification formalism to generate 52 candidate metrics across 25 dimensions drawn from existing taxonomies. These are evaluated on 118 components from 18 repositories using maintenance activity (from version history) as a proxy for complexity; metrics are discarded if they lose significance after controlling for code size. Ten metrics survive (seven new, three conventional), with prompt-layer metrics retaining significance even after adding the strongest code metric as a covariate. A held-out validation on 20 components from six additional repositories supports generalizability of the top two metrics.
Significance. If the maintenance-activity proxy is accepted as valid, the result is significant because it supplies the first empirical demonstration that prompt-layer metrics capture an independent complexity dimension orthogonal to code size and conventional code metrics. The covariate-control design and held-out validation provide a concrete, falsifiable basis for treating prompt complexity as a distinct construct, which could inform new tooling and evaluation practices for hybrid LLM systems. The structural-breadth interpretation of the surviving metrics also offers a constructive alternative to volume-based measures.
major comments (2)
- [Abstract / filtering procedure] Abstract and the filtering procedure: the central claim that prompt metrics establish an independent dimension rests entirely on the upstream filtering step that retains only metrics whose association with maintenance activity survives control for code size on the 118 components. Maintenance activity (commit count or churn) can be driven by non-complexity factors such as team size, release cadence, or project governance; because the held-out validation re-uses the identical proxy, it cannot adjudicate this confound. Additional controls or external validation of the proxy are required before the independence result can be treated as load-bearing.
- [Abstract] Abstract: 52 metrics are tested against the same outcome variable with a single significance threshold after covariate control, yet no multiple-testing correction is mentioned. Without it, the set of ten retained metrics (and therefore the subsequent regression results) may contain false positives, directly affecting the claim that the top-performing prompt metrics exceed the three conventional survivors.
minor comments (2)
- [Abstract] Abstract: no regression coefficients, standard errors, or exact p-values are reported for the significance claims or the covariate-controlled models, making it impossible to assess effect sizes or the practical magnitude of the retained associations.
- [Methods] The manuscript does not specify how the 25 dimensions were selected or aggregated from the published taxonomies, nor does it provide the exact operational definitions of the 52 candidate metrics; this information is needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating revisions where feasible while remaining honest about the scope of the current study.
read point-by-point responses
-
Referee: [Abstract / filtering procedure] Abstract and the filtering procedure: the central claim that prompt metrics establish an independent dimension rests entirely on the upstream filtering step that retains only metrics whose association with maintenance activity survives control for code size on the 118 components. Maintenance activity (commit count or churn) can be driven by non-complexity factors such as team size, release cadence, or project governance; because the held-out validation re-uses the identical proxy, it cannot adjudicate this confound. Additional controls or external validation of the proxy are required before the independence result can be treated as load-bearing.
Authors: We agree that maintenance activity is an imperfect proxy potentially influenced by non-complexity factors. Our design already controls for code size, and the held-out set provides evidence of generalizability across repositories. In revision we will add an expanded Limitations subsection that explicitly discusses alternative drivers (team size, governance, release cadence) and will qualify the independence claim to reflect this. We will also suggest how future work could incorporate such covariates. However, collecting new metadata or external validation lies outside the present study. revision: partial
-
Referee: [Abstract] Abstract: 52 metrics are tested against the same outcome variable with a single significance threshold after covariate control, yet no multiple-testing correction is mentioned. Without it, the set of ten retained metrics (and therefore the subsequent regression results) may contain false positives, directly affecting the claim that the top-performing prompt metrics exceed the three conventional survivors.
Authors: We accept this criticism. The revised manuscript will re-run the filtering step with Benjamini-Hochberg FDR correction (q = 0.05) and will report both raw and adjusted significance for the ten retained metrics. The comparison of prompt-layer versus conventional metrics will be updated accordingly. revision: yes
- Additional controls or external validation of the maintenance-activity proxy (beyond code-size covariate control) cannot be supplied within the current study.
Circularity Check
No significant circularity; empirical validation uses independent external proxy data
full rationale
The paper generates 52 candidate metrics from 25 dimensions drawn from published external taxonomies, then evaluates and filters them against maintenance activity derived from version history on 118 components (with held-out validation on 20 components from six repositories). The central claim—that prompt-layer metrics retain significance after controlling for the strongest code-level metric—rests on this external-outcome regression, not on any derivation that reduces to fitted parameters or self-citations by construction. No equations, uniqueness theorems, or ansatzes are invoked that collapse the result to its inputs. This is the normal case of a self-contained empirical study against independent benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- significance threshold after covariate control
axioms (2)
- domain assumption Maintenance activity from version history is a valid proxy for complexity
- domain assumption The 25 complexity dimensions from published taxonomies are sufficient to generate relevant metrics for LLM apps
invented entities (1)
-
Prompt-as-Specification formalism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Linet al., “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
2024
-
[2]
The Rise and Potential of Large Language Model Based Agents: A Survey
Z. Xi, W. Chen, X. Guo, W. He, Y . Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhouet al., “The rise and potential of large language model based agents: A survey,”arXiv preprint arXiv:2309.07864, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
T. Guo, X. Chen, Y . Wang, R. Chang, S. Pei, N. V . Chawla, O. Wiest, and X. Zhang, “Large language model based multi-agents: A survey of progress and challenges,”arXiv preprint arXiv:2402.01680, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
MetaGPT: Meta programming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Linet al., “MetaGPT: Meta programming for a multi-agent collaborative framework,” inICLR, 2024
2024
-
[5]
LangChain: Building applications with LLMs through com- posability,
H. Chase, “LangChain: Building applications with LLMs through com- posability,” https://github.com/langchain-ai/langchain, 2023
2023
-
[6]
A validation of object- oriented design metrics as quality indicators,
V . R. Basili, L. C. Briand, and W. L. Melo, “A validation of object- oriented design metrics as quality indicators,”IEEE Transactions on Software Engineering, vol. 22, no. 10, pp. 751–761, 1996
1996
-
[7]
Hidden technical debt in machine learning systems,
D. Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V . Chaudhary, M. Young, J.-F. Crespo, and D. Dennison, “Hidden technical debt in machine learning systems,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 28, 2015, pp. 2503– 2511
2015
-
[8]
A complexity measure,
T. J. McCabe, “A complexity measure,”IEEE Transactions on Software Engineering, vol. SE-2, no. 4, pp. 308–320, 1976
1976
-
[9]
M. H. Halstead,Elements of Software Science. Elsevier, 1977
1977
-
[10]
A metrics suite for object oriented design,
S. R. Chidamber and C. F. Kemerer, “A metrics suite for object oriented design,”IEEE Transactions on Software Engineering, vol. 20, no. 6, pp. 476–493, 1994
1994
-
[11]
Exploring the relationships between design measures and software quality in object- oriented systems,
L. C. Briand, J. W ¨ust, J. W. Daly, and D. V . Porter, “Exploring the relationships between design measures and software quality in object- oriented systems,”Journal of Systems and Software, vol. 51, no. 3, pp. 245–273, 2000
2000
-
[12]
Radon: Various code metrics for Python code,
M. Lacchia, “Radon: Various code metrics for Python code,” https:// github.com/rubik/radon, 2024
2024
-
[13]
Lizard: A simple code complexity analyser,
T. Yin, “Lizard: A simple code complexity analyser,” https://github.com/ terryyin/lizard, 2024
2024
-
[14]
The confounding effect of class size on the validity of object-oriented metrics,
K. El Emam, S. Benlarbi, N. Goel, and S. N. Rai, “The confounding effect of class size on the validity of object-oriented metrics,”IEEE Transactions on Software Engineering, vol. 27, no. 7, pp. 630–650, 2001
2001
-
[15]
How far we have progressed in the journey? An examination of cross- project defect prediction,
Y . Zhou, Y . Yang, H. Lu, L. Chen, Y . Li, Y . Zhao, J. Qian, and B. Xu, “How far we have progressed in the journey? An examination of cross- project defect prediction,”ACM Transactions on Software Engineering and Methodology, vol. 27, no. 1, pp. 1:1–1:51, 2018
2018
-
[16]
An axiomatic basis for computer programming,
C. A. R. Hoare, “An axiomatic basis for computer programming,” Communications of the ACM, vol. 12, no. 10, pp. 576–580, 1969
1969
-
[17]
Applying “design by contract
B. Meyer, “Applying “design by contract”,”Computer, vol. 25, no. 10, pp. 40–51, 1992
1992
-
[18]
Inside the Scaffold: A Source-Code Taxonomy of Coding Agent Architectures
B. Rombaut, “Inside the scaffold: A source-code taxonomy of coding agent architectures,”arXiv preprint arXiv:2604.03515, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Benchmarking complex instruction-following with multiple constraints composition,
B. Wen, P. Ke, X. Gu, L. Wu, H. Huanget al., “Benchmarking complex instruction-following with multiple constraints composition,” inNeurIPS Datasets and Benchmarks Track, 2024
2024
-
[20]
PromptDebt: A comprehensive study of technical debt across LLM projects,
A. Aljohani and H. Do, “PromptDebt: A comprehensive study of technical debt across LLM projects,”arXiv preprint arXiv:2509.20497, 2025
-
[21]
Object-oriented metrics that predict maintain- ability,
W. Li and S. M. Henry, “Object-oriented metrics that predict maintain- ability,”Journal of Systems and Software, vol. 23, no. 2, pp. 111–122, 1993
1993
-
[22]
Empirical analysis of CK metrics for object-oriented design complexity: Implications for software defects,
R. Subramanyam and M. S. Krishnan, “Empirical analysis of CK metrics for object-oriented design complexity: Implications for software defects,”IEEE Transactions on Software Engineering, vol. 29, no. 4, pp. 297–310, 2003
2003
-
[23]
Empirical validation of object- oriented metrics on open source software for fault prediction,
T. Gyim ´othy, R. Ferenc, and I. Siket, “Empirical validation of object- oriented metrics on open source software for fault prediction,”IEEE Transactions on Software Engineering, vol. 31, no. 10, pp. 897–910, 2005
2005
-
[24]
Empirical analysis of object-oriented design metrics for predicting high and low severity faults,
Y . Zhou and H. Leung, “Empirical analysis of object-oriented design metrics for predicting high and low severity faults,”IEEE Transactions on Software Engineering, vol. 32, no. 10, pp. 771–789, 2006
2006
-
[25]
Hoare- Prompt: Structural reasoning about program correctness in natural language,
D. S. Bouras, Y . Dai, T. Wang, Y . Xiong, and S. Mechtaev, “Hoare- Prompt: Structural reasoning about program correctness in natural language,”arXiv preprint arXiv:2503.19599, 2025
-
[26]
A taxonomy of prompt defects in LLM systems,
H. Tian, C. Wang, B. Yang, L. Zhang, and Y . Liu, “A taxonomy of prompt defects in LLM systems,”arXiv preprint arXiv:2509.14404, 2025
-
[27]
Unified tool integration for LLMs: A protocol- agnostic approach to function calling,
P. Ding and R. Stevens, “Unified tool integration for LLMs: A protocol- agnostic approach to function calling,”arXiv preprint arXiv:2508.02979, 2025
-
[28]
Predicting fault incidence using software change history,
T. L. Graves, A. F. Karr, J. S. Marron, and H. P. Siy, “Predicting fault incidence using software change history,”IEEE Transactions on Software Engineering, vol. 26, no. 7, pp. 653–661, 2000
2000
-
[29]
Predicting faults using the complexity of code changes,
A. E. Hassan, “Predicting faults using the complexity of code changes,” inProc. 31st Int’l Conf. Software Engineering (ICSE), 2009, pp. 78–88
2009
-
[30]
Don’t touch my code!: Examining the effects of ownership on software quality,
C. Bird, N. Nagappan, B. Murphy, H. C. Gall, and P. T. Devanbu, “Don’t touch my code!: Examining the effects of ownership on software quality,” inProc. 19th ACM SIGSOFT Symp. Foundations of Software Engineering (FSE), 2011, pp. 4–14
2011
-
[31]
An automatic qual- ity evaluation for natural language requirements,
F. Fabbrini, M. Fusani, S. Gnesi, and G. Lami, “An automatic qual- ity evaluation for natural language requirements,” inProc. 7th Int’l Workshop Requirements Engineering: Foundation for Software Quality (REFSQ), 2001
2001
-
[32]
On the correlation between size and metric validity,
Y . Gil and G. Lalouche, “On the correlation between size and metric validity,”Empirical Software Engineering, vol. 22, no. 5, pp. 2585–2611, 2017
2017
-
[33]
Data mining static code attributes to learn defect predictors,
T. Menzies, J. Greenwald, and A. Frank, “Data mining static code attributes to learn defect predictors,”IEEE Transactions on Software Engineering, vol. 33, no. 1, pp. 2–13, 2007
2007
-
[34]
Tornhill,Your Code as a Crime Scene
A. Tornhill,Your Code as a Crime Scene. Pragmatic Bookshelf, 2015
2015
-
[35]
Prompts as software engineering artifacts: A research agenda and preliminary findings,
H. Villamizar, J. Fischbach, A. Korn, A. V ogelsang, and D. Mendez, “Prompts as software engineering artifacts: A research agenda and preliminary findings,”arXiv preprint arXiv:2509.17548, 2025
-
[36]
AI-Generated Smells: An Analysis of Code and Architecture in LLM and Agent-Driven Development
Y . Zhu, N. Tsantalis, and P. C. Rigby, “AI-generated smells: An analysis of code and architecture in LLM and agent-driven development,”arXiv preprint arXiv:2605.02741, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.