Conditional Co-Ablation: Recovering Self-Repair Backups in Transformer Circuits
Pith reviewed 2026-07-03 17:29 UTC · model grok-4.3
The pith
Conditional co-ablation recovers the backup heads that maintain function after primary removal in transformer circuits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
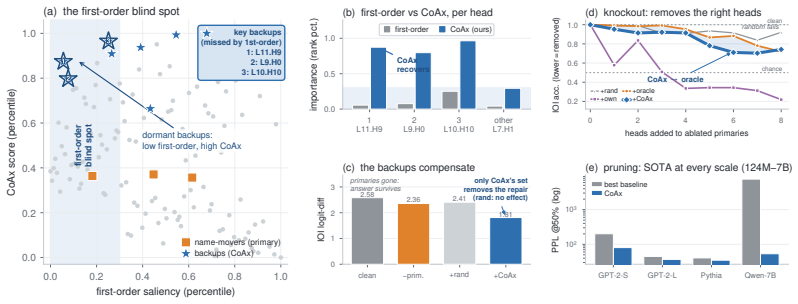
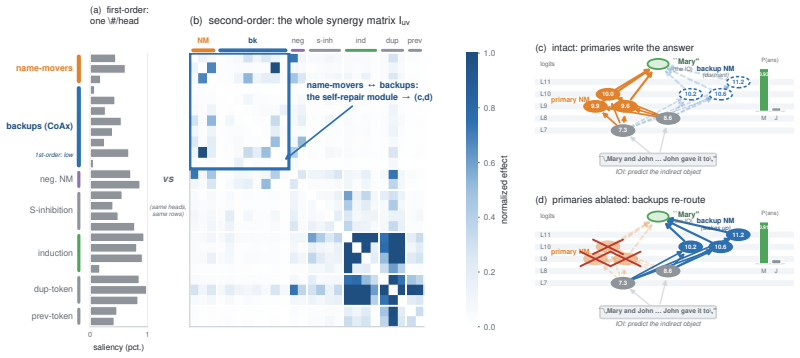
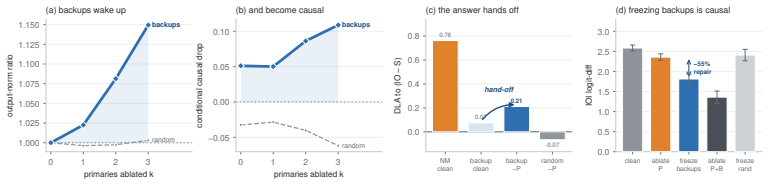
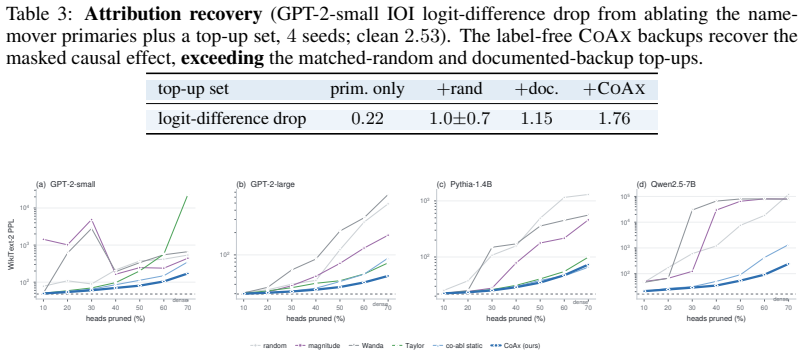
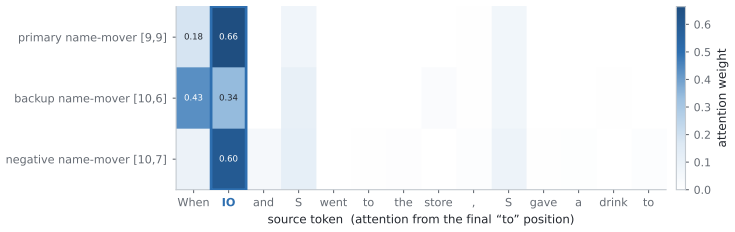
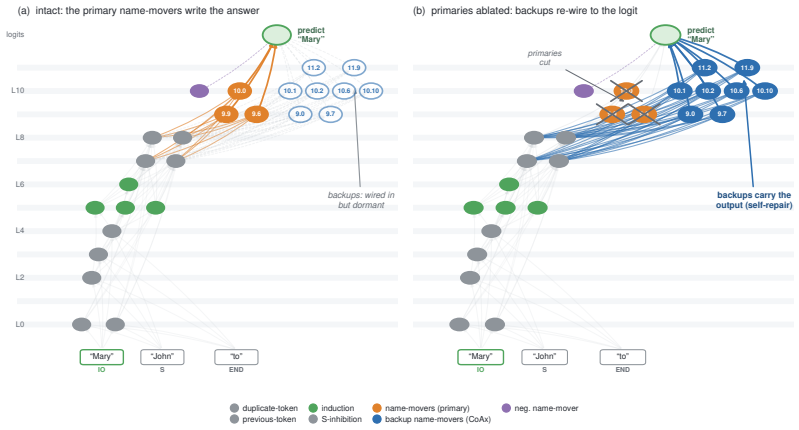
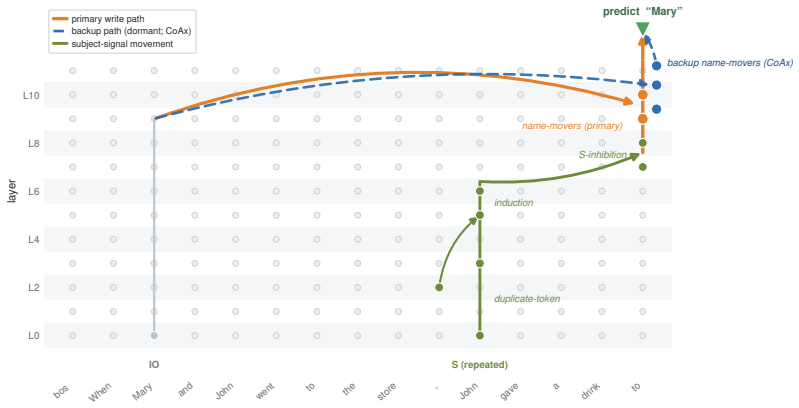
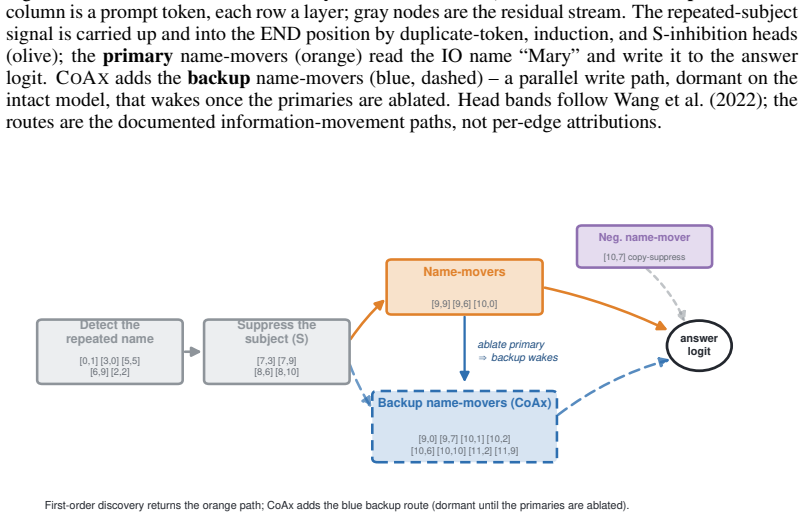
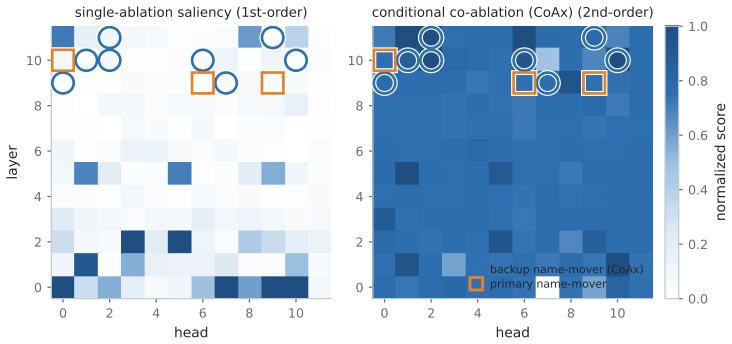
Component importance is not merely an isolated-unit property; in robust circuits the components that matter become visible only under the interventions that make them necessary. Conditional Co-Ablation computes, for each remaining unit, how much its ablation effect grows after a primary set is removed; the resulting score recovers the heads that causally carry the repair, as confirmed by counterfactual patching.
What carries the argument
Conditional Co-Ablation (CoAx), a label-free output-grounded score that quantifies the increase in each remaining unit's ablation effect once a primary set has been removed.
If this is right
- Recovered backups correct self-repair-masked attribution scores.
- The same units identify the minimal set required for capability knockout.
- Repair-aware structured pruning scales from 124M to 7B parameters.
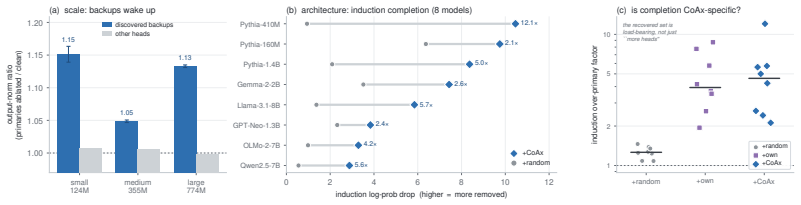
- The label-free procedure transfers to induction-head circuits across eight models.
Where Pith is reading between the lines
- Circuit analysis pipelines may need conditional interventions as a routine second pass rather than relying on single ablations.
- The same growth metric could be applied to identify redundant pathways in non-transformer architectures.
- Repair-aware pruning informed by these scores may preserve performance on downstream tasks better than magnitude-based methods.
Load-bearing premise
Growth in ablation effect after primary removal specifically identifies the causally responsible backup components rather than other correlated units.
What would settle it
Counterfactual patching experiments in which high-CoAx units fail to restore the original behavior when the primary set is removed.
Figures




read the original abstract
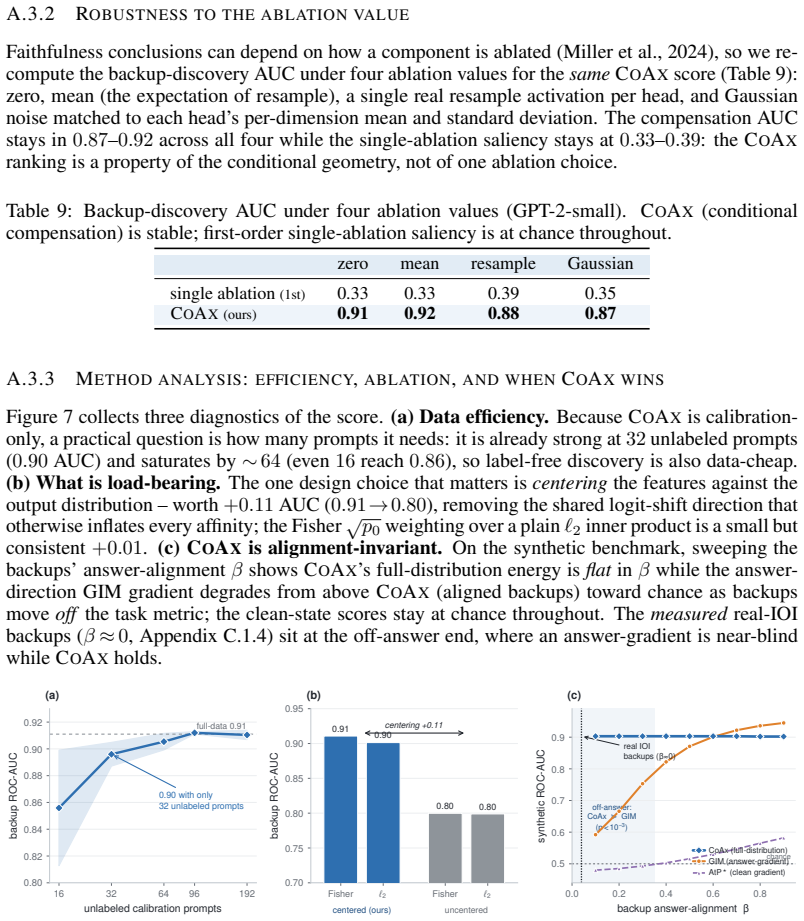
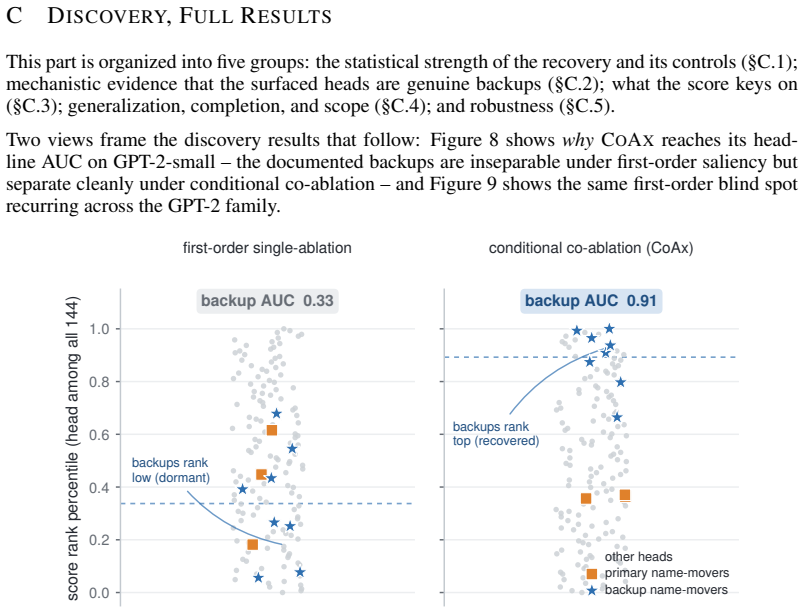
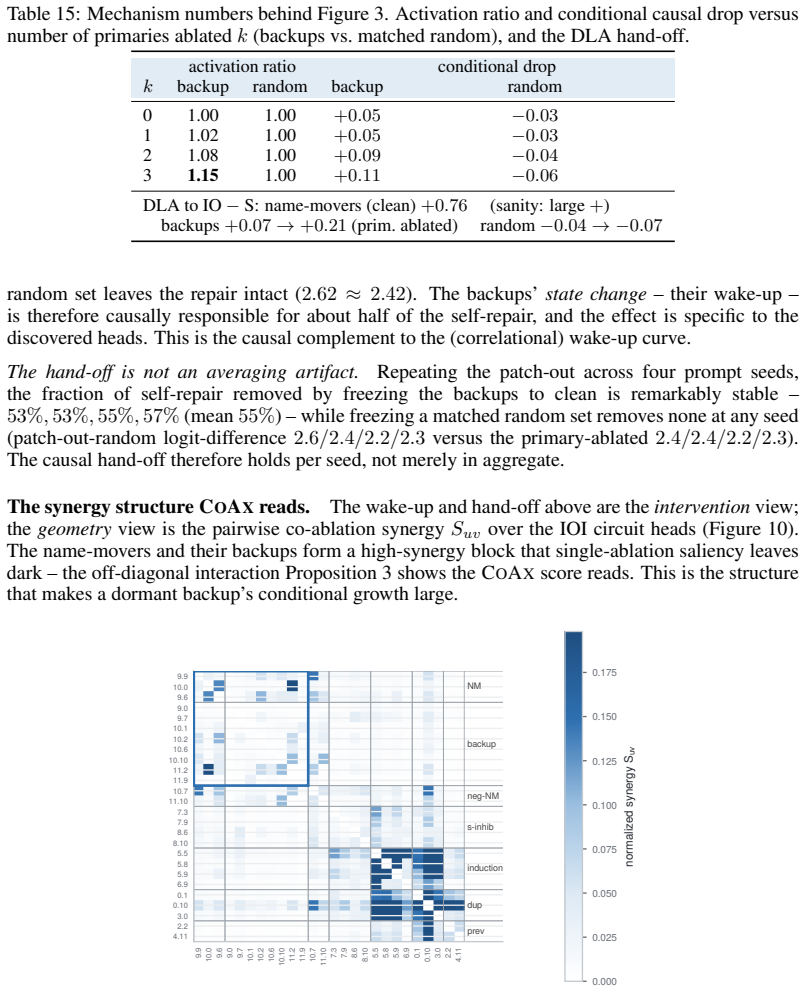
Mechanistic interpretability often relies on component-level interventions to discover how a model produces a behavior. This guides attribution, capability knockout, and model pruning downstream to operate by scoring each unit by the effect of ablation in isolation. Such first-order scoring is natural when component importance is additive, but becomes misleading when a transformer self-repairs: after a primary component is removed, a dormant backup can take over, muting the primary's measured effect while the backup itself appears irrelevant on the intact model. We recast this failure as a recovery task, conditional circuit completion, and introduce Conditional Co-Ablation (CoAx), a label-free, output-grounded score that asks how much each remaining unit's ablation effect grows once a primary set has been removed. This conditional growth exposes the second-order interaction that single-unit scores discard. On the GPT-2-small IOI circuit, CoAx raises backup-head recovery from 0.33 to 0.91 ROC-AUC, outperforming all baselines, including self-repair-aware gradient scores (best 0.82); counterfactual patching verifies that the recovered heads causally carry the repair. The same label-free procedure transfers to induction across eight models. Beyond discovery, the recovered backups correct self-repair-masked attribution, identify the components required for capability knockout, and yield repair-aware structured pruning scaling from 124M to 7B. Component importance is therefore not merely an isolated-unit property: in robust circuits, the components that matter can become visible only under the interventions that make them necessary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Conditional Co-Ablation (CoAx), a label-free score that recovers backup components in self-repairing transformer circuits by quantifying the growth in a unit's ablation effect after a primary set is removed. On the GPT-2-small IOI circuit, CoAx achieves 0.91 ROC-AUC for backup-head recovery (vs. 0.33 for standard ablation and 0.82 for best gradient baseline); counterfactual patching confirms the recovered heads causally implement the repair. The method transfers to induction-head recovery across eight models and improves downstream tasks including attribution correction, capability knockout, and structured pruning up to 7B scale.
Significance. If the empirical results hold, the work provides a concrete advance for mechanistic interpretability by directly addressing self-repair, a known failure mode of first-order ablation scoring. Credit is due for the causal verification step via counterfactual patching on the IOI circuit and for the label-free transfer demonstration across multiple models and scales; these elements strengthen the central claim beyond correlational recovery metrics.
major comments (2)
- [§4.2] §4.2 (CoAx definition and IOI evaluation): the ROC-AUC metric for backup recovery requires an explicit positive set of ground-truth backup heads and exclusion criteria; without these details the reported lift from 0.33 to 0.91 cannot be reproduced or compared to the gradient baseline of 0.82.
- [§5] §5 (counterfactual patching verification): while patching is used to confirm causal contribution of CoAx-recovered heads, the manuscript does not report the magnitude of the repair effect restored or the fraction of total self-repair recovered; this is load-bearing for the claim that the recovered heads 'causally carry the repair'.
minor comments (3)
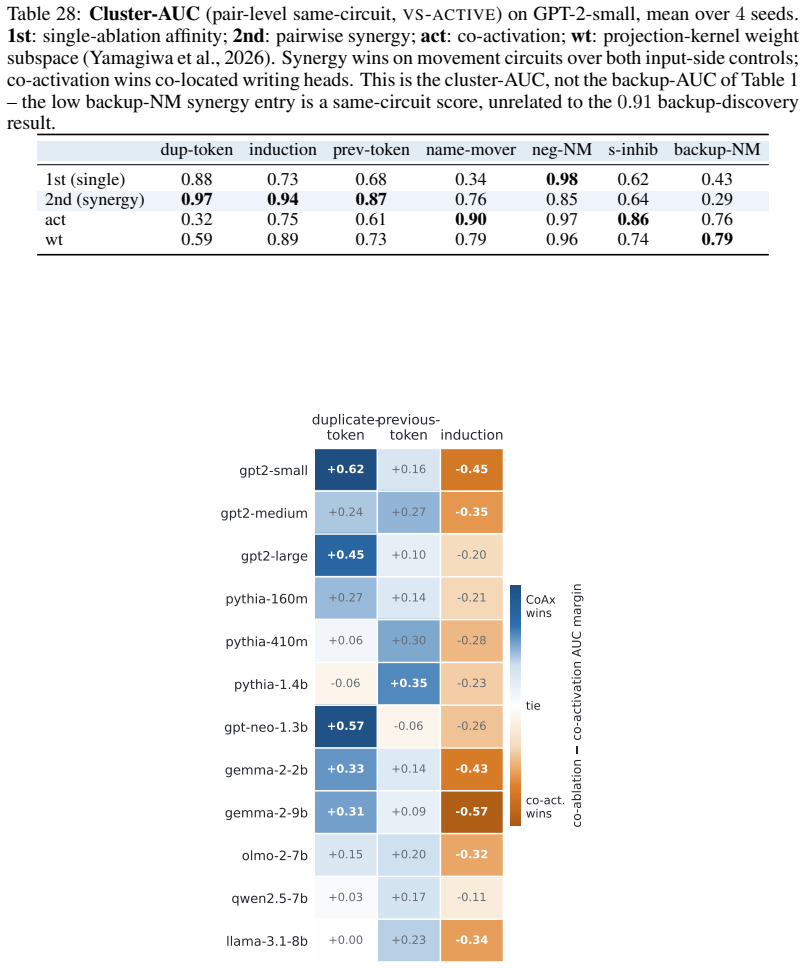
- The induction transfer experiment mentions eight models but provides no per-model breakdown or aggregate statistics; a table summarizing ROC-AUC per model would clarify the scope of generalization.
- No error bars, number of random seeds, or statistical tests accompany the ROC-AUC numbers or pruning scaling curves; adding these would strengthen the performance claims without altering the central argument.
- [§3] Notation for the conditional growth term in the CoAx score (difference of ablation effects) should be defined with an equation number for clarity when contrasting with first-order scores.
Simulated Author's Rebuttal
We thank the referee for the positive summary and recommendation of minor revision. We address each major comment below and will incorporate the requested details into the revised manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (CoAx definition and IOI evaluation): the ROC-AUC metric for backup recovery requires an explicit positive set of ground-truth backup heads and exclusion criteria; without these details the reported lift from 0.33 to 0.91 cannot be reproduced or compared to the gradient baseline of 0.82.
Authors: We agree that explicit specification of the positive set and exclusion criteria is required for reproducibility. The current manuscript defines the positive set as the heads previously identified as backups in the IOI circuit literature (specifically the set of heads whose activation increases after primary ablation) and applies exclusion criteria based on attention-head type and layer range; however, these details are only summarized rather than enumerated. In the revision we will add a dedicated paragraph in §4.2 listing the exact positive-set heads, the exclusion rules, and the precise procedure used to compute the ROC-AUC values, enabling direct reproduction of the 0.91 result and comparison against the 0.82 gradient baseline. revision: yes
-
Referee: [§5] §5 (counterfactual patching verification): while patching is used to confirm causal contribution of CoAx-recovered heads, the manuscript does not report the magnitude of the repair effect restored or the fraction of total self-repair recovered; this is load-bearing for the claim that the recovered heads 'causally carry the repair'.
Authors: We concur that reporting the magnitude of the restored repair effect and the fraction of total self-repair recovered would strengthen the causal claim. The existing counterfactual patching experiment demonstrates that patching the CoAx-recovered heads restores a statistically significant portion of the original circuit behavior, but does not quantify the absolute logit difference or the percentage of the full self-repair gap closed. In the revised §5 we will add these two metrics (restored logit delta and fraction of total repair recovered) computed on the same IOI task, together with the corresponding numbers for the primary heads alone, to make the load-bearing claim fully supported by the reported evidence. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines CoAx directly as a conditional ablation growth score computed from model interventions on the intact and ablated network; this is an empirical procedure, not a derivation that reduces by the paper's own equations to a fitted parameter or prior result. Central claims rest on measured ROC-AUC gains (0.33 to 0.91) and counterfactual patching verification on the IOI circuit, which are independent of any self-citation chain or self-definitional loop. No uniqueness theorems, ansatzes smuggled via citation, or renaming of known results appear as load-bearing steps. The method is self-contained against external benchmarks via patching.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author =. 2021 , journal=
2021
-
[2]
2022 , eprint =
In-context Learning and Induction Heads , author =. 2022 , eprint =
2022
-
[3]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , year =. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2211.00593 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Towards Automated Circuit Discovery for Mechanistic Interpretability , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[5]
2023 , eprint =
Attribution Patching Outperforms Automated Circuit Discovery , author =. 2023 , eprint =
2023
-
[6]
Conference on Language Modeling (COLM) , year =
Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms , author =. Conference on Language Modeling (COLM) , year =
-
[7]
2024 , eprint =
Kram. 2024 , eprint =
2024
-
[8]
2024 , eprint =
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author =. 2024 , eprint =
2024
-
[9]
2024 , eprint =
Information Flow Routes: Automatically Interpreting Language Models at Scale , author =. 2024 , eprint =
2024
-
[10]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Finding Transformer Circuits with Edge Pruning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[11]
International Conference on Learning Representations (ICLR) , year =
Efficient Automated Circuit Discovery in Transformers using Contextual Decomposition , author =. International Conference on Learning Representations (ICLR) , year =
-
[12]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Neuron Shapley: Discovering the Responsible Neurons , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[13]
2023 , eprint =
The Hydra Effect: Emergent Self-repair in Language Model Computations , author =. 2023 , eprint =
2023
-
[14]
International Conference on Machine Learning (ICML) , year =
Explorations of Self-Repair in Language Models , author =. International Conference on Machine Learning (ICML) , year =
-
[15]
2023 , eprint =
Copy Suppression: Comprehensively Understanding an Attention Head , author =. 2023 , eprint =
2023
-
[16]
How Does
Hanna, Michael and Liu, Ollie and Variengien, Alexandre , booktitle =. How Does. 2023 , note =
2023
-
[17]
Correcting Gradient-Based Circuit Localization via Interaction-Aware Backpropagation (
Edin, Joakim and Csord. Correcting Gradient-Based Circuit Localization via Interaction-Aware Backpropagation (. 2025 , eprint =
2025
-
[18]
2026 , eprint =
Hidden Heroes and Gradient Bloats: Layer-Wise Redundancy Inverts Attribution in Transformers , author =. 2026 , eprint =
2026
-
[19]
and Wang, Jun and Luppi, Andrea I
Urbina-Rodriguez, Pedro and Fountas, Zafeirios and Rosas, Fernando E. and Wang, Jun and Luppi, Andrea I. and Bou-Ammar, Haitham and Shanahan, Murray and Mediano, Pedro A. M. , year =. A Brain-like Synergistic Core in. 2601.06851 , archivePrefix =
-
[20]
2026 , eprint =
Measuring Affinity between Attention-Head Weight Subspaces via the Projection Kernel , author =. 2026 , eprint =
2026
-
[21]
Mueller, Aaron and Geiger, Atticus and Wiegreffe, Sarah and others , year =. 2504.13151 , archivePrefix =
-
[22]
Conference on Language Modeling (COLM) , year =
Transformer Circuit Faithfulness Metrics Are Not Robust , author =. Conference on Language Modeling (COLM) , year =
-
[23]
International Conference on Machine Learning (ICML) , year =
Axiomatic Attribution for Deep Networks , author =. International Conference on Machine Learning (ICML) , year =
-
[24]
2023 , eprint =
A Simple and Effective Pruning Approach for Large Language Models , author =. 2023 , eprint =
2023
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year =
A Fast Post-Training Pruning Framework for Transformers , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[26]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Importance Estimation for Neural Network Pruning , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Optimal Brain Damage , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[28]
International Conference on Machine Learning (ICML) , year=
SubspacePath Pruner: Inference-time Pruning via Probe-based Representation--Parameter Coupling , author=. International Conference on Machine Learning (ICML) , year=
-
[29]
Biometrics , volume =
Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach , author =. Biometrics , volume =
-
[30]
Neural Computation , volume =
Natural Gradient Works Efficiently in Learning , author =. Neural Computation , volume =
-
[31]
2020 , howpublished =
Interpreting. 2020 , howpublished =
2020
-
[32]
International Conference on Learning Representations (ICLR) , year =
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods , author =. International Conference on Learning Representations (ICLR) , year =
-
[33]
Distill , year =
Zoom In: An Introduction to Circuits , author =. Distill , year =
-
[34]
Mechanistic Interpretability for
Bereska, Leonard and Gavves, Efstratios , journal=. Mechanistic Interpretability for. 2024 , note =
2024
-
[35]
OpenAI technical report , year =
Language Models are Unsupervised Multitask Learners , author =. OpenAI technical report , year =
-
[36]
International Conference on Machine Learning (ICML) , year =
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author =. International Conference on Machine Learning (ICML) , year =
-
[37]
Black, Sid and Gao, Leo and Wang, Phil and Leahy, Connor and Biderman, Stella , year =
-
[38]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving Open Language Models at a Practical Size , author =. arXiv:2408.00118 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
2. arXiv:2501.00656 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
The Llama 3 Herd of Models , author =. arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Qwen2.5 Technical Report , author =. arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
International Conference on Learning Representations (ICLR) , year =
Pointer Sentinel Mixture Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[43]
Bisk, Yonatan and Zellers, Rowan and Le Bras, Ronan and Gao, Jianfeng and Choi, Yejin , booktitle =
-
[44]
Think You Have Solved Question Answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think You Have Solved Question Answering? Try
-
[45]
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.