Object Aligner: A Configurable JSON Schema Similarity Score for Graphs, Applied to LLM Prompt Optimization
Pith reviewed 2026-07-03 14:52 UTC · model grok-4.3
The pith
Object Aligner scores two JSON objects by aligning their graphs so the result stays the same even if identifiers are swapped.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
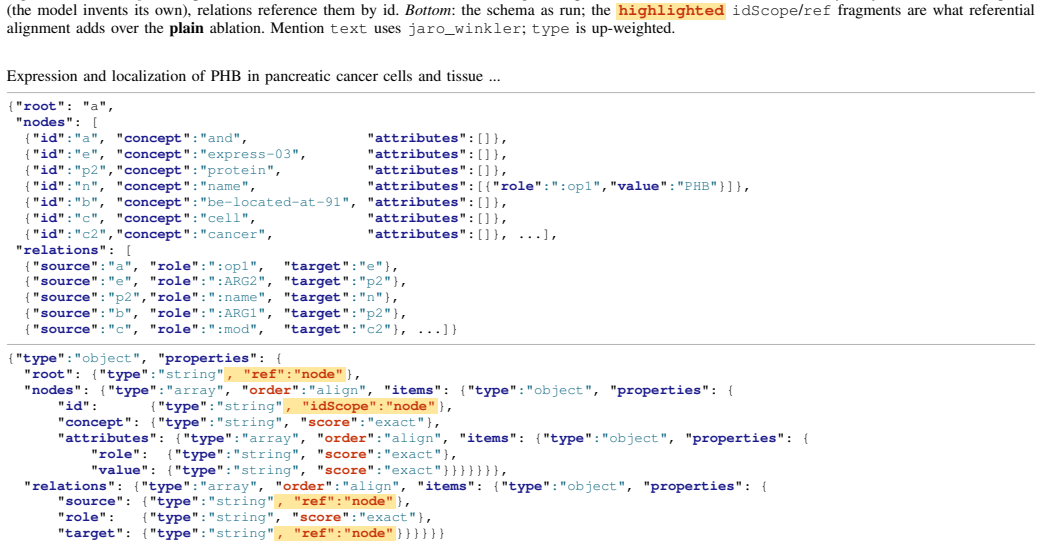
Object Aligner aligns JSON trees with the Hungarian algorithm on unordered collections and sequence alignment on ordered ones, awards partial credit at the granularity declared by the schema, and for graph-structured data applies referential alignment that infers a bijection between gold and candidate identifiers via Weisfeiler-Leman color refinement, rendering the score invariant to relabeling.
What carries the argument
referential alignment, which approximates the identifier bijection required for graph isomorphism using Weisfeiler-Leman color refinement so every reference can be scored consistently regardless of label choice
If this is right
- The same alignment procedure localizes every mismatch and therefore produces ranked repair suggestions at no added cost.
- An order-sensitive sequence regime supports ranking and planning tasks while the unordered regime covers general records.
- Used as a reward inside the GEPA prompt optimizer, Object Aligner improves or stays neutral across all evaluated datasets.
- Adapting the scorer to a new task requires only schema annotations instead of writing alignment code.
Where Pith is reading between the lines
- The method could be tested on knowledge-graph construction tasks where entity identifiers are generated rather than copied from a fixed vocabulary.
- If the approximation remains reliable, the same library might serve as a drop-in replacement for LLM-as-judge in structured-output benchmarks.
- Extending the schema language to declare hypergraph relations would allow the approach to handle cases the current tree-plus-graph model excludes.
Load-bearing premise
Weisfeiler-Leman color refinement recovers identifier bijections accurately enough for the graph-structured JSON cases that appear in LLM prompt optimization, and schema extensions alone can encode all needed alignment rules.
What would settle it
A collection of gold and candidate JSON graphs with deliberately permuted identifiers on which the Object Aligner score diverges markedly from human similarity judgments or from the score obtained with exact bijection recovery.
Figures

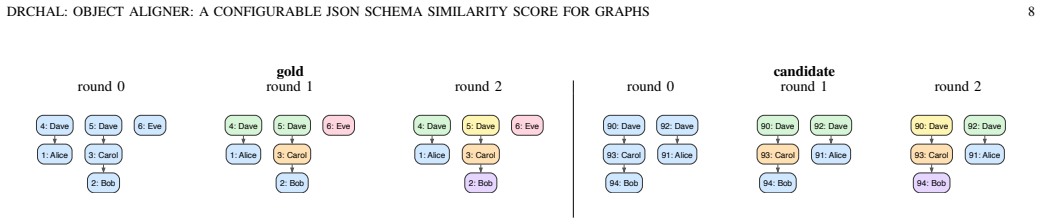

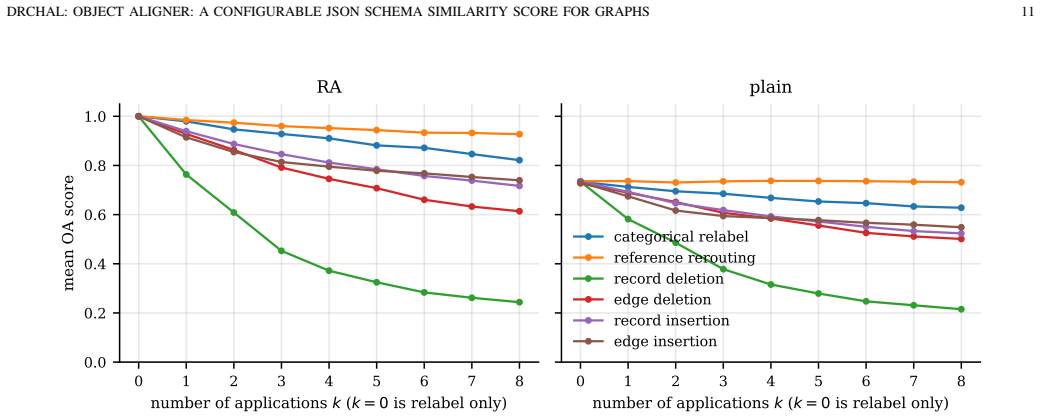
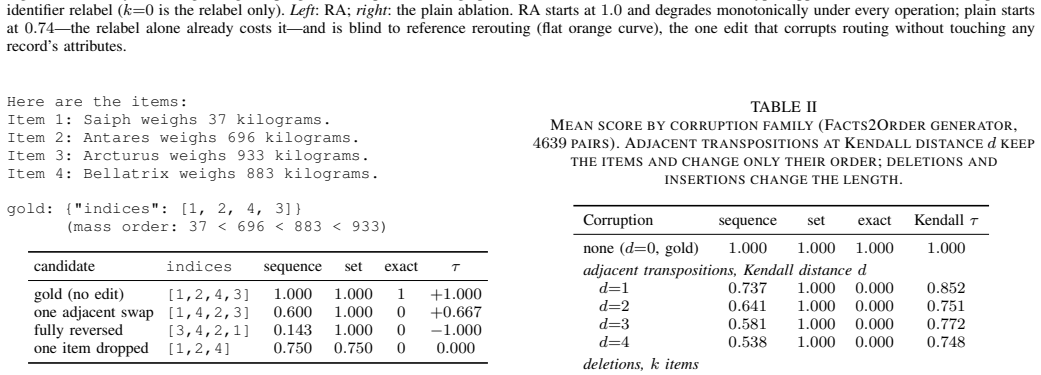
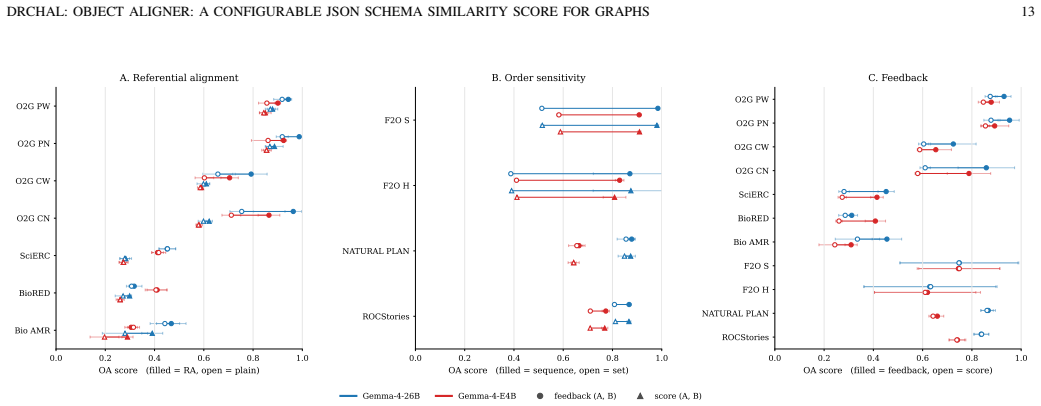
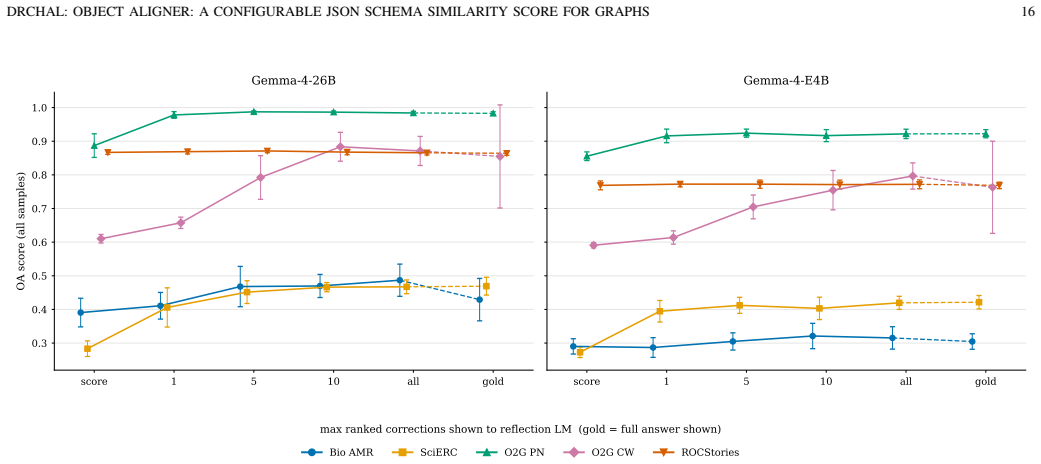







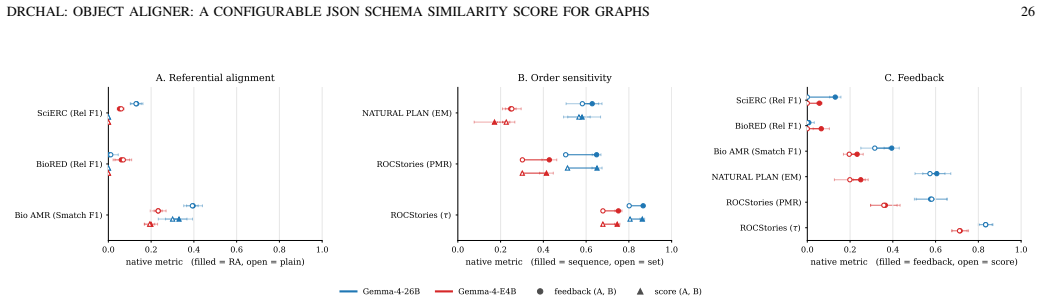
read the original abstract
Large language models (LLMs) are often asked to produce JSON conforming to a fixed schema, powering information extraction, tool calling, agentic planning, and knowledge-graph construction. Measuring how closely an output matches a gold reference is essential yet surprisingly hard: exact match is brittle, text similarity ignores structure, and an LLM judge is expensive, opaque, and non-deterministic. We address this with Object Aligner (OA), an open-source Python library that scores two JSON objects deterministically by recursively aligning their trees (the Hungarian algorithm for unordered collections, sequence alignment for ordered ones) and awarding partial credit at the granularity the schema declares. The Object Aligner is configured entirely through a set of JSON Schema extensions, so adapting it to a new task involves annotating a schema rather than writing code. Complex structured data, however, are rarely flat trees: records may form graphs or hypergraphs keyed by arbitrary identifiers, breaking the assumptions of prior similarity metrics. Our central contribution, referential alignment, closes this gap by inferring a bijection between gold and candidate identifiers and scoring every reference through it, so the score is invariant to relabeling. Since recovering this bijection exactly is graph isomorphism, the Object Aligner approximates it with Weisfeiler-Leman color refinement. An order-sensitive sequence regime targets ranking and planning. Since the same alignment localizes every mismatch, the Object Aligner emits ranked repair suggestions at no extra cost. Used as a reward inside the GEPA prompt optimizer, Object Aligner helps or stays neutral across all datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Object Aligner, an open-source Python library for deterministically scoring JSON similarity via recursive tree alignment (Hungarian algorithm for unordered collections, sequence alignment for ordered ones) configured entirely through JSON Schema extensions. Its central contribution is referential alignment, which infers an identifier bijection via Weisfeiler-Leman color refinement to achieve relabeling invariance for graph-structured JSON; the method also emits ranked repair suggestions. When used as a reward inside the GEPA prompt optimizer, the aligner is claimed to help or stay neutral across all datasets.
Significance. If the empirical and approximation claims hold, the work supplies a practical, deterministic, and schema-configurable metric for structured JSON outputs that handles graph references without requiring custom code, addressing a gap between exact match, text similarity, and expensive LLM judges. The open-source release, mismatch localization, and direct application to prompt optimization are concrete strengths that could improve reproducibility in information extraction and agentic systems.
major comments (2)
- [Abstract] Abstract: the claim that 'Object Aligner helps or stays neutral across all datasets' when used inside GEPA supplies no quantitative results, dataset details, baseline comparisons, error analysis, or ablation studies, which is load-bearing for the central application claim.
- [Abstract] Abstract (referential alignment paragraph): the invariance guarantee rests on Weisfeiler-Leman color refinement recovering identifier bijections, yet the manuscript provides neither a characterization of the JSON graphs arising in GEPA optimization nor any empirical verification against known WL-indistinguishable counterexamples (e.g., certain strongly regular graphs), leaving the approximation's adequacy untested.
minor comments (1)
- [Abstract] Abstract: the phrase 'an order-sensitive sequence regime targets ranking and planning' is introduced without indicating how this regime differs from or integrates with the primary Hungarian/sequence alignment procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Object Aligner helps or stays neutral across all datasets' when used inside GEPA supplies no quantitative results, dataset details, baseline comparisons, error analysis, or ablation studies, which is load-bearing for the central application claim.
Authors: We agree the abstract claim is presented without supporting numbers or details. The experimental section of the manuscript reports the GEPA results across datasets, but the abstract itself does not. We will revise the abstract to include a concise summary sentence referencing the key quantitative outcomes (e.g., number of datasets and observed help/neutral effect) while keeping the abstract length appropriate. revision: yes
-
Referee: [Abstract] Abstract (referential alignment paragraph): the invariance guarantee rests on Weisfeiler-Leman color refinement recovering identifier bijections, yet the manuscript provides neither a characterization of the JSON graphs arising in GEPA optimization nor any empirical verification against known WL-indistinguishable counterexamples (e.g., certain strongly regular graphs), leaving the approximation's adequacy untested.
Authors: The manuscript explicitly frames referential alignment as an approximation because exact bijection recovery is graph isomorphism. We did not provide a characterization of the specific JSON graphs from GEPA or tests on WL counterexamples. We will add a paragraph in the methods or discussion section describing the typical structure of these graphs (sparse references with distinguishing node features) and noting the known limitations of WL, including potential failure cases on strongly regular graphs. This addresses the concern without claiming stronger guarantees than the approximation provides. revision: yes
Circularity Check
No significant circularity; derivation uses standard external algorithms
full rationale
The paper's central mechanism (referential alignment via Weisfeiler-Leman color refinement to approximate identifier bijections, combined with Hungarian/sequence alignment) is defined directly in terms of well-known, independently established algorithms rather than any self-referential quantity, fitted parameter, or prior result by the same authors. No equations or claims reduce the reported similarity score to its own inputs by construction, and the text supplies no load-bearing self-citations or uniqueness theorems that would create a circular chain. The method remains algorithmically self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The Hungarian algorithm optimally solves the assignment problem for matching elements of unordered collections.
- domain assumption Weisfeiler-Leman color refinement provides a practical approximation to graph isomorphism sufficient for identifier bijection recovery.
Reference graph
Works this paper leans on
-
[1]
G-eval: NLG evaluation using GPT-4 with better human alignment,
Y . Liu, D. Iter, Y . Xu, S. Wang, R. Xu, and C. Zhu, “G-eval: NLG evaluation using GPT-4 with better human alignment,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 2511–2522
2023
-
[2]
BERTScore: Evaluating text generation with BERT,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “BERTScore: Evaluating text generation with BERT,” inInternational Conference on Learning Representations, 2020
2020
-
[3]
BLEURT: Learning robust metrics for text generation,
T. Sellam, D. Das, and A. Parikh, “BLEURT: Learning robust metrics for text generation,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Compu- tational Linguistics, Jul. 2020, pp. 7881–7892
2020
-
[4]
COMET: A neural framework for MT evaluation,
R. Rei, C. Stewart, A. C. Farinha, and A. Lavie, “COMET: A neural framework for MT evaluation,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), B. Webber, T. Cohn, Y . He, and Y . Liu, Eds. Online: Association for Computational Linguistics, Nov. 2020, pp. 2685–2702
2020
-
[5]
A systematic survey of automatic prompt optimiza- tion techniques,
K. Ramnathet al., “A systematic survey of automatic prompt optimiza- tion techniques,” inProceedings of the 2025 Conference on Empiri- cal Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Suzhou, China: Association for Computational Linguistics, Nov. 2025, pp. 33 078–33 110
2025
-
[6]
STED and consistency scoring: A framework for eval- uating LLM structured output reliability,
G. Wanget al., “STED and consistency scoring: A framework for eval- uating LLM structured output reliability,” inNeurIPS 2025 Workshop on Structured Probabilistic Inference & Generative Modeling, 2025
2025
-
[7]
Extractbench: A benchmark and evaluation methodology for complex structured extraction, 2026
N. Fergusonet al., “ExtractBench: A benchmark and evaluation methodology for complex structured extraction,” 2026. [Online]. Available: https://arxiv.org/abs/2602.12247
-
[8]
Stickler: A library for evaluating structured data and AI outputs with weighted field comparison and custom comparators,
AWS Labs, “Stickler: A library for evaluating structured data and AI outputs with weighted field comparison and custom comparators,” https://github.com/awslabs/stickler, 2025, software, no accompanying publication; first commit 2025-10-07, version 0.4.0 (May 2026) com- pared here
2025
-
[9]
DSPy: Compiling declarative language model calls into state-of-the-art pipelines,
O. Khattabet al., “DSPy: Compiling declarative language model calls into state-of-the-art pipelines,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[10]
GEPA: Reflective prompt evolution can outper- form reinforcement learning,
L. A. Agrawalet al., “GEPA: Reflective prompt evolution can outper- form reinforcement learning,” inThe Fourteenth International Confer- ence on Learning Representations, 2026
2026
-
[11]
Optimizing generative AI by backpropagating language model feedback,
M. Y ¨uksekg¨on¨ulet al., “Optimizing generative AI by backpropagating language model feedback,”Nature, vol. 639, no. 8055, pp. 609–616, Mar. 2025
2025
-
[12]
The reduction of a graph to canonical form and the algebra which appears therein,
B. Weisfeiler and A. A. Leman, “The reduction of a graph to canonical form and the algebra which appears therein,”Nauchno-Technicheskaya Informatsia, vol. 2, no. 9, pp. 12–16, 1968, english translation by G. Ryabov available online
1968
-
[13]
The tree-to-tree correction problem,
K.-C. Tai, “The tree-to-tree correction problem,”J. ACM, vol. 26, no. 3, pp. 422–433, Jul. 1979
1979
-
[14]
Simple fast algorithms for the editing distance between trees and related problems,
K. Zhang and D. Shasha, “Simple fast algorithms for the editing distance between trees and related problems,”SIAM Journal on Computing, vol. 18, no. 6, pp. 1245–1262, 1989
1989
-
[15]
Tree edit distance: Robust and memory- efficient,
M. Pawlik and N. Augsten, “Tree edit distance: Robust and memory- efficient,”Information Systems, vol. 56, pp. 157–173, 2016
2016
-
[16]
A constrained edit distance between unordered labeled trees,
K. Zhang, “A constrained edit distance between unordered labeled trees,” Algorithmica, vol. 15, no. 3, pp. 205–222, Mar. 1996
1996
-
[17]
X-diff: An effective change detec- tion algorithm for XML documents,
Y . Wang, D. J. DeWitt, and J.-Y . Cai, “X-diff: An effective change detec- tion algorithm for XML documents,” inProceedings 19th International Conference on Data Engineering (Cat. No.03CH37405). Bangalore, India: IEEE Computer Society, 2003, pp. 519–530
2003
-
[18]
The Hungarian method for the assignment problem,
H. W. Kuhn, “The Hungarian method for the assignment problem,” Naval Research Logistics Quarterly, vol. 2, no. 1–2, pp. 83–97, 1955
1955
-
[19]
On coreference resolution performance metrics,
X. Luo, “On coreference resolution performance metrics,” inPro- ceedings of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, R. Mooney, C. Brew, L.-F. Chien, and K. Kirchhoff, Eds. Vancouver, British Columbia, Canada: Association for Computational Linguistics, Oct. 2005, pp. 25–32
2005
-
[20]
A model-theoretic coreference scoring scheme,
M. Vilain, J. Burger, J. Aberdeen, D. Connolly, and L. Hirschman, “A model-theoretic coreference scoring scheme,” inSixth Message Understanding Conference (MUC-6). Association for Computational Linguistics, 1995
1995
-
[21]
Which coreference evaluation metric do you trust? A proposal for a link-based entity aware metric,
N. S. Moosavi and M. Strube, “Which coreference evaluation metric do you trust? A proposal for a link-based entity aware metric,” inProceed- ings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), K. Erk and N. A. Smith, Eds. Berlin, Germany: Association for Computational Linguistics, Aug. 2016, pp. 632–642
2016
-
[22]
Algorithms for scoring coreference chains,
A. Bagga and B. Baldwin, “Algorithms for scoring coreference chains,” inProceedings of the First International Conference on Language Resources and Evaluation (LREC) Workshop on Linguistic Coreference, Granada, Spain, 1998, pp. 563–566
1998
-
[23]
GRIT: Generative role-filler trans- formers for document-level event entity extraction,
X. Du, A. Rush, and C. Cardie, “GRIT: Generative role-filler trans- formers for document-level event entity extraction,” inProceedings of the 16th Conference of the European Chapter of the Association for DRCHAL: OBJECT ALIGNER: A CONFIGURABLE JSON SCHEMA SIMILARITY SCORE FOR GRAPHS 27 Computational Linguistics: Main Volume, P. Merlo, J. Tiedemann, and R....
2021
-
[24]
Iterative document-level information extraction via imitation learning,
Y . Chen, W. Gantt, W. Gu, T. Chen, A. S. White, and B. Van Durme, “Iterative document-level information extraction via imitation learning,” inProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, A. Vlachos and I. Au- genstein, Eds. Dubrovnik, Croatia: Association for Computational Linguistics, May 2...
2023
-
[25]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” inCom- puter Vision – ECCV 2020. Cham: Springer International Publishing, 2020, pp. 213–229
2020
-
[26]
Approximate graph edit distance computation by means of bipartite graph matching,
K. Riesen and H. Bunke, “Approximate graph edit distance computation by means of bipartite graph matching,”Image Vision Comput., vol. 27, no. 7, pp. 950–959, Jun. 2009
2009
-
[27]
Smatch: An evaluation metric for semantic feature structures,
S. Cai and K. Knight, “Smatch: An evaluation metric for semantic feature structures,” inProceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), H. Schuetze, P. Fung, and M. Poesio, Eds. Sofia, Bulgaria: Association for Computational Linguistics, Aug. 2013, pp. 748–752
2013
-
[28]
AMR similarity metrics from principles,
J. Opitz, L. Parcalabescu, and A. Frank, “AMR similarity metrics from principles,”Transactions of the Association for Computational Linguistics, vol. 8, pp. 522–538, 2020
2020
-
[29]
SMATCH++: Standardized and extended evaluation of seman- tic graphs,
J. Opitz, “SMATCH++: Standardized and extended evaluation of seman- tic graphs,” inFindings of the Association for Computational Linguistics: EACL 2023, A. Vlachos and I. Augenstein, Eds. Dubrovnik, Croatia: Association for Computational Linguistics, May 2023, pp. 1595–1607
2023
-
[30]
Weisfeiler-Leman in the Bamboo: Novel AMR graph metrics and a benchmark for AMR graph similarity,
J. Opitz, A. Daza, and A. Frank, “Weisfeiler-Leman in the Bamboo: Novel AMR graph metrics and a benchmark for AMR graph similarity,” Transactions of the Association for Computational Linguistics, vol. 9, pp. 1425–1441, 2021
2021
-
[31]
On valid optimal assign- ment kernels and applications to graph classification,
N. M. Kriege, P.-L. Giscard, and R. C. Wilson, “On valid optimal assign- ment kernels and applications to graph classification,” inProceedings of the 30th International Conference on Neural Information Processing Systems, ser. NIPS’16. Red Hook, NY , USA: Curran Associates Inc., 2016, pp. 1623–1631
2016
-
[32]
DeepDiff: Deep difference and search of any Python object/data,
S. Dehpour, “DeepDiff: Deep difference and search of any Python object/data,” https://github.com/seperman/deepdiff, 2026, version 9.0.0
2026
-
[33]
A theory for record linkage,
I. P. Fellegi and A. B. Sunter, “A theory for record linkage,”Journal of the American Statistical Association, vol. 64, no. 328, pp. 1183–1210, 1969
1969
-
[34]
Splink: Free software for probabilistic record linkage at scale,
R. Linacreet al., “Splink: Free software for probabilistic record linkage at scale,”International Journal of Population Data Science, vol. 7, no. 3, 2022
2022
-
[35]
The entity-relationship model—toward a unified view of data,
P. P.-S. Chen, “The entity-relationship model—toward a unified view of data,”ACM Trans. Database Syst., vol. 1, no. 1, pp. 9–36, Mar. 1976
1976
-
[36]
The Berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models,
S. G. Patilet al., “The Berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models,” in Proceedings of the 42nd International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 267. PMLR, 2025, pp. 48 371–48 392
2025
-
[37]
Beyond the leaderboard: A survey of the science of evaluation, benchmarking, and methodologies for large language models,
S. Sheikhi, L. Lov ´en, and P. Kostakos, “Beyond the leaderboard: A survey of the science of evaluation, benchmarking, and methodologies for large language models,”IEEE Access, vol. 14, pp. 66 493–66 515, 2026
2026
-
[38]
Large language models are human-level prompt engi- neers,
Y . Zhouet al., “Large language models are human-level prompt engi- neers,” inThe Eleventh International Conference on Learning Repre- sentations, 2023
2023
-
[39]
Large language models as optimizers,
C. Yanget al., “Large language models as optimizers,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[40]
Promptbreeder: self-referential self-improvement via prompt evolution,
C. Fernando, D. Banarse, H. Michalewski, S. Osindero, and T. Rockt ¨aschel, “Promptbreeder: self-referential self-improvement via prompt evolution,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[41]
Connecting large language models with evolutionary algorithms yields powerful prompt optimizers,
Q. Guoet al., “Connecting large language models with evolutionary algorithms yields powerful prompt optimizers,” inThe Twelfth Interna- tional Conference on Learning Representations, 2024
2024
-
[42]
Error-driven prompt optimization for arithmetic reasoning: A code generation approach using on-premises small language models on tabular data,
´A. P´andy, R. Lakatos, and A. Hajdu, “Error-driven prompt optimization for arithmetic reasoning: A code generation approach using on-premises small language models on tabular data,”IEEE Access, vol. 14, pp. 62 570–62 583, 2026
2026
-
[43]
Optimizing instructions and demonstrations for multi-stage language model programs,
K. Opsahl-Onget al., “Optimizing instructions and demonstrations for multi-stage language model programs,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, FL, USA: Association for Computational Linguistics, Nov. 2024, pp. 9340–9366
2024
-
[44]
Automatic prompt optimization for knowledge graph construction: Insights from an empirical study,
N. Mihindukulasooriya, N. S. D’Souza, M. F. M. Chowdhury, and H. Samulowitz, “Automatic prompt optimization for knowledge graph construction: Insights from an empirical study,” 2025. [Online]. Available: https://arxiv.org/abs/2506.19773
-
[45]
Symbolic prompt program search: A structure-aware approach to efficient compile-time prompt optimization,
T. Schnabel and J. Neville, “Symbolic prompt program search: A structure-aware approach to efficient compile-time prompt optimization,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, FL, USA: Association for Computational Linguistics, Nov. 2024, pp. 670– 686
2024
-
[46]
FMI@SU ToxHabits: Evaluating LLMs Performance on Toxic Habit Extraction in Spanish Clinical Texts
S. Vassileva, I. Koychev, and S. Boytcheva, “FMI@SU ToxHabits: Evaluating LLMs performance on toxic habit extraction in Spanish clinical texts,” inBioCreative IX Workshop at IJCAI 2025, 2025. [Online]. Available: https://arxiv.org/abs/2604.06403
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Rewarding Smatch: Transition-based AMR parsing with reinforcement learning,
T. Naseem, A. Shah, H. Wan, R. Florian, S. Roukos, and M. Ballesteros, “Rewarding Smatch: Transition-based AMR parsing with reinforcement learning,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M`arquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul. 2019, p...
2019
-
[48]
STRuCT-LLM: Unifying tabular and graph reasoning with reinforcement learning for semantic parsing,
J. L. Stoisser, M. Boubnovski Martell, L. Phillips, C. Hansen, and J. Fauqueur, “STRuCT-LLM: Unifying tabular and graph reasoning with reinforcement learning for semantic parsing,” 2025. [Online]. Available: https://arxiv.org/abs/2506.21575
-
[49]
Advances in record-linkage methodology as applied to matching the 1985 census of Tampa, Florida,
M. A. Jaro, “Advances in record-linkage methodology as applied to matching the 1985 census of Tampa, Florida,”Journal of the American Statistical Association, vol. 84, no. 406, pp. 414–420, 1989
1985
-
[50]
Binary codes capable of correcting deletions, inser- tions, and reversals,
V . I. Levenshtein, “Binary codes capable of correcting deletions, inser- tions, and reversals,”Soviet Physics Doklady, vol. 10, no. 8, pp. 707–710, 1966
1966
-
[51]
Weisfeiler-Lehman graph kernels,
N. Shervashidze, P. Schweitzer, E. J. van Leeuwen, K. Mehlhorn, and K. M. Borgwardt, “Weisfeiler-Lehman graph kernels,”Journal of Machine Learning Research, vol. 12, no. 77, pp. 2539–2561, 2011
2011
-
[52]
A new measure of rank correlation,
M. G. Kendall, “A new measure of rank correlation,”Biometrika, vol. 30, no. 1/2, pp. 81–93, 1938
1938
-
[53]
Multi-task identi- fication of entities, relations, and coreference for scientific knowledge graph construction,
Y . Luan, L. He, M. Ostendorf, and H. Hajishirzi, “Multi-task identi- fication of entities, relations, and coreference for scientific knowledge graph construction,” inProceedings of the 2018 Conference on Empir- ical Methods in Natural Language Processing, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, Eds. Brussels, Belgium: Association for Computa...
2018
-
[54]
Assessment of Generative Named Entity Recognition in the Era of Large Language Models
Q. Zhan, Y . Wang, and H. Huang, “Assessment of generative named entity recognition in the era of large language models,” 2026. [Online]. Available: https://arxiv.org/abs/2601.17898
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
BioRED: a rich biomedical relation extraction dataset,
L. Luo, P.-T. Lai, C.-H. Wei, C. N. Arighi, and Z. Lu, “BioRED: a rich biomedical relation extraction dataset,”Briefings in Bioinformatics, vol. 23, no. 5, p. bbac282, 2022
2022
-
[56]
Bio AMR corpus, release 3.0,
USC Information Sciences Institute, “Bio AMR corpus, release 3.0,” https://amr.isi.edu/download.html, 2018, amr-release-bio-v3.0;∼6,900 biomedical sentences
2018
-
[57]
Abstract Meaning Representation for sembanking,
L. Banarescuet al., “Abstract Meaning Representation for sembanking,” inProceedings of the 7th Linguistic Annotation Workshop and Interop- erability with Discourse, A. Pareja-Lora, M. Liakata, and S. Dipper, Eds. Sofia, Bulgaria: Association for Computational Linguistics, Aug. 2013, pp. 178–186
2013
-
[58]
H. S. Zhenget al., “NATURAL PLAN: Benchmarking LLMs on natural language planning,” 2024. [Online]. Available: https: //arxiv.org/abs/2406.04520
-
[59]
A corpus and cloze evaluation for deeper understanding of commonsense stories,
N. Mostafazadehet al., “A corpus and cloze evaluation for deeper understanding of commonsense stories,” inProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, K. Knight, A. Nenkova, and O. Rambow, Eds. San Diego, CA, USA: Association for Computational Linguistics, J...
2016
-
[60]
GPT-5 system card,
OpenAI, “GPT-5 system card,” https://cdn.openai.com/ gpt-5-system-card.pdf, 2025, published 2025-08-07; reflection model uses thegpt-5-2025-08-07snapshot. Accessed: 2026-06-28
2025
-
[61]
Gemma 4 model card,
Gemma Team, Google DeepMind, “Gemma 4 model card,” https://ai.google.dev/gemma/docs/core/model card 4, 2026, open- weights model family; task models are thegemma-4-26B-A4B-it andgemma-4-E4B-itinstruction-tuned variants. Accessed: 2026- 06-28
2026
-
[62]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” https: //qwen.ai/blog?id=qwen3.5, 2026, blog post; published February 2026. Accessed: 2026-06-28. DRCHAL: OBJECT ALIGNER: A CONFIGURABLE JSON SCHEMA SIMILARITY SCORE FOR GRAPHS 28
2026
-
[63]
Collective entity resolution in relational data,
I. Bhattacharya and L. Getoor, “Collective entity resolution in relational data,”ACM Trans. Knowl. Discov. Data, vol. 1, no. 1, pp. 5–es, Mar. 2007
2007
-
[64]
Weisfeiler and Leman go neural: higher-order graph neural networks,
C. Morriset al., “Weisfeiler and Leman go neural: higher-order graph neural networks,” inProceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Ap- plications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, ser. AAAI’19/IAAI’19/EAAI’19. AAAI ...
2019
-
[65]
Is everything in order? a simple way to order sentences,
S. Basu Roy Chowdhury, F. Brahman, and S. Chaturvedi, “Is everything in order? a simple way to order sentences,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, M.- F. Moens, X. Huang, L. Specia, and S. W.-t. Yih, Eds. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, Nov. 2021,...
2021
-
[66]
Maximum Bayes Smatch ensemble distillation for AMR parsing,
Y .-S. Lee, R. Astudillo, H. Thanh Lam, T. Naseem, R. Florian, and S. Roukos, “Maximum Bayes Smatch ensemble distillation for AMR parsing,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Seattle, United States: Association for Computational Linguistics, Jul....
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.