PACE: A Proxy for Agentic Capability Evaluation
Pith reviewed 2026-07-03 13:31 UTC · model grok-4.3
The pith
A small curated subset of non-agentic tests can predict LLM agent performance on expensive benchmarks via regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
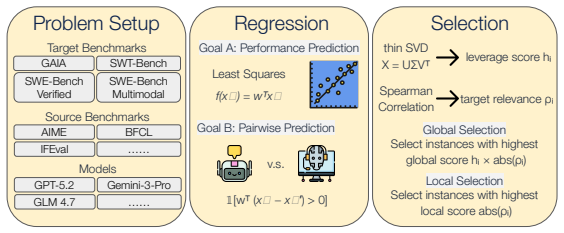
PACE constructs proxy benchmarks by selecting instances from existing non-agentic evaluations whose aggregate scores most reliably predict model performances on agentic benchmarks. It fits a regression that maps a model's scores on a compact subset of source instances to its score on the target agentic benchmark, using target-relevance local selection and globally informative global selection to curate the subset. Experiments across 14 models, 4 agentic benchmarks, and 19 non-agentic benchmarks show that the resulting PACE-Bench predicts agentic scores with leave-one-out cross-validation mean absolute error under 4%, Spearman correlation above 0.80, and pairwise model-ranking accuracy around
What carries the argument
PACE framework, which curates a compact subset of atomic instances from non-agentic benchmarks via local and global selection strategies and fits a regression to map subset scores to agentic benchmark scores.
If this is right
- Proxy benchmarks allow reliable estimates of agentic performance at under 1% of full evaluation cost during model development.
- The selected instances reveal which atomic skills each agentic benchmark uniquely demands.
- The same proxy supports model selection and routing decisions without running complete agent evaluations.
- Performance predictions remain stable across the tested set of 14 models with high ranking accuracy.
Where Pith is reading between the lines
- If the regression generalizes, agentic tasks largely decompose into measurable atomic capabilities already covered by existing non-agentic tests.
- The method could be re-applied to additional agentic targets or new non-agentic pools to create domain-specific proxies.
- Future models whose capability distributions differ markedly from the training set may require fresh instance selection to maintain accuracy.
Load-bearing premise
That a regression fitted on scores from the selected non-agentic instances will generalize to predict agentic benchmark performance for new models.
What would settle it
Apply the fitted PACE-Bench regression to a new model outside the original 14 and measure whether the absolute error on an agentic benchmark exceeds 4% on average.
Figures



read the original abstract
Evaluating LLM agents on benchmarks like SWE-Bench and GAIA can be expensive, time-consuming, and requires complex infrastructure. A single evaluation can cost thousands of dollars and take days to complete. In contrast, non-agentic LLM benchmarks that test individual capabilities (e.g., reasoning, code generation) are fast and cheap to run. In this paper, we investigate whether performance on expensive agentic benchmarks can be accurately predicted by the performance on a small, carefully selected subset of atomic evaluation instances. We introduce PACE, a framework that constructs proxy benchmarks by selecting instances from existing non-agentic evaluations whose aggregate scores most reliably predict model performances on agentic benchmarks. Given a pool of candidate instances spanning atomic capabilities, PACE fits a regression that maps a model's scores on a compact subset of source instances to its score on the target agentic benchmark. The subset itself is curated by combining two complementary instance-selection strategies, target-relevance local selection and globally informative global selection. We apply PACE to the 4 target agentic benchmarks in this paper, which yields PACE-Bench, the concrete proxy benchmark that we evaluate in the paper. Experiments across 14 models, 4 agentic benchmarks, and 19 non-agentic benchmarks show that PACE-Bench predicts agentic scores with leave-one-out cross-validation (LOOCV) mean absolute error (MAE) under 4%, Spearman correlation above 0.80, and pairwise model-ranking accuracy around 85%, all at much less than 1% of the full agentic evaluation cost. We further analyze the selected proxy instances, revealing which skills each agentic benchmark uniquely demands. PACE enables practitioners to obtain reliable estimates of agentic performance during model development, selection, and routing, without the overhead of full agent evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the PACE framework for constructing compact proxy benchmarks (PACE-Bench) from subsets of instances drawn from 19 non-agentic LLM evaluations. These proxies are selected via target-relevance local selection and globally informative global selection, then used to fit a regression predicting scores on four target agentic benchmarks (including SWE-Bench and GAIA). On 14 models, LOOCV yields MAE under 4%, Spearman correlation above 0.80, and ~85% pairwise ranking accuracy at <1% of full agentic evaluation cost; the paper also analyzes which atomic skills each agentic benchmark requires.
Significance. If the reported predictive accuracy generalizes to new models, PACE would materially reduce the cost and infrastructure burden of agentic evaluation, enabling faster iteration during development and routing. The skill-analysis component provides additional value by linking agentic performance to specific non-agentic capabilities. The multi-benchmark experimental design and use of LOOCV are positive features, though the strength of the central claim depends on whether selection bias is properly controlled.
major comments (2)
- [Abstract] Abstract and the description of the evaluation procedure: the LOOCV results (MAE <4%, Spearman >0.80, ranking accuracy ~85%) are obtained after applying the two instance-selection strategies to the pool of 14 models. The manuscript does not state whether subset selection occurs inside the leave-one-out loop or on the full model pool before CV begins. If the latter, the metrics are optimistically biased for truly unseen models and the generalization claim for new models during development is untested.
- [Experiments section (implied by abstract)] The regression step and selection algorithm: the abstract and experimental section provide no explicit description of the regression form (linear, regularized, etc.), the precise implementation of target-relevance local selection versus globally informative global selection, or any ablation that isolates the contribution of each strategy. These details are load-bearing for reproducing the reported correlations and for assessing whether the proxy is overfit to the particular 14-model distribution.
minor comments (1)
- [Abstract] The abstract should state the typical size of the selected PACE-Bench subset (number of instances) for each target benchmark to give readers an immediate sense of the cost reduction.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments identify important issues around evaluation procedure and methodological transparency. We address each below and commit to revisions that improve rigor and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of the evaluation procedure: the LOOCV results (MAE <4%, Spearman >0.80, ranking accuracy ~85%) are obtained after applying the two instance-selection strategies to the pool of 14 models. The manuscript does not state whether subset selection occurs inside the leave-one-out loop or on the full model pool before CV begins. If the latter, the metrics are optimistically biased for truly unseen models and the generalization claim for new models during development is untested.
Authors: We appreciate this observation on potential bias. The manuscript text indicates that selection strategies were applied to the full pool of 14 models prior to LOOCV, which does create the risk of optimistic bias for truly unseen models. We will revise the Experiments section to explicitly describe the current procedure, acknowledge the limitation for generalization claims, and add results from an inner-loop selection variant (selection performed within each LOOCV fold) to quantify the difference and provide a more conservative estimate. revision: yes
-
Referee: [Experiments section (implied by abstract)] The regression step and selection algorithm: the abstract and experimental section provide no explicit description of the regression form (linear, regularized, etc.), the precise implementation of target-relevance local selection versus globally informative global selection, or any ablation that isolates the contribution of each strategy. These details are load-bearing for reproducing the reported correlations and for assessing whether the proxy is overfit to the particular 14-model distribution.
Authors: We agree these details are essential for reproducibility and for evaluating potential overfitting. The current manuscript omits them. In the revision we will add a dedicated Methods subsection that (a) specifies the regression form and any regularization, (b) provides precise algorithmic descriptions (including equations or pseudocode) for both selection strategies, and (c) includes ablation experiments that isolate the contribution of local versus global selection as well as comparisons to random and single-strategy baselines. revision: yes
Circularity Check
Instance selection on full 14-model pool before LOOCV creates optimistic bias in proxy performance metrics
specific steps
-
fitted input called prediction
[Abstract]
"The subset itself is curated by combining two complementary instance-selection strategies, target-relevance local selection and globally informative global selection. ... Experiments across 14 models, 4 agentic benchmarks, and 19 non-agentic benchmarks show that PACE-Bench predicts agentic scores with leave-one-out cross-validation (LOOCV) mean absolute error (MAE) under 4%, Spearman correlation above 0.80, and pairwise model-ranking accuracy around 85%"
The two selection strategies operate on the full set of 14 models' scores to choose instances whose aggregate best predicts the agentic targets for exactly those models. LOOCV is then applied only after this fixed subset has been chosen, so the quoted performance numbers reflect a selection process already tuned to the evaluation distribution rather than an independent prediction.
full rationale
The paper's central claim rests on curating a subset of non-agentic instances via data-driven strategies that explicitly use the 14 models' scores to predict agentic performance, then reporting LOOCV metrics on the resulting regression. Because selection occurs outside the CV loop on the same model pool used for evaluation, the reported MAE <4%, Spearman >0.80 and ranking accuracy ~85% are partially forced by the selection step rather than representing generalization to unseen models. No equations reduce by algebraic identity and no self-citation chain is load-bearing; the circularity is limited to the non-nested selection procedure.
Axiom & Free-Parameter Ledger
free parameters (2)
- regression coefficients
- selected instance subset size and composition
axioms (1)
- domain assumption Non-agentic atomic capability tests can be aggregated to predict complex agentic task performance
invented entities (1)
-
PACE-Bench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
NeurIPS , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[4]
2023 , eprint=
Instruction-Following Evaluation for Large Language Models , author=. 2023 , eprint=
2023
-
[5]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Logiqa: A challenge dataset for machine reading comprehension with logical reasoning , author=. arXiv preprint arXiv:2007.08124 , year=
-
[7]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Debugbench: Evaluating debugging capability of large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[10]
Transactions on Machine Learning Research , issn=
Holistic Evaluation of Language Models , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[11]
A survey on large language model based autonomous agents.Frontiers Comput
Wang, Lei and Ma, Chen and Feng, Xueyang and Zhang, Zeyu and Yang, Hao and Zhang, Jingsen and Chen, Zhiyuan and Tang, Jiakai and Chen, Xu and Lin, Yankai and Zhao, Wayne Xin and Wei, Zhewei and Wen, Jirong , year=. A survey on large language model based autonomous agents , volume=. Frontiers of Computer Science , publisher=. doi:10.1007/s11704-024-40231-1...
-
[12]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[13]
The Twelfth International Conference on Learning Representations , year=
Gr. The Twelfth International Conference on Learning Representations , year=
-
[14]
The Twelfth International Conference on Learning Representations , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. The Twelfth International Conference on Learning Representations , year=
-
[15]
The Thirteenth International Conference on Learning Representations , year=
Commit0: Library Generation from Scratch , author=. The Thirteenth International Conference on Learning Representations , year=
-
[16]
arXiv preprint arXiv:2501.14723 , year=
CodeMonkeys: Scaling Test-Time Compute for Software Engineering , author =. Preprint , year =. doi:10.48550/arXiv.2501.14723 , url =
-
[17]
Transactions on Machine Learning Research , year=
Cognitive architectures for language agents , author=. Transactions on Machine Learning Research , year=
-
[18]
Science China Information Sciences , volume=
The rise and potential of large language model based agents: A survey , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[19]
Efficient Benchmarking (of Language Models)
Perlitz, Yotam and Bandel, Elron and Gera, Ariel and Arviv, Ofir and Ein-Dor, Liat and Shnarch, Eyal and Slonim, Noam and Shmueli-Scheuer, Michal and Choshen, Leshem. Efficient Benchmarking (of Language Models). Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V...
-
[20]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Polo, Felipe Maia and Weber, Lucas and Choshen, Leshem and Sun, Yuekai and Xu, Gongjun and Yurochkin, Mikhail , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[21]
2025 , eprint=
APTBench: Benchmarking Agentic Potential of Base LLMs During Pre-Training , author=. 2025 , eprint=
2025
-
[22]
NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling , year=
How Benchmark Prediction from Fewer Data Misses the Mark , author=. NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling , year=
2025
-
[23]
2026 , eprint=
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory , author=. 2026 , eprint=
2026
-
[24]
The Thirteenth International Conference on Learning Representations , year=
metabench - A Sparse Benchmark of Reasoning and Knowledge in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[25]
and Yang, John and Ho, Leyton and Patwardhan, Tejal and Liu, Kevin and Madry, Aleksander , year=
Chowdhury, Neil and Aung, James and Shern, Chan Jun and Jaffe, Oliver and Sherburn, Dane and Starace, Giulio and Mays, Evan and Dias, Rachel and Aljubeh, Marwan and Glaese, Mia and Jimenez, Carlos E. and Yang, John and Ho, Leyton and Patwardhan, Tejal and Liu, Kevin and Madry, Aleksander , year=. Introducing
-
[26]
The Thirteenth International Conference on Learning Representations , year=
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains? , author=. The Thirteenth International Conference on Learning Representations , year=
-
[27]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Niels M. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[28]
V isual W eb A rena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Koh, Jing Yu and Lo, Robert and Jang, Lawrence and Duvvur, Vikram and Lim, Ming and Huang, Po-Yu and Neubig, Graham and Zhou, Shuyan and Salakhutdinov, Russ and Fried, Daniel. V isual W eb A rena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
-
[29]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Acpbench: Reasoning about action, change, and planning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[30]
American Invitational Mathematics Examination (AIME) 2025 , author=
2025
-
[31]
2025 , howpublished=
OpenHands Index: A Comprehensive Leaderboard for AI Coding Agents , author=. 2025 , howpublished=
2025
-
[32]
Proceedings of the National Academy of Sciences , volume=
CUR matrix decompositions for improved data analysis , author=. Proceedings of the National Academy of Sciences , volume=. 2009 , publisher=
2009
-
[33]
Technometrics , volume=
Ridge regression: Biased estimation for nonorthogonal problems , author=. Technometrics , volume=. 1970 , publisher=
1970
-
[34]
Journal of the Royal Statistical Society: Series B (Methodological) , volume =
Tibshirani, Robert , title =. Journal of the Royal Statistical Society: Series B (Methodological) , volume =. 1996 , month =. doi:10.1111/j.2517-6161.1996.tb02080.x , url =
-
[35]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
Nandan Thakur and Nils Reimers and Andreas R. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[36]
2025 , eprint=
SWE-Effi: Re-Evaluating Software AI Agent System Effectiveness Under Resource Constraints , author=. 2025 , eprint=
2025
-
[37]
Collaborative Performance Prediction for Large Language Models
Zhang, Qiyuan and Lyu, Fuyuan and Liu, Xue and Ma, Chen. Collaborative Performance Prediction for Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.150
-
[38]
ONEB ench to Test Them All: Sample-Level Benchmarking Over Open-Ended Capabilities
Ghosh, Adhiraj and Dziadzio, Sebastian and Prabhu, Ameya and Udandarao, Vishaal and Albanie, Samuel and Bethge, Matthias. ONEB ench to Test Them All: Sample-Level Benchmarking Over Open-Ended Capabilities. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1560
-
[39]
Spangher, Lucas and Li, Tianle and Arnold, William F. and Masiewicki, Nick and Dotiwalla, Xerxes and Pasumarthi, Rama Kumar and Grabowski, Peter and Ie, Eugene and Gruhl, Daniel. Chatbot Arena Estimate: towards a generalized performance benchmark for LLM capabilities. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Associa...
-
[40]
Model Consistency as a Cheap yet Predictive Proxy for LLM Elo Scores
Ramaswamy, Ashwin and Demeure, Nestor and Rrapaj, Ermal. Model Consistency as a Cheap yet Predictive Proxy for LLM Elo Scores. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1534
-
[41]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Lifbench: Evaluating the instruction following performance and stability of large language models in long-context scenarios , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[43]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Infobench: Evaluating instruction following ability in large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[44]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[45]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[46]
RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems
Repobench: Benchmarking repository-level code auto-completion systems , author=. arXiv preprint arXiv:2306.03091 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Advances in Neural Information Processing Systems , volume=
Planbench: An extensible benchmark for evaluating large language models on planning and reasoning about change , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
Gonzalez , booktitle=
Shishir G Patil and Huanzhi Mao and Fanjia Yan and Charlie Cheng-Jie Ji and Vishnu Suresh and Ion Stoica and Joseph E. Gonzalez , booktitle=. The Berkeley Function Calling Leaderboard (. 2025 , url=
2025
-
[49]
arXiv preprint arXiv:2404.05955 , year=
Visualwebbench: How far have multimodal llms evolved in web page understanding and grounding? , author=. arXiv preprint arXiv:2404.05955 , year=
-
[50]
Introducing GPT-5.2-Codex , year =
OpenAI , key =. Introducing GPT-5.2-Codex , year =
-
[51]
Introducing GPT-5.2 , year =
OpenAI , key =. Introducing GPT-5.2 , year =
-
[52]
Introducing Claude Sonnet 4.5 , year =
Anthropic , key =. Introducing Claude Sonnet 4.5 , year =
-
[53]
Introducing Claude Opus 4.5 , year =
Anthropic , key =. Introducing Claude Opus 4.5 , year =
-
[54]
Introducing Claude Opus 4.6 , year =
Anthropic , key =. Introducing Claude Opus 4.6 , year =
-
[55]
Gemini 3: A new era of intelligence with Gemini 3 , year =
-
[56]
The Fourteenth International Conference on Learning Representations , year=
SparseEval: Efficient Evaluation of Large Language Models by Sparse Optimization , author=. The Fourteenth International Conference on Learning Representations , year=
-
[57]
2026 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2026 , eprint=
2026
-
[58]
Visualpuzzles: Decoupling multimodal reasoning evaluation from domain knowledge , author=. arXiv preprint arXiv:2504.10342 , year=
-
[59]
2026 , eprint=
Kimi K2.5: Visual Agentic Intelligence , author=. 2026 , eprint=
2026
-
[60]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
MiniMax M2.1: Significantly Enhanced Multi-Language Programming, Built for Real-World Complex Tasks , year =
MiniMax , key =. MiniMax M2.1: Significantly Enhanced Multi-Language Programming, Built for Real-World Complex Tasks , year =
-
[62]
MiniMax M2.5: Built for Real-World Productivity
MiniMax , key =. MiniMax M2.5: Built for Real-World Productivity. , year =
-
[63]
Journal of Statistical software , volume=
Bradley-Terry models in R , author=. Journal of Statistical software , volume=
-
[64]
Journal of machine learning research , volume=
An introduction to variable and feature selection , author=. Journal of machine learning research , volume=
-
[65]
bioinformatics , volume=
A review of feature selection techniques in bioinformatics , author=. bioinformatics , volume=. 2007 , publisher=
2007
-
[66]
Qwen3-Coder: Agentic Coding in the World , year =
Qwen Team , key =. Qwen3-Coder: Agentic Coding in the World , year =
-
[67]
GLM-4.7: Advancing the Coding Capability , year =
Z.ai , key =. GLM-4.7: Advancing the Coding Capability , year =
-
[68]
2025 , eprint=
OpenAI GPT-5 System Card , author=. 2025 , eprint=
2025
-
[69]
2024 , eprint=
Lessons from the Trenches on Reproducible Evaluation of Language Models , author=. 2024 , eprint=
2024
-
[70]
2024 , month = jul, publisher =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[71]
2025 , eprint=
The OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agents , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.